主要内容:
main函数其本声就是一个线程,在其中又可以启动别的线程和设置其对应的函数入口。
不管线程要执行的任务是复杂还是简单,其最终都要落实到标准库
std::thread my_thread((background_task()));
下面我写了一个验证程序来验证作者所说的这一种情况:
class background_task
{
public:
//函数转化操作符,将类转为函数对象
void operator()() const
{
cout<<"background_task's function convert"<<endl;
}
};
void func_inside_mythread()
{
cout<<"func_inside_mythread"<<endl;
}
//一个返回background_task对象的函数
background_task do_something()
{
cout<<"do somthing inside background_task"<<endl;
return background_task();
}
//这里便是引发编译器歧义的申明,这里既可以声明为thread对象的创建也可以是一个参数为返回background_task函数指针的函数
thread my_thread(background_task(*p)());
//如下便是对于上面t1的函数定义
thread my_thread(background_task(*p)())
{
(*p)();
cout<<"I am a function which get function pointer background_task"<<endl;
return thread(func_inside_mythread);
}
int main()
{
thread mt = my_thread(do_something);
mt.join();
return 0;
}
上面的t1就是引发编译器歧义的地方,也就是作者所举例说明的情况,下面来看一下执行结果:
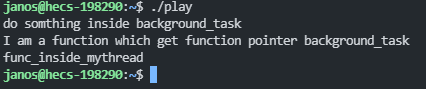
可以发现编译器把my_thread看作是了一个函数定义,但是实际上这里我传入的参数是故意给了一个具名的返回background_tast对象的p函数指针,实际上还可以这么写:
int main()
{
//1
thread my_thread(background_task());
//2
background_task f;
thread my_thread(f);
return 0;
}
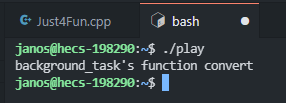
main里的第一句,其实按照语法上来讲,这里的backgroun_task类已经做过了函数类型转化的操作了,在这里正常时可以解释成我定义了一个thread线程对象,他接收可调用对象background_task函数,但是实际上通过vscode自带的提示器,将鼠标移动上去以后可以看见它仍然提示这是一个函数声明:

那如何解决上述问题呢?其实就是书上说的C11以后引入了新式的统一初始化语法,也叫列表初始化,像下面这样写就不存在编译器把这一行解释成函数的情况了(或者还可以直接传入lambda表达式做临时函数变量也能解决问题):
int main()
{
thread my_thread{background_task()};
my_thread.join();
return 0;
接下来作者说到了线程的分离和汇合,这里要总结一个概念:如果什么都不设置,thread对象析构时将自动终止线程程序,如果分离,就算thread对象已经彻底析构了,线程程序还在自己继续跑着。
这也接下来引发了第二个问题,即如果新线程的函数上持有指向主线程的变量或者数据的指针或引用时,但主线程运行退出后,新线程还没结束时,这个时候再访问那些指针的时候就是非法访问了,书配套代码如下:
#include <thread>
void do_something(int& i)
{
++i;
}
struct func
{
int& i;
func(int& i_):i(i_){}
void operator()()
{
//for(unsigned j=0;j<1000000;++j)
//这里为了复现非法访问的情况改成了无限循环
while(1)
{
do_something(i);
}
}
};
void oops()
{
int some_local_state=0;
func my_func(some_local_state);
std::thread my_thread(my_func);
my_thread.detach();
}
int main()
{
oops();
}
这里要引发的问题就在于,主线程detach以后结束了,自然局部变量得到释放,但是新增的线程仍然还在跑着,因为传的是引用类型,所以这个时候再去访问就是非法访问了,以下是我的运行结果,估计是Linux内部的什么机制,主线程一旦退出子线程随即也退出的场景我没有复现出来:
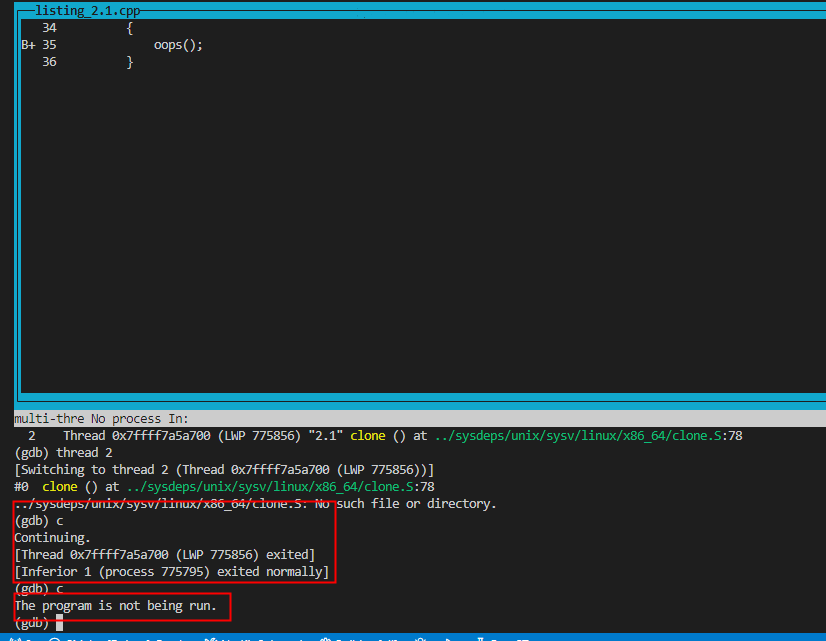
可以看见在gdb中切换到子进程以后输入c命令让程序自动运行,主线程775856先退出,随后子进程立刻也跟着退出了。
解决上述问题的方法作者也给了出来,主要是两点,一是让线程函数完全自含(self-contained),另一种是使用thread的join函数,确保子进程在父进程之前退出,也就是汇合线程操作。如果想要更加精细化地控制线程等待,则要到后面讲条件变量和future的时候继续学习,一旦调用了join,则这个线程相关的任何存储空间都将被立即删除。
接下来说到了在出现异常状况下的join等待,主要的问题在于当新线程启动以后,如果有异常抛出,但是这个时候join在异常的后面,这样join就得不到执行了略过了,先来看一下代码清单2.2中不用try-catch的情况:
#include <thread>
#include <iostream>
using namespace std;
void do_something(int& i)
{
++i;
}
struct func
{
int& i;
func(int& i_):i(i_){}
void operator()()
{
for(unsigned j=0;j<1000000;++j)
{
do_something(i);
}
}
};
void do_something_in_current_thread()
{
cout<<"do something error in current thread"<<endl;
}
void f()
{
int some_local_state=0;
func my_func(some_local_state);
std::thread t(my_func);
// try
// {
do_something_in_current_thread();
cout<< 3 / 0 <<endl;
//}
// catch(...)
// {
// t.join();
// throw;
// }
t.join();
}
int main()
{
f();
}
运行结果:通过gdb可以看到出现算术异常时,系统抛出了浮点运算错误,此时新线程2因为浮点错误直接终止了,但是此时主线程收到了子线程传过来的SIGFPE信号,也终止了:
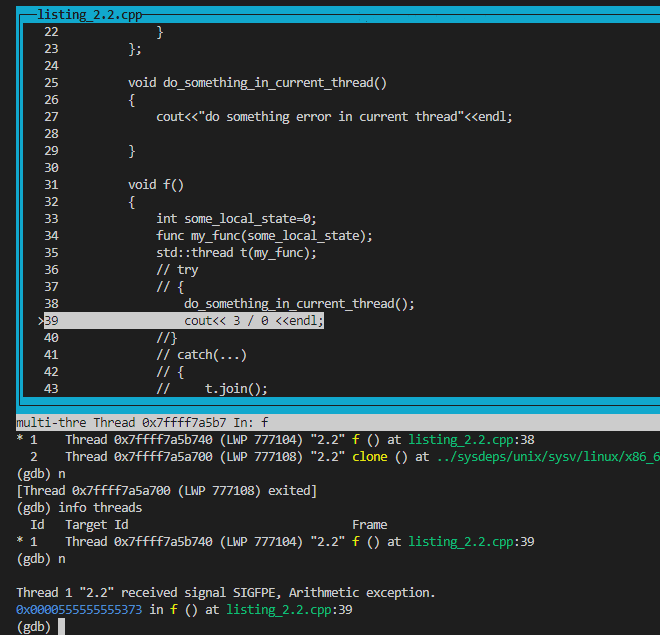
主线程随后也收到了该信号终止:
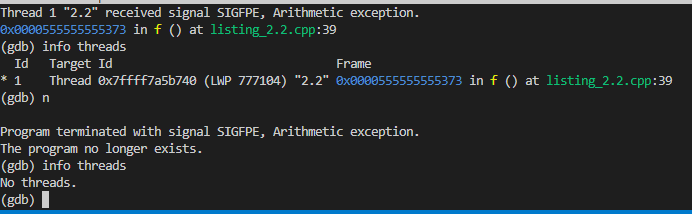
下面展示成功捕捉到异常然后汇合的场景:
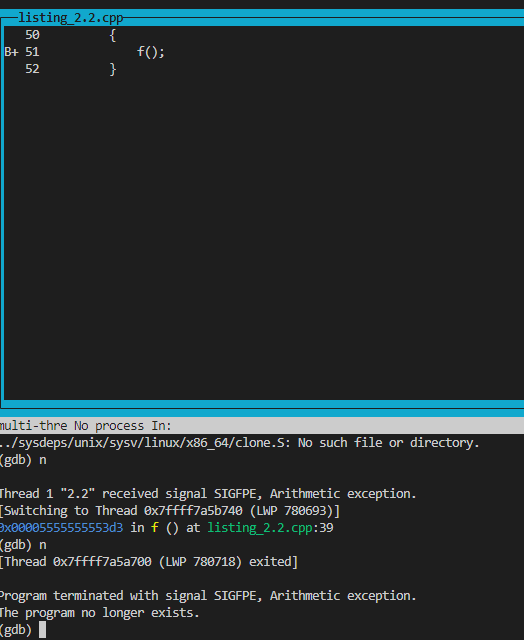
此处新线程在收到SIGFPE时,两个线程同时终止。上述的使用try-catch捕获异常的写法其实稍显冗余,更好的是使用标准RALL手法,如下面配套2.3代码:
#include <thread>
#include <iostream>
using namespace std;
class thread_guard
{
std::thread& t;
public:
explicit thread_guard(std::thread& t_):
t(t_)
{}
~thread_guard()
{
if(t.joinable())
{
cout<<"Prepare to join"<<endl;
t.join();
}
}
//=delete不允许系统生成自己的默认拷贝和等号运算符重载
thread_guard(thread_guard const&)=delete;
thread_guard& operator=(thread_guard const&)=delete;
};
void do_something(int& i)
{
++i;
}
struct func
{
int& i;
func(int& i_):i(i_){}
void operator()()
{
for(unsigned j=0;j<1000000;++j)
{
do_something(i);
}
}
};
void do_something_in_current_thread()
{}
void f()
{
int some_local_state;
func my_func(some_local_state);
std::thread t(my_func);
thread_guard g(t);
do_something_in_current_thread();
}
int main()
{
f();
}
这里的要点是,利用析构的顺序这个概念,thread_guard对象一定比thread对象t先析构,又用了RALL手法,所以一定可以汇合,不管后面出不出异常,以下是执行结果:
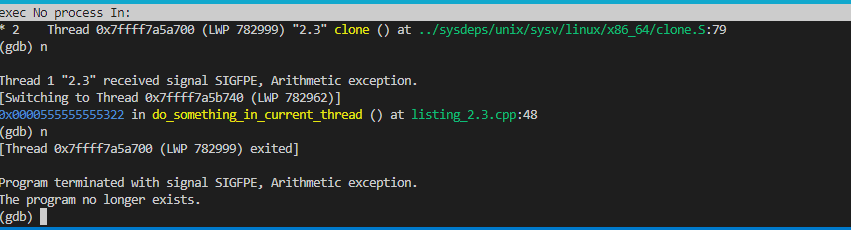
可以看出在线程2出现异常以后,主线程成功调用了join等待到了与2号线程汇合。
这一节主要讲了detach的用法以及一个模拟应用场景,提到了守护线程的概念:即和守护进程一样,被分离出去的线程完全在后台运行,其几乎存在于整个应用程序生命周期内。配套代码2.4给出了文字处理软件编辑多文件的多线程分离应用场景:
#include <thread>
#include <string>
void open_document_and_display_gui(std::string const& filename)
{}
bool done_editing()
{
return true;
}
enum command_type{
open_new_document
};
struct user_command
{
command_type type;
user_command():
type(open_new_document)
{}
};
user_command get_user_input()
{
return user_command();
}
std::string get_filename_from_user()
{
return "foo.doc";
}
void process_user_input(user_command const& cmd)
{}
void edit_document(std::string const& filename)
{
open_document_and_display_gui(filename);
//while(!done_editing())
for(int i = 0 ;i < 3 ;i++)
{
user_command cmd=get_user_input();
if(cmd.type==open_new_document)
{
std::string const new_name=get_filename_from_user();
std::thread t(edit_document,new_name);
t.detach();
}
else
{
process_user_input(cmd);
}
}
}
int main()
{
edit_document("bar.doc");
}
主要是模拟多线程处理过程,这里就跳过执行结果了。
首先总结一个概念:线程的内部是有存储空间的,任何传递给线程的函数参数都会默认先被复制到该处,随后新线程才能访问他们,再然后这些副本被当做右值传给线程上的可调用对象。
上述的概念引出了书中说的第一个错误,示例如下:
void f(int i,std::string const& s);
void oops(int some_param)
{
char buffer[1024]; // ⇽--- ①
sprintf(buffer, "%i",some_param);
std::thread t(f,3,buffer); // ⇽--- ②
t.detach();
}
这里的问题在于,因为thread的构造函数需要原样复制所提供的值,然后再转换成可调用对象参数的预期类型,所以有可能oops在这个复制过程中先行崩溃或者退出,导致局部变量buffer被销毁而引发未定义的行为,所以作者提出的解决办法是先给他手工转成string:
std::string(buffer)
然后再传进去就行了。
另一个场景刚好相反,也就是我们期望参数类型是非const引用,而岸上上述的thread构造概念,整个对象却被完全复制了一遍,这个是不合理的情况,编译也过不了,这里作者没给出示例代码,我写了一段验证之:
#include <thread>
#include <iostream>
#include <condition_variable>
#include <queue>
#include <mutex>
#include <stdlib.h>
#include <string.h>
using namespace std;
struct widget_id
{
int id;
};
struct widget_data
{
};
void update_data_for_widget(widget_id w, widget_data & data)
{
}
void oops_again(widget_id w)
{
widget_data data;
//正确情况
//thread t(update_data_for_widget,w,ref(data));
//非正确,编译错误
thread t(update_data_for_widget,w,data);
t.join();
}
int main()
{
oops_again(widget_id());
return 0;
}
编译错误显示如下:
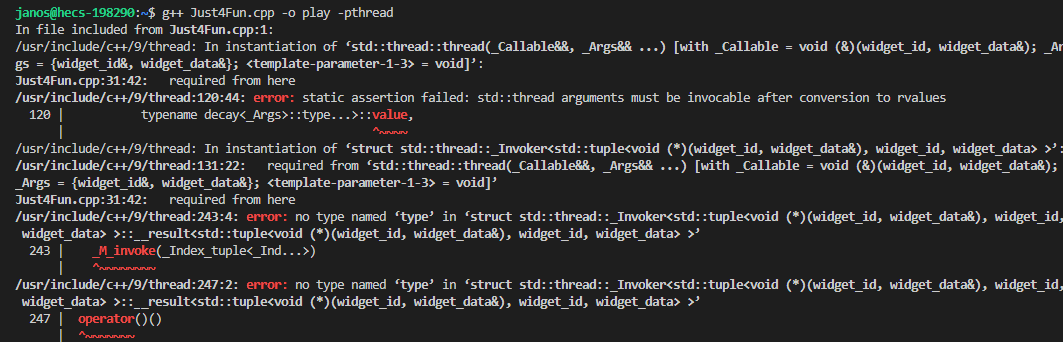
这里的解决方案是利用标准的std::ref函数做一层包装,把它强制转成左值引用传入,这里其实内部还有的讲(即为什么ref之后就会忽略thread构造本身需要复制一遍的事实呢?这里其实是内部用forward实现了完美转发),引用类型按照原先的类型传递到了线程的可调用对象参数列表中。
bind函数和thread构造的参数传递机制其实很相似,下一部分作者提到了如何将一个类的非静态成员函数最为thread的调用对象的,其原理译者在下方1号注释中做了说明。
如果thread对象正在管理一个线程,就不能简单地向他赋新值,否则新线程会因此被遗弃。这一节主要讲的是移动语义和线程归属权相互移交的过程,代码清单2-5展示了从函数内部返回thread对象,清单2-6和之前的2-3很相似,只不过在构造函数用了移动语义直接去构造要接管的thread对象,以及本来要引入C17的joining_thread类,这里就不做展示和演示了。
清单2.7展示了线程管控自动化切分的简单实现,用vector管理了一堆线程:
#include <vector>
#include <thread>
#include <algorithm>
#include <functional>
void do_work(unsigned id)
{}
void f()
{
std::vector<std::thread> threads;
for(unsigned i=0;i<20;++i)
{
threads.push_back(std::thread(do_work,i));
}
std::for_each(threads.begin(),threads.end(),
std::mem_fn(&std::thread::join));
}
int main()
{
f();
}
这里使用了标准的mem_fn,返回一个指向其参数函数的函数指针用于foreach遍历。
这章简单实现了一个并行版本的accumulate,无特别说明,看懂代码和说明即可。
主要介绍了线程id,如何获取它(调用thread.get_id),获取当前线程的方法(this_thread)以及标准库对其实现了全面的比较运算符支持。
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我正在尝试使用ruby编写一个双线程客户端,一个线程从套接字读取数据并将其打印出来,另一个线程读取本地数据并将其发送到远程服务器。我发现的问题是Ruby似乎无法捕获线程内的错误,这是一个示例:#!/usr/bin/rubyThread.new{loop{$stdout.puts"hi"abc.putsefsleep1}}loop{sleep1}显然,如果我在线程外键入abc.putsef,代码将永远不会运行,因为Ruby将报告“undefinedvariableabc”。但是,如果它在一个线程内,则没有错误报告。我的问题是,如何让Ruby捕获这样的错误?或者至少,报告线程中的错误?
我是ruby的新手,我认为重新构建一个我用C#编写的简单聊天程序是个好主意。我正在使用Ruby2.0.0MRI(Matz的Ruby实现)。问题是我想在服务器运行时为简单的服务器命令提供I/O。这是从示例中获取的服务器。我添加了使用gets()获取输入的命令方法。我希望此方法在后台作为线程运行,但该线程正在阻塞另一个线程。require'socket'#Getsocketsfromstdlibserver=TCPServer.open(2000)#Sockettolistenonport2000defcommandsx=1whilex==1exitProgram=gets.chomp
我有一个使用PDFKit呈现网页的pdf版本的Rails应用程序。我使用Thin作为开发服务器。问题是当我处于开发模式时。当我使用“bundleexecrailss”启动我的服务器并尝试呈现任何PDF时,整个过程会陷入僵局,因为当您呈现PDF时,会向服务器请求一些额外的资源,如图像和css,看起来只有一个线程.如何配置Rails开发服务器以运行多个工作线程?非常感谢。 最佳答案 我找到的最简单的解决方案是unicorn.geminstallunicorn创建一个unicorn.conf:worker_processes3然后使用它:
有没有办法跳过CSV文件的第一行,让第二行作为标题?我有一个CSV文件,第一行是日期,第二行是标题,所以我需要能够在遍历它时跳过第一行。我尝试使用slice但它会将CSV转换为数组,我真的很想将其读取为CSV,以便我可以利用header。 最佳答案 根据您的数据,您可以使用另一种方法和skip_lines-option此示例跳过所有以#开头的行require'csv'CSV.parse(DATA.read,:col_sep=>';',:headers=>true,:skip_lines=>/^#/#Markcomments!)do|
所以,Ruby1.9.1现在是declaredstable.Rails应该与它一起工作,并且正在慢慢地将gem移植到它。它具有native线程和全局解释器锁(GIL)。自从GIL到位后,原生线程是否比1.9.1中的绿色线程有任何优势? 最佳答案 1.9中的线程是原生的,但它们被“放慢了速度”,一次只允许一个线程运行。这是因为如果线程真的并行运行,它会混淆现有代码。优点:IO现在在线程中是异步的。如果一个线程阻塞在IO上,那么另一个线程将继续执行直到IO完成。C扩展可以使用真正的线程。缺点:任何非线程安全的C扩展都可能存在使用Thre
我在一个ruby文件中有一个函数可以像这样写入一个文件File.open("myfile",'a'){|f|f.puts("#{sometext}")}这个函数在不同的线程中被调用,使得像上面这样的文件写入不是线程安全的。有谁知道如何以最简单的方式使这个文件写入线程安全?更多信息:如果重要的话,我正在使用rspec框架。 最佳答案 您可以通过File#flock给锁File.open("myfile",'a'){|f|f.flock(File::LOCK_EX)f.puts("#{sometext}")}
我编写了几个类来控制我想如何处理多个网站,两者都使用类似的方法(即登录、刷新)。每个类都打开自己的WATIR浏览器实例。classSite1definitialize@ie=Watir::Browser.newenddeflogin@ie.goto"www.blah.com"endend无线程的main中的代码示例如下require'watir'require_relative'site1'agents=[]agents这工作正常,但在当前代理完成登录之前不会移动到下一个代理。我想合并多线程来处理这个问题,但似乎无法让它工作。require'watir'require_relative
代码:threads=[]Thread.abort_on_exception=truebegin#throwexceptionsinthreadssowecanseethemthreadseputs"EXCEPTION:#{e.inspect}"puts"MESSAGE:#{e.message}"end崩溃:.rvm/gems/ruby-2.1.3@req/gems/activesupport-4.1.5/lib/active_support/dependencies.rb:478:inload_missing_constant':自动加载常量MyClass时检测到循环依赖稍加研究后,
任何人都可以推荐任何详细介绍Ruby多线程/多处理的复杂性的好的多线程/处理书籍/网站吗?我尝试使用ruby线程,基本上在1.9vm上的无死锁代码中它在jruby中遇到了死锁。是的,我意识到差异很大(jruby没有GIL),但我想知道是否有用于ruby中多线程编程的策略或类集,我只需要继续阅读。旁注:从java到ruby必须定义是否需要重新输入锁,这有点奇怪。 最佳答案 如果你使用Ruby1.9,你可以试试Fiber,它是Ruby中线程的一大改进http://ruby-doc.org/core-1.9/classes/F