自动化测试的核心技术就是元素定位,我们要想对元素进行操作,必须要找到这个元素的所在位置,webdriver中有很多进行元素定位的方法:
1、xpath定位
xpath定位有很多种定位策略:
>使用元素的绝对路径
>使用元素的相对路径
>使用元素属性定位
>使用层级和属性结合定位(使用上级属性定位)
>使用层级和属性结合定位(使用逻辑运算符定位)
方法:find_element_by_xpath()
Discuz论坛登录业务:
from time import sleep # 导入时间模块
from selenium import webdriver # 从selenium模块中导入webdriver子模块
url = "http://192.168.152.128/upload/forum.php" # 定义url地址
driver = webdriver.Chrome() # 定义一个对象
driver.get(url=url) # 访问url
sleep(6) # 思考时间6s
# 根据相对路径定位用户名输入框
driver.find_element_by_xpath('//*[@id="ls_username"]').send_keys('admin')
sleep(6)
# 根据绝对路径定位密码输入框
driver.find_element_by_xpath('/html/body/div[5]/div/div[1]/form/div/div/table/tbody/tr[2]/td[2]/input').send_keys(
'123456')
# 根据相对路径定位登录按钮
driver.find_element_by_xpath('//*[@id="lsform"]/div/div/table/tbody/tr[2]/td[3]/button/em').click()
sleep(6)
driver.quit()操作步骤:
①打开Discuz论坛首页,点击右键/检查,或者点击F12,进入调试界面
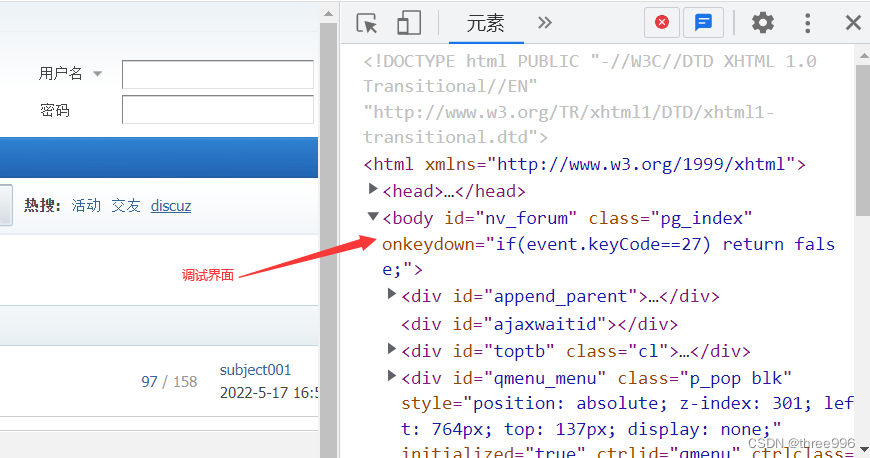
②点击元素检查按钮,然后点击网站中用户名输入框,查看元素源代码
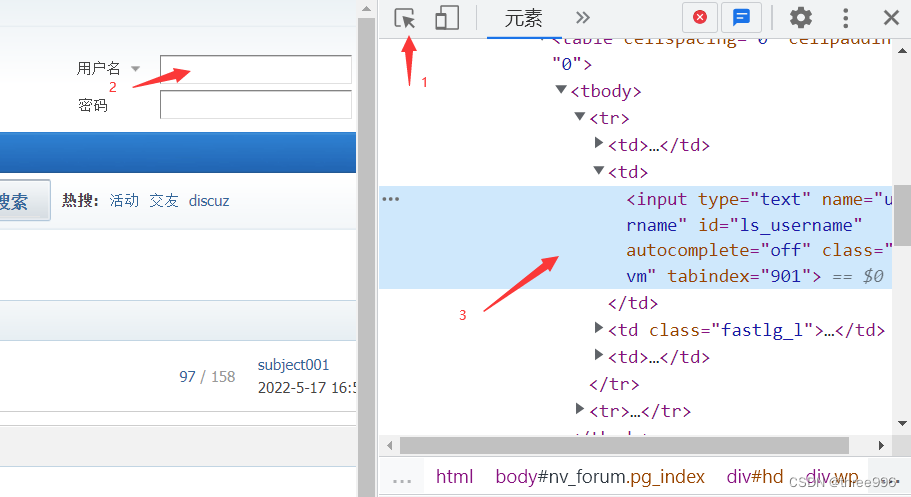
③点击调试界面的源代码,右键/复制/复制Xpath(相对路径)或者复制完整Xpath(绝对路径)
④将复制的Xpath放到 driver.find_element_by_xpath()中
⑤ 依次点击密码输入框、登录按钮,然后将路径全部复制到 driver.find_element_by_xpath()中
2、id定位
HTML文档中的id是唯一的,id定位是查找元素的最佳方法,方法是:
driver.find_element_by_id()和driver.find_elements_by_id
Discuz论坛登录业务:
from time import sleep # 导入时间模块
from selenium import webdriver # 从selenium模块中导入webdriver子模块
url = "http://192.168.152.128/upload/forum.php" # 定义url地址
driver = webdriver.Chrome() # 定义一个对象
driver.get(url=url) # 访问url
sleep(6) # 思考时间6s
driver.find_element_by_id('ls_username').send_keys('admin') # id元素定位用户名输入框
sleep(6)
driver.find_element_by_id('ls_password').send_keys('123456') # id元素定位密码输入框
# xpath定位登录按钮
driver.find_element_by_xpath('/html/body/div[5]/div/div[1]/form/div/div/table/tbody/tr[2]/td[3]/button/em').click()
sleep(6)
driver.quit() # 退出网页操作步骤:
①同上
②在调试代码中找到Id的值,复制到driver.find_element_by_id()中
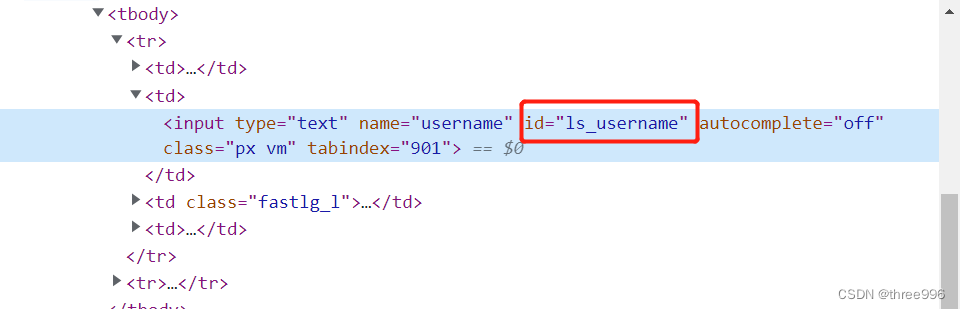
③将密码输入框的id值,复制到driver.find_element_by_id()中
④登录按钮的代码中,发现没有id值,我们用Xpath定位法将路径复制过去

3、name定位
name值在HTMl中不一定是唯一的
方法:find_element_by_name() 和 find_elements_by_name()
Discuz论坛登录业务:
from time import sleep # 导入时间模块
from selenium import webdriver # 从selenium模块中导入webdriver子模块
url = "http://192.168.152.128/upload/forum.php" # 定义url地址
driver = webdriver.Chrome() # 定义一个对象
driver.get(url=url) # 访问url
sleep(6)
driver.find_element_by_name('username').send_keys('admin') # 使用name定位用户名输入框
driver.find_element_by_name('password').send_keys('123456') # 使用name定位密码输入框
# xpath定位登录按钮
driver.find_element_by_xpath('//*[@id="lsform"]/div/div/table/tbody/tr[2]/td[3]/button/em').click()
sleep(6)
driver.quit()操作步骤:
①同上
②在调试代码中找到name的值,复制到driver.find_element_by_name()中
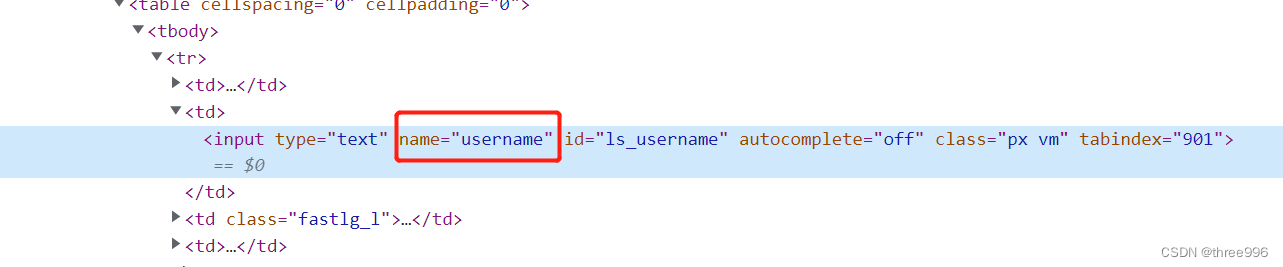
③将密码输入框的name值,复制到driver.find_element_by_name()中
④登录按钮的代码中,发现没有name值,我们用Xpath定位法将路径复制过去
4、class定位
通过class属性定位元素,class属性不止有一个属性值,但是只能使用其中一个
方法:find_element_by_class_name()和 find_elements_by_class_name()
Discuz论坛登录业务:
from time import sleep # 导入时间模块
from selenium import webdriver # 从selenium模块中导入webdriver子模块
url = "http://192.168.152.128/upload/forum.php" # 定义url地址
driver = webdriver.Chrome() # 定义一个对象
driver.get(url=url) # 访问url
sleep(6)
driver.find_element_by_class_name('px').send_keys('admin') # class_name定位用户名输入框
driver.find_element_by_xpath('//*[@id="ls_password"]').send_keys("123456") # xpath定位密码输入框
# xpath定位登录按钮
driver.find_element_by_xpath('//*[@id="lsform"]/div/div/table/tbody/tr[2]/td[3]/button/em').click()
sleep(6)
driver.quit()操作步骤:
①同上
②在调试代码中找到class的值,选择其中一个,复制到driver.find_element_by_class_name()中
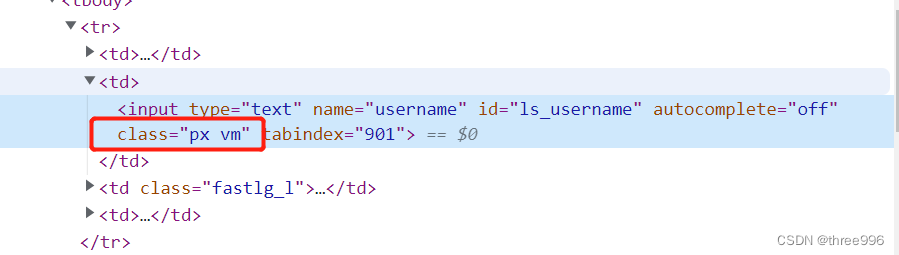
③查看密码输入框源代码时,发现密码输入框的class值与用户名输入框的class值是一样的,我们就用xpath定位法将路径复制到driver.find_element_by_xpath()中
④登录按钮的源代码中没有class值,使用xpath定位法将路径复制到driver.find_element_by_xpath()中
5、tag定位
在HTML中,每一个元素都是tag,在一个网页中通常会有很多个重复的tag,用tag来定位元素,相对于其他方法效率很低
方法:find_element_by_tag_name()和 find_elements_by_tag_name()
Discuz论坛登录业务:
from time import sleep # 导入时间模块
from selenium import webdriver # 从selenium模块中导入webdriver子模块
url = "http://192.168.152.128/upload/forum.php" # 定义url地址
driver = webdriver.Chrome() # 定义一个对象
driver.get(url=url) # 访问url
sleep(6)
driver.find_elements_by_tag_name('input')[0].send_keys('admin') #tag定位用户名输入框
sleep(6)
driver.find_elements_by_tag_name('input')[2].send_keys('123456') #tag定位密码输入框
sleep(6)
driver.find_elements_by_tag_name('em')[0].click() #tag定位登录按钮
sleep(6)
driver.quit()操作步骤:
①同上
②在源代码中,找一个最近的标签(input),然后去网页源代码中查找这个标签,看看它是第几个(第一个)
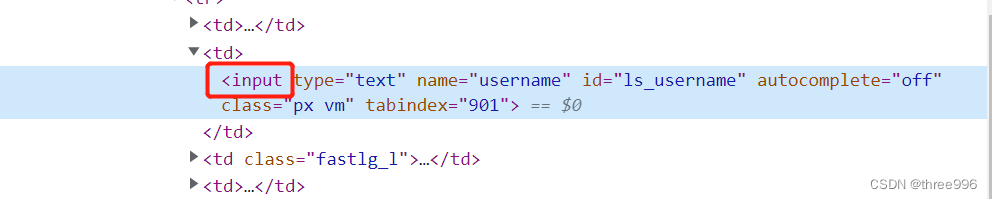
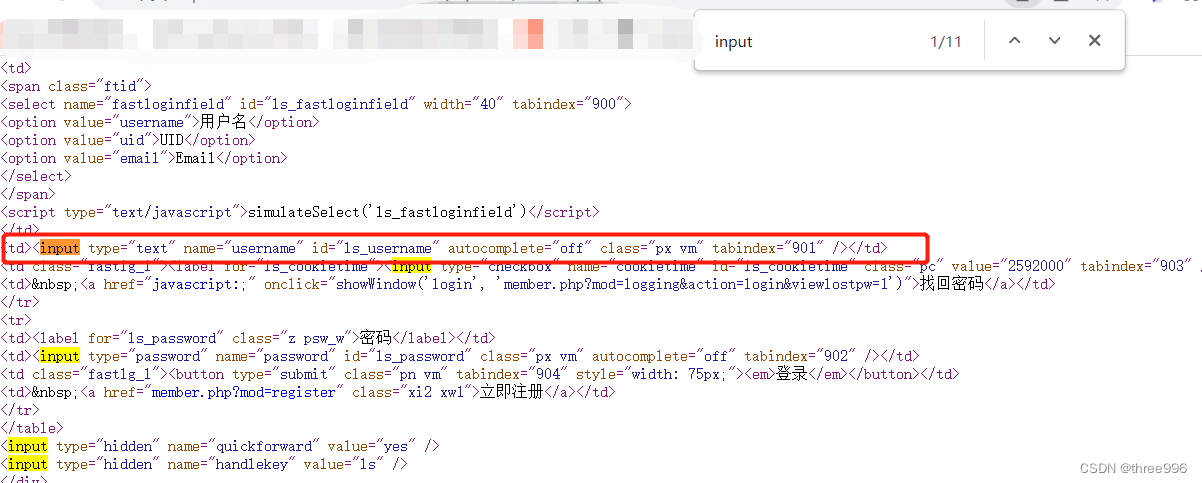
③将input标签放到driver.find_elements_by_tag_name()中,因为数组下标是从0开始的, 查找出来的是第一个,下标就是(n-1),应该写成[0]
④找到密码输入框的标签(input),跟用户名输入框的标签一样,只是顺序下标不一样,密码输入框的标签是第三个,应该写成[2]
⑤找到登录按钮的标签(em),然后去网页源代码中查找这个标签,看看它是第几个(第一个)

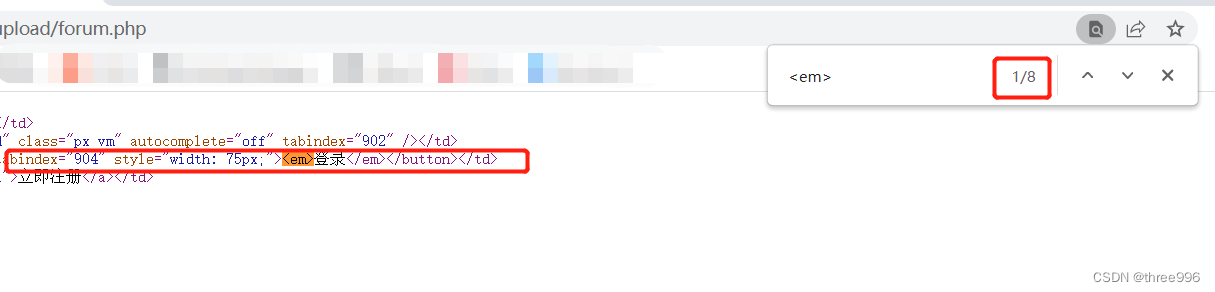
⑤将input标签放到driver.find_elements_by_tag_name()中,因为数组下标是从0开始的,查找出来的是第一个,下标就是(n-1),应该写成[0]
6、css定位
css比较灵活,可以选择任意属性,定位速度比xpath快
方法:find_element_by_css_selector()和 find_elements_by_css_selector()
css也有很多种定位策略:
>使用id定位
>使用class定位
>使用属性定位
>使用元素层级、属性组合定位
Discuz论坛登录业务:
from time import sleep # 导入时间模块
from selenium import webdriver # 从selenium模块中导入webdriver子模块
url = "http://192.168.152.128/upload/forum.php" # 定义url地址
driver = webdriver.Chrome() # 定义一个对象
driver.get(url=url) # 访问url
sleep(6)
driver.find_element_by_css_selector('#ls_username').send_keys('admin') # 使用class中id定位
driver.find_element_by_css_selector('[name="password"]').send_keys('123456') # 使用class中属性定位
# 使用xpath定位
driver.find_element_by_xpath('//*[@id="lsform"]/div/div/table/tbody/tr[2]/td[3]/button/em').click()
sleep(6)
driver.quit()操作步骤:
①同上
②在用户名输入框代码中,能看到id和name属性以及class属性等,我们可以随意选择这些数据进行css定位,在这里我们使用id值,将id值复制到driver.find_element_by_css_selector()中,id值前必须加上 # (如果选择class值的话,就必须加上.)

③在密码输入框代码中,我们选择name属性值,普通属性值用[]括起来,同时注意引号的嵌套
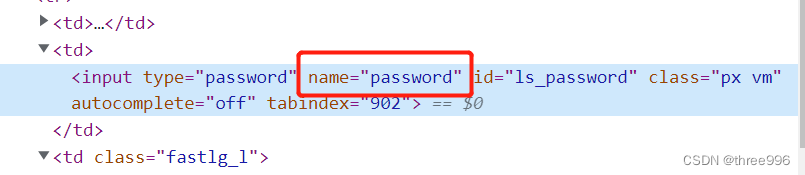
④登录按钮使用xpath定位
7、link定位
link主要是定位文本链接
方法:find_element_by_link_text() 和 find_elements_by_link_text()
Discuz论坛“交友”链接:
from time import sleep # 导入时间模块
from selenium import webdriver # 从selenium模块中导入webdriver子模块
url = "http://192.168.152.128/upload/forum.php" # 定义url地址
driver = webdriver.Chrome() # 定义一个对象
driver.get(url=url) # 访问url
sleep(6) # 思考时间6s
driver.find_element_by_link_text('交友').click() # 使用link定位
sleep(6)
driver.quit()操作步骤:
①将文本链接的文字(交友)复制到find_element_by_link_text()中即可
8、partial link 定位
有时链接文本比较长时,我们可以使用partial link定位,意思是部分文本定位
方法:find_element_by_partial_link_text()和 find_elements_by_partial_link_text()
Discuz论坛“查看新帖”链接:
from time import sleep # 导入时间模块
from selenium import webdriver # 从selenium模块中导入webdriver子模块
url = "http://192.168.152.128/upload/forum.php" # 定义url地址
driver = webdriver.Chrome() # 定义一个对象
driver.get(url=url) # 访问url
sleep(6) # 思考时间6s
driver.find_element_by_partial_link_text('查看新').click() # 使用partial link定位
sleep(6)
driver.quit()操作步骤:
①将文本链接的部分文字(查看新)复制到driver.find_element_by_partial_link_text()中即可
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我是HanamiWorld的新人。我已经写了这段代码:moduleWeb::Views::HomeclassIndexincludeWeb::ViewincludeHanami::Helpers::HtmlHelperdeftitlehtml.headerdoh1'Testsearchengine',id:'title'hrdiv(id:'test')dolink_to('Home',"/",class:'mnu_orizontal')link_to('About',"/",class:'mnu_orizontal')endendendendend我在模板上调用了title方法。htm
在Ruby中,是否有一种简单的方法可以将n维数组中的每个元素乘以一个数字?这样:[1,2,3,4,5].multiplied_by2==[2,4,6,8,10]和[[1,2,3],[1,2,3]].multiplied_by2==[[2,4,6],[2,4,6]]?(很明显,我编写了multiplied_by函数以区别于*,它似乎连接了数组的多个副本,不幸的是这不是我需要的)。谢谢! 最佳答案 它的长格式等价物是:[1,2,3,4,5].collect{|n|n*2}其实并没有那么复杂。你总是可以使你的multiply_by方法:c
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1
我在尝试使用Nokogiri构建XML文档时遇到了一个小问题。我想将我的元素之一称为“文本”(请参阅下面粘贴代码的最底部)。通常,要创建一个新元素,我会执行类似以下的操作xml.text--但它似乎是.text是Nokogiri已经用来做其他事情的方法。因此,当我写这行时xml.textNokogiri没有创建名为的新元素但只是写了意味着成为元素内容的文本。我怎样才能让Nokogiri实际制作一个名为的元素??builder=Nokogiri::XML::Builder.newdo|xml|xml.TEI("xmlns"=>"http://www.tei-c.org/ns/1.0"
如果我想使用“create”构建策略创建和实例,然后想使用“attributes_for”构建策略进行验证,是否可以这样做?如果我在工厂中使用序列?在Machinistgem中有可能吗? 最佳答案 不太确定我是否完全理解。而且我不是机械师的用户。但听起来您只是想做这样的事情。@attributes=FactoryGirl.attributes_for(:my_object)my_object=MyObject.create(@attributes)my_object.some_property.should==@attributes
我想通过内部数组中的第一个元素从数组数组中找到唯一元素。例如a=[[1,2],[2,3],[1,5]我想要类似的东西[[1,2],[2,3]] 最佳答案 uniq方法需要一个block:uniq_a=a.uniq(&:first)或者如果您想就地进行:a.uniq!(&:first)例如:>>a=[[1,2],[2,3],[1,5]]=>[[1,2],[2,3],[1,5]]>>a.uniq(&:first)=>[[1,2],[2,3]]>>a=>[[1,2],[2,3],[1,5]]或者>>a=[[1,2],[2,3],[1,5]