现在本地创建一个excel表,以及两个sheet,具体数据如下:
sheet1:
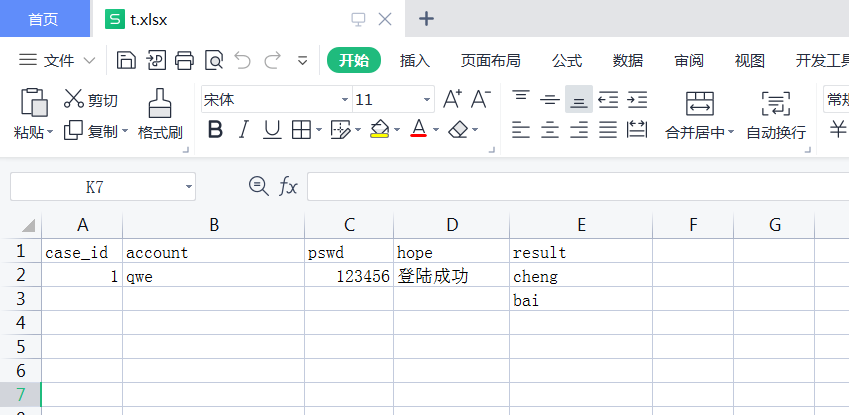
sheet2:
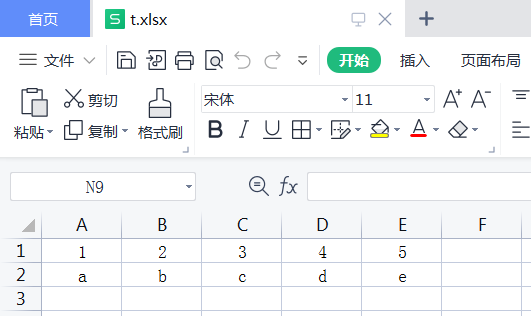
读取excel文件
pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None)
io:excel文件路径。
sheet_name:返回指定的sheet。
header:表头,默认值为0。也可以指定多行。当header取值为None时候data打印值最多,0相比None会少一行,1对比0又会在少一行。也就是说设置header为多少,那么那行之前的数据就会缺失。header也可以设置为一个范围值如header=[0, 1]表示前两行为多重索引。
usecols:读取指定的列。
skiprows:跳过特定行。
import pandas
a = pandas.read_excel("t.xlsx",sheet_name=0)#sheet_name可以使用下标,sheet的名称
print(a) #打印所有
print(a.values) #打印除第一行以外的信息
print(a.values[0]) #打印第一行的值
print(data['标题列'].values) #打印具体一列的值
#读取同一文件的不同sheet
data= pandas.read_excel("t.xlsx", ['Sheet1', 'Sheet2'])
print(data)#打印sheet1和sheet2的所有元素
print(data.get('Sheet1')['result'][0]) #打印sheet1表的result列的第一个元素
#sheet_name = None时,返回所有表的数据
data = pandas.read_excel("t.xlsx", sheet_name=None)
print(data)
结果:
"""
{'Sheet1': case_id account pswd hope result
0 1.0 qwe 123456.0 登陆成功 cheng
1 NaN NaN NaN NaN bai, 'Sheet2': 1 2 3 4 5
0 a b c d e}
"""
#sheet_name可以选择名称,下标组合方式提取多张表数据
data = pandas.read_excel("t.xlsx", sheet_name=['Sheet1',1])
print(data)
结果:
"""
{'Sheet1': case_id account pswd hope result
0 1.0 qwe 123456.0 登陆成功 cheng
1 NaN NaN NaN NaN bai, 1: 1 2 3 4 5
0 a b c d e}
"""
#查询指定列的数据
data = pandas.read_excel('t.xlsx', sheet_name='Sheet1', usecols=['result',])
print(data)
结果:
"""
result
0 cheng
1 bai
"""
data = pandas.read_excel('t.xlsx', sheet_name='Sheet1', usecols=[0])
print(data)
结果:
"""
case_id
0 1.0
1 NaN
"""
data = pandas.read_excel('t.xlsx', sheet_name='Sheet1', usecols=[0, 1])
print(data)
结果:
"""
case_id account
0 1.0 qwe
1 NaN NaN
"""ExcelFile:为了更方便地读取同一个文件的多张表格
import pandas
#同时读取一个文件的多个sheet,仅需读取一次内存,性能更好
data = pandas.ExcelFile("t.xlsx")
sheets = pandas.read_excel(data)#sheet_name不写,默认为查第一个sheet的数据
sheets = pandas.read_excel(data, sheet_name="Sheet2")#查看指定sheet的数据
print(sheets)
#也可以这么写
with pandas.ExcelFile("t.xlsx") as xlsx:
s1 = pandas.read_excel(xlsx, sheet_name="Sheet1")
s2 = pandas.read_excel(xlsx, sheet_name="Sheet2")
print(s1)
print("-----------------------")
print(s2)
结果:
"""
case_id account pswd hope result
0 1.0 qwe 123456.0 登陆成功 cheng
1 NaN NaN NaN NaN bai
-----------------------
1 2 3 4 5
0 a b c d e
""""""
index_col:索引对应的列,可以设置范围如[0, 1]来设置多重索引
na_values:指定字符串展示为NAN
"""
with pandas.ExcelFile('t.xlsx') as xls:
data['Sheet1'] = pandas.read_excel(xls, 'Sheet1', index_col=None,
na_values=['NA'])
data['Sheet2'] = pandas.read_excel(xls, 'Sheet2', index_col=1)
print(data)
print("-------------------------------")
print(data['Sheet1'])
print("--------------------------------")
print(data['Sheet2'])
结果:
"""
{'Sheet1': case_id account pswd hope result
0 1.0 qwe 123456.0 登陆成功 cheng
1 NaN NaN NaN NaN bai, 'Sheet2': 1 3 4 5
2
b a c d e}
-------------------------------
case_id account pswd hope result
0 1.0 qwe 123456.0 登陆成功 cheng
1 NaN NaN NaN NaN bai
--------------------------------
1 3 4 5
2
b a c d e
"""
写入文件:
将数据写入excel
1.当文件不存在时,会自动创建文件,并写入数据;
2.当文件存在时,会覆盖数据;
3.sheet_name 不写默认为Sheet1;
4.文件写入,切记关闭excel。
data = {'名字': ['张三','李四'],
'分数': [100, 100]
}
a= pandas.DataFrame(data)
a.to_excel('1.xlsx', sheet_name='Sheet1',index=False)# index = False表示不写入索引excel一次写入多sheet:
1.下面代码为在1.xlsx中写入sheet1,sheet2两个表。
2.可以通过在ExcelWriter中添加mode参数,该参数默认为w,修改为a的话,可以在已存在sheet的excel中添加sheet表。
df1 = pandas.DataFrame({'名字': ['张三', '王四'], '分数': [100, 100]})
df2 = pandas.DataFrame({'年龄': ['18', '19'], '性别': ['男', '女']})
with pandas.ExcelWriter('1.xlsx') as writer:
df1.to_excel(writer, sheet_name='Sheet1', index=False)
df2.to_excel(writer, sheet_name='Sheet2', index=False)
#新增一个sheet
df3 = pandas.DataFrame({'新增表': ['1', '2']})
with pandas.ExcelWriter('1.xlsx', mode='a') as writer:
df3.to_excel(writer, sheet_name='Sheet3', index=False)
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题