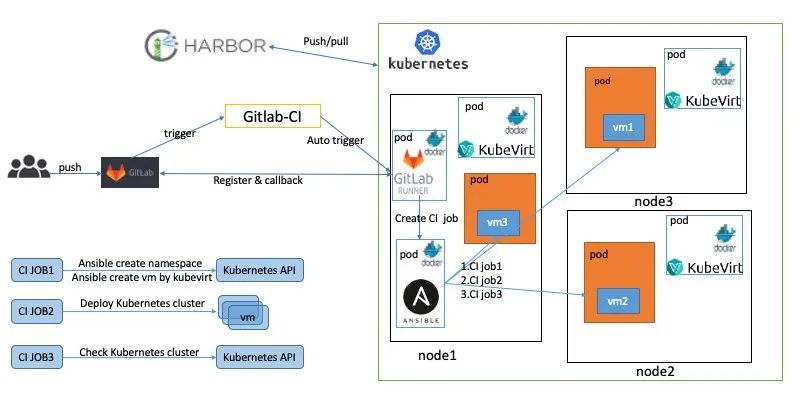
 如上图所示,当开发人员在GitLab提交PR时会触发一系列操作。这里主要展示了创建虚拟机和集群部署。其实在我们的集群还部署了语法检查和性能测试gitlab-runner,通过这些gitlab-runner创建CI的job去执行CI流程。具体CI流程如下:
如上图所示,当开发人员在GitLab提交PR时会触发一系列操作。这里主要展示了创建虚拟机和集群部署。其实在我们的集群还部署了语法检查和性能测试gitlab-runner,通过这些gitlab-runner创建CI的job去执行CI流程。具体CI流程如下: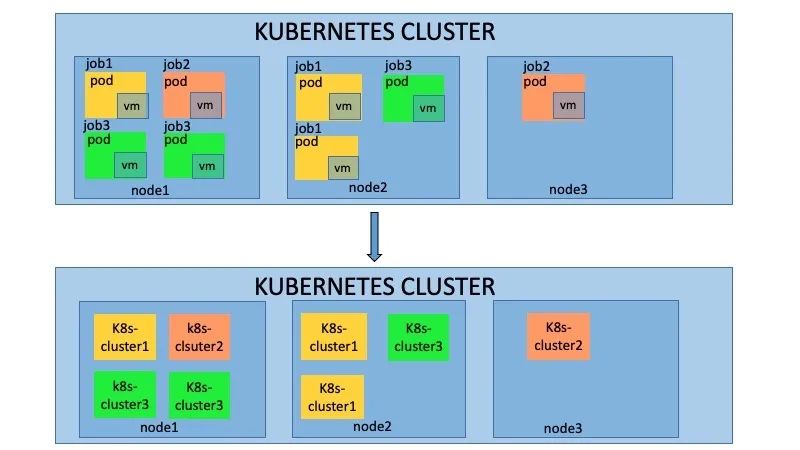 如上图所示,当开发人员提交多个PR时,会在k8s集群中创建多个job,每个job都会执行上述的CI测试,互相不会产生影响。这种主要使用kubevirt的能力,实现了k8s on k8s的架构。kubevirt主要能力如下:
如上图所示,当开发人员提交多个PR时,会在k8s集群中创建多个job,每个job都会执行上述的CI测试,互相不会产生影响。这种主要使用kubevirt的能力,实现了k8s on k8s的架构。kubevirt主要能力如下: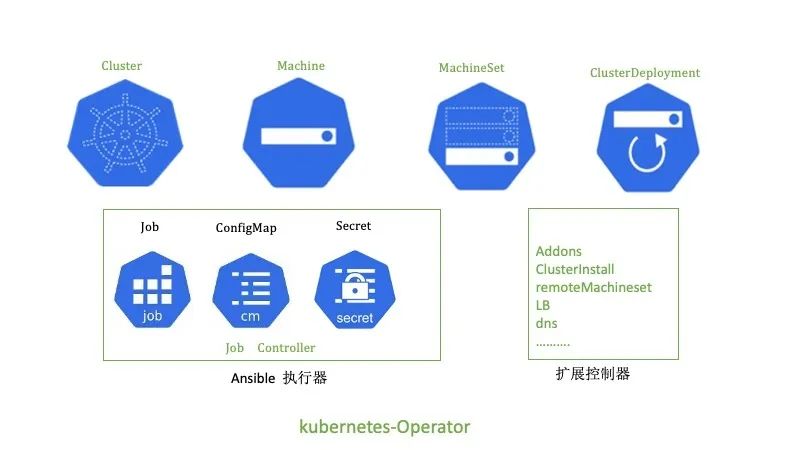 kubernetes-operator的使用很多自定义的CR资源和控制器,这里简单的介绍功能和作用。【ClusterDeployment】: 管理员配置的唯一的CR,其中MachineSet、Machine和Cluster它的子资源或者关联资源。ClusterDeployment是所有的配置参数入口,定义了如etcd、k8s、lb、集群版本、网路和addons等所有配置。【MachineSet】:集群角色的集合包括控制节点、计算节点和etcd的配置和执行状态。【Machine】:每台机器的具体信息,包括所属的角色、节点本身信息和执行的状态。【Cluster】:和ClusterDeployment对应,它的status定义为subresource,减少clusterDeployment的触发压力。主要用于存储ansible执行器执行脚本的状态。【ansible执行器】:主要包括k8s自身的job、configMap、Secret和自研的job控制器。其中job主要用来执行ansible的脚本,因为k8s的job的状态有成功和失败,这样job 控制器很好观察到ansible执行的成功或者失败,同时也可以通过job对应pod日志去查看ansible的执行详细流程。configmap主要用于存储ansible执行时依赖的inventory和变量,挂在到job上。secret主要存储登陆主机的密钥,也是挂载到job上。【扩展控制器】:主要用于扩展集群管理的功能的附加控制器,在部署kubernetes-operator我们做了定制,可以选择自己需要的扩展控制器。比如addons控制器主要负责addon插件的安装和管理。clusterinstall主要生成ansible执行器。remoteMachineSet用于多集群管理,同步元数据集群和业务集群的machine状态。还有其它的如对接公有云、dns、lb等控制器。
kubernetes-operator的使用很多自定义的CR资源和控制器,这里简单的介绍功能和作用。【ClusterDeployment】: 管理员配置的唯一的CR,其中MachineSet、Machine和Cluster它的子资源或者关联资源。ClusterDeployment是所有的配置参数入口,定义了如etcd、k8s、lb、集群版本、网路和addons等所有配置。【MachineSet】:集群角色的集合包括控制节点、计算节点和etcd的配置和执行状态。【Machine】:每台机器的具体信息,包括所属的角色、节点本身信息和执行的状态。【Cluster】:和ClusterDeployment对应,它的status定义为subresource,减少clusterDeployment的触发压力。主要用于存储ansible执行器执行脚本的状态。【ansible执行器】:主要包括k8s自身的job、configMap、Secret和自研的job控制器。其中job主要用来执行ansible的脚本,因为k8s的job的状态有成功和失败,这样job 控制器很好观察到ansible执行的成功或者失败,同时也可以通过job对应pod日志去查看ansible的执行详细流程。configmap主要用于存储ansible执行时依赖的inventory和变量,挂在到job上。secret主要存储登陆主机的密钥,也是挂载到job上。【扩展控制器】:主要用于扩展集群管理的功能的附加控制器,在部署kubernetes-operator我们做了定制,可以选择自己需要的扩展控制器。比如addons控制器主要负责addon插件的安装和管理。clusterinstall主要生成ansible执行器。remoteMachineSet用于多集群管理,同步元数据集群和业务集群的machine状态。还有其它的如对接公有云、dns、lb等控制器。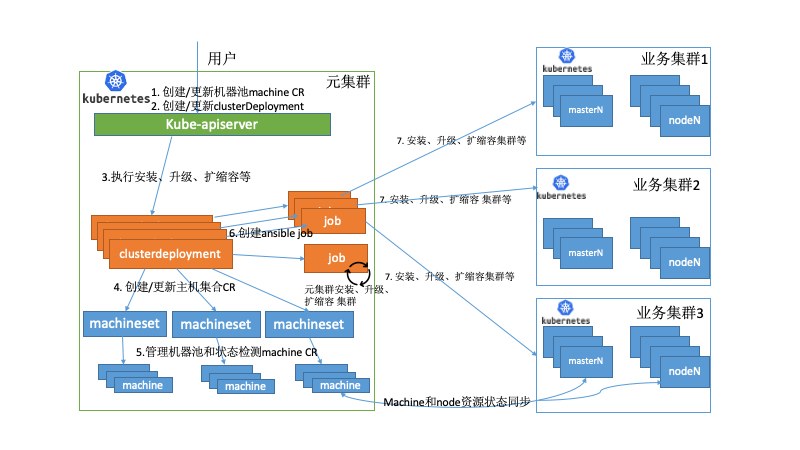 vivo的应用分布在数据中心的多个k8s集群上,提供了具有集中式多云管理、统一调度、高可用性、故障恢复等关键特性。主要搭建了一个元数据集群的pass平台去管理多个业务k8s集群。在众多关键组件中,其中kubernetes-operator就部署在元数据集群中,同时单独运行了machine控制器去管理物理资源。下面举例部分场景如下:场景一:当大量应用迁移到kubernets上,管理员评估需要扩容集群。首先需要审批物理资源并通过pass平台生成对应machine的CR资源,此时的物理机处于备机池里,machine CR的状态为空闲状态。当管理员创建ClusterDeploment时所属的MachineSet会去关联空闲状态的machine,拿到空闲的machine资源,我们就可以观测到当前需要操作机器的IP地址生成对应的inventory和变量,并创建configmap并挂载给job。执行扩容的ansible脚本,如果job成功执行完会去更新machine的状态为deployed。同时跨集群同步node的控制器会检查当前的扩容的node是否为ready,如果为ready,会更新当前的machine为Ready状态,才完成整个扩容流程。场景二:当其中一个业务集群出现故障,无法提供服务,触发故障恢复流程,走统一资源调度。同时业务的策略是分配在多个业务集群,同时配置了一个备用集群,并没有在备用集群上分配实例,备用集群并不实际存在。有如下2种情况:
vivo的应用分布在数据中心的多个k8s集群上,提供了具有集中式多云管理、统一调度、高可用性、故障恢复等关键特性。主要搭建了一个元数据集群的pass平台去管理多个业务k8s集群。在众多关键组件中,其中kubernetes-operator就部署在元数据集群中,同时单独运行了machine控制器去管理物理资源。下面举例部分场景如下:场景一:当大量应用迁移到kubernets上,管理员评估需要扩容集群。首先需要审批物理资源并通过pass平台生成对应machine的CR资源,此时的物理机处于备机池里,machine CR的状态为空闲状态。当管理员创建ClusterDeploment时所属的MachineSet会去关联空闲状态的machine,拿到空闲的machine资源,我们就可以观测到当前需要操作机器的IP地址生成对应的inventory和变量,并创建configmap并挂载给job。执行扩容的ansible脚本,如果job成功执行完会去更新machine的状态为deployed。同时跨集群同步node的控制器会检查当前的扩容的node是否为ready,如果为ready,会更新当前的machine为Ready状态,才完成整个扩容流程。场景二:当其中一个业务集群出现故障,无法提供服务,触发故障恢复流程,走统一资源调度。同时业务的策略是分配在多个业务集群,同时配置了一个备用集群,并没有在备用集群上分配实例,备用集群并不实际存在。有如下2种情况: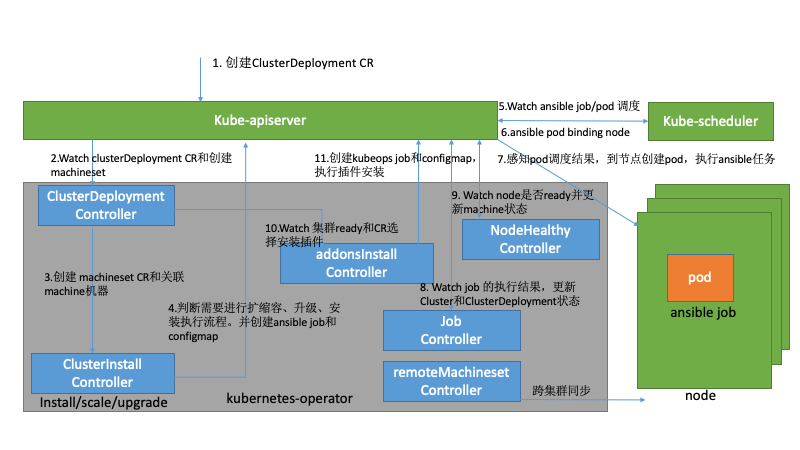
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我想知道是否可以通过自动创建数组来插入数组,如果数组不存在的话,就像在PHP中一样:$toto[]='titi';如果尚未定义$toto,它将创建数组并将“titi”压入。如果已经存在,它只会推送。在Ruby中我必须这样做:toto||=[]toto.push('titi')可以一行完成吗?因为如果我有一个循环,它会测试“||=”,除了第一次:Person.all.eachdo|person|toto||=[]#with1billionofperson,thislineisuseless999999999times...toto.push(person.name)你有更好的解决方案吗?
参见下面的示例,我想最好使用第二种方法,但第一种也可以。哪种方法最好,使用另一种的后果是什么?classTestdefstartp"started"endtest=Test.newtest.startendclassTest2defstartp"started"endendtest2=Test2.newtest2.start 最佳答案 我肯定会说第二种变体更有意义。第一个不会导致错误,但对象实例化完全过时且毫无意义。外部变量在类的范围内不可见:var="string"classAvar=A.newendputsvar#=>strin
如果我构建了一个应用程序来访问来自Gmail、Twitter和Facebook的一些数据,并且我希望用户只需输入一次他们的身份验证信息,并且在几天或几周后重置,那会怎样是在Ruby中动态执行此操作的最佳方法吗?我看到很多人只是拥有他们客户/用户凭证的配置文件,如下所示:gmail_account:username:myClientpassword:myClientsPassword这看起来a)非常不安全,b)如果我想为成千上万的用户存储此类信息,它就无法工作。推荐的方法是什么?我希望能够在这些服务之上构建一个界面,因此每次用户进行交易时都必须输入凭据是不可行的。