原文链接:https://www.techbeat.net/article-info?id=4583
作者:seven_
随着以ChatGPT等大型语言模型(large language models,LLMs)的爆火,学界和工业界目前已经开始重视这些模型的安全性,由于ChatGPT强大的知识存储和推理能力,其目前可以针对各种各样的用户输入来产生非常流畅和完整的回答,甚至在一些专业领域以及公共讨论话题中,它也可以从容应对。例如,一些学生可能会使用LLMs来帮助他们完成书面作业,使老师无法准确的判断学生的学习效果,这也的的确确是LLMs带来的负面影响。

论文链接:
https://arxiv.org/abs/2301.11305
项目主页:
https://ericmitchell.ai/detectgpt/
近日,来自斯坦福大学的研究团队发布了一个名为DetectGPT的检测模型来判断一个文本段落是否是由机器生成的。作者首先观察了LLMs的运行机制,他们发现LLM生成的文本往往占据模型的对数概率函数的负曲率区域。根据这一现象,作者提出想法,能够基于概率函数的曲率标准来对文本进行判定呢?
实验结果表明,这种想法完全可行,DetectGPT不需要专门训练一个单独的分类器,也不需要额外收集真实场景中或者机器生成的文本段落数据,它只需要对当前模型计算其对数概率并与另外一个通用的预训练语言模型(例如T5)的段落随机扰动进行比较,即可得出结论。作者发现DetectGPT比现有的zero-shot文本检测方法更具有鉴别能力。
如果我们仔细推敲ChatGPT等LLMs生成出的文本回答,会发现它们的答案仍然有明显的机器翻译痕迹。但是这种生成技术确实在一些领域能够以假乱真,甚至取代人工劳动,特别是在学生的论文写作和记者的新闻写作中,这都会带来很大的风险,例如影响学生的学习积极性,也有可能会因为虚假新闻导致公众获得错误的信息。但是幸运的是,目前机器模型生成的文本与人类编写出的文字相比仍然有不小的差距,这使得我们及时开发文本检测方法和工具成为可能。之前已经有很多工作将机器生成的文本检测任务看做是一个二分类问题[1],具体来说,这些方法的目标是对一个候选文本段落的来源进行分类,其中这些文本来源是预定义的类别。但是这种方法有几个明显的缺点,例如它们会非常倾向于参与训练的那些文本来源,并且不具备增量学习功能,如果想要使模型能够识别未知来源的文本,就需要对模型整体重新训练。因此考虑开发具有zero-shot功能的模型才更符合现实场景,即根据文本源模型本身来进行开发,不进行任何形式的微调或适应,来检测它自己生成的样本。
zero-shot文本检测任务最常见的方法就是对生成文本的平均token对数概率进行评估,并设置阈值进行判断。本文作者针对此提出了一个简单的假设:机器对自己生成的文本进行改动时往往会比原始样本的对数概率低,而人类对自己所写文本的改动会远超过原本文本的对数概率。换句话说,与人类写的文本不同,模型生成的文本往往位于对数概率函数具有负曲率的区域(例如,对数概率的局部最大值),如下图所示。
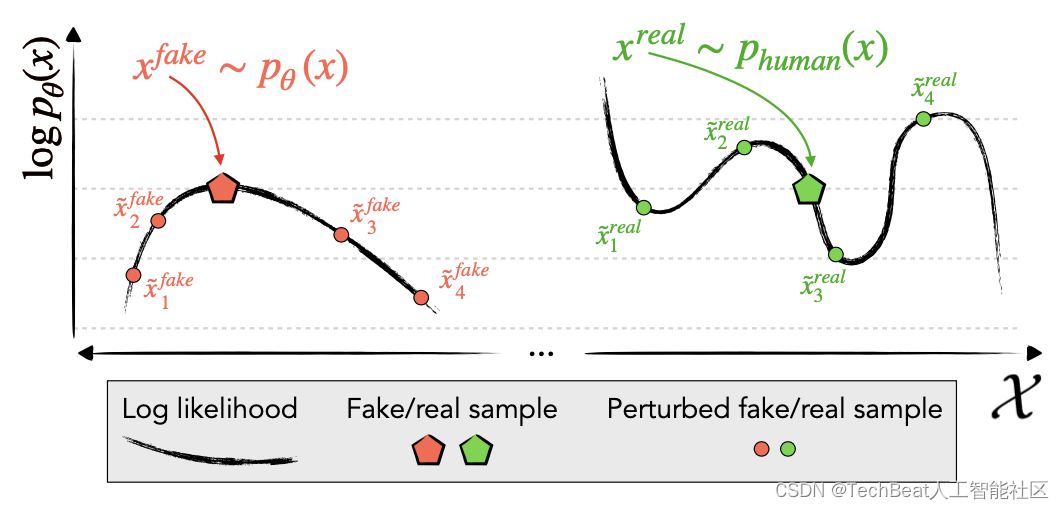
作者基于这一假设设计了DetectGPT,为了测试一个段落是否来自一个源模型
p
θ
p_{\theta}
pθ ,DetectGPT将与
p
θ
p_{\theta}
pθ 相关候选段落的对数概率与对
p
θ
p_{\theta}
pθ 进行随机扰动生成的段落的平均对数概率(例如用T5参与扰动)进行比较。如果被扰动的段落的平均对数概率比原始段落低一些,那么候选段落很可能来自于
p
θ
p_{\theta}
pθ , 这一过程的具体运行如下图所示。

对于机器生成的zero-shot文本检测任务设置,即检测一段文本或候选段落 x x x 是否是源模型 p θ p_{\theta} pθ 的样本,在模型训练时无需加入外部数据,其呈现“白盒设置”的特点,模型中的检测器可以评估当前样本对 p θ p_{\theta} pθ 的对数概率情况。此外“白盒设置”也不限制对模型架构和参数规模的选择,因此作者在对DetectGPT的性能评估中也选用了目前通用的预训练Masked模型,用来生成与当前段落比较接近的候选文本,但是这些段落的生成不会经过任何形式的微调和域适应。
上文提到,DetectGPT基于这样一个假设:来自源模型
p
θ
p_{\theta}
pθ 的样本通常位于
p
θ
p_{\theta}
pθ 的对数概率函数的负曲率区域。如果我们对一段话
x
∼
p
θ
x \sim p_{\theta}
x∼pθ 施加一个小的扰动,产生
x
~
\tilde{x}
x~ ,那么与人类编写的文本相比,机器生成的样本的对数值
log
p
θ
(
x
)
−
log
p
θ
(
x
~
)
\log p_{\theta}(x)-\log p_{\theta}(\tilde{x})
logpθ(x)−logpθ(x~) 应该是比较大的。基于这一假设,作者首先考虑了一个扰动函数
q
(
⋅
∣
x
)
q(\cdot \mid x)
q(⋅∣x) ,它会先在
x
~
\tilde{x}
x~ 上给出一个分布,代表意义相近的略微修改过的
x
x
x 的版本。使用扰动函数的概念,我们可以q轻松的定义出扰动差异指标
d
(
x
,
p
θ
,
q
)
\mathbf{d}\left(x, p_{\theta}, q\right)
d(x,pθ,q):
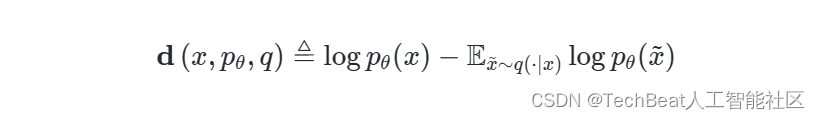
对上述假设更为正式的定义如下:如果
q
q
q 在数据流形分布上产生样本,对于样本
x
∼
p
θ
x \sim p_{\theta}
x∼pθ 来说,
d
(
x
,
p
θ
,
q
)
\mathbf{d}\left(x, p_{\theta}, q\right)
d(x,pθ,q) 大概率为正,而对于人类编写文本,
d
(
x
,
p
θ
,
q
)
\mathbf{d}\left(x, p_{\theta}, q\right)
d(x,pθ,q) 对所有
x
x
x 都趋向于0。
如果此时将扰动函数
q
(
⋅
∣
x
)
q(\cdot \mid x)
q(⋅∣x) 定义为来自T5等预训练模型生成的扰动样本,而不是人类改写的样本,就可以以一种自动的、可扩展的方式对上述假设进行经验性测试。对于机器生成样本,这里作者使用了四个不同的LLM进行输出,例如使用T5-3B模型来产生扰动,对于给定样本,按照2个字的跨度进行随机扰动,直到文本中15%的字被覆盖。随后使用经过T5处理的100个样本按照假设进行近似计算,发现扰动差异的分布对于人类编写文本和机器生成样本是明显不同的,机器样本往往有较大的扰动差异。
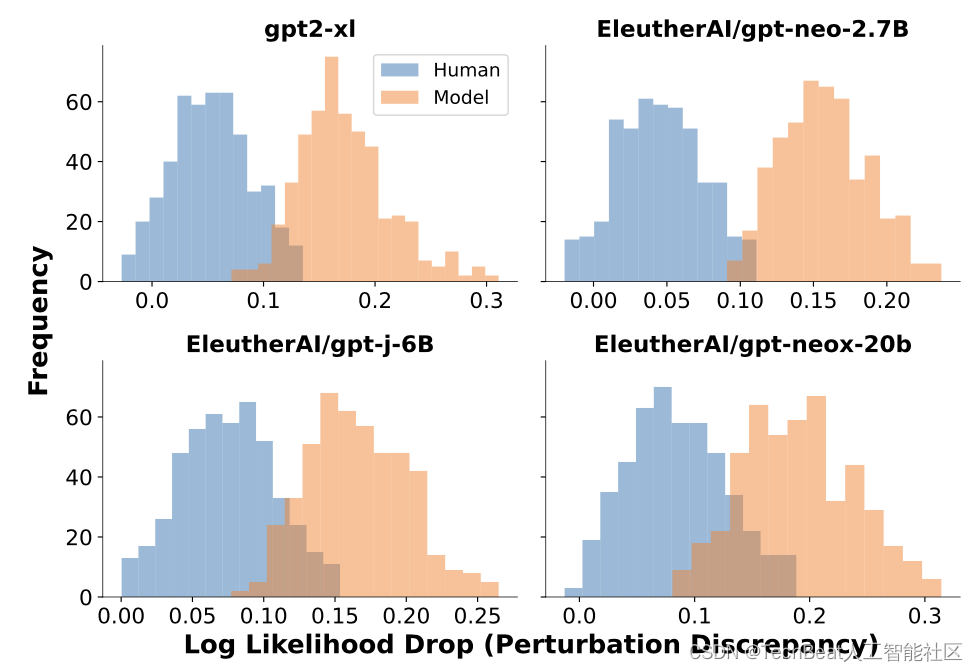
上图展示了来自GPT-2、GPT-Neo-2.7B、GPT-J和GPT-NeoX 四个模型与人类样本扰动后的分布对比,其中蓝色区域为人类编写文本的分布,橙色为机器生成文本的分布。
通过上图,只能看出扰动差异在鉴别文本是否来自人类还是机器方面是有效的,但是其衡量的理论指标还不够清晰。因而作者进一步为扰动差异寻找到了理论依据,作者表明扰动差异近似于候选段落附近对数概率函数的局部曲率的度量,更具体地说,它与对数概率函数的Hessian 矩阵的负迹成正比。为了处理离散数据的不可微性,作者在这里仅考虑了在潜在语义空间中的候选段落,其中的小扰动对应于保留与原始相似含义的文本编辑过程。因为本文选用的扰动函数 (T5) 是经过大量自然文本语料预训练的,所以这里的扰动可以被粗略地认为是对原始段落的有效修改,而不是随意编辑。
作者首先利用Hutchinson提出的迹估计器[3]给出矩阵
A
A
A 迹的无偏估计:
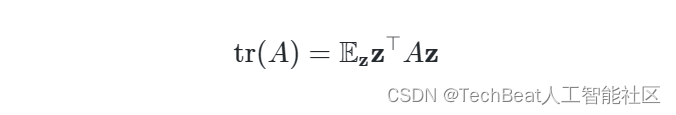
随后使用有限差分来近似这个表达式:
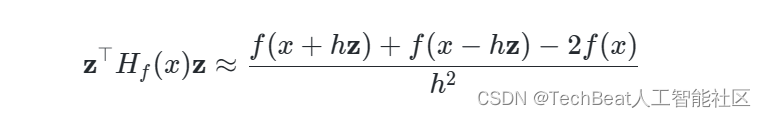
联立上述两式子并使用
h
=
1
h = 1
h=1 进行简化,就可以得到负Hessian矩阵的迹估计:
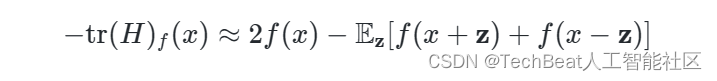
作者观察到上式其实对应于扰动差异
d
(
x
,
p
θ
,
q
)
\mathbf{d}\left(x, p_{\theta}, q\right)
d(x,pθ,q) ,其中扰动函数
q
(
⋅
∣
x
)
q(\cdot \mid x)
q(⋅∣x) 可以使用Hutchinson迹估计器中使用的分布
q
z
(
z
)
q_{z}(z)
qz(z) 代替。这里,
x
~
\tilde{x}
x~ 是一个高维的token序列,而
q
z
q_{z}
qz 是一个嵌入语义空间中的向量。由于扰动文本模型生成的句子与
x
x
x 相似,语义变化较小,因此可以将扰动文本模型视为与当前采样相似的语义嵌入
(
z
~
∼
q
z
)
\left(\tilde{z} \sim q_{z}\right)
(z~∼qz) ,然后将其映射到token序列中
(
z
~
↦
x
~
)
(\tilde{z} \mapsto \tilde{x})
(z~↦x~) 。 这样做,可以保证语义空间中的采样都保持在数据流形附近,当随机扰动发生后,对数概率就会产生明显下降,这样就可以将扰动差异解释为近似限制在数据流形上的曲率。
本文的实验部分作者使用了六个数据集,涵盖了各种日常领域,例如使用XSum数据集中的新闻文章来进行假新闻检测实验,使用SQuAD上下文中的维基百科段落来表示机器编写的学术论文,以及使用Reddit WritingPrompts数据集来表示机器生成的创意写作。此外,为了评估分布变化的稳健性,作者还使用了WMT16的英语和德语部分以及人类专家在PubMedQA数据集中编写的标准答案。
作者首先对DetectGPT的zero-shot文本检测能力进行评估,实验结果如下表所示,可以看出,DetectGPT在所有15种数据集和模型组合中的14种实验组合上都得到了最准确的检测性能。尤其是DetectGPT最大程度地提高了XSum数据集的平均检测精度(0.1 AUROC 改进),在SQuAD维基百科上下文数据集上也有明显的性能提升(0.05 AUROC 改进)。

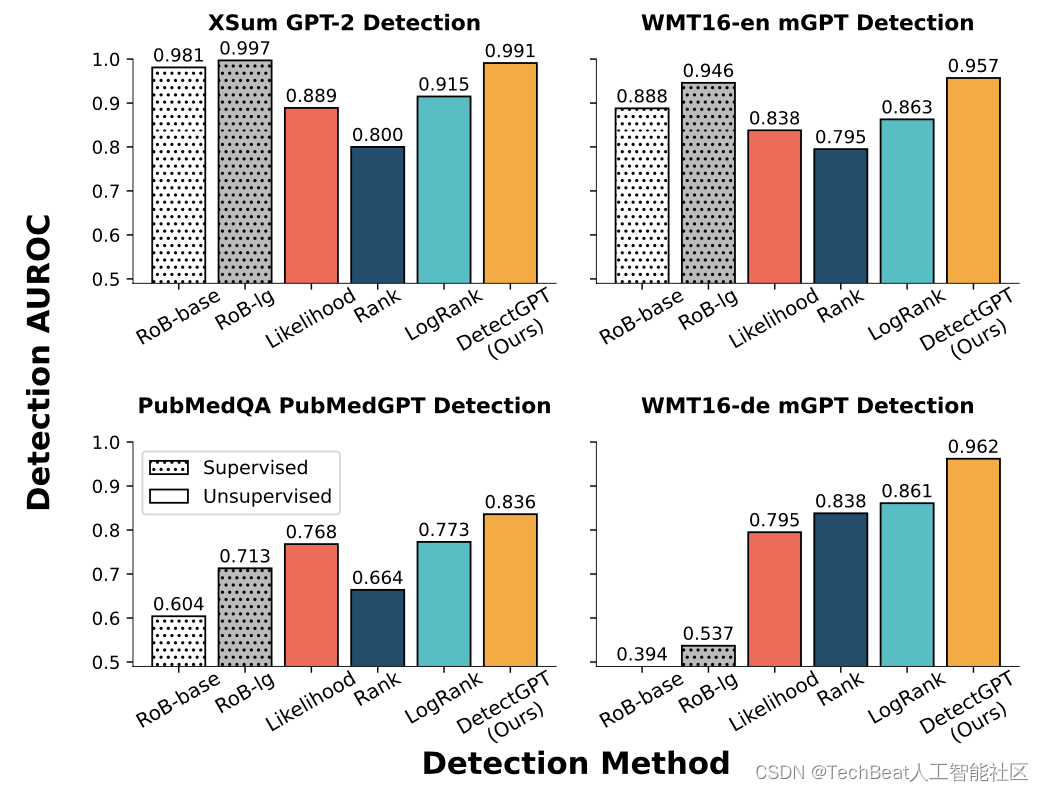
此外,作者还选取了一部分监督学习训练的检测器进行对比。作者着重探索了几个领域,或者说几种语境,对比结果如下图所示。例如在英语新闻数据上,监督检测器可以达到与 DetectGPT 接近的检测性能,但在英语科学写作数据下,其性能明显低于本文方法。而在德语写作中监督学习方法会完全失败。相比之下,以DetectGPT为代表的零样本方法更容易泛化到新的语言和领域中。
随着LLMs的不断发展和改进,我们应该一方面对它们在越来越多的领域中减轻人类工作者的创作压力感到高兴,另一方面也更应该同步发展针对它们的安全检测技术,这对于这一领域未来的健康发展至关重要。本文从这些大模型本身的运行机制出发设计了DetectGPT方法,DetectGPT通过一个简单的数据分布特点即可判断出文本的来源,此外作者还对本文方法进行了详尽的理论推导,这使得DetectGPT具有更高的可信度和可解释性。此外DetectGPT的zero-shot特性使它相比那些使用数百万数据样本定制训练的检测模型更具有竞争力。此外作者在文章的最后还谈到了DetectGPT的未来计划,他们会进一步探索对数概率曲率属性是否在其他领域(音频、视频或图像)的生成模型中也能起到很好的检测作用,这一方向也具有非常重要的现实意义,让我们一起期待吧。
[1] Jawahar, G., Abdul-Mageed, M., and Lakshmanan, L. V. S. Automatic detection of machine generated text: A critical survey. In International Conference on Computational Linguistics, 2020.
[2] Narayan, S., Cohen, S. B., and Lapata, M. Don’t give me the details, just the summary! Topic-aware convolutional neural networks for extreme summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 2018.
[3] Hutchinson, M. A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines. Communications in Statistics - Simulation and Computation, 19(2):433–450, 1990. doi: 10.1080/ 03610919008812866. URL https://doi.org/10. 1080/03610919008812866.
Illustration by Bittu Designs from IconScout
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri