专业阵列介绍(不是FS):
一个交换机上连有几个CNA和一个VRM,CNA连接着SAN交换机,SAN交换机连着专业的Array阵列,它是由一个控制框和几个硬盘框组成的。控制框如果是双控制器的话(双活控制),那么它有两个控制器A和B,控制器后面都有几个接口,两个控制器分别有一个接口网线连接到SAN交换机,可能是通过FC也可能是FCoE也可能是10G的以太网。控制框还有两个电源接口,如果两路电源都突然断电了的话,还有一个后备电源(叫后备电源模块),它可以供电5-10分钟,让控制框可以暂时性的把阵列中的控制器中的缓存中的数据写到项目盘里去。所以阵列的数据绝对可靠。然后不管是控制框还是硬盘框的硬盘都是做RAID2.0(可以坏一块硬盘)。
如果担心这个阵列的机房出问题,那么可以再另外一个数据中心再部署一个SAN交换机与前一个交换机连接起来,然后再布置一个阵列,通过双活特性将它们连接起来。(这个阵列和前一个阵列的LUN一模一样)
阵列的可靠性非常高、可用性非常好、成本非常高、当使用它的主机虚拟机非常多的时候就出现瓶颈。(阵列的框有多大,容量就只有多大)
FusionStorage:①是一套软件的存储解决方案。(软件定义存储 华为自研) 灵活性好
②它先把服务器组织在一起,再把服务器上的硬盘组织在一起。
它就是每个linux服务器上装上FS软件,然后用交换机连起来。特点就是硬盘多了点。
它是利用软件把服务器组织起来的方案。

FusionStorage现在能提供三种存储:
①block(块)存储 =Array(SCSI) 在企业中(企业用户)用的多(容量小、价值密度高)
②object(对象)存储 (Restful/http) 在互联网上(互联网用户)用的多(容量大、价值密度低)
③文件存储(NAS(CIFS、NFS)) 分布式文件系统(DFS)
FS特点:
①价格低
②扩展性好
③容量大
④部署方便
⑤性能优
副本机制(FS的):如果有12块盘,每块盘100M,那么一共就有1200M的存储可以用。如果是2副本的话,有效数据只有600M;如果是3副本的话,有效数据只有400M。(空间利用率低、FS成本低) 冗余数据 牺牲了成本换来了高可靠
RAID(阵列的):RAID5至少3块盘,每块盘1G,硬盘总容量3G,有效数据2G。
(1)认识Server SAN
1. 概念
(1)由多个独立服务器自带的存储(硬盘:SAS机械盘、固态盘)组成一个存储资源池,同时融合了计算和存储资源。
融合计算和存储资源:
例:一台CNA服务器,上面是计算资源,然后中间是hypervisor,下面是存储。假设它有15块盘,拿出2块盘做RAID1(镜像)就是系统盘(计算),剩下的13块盘就是存储池(FS)。
2. 特征
(1)专有设备变通用设备
(2)计算与存储线性扩展
计算节点增加的时候说明IO数量越多,存储需求越大,存储(服务器)也跟着扩容。
(3)简单管理、低TCO(低成本)
(2)华为Server SAN产品FusionStorage
1. 分布式块存储软件
2. 将通用X86服务器的本地HDD、SSD等介质通过分布式技术组织成大规模存储资源池
3. 对非虚拟化环境的上层应用和虚拟机提供工业界标准的SCSI和iSCSI接口(只要是块存储就一定是块访问协议(SCSI协议)。)
4. 开放的API(可以做其他的开发)

(3)传统SAN架构
阵列1(四活四控) 阵列2(四活四控)

1. 机头(控制器、引擎)瓶颈:双控~16控,且无法线性扩展
2. Cache(电脑高速缓冲存储器)瓶颈:通常为GB
硬盘框是机械盘。
每个控制器里一个Cache。
允许在控制框里插入硬盘,做二级Cache(可扩)。
在控制器里放上缓存,它直接写到Cache里去,然后返回主机写ok,就写完了(主机把数据写到控制器的Cache里去,主机就写完了,然后主机去忙别的作业处理别的IO去了)。然后控制器利用其他时间,控制器把IO的数据落盘,通过移步的方式,把缓存数据移到硬盘。
3. 网络瓶颈:10GE、8G FC
(4)分布式Server SAN架构

每台服务器都有每台服务器的Cache。最多能有4096台服务器。
假设每台服务器内部都有15块盘,这个15块盘独享这台服务器内部的Cache(这Cache是SSD固态盘)。假设是10G的网。每台服务器独享10G的网口。所以服务器的数量越多,每台服务器的Cache容量也在增大。(每台服务器上有5G的Cache:5G*4096(Cahce的容量))
上面的服务器是计算节点,在每个节点中装入FS软件和OS,(软件(模拟))SCSI接口(软的块接口)(软件机头、软件控制器)在这每台服务器上。不管每个服务器上有多少个虚拟机,它们都通过这台服务器上的机头独享10G。(分布的IO访问:每台服务器都有自己独立的块接口)
假设计算的某一台服务器上有一台虚拟机,它以为它的磁盘就在这台服务器上,但事实上都是分片访问到存储池中多台服务器上了。(好处:IO在访问存储池时,每个IO并行访问不同的存储服务器。这种并发吞吐比阵列优。)
FusionStorage支持万兆以太网。
1. 分布式控制器,可线性扩展至4096节点
2. 分布式Cache,扩展至TB级
3. P2P无阻塞高速IB网络,56G InfiniBand RDMA
(5)存储发展趋势:分布式存储快速增长

(1)华为FusionStorage两大主要应用场景

(2)华为FusionStorage方案选择参考

(1)FusionStorage销售版本

1. 标准版适用于建立大规模块存储资源池,提供标准的块存储数据访问接口,支持各种虚拟化Hypervisor平台和各种业务应用,按需分配存储资源
2. 高级版支持IB(RMDA)和SSD做主存,适用于企业关键IT基础设施
3. 两种版本使用时需要license,销售量纲是per TB
(2)FusionStorage兼容性——硬件&软件
1. 硬件兼容性主要包括:
(1)服务器
(2)HDD盘,SSD盘,PCIE SSD卡/盘
(3)RAID卡,以太网卡, Infiniband卡
2. 软件兼容性主要包括:
(1)虚拟化平台
(2)操作系统
(3)数据库软件
(3)FusionStorage技术规格参数

(2)FusionStorage部署方式
1. 融合部署
(1)指的是将VBS和OSD部署在同一台服务器中
(2)虚拟化应用推荐采用融合部署的方式部署
不足:计算与存储资源争用。
2. 分离部署
(1)指的是将VBS和OSD分别部署在不同的服务器中
(2)高性能数据库应用则推荐采用分离部署的方式
答:第一,虚拟化是使用集群技术的计算节点的集合,集群规模可以无限扩大,可以和存储集群融合在一起,一台计算节点同时提供存储资源。 第二, 计算集群同时也是存储集群。节省服务器数量,虚拟化资源池同时也是计算和存储的合体。


服务器1、2、3也可以只有一个网口,FSM一样可以通过中间那(平面)条横线到达。
(1)FusionStorage备份方案


(2)FusionStorage容灾方案


SSD
SAS 15K
SATA
NL-SAS:Nearline近线 SAS接口+SATA片
优选顺序:①SSD②SAS 15K③NL-SAS④SATA
存储服务器:机械盘(SAS)当主存的情况下,必须有缓存(Cache)(速度快)。(写入数据时,先进入缓存,缓存再慢慢调给主存。)
固态盘当主存的情况下,可以没有缓存。
(1)基础概念
1. DHT: Distributed Hash Table(分布式哈希表/环),FusionStorage中指数据路由算法。
头:P0 尾:P(2^32)-1 线长=2^32=4G
2. Partition:代表了一块数据分区,DHT环上的固定Hash段代表的数据区。(最多3600分区(段))
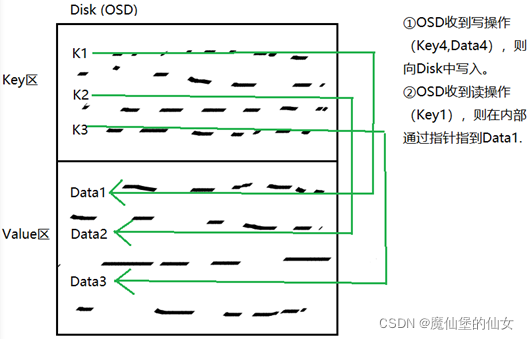
3. Key-Value(键值):底层磁盘上的数据组织成Key-Value的形式(数据组织形式),每个Value代表一个块存储空间
每个IndexID(Key)对应一个Data。
哈希函数特点:Y=Hash(X) (Y:output X:input)
(1)不管输入的X多大(任意值),哈希函数得出的Y一定在0~(2^32)-1范围内(Y值一定在环内)。 哈希函数把任意数映射到这段数内。
(2)不可逆


4. 资源池:FusionStorage中一组分区(partition)构成的存储池,对应到DHT环
5. Volume:应用卷,代表了应用看到的一个LBA连续编址
资源池中有卷,卷在资源池中。

6. 数据副本: FusionStorage采用数据多副本备份机制来保证数据的可靠性,即同一份数据可以复制保存为2~3个副本

(2)FusionStorage数据路由原理
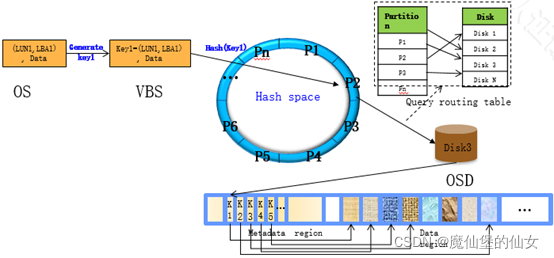
1. FusionStorage数据路由采取分层处理方式(两级定位数据位置):
(1)VBS通过计算确定数据存放在哪个服务器的哪块硬盘上
(2)OSD通过计算确定数据存放在硬盘的具体位置
1)VBS通过SCSI方式收到Data(2M)。
2)分解(Data1—Key1,Data2—Key2)key-value
3)存在哪里?计算出位置(place)。
把hash(Key1)àDHTàpartition 2
hash(Key2)àDHTàpartition 4
4)Partition视图:partition与Disk的对照表。
Key1: Partition2àServer1. D1
Key2: Partition4àServer5. D3
IP Port(TCP)

场景:实验演示

一个存储池一个哈希环DHT。
(1)FusionStorage VBS模块及处理流程
1. VBS模块作为FusionStorage系统存储功能的接入侧,负责完成两大类业务:
(1)卷和快照的管理功能
(2)IO的接入和处理
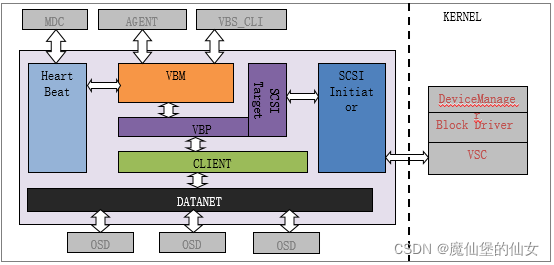
(3)VBM模块负责完成卷和快照的管理功能:创建卷、挂载卷、卸载卷、查询卷、删除卷、创建快照、删除快照、基于快照创建卷等
(2)FusionStorage OSD模块及处理流程
1. FusionStorage存储池管理的每个物理磁盘对应一个OSD进程,OSD负责:
(1)磁盘的管理
(2)IO的复制
(3)IO数据的Cache处理

(3)FusionStorage OSD模块磁盘数据分区
1. 磁盘的每一个1M空间都固定的分配给一个key,一定数量连续的key组成一个chunk
2. Chunk:一个Partition的存储空间由1个或多个Chunk构成

(4)VDB(Key-Value DB)

(5)FusionStorage MDC模块功能
1. MDC(Metadata Controller):元数据控制器。是一个高可靠集群(3、5、7……奇数),通过HA(High Availability)机制保证整个系统的高可用性和高可靠性:
(1)通过ZooKeeper集群,实现元数据(如Topology、OSD View、Partition View、VBS View等)的可靠保存
(2)通过Partition分配算法,实现数据多份副本的RAID可靠性
(3)通过与OSD、VBS间的消息交互,实现对OSD、VBS节点的状态变化的获取与通知
(4)通过与Agent间的消息交互,实现系统的扩减容、状态查询、维护等
(5)通过心跳检测机制,实现对OSD、VBS的状态监控
2. Zookeeper(简称ZK) 分布式服务框架主要用来解决分布式应用中经常遇到的,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等,ZK主要工作包括三项:
(1)MDC主备管理: MDC采用一主两备部署模式;在MDC模块进程启动后,各个MDC进程会向ZK注册选主,先注册的为主MDC;运行过程中,ZK记录MDC主备信息,并通过心跳机制监控MDC主备健康状况,一旦主MDC进程故障,会触发MDC重新选主
(2)数据存储:在MDC运行过程中,会生成各种控制视图信息,包括目标视图、中间视图、IO视图信息等,这些信息的保存、更新、查询、删除操作都通过ZK提供的接口实现
(3)数据同步:数据更新到主ZK,由主ZK自动同步到两个备ZK,保证主备ZK数据实时同步。一旦ZK发生主备切换,业务不受影响
(6)FusionStorage 视图
1. IO View:partition主和osd节点的映射关系。
2. Partition View:partition主备对应的osd关系,ioview是partitionview的子集。
3. MDC通过心跳感知OSD的状态;OSD每秒上报给MDC特定的消息(比如:OSD容量等),当MDC连续在特定的时间内(当前系统为5s)没有接收到OSD的心跳信息,则MDC认为该OSD已经出故障(比如:OSD进程消失或OSD跟MDC间网络中断等),MDC则会发送消息告知该OSD需要退出,MDC更新系统的OSD视图并给每台OSD发送视图变更通知,OSD根据新收到的视图,来决定后续的操作对象。
4. 多副本复制取决于MDC的视图;两副本情况下,当client发送一个写请求到达该OSD的时候,该OSD将根据视图的信息,将该写请求复制一份到该Partition的备OSD。多副本情况下,则会复制发送多个写请求到多个备OSD上。

(7)FusionStorage 主要模块交互关系
1. 系统启动时,MDC与ZK互动决定主MDC。主MDC与其它MDC相互监控心跳,主MDC决定某MDC故障后接替者。其它MDC发现主MDC故障又与ZK互动升任主MDC
2. OSD启动时向MDC查询归属MDC,向归属MDC报告状态,归属MDC把状态变化发送给VBS。当归属MDC故障,主MDC指定一个MDC接管,最多两个池归属同一个MDC
场景:假设现在有个资源池内有四台服务器,其中三台有MDC,如果现在又多了一个资源池OSD启动,那么第四台服务器会出现一个这个OSD的归属MDC。。(每多一个存储池会再MDC集群服务器上创建一个MDC进程,这个MDC是该存储池的归属MDC,降低MDC集群的压力,负责该存储池的维护,该MDC会把数据写到相应MDC集群里去。)
3. VBS启动时查询主MDC,向主MDC注册(主MDC维护了一个活动VBS的列表,主MDC同步VBS列表到其它MDC,以便MDC能将OSD的状态变化通知到VBS),向MDC确认自己是否为leader;VBS从主MDC获取IO View,主VBS向OSD获取元数据,其它VBS向主VBS获取元数据

(8)FusionStorage弹性扩展
1. FusionStorage的分布式架构具有良好的可扩展性,支持超大容量的存储
2. 扩容存储节点后不需要做大量的数据搬迁,系统可快速达到负载均衡状态
3. 支持灵活扩容计算节点、硬盘、存储节点,或者同时进行扩容
4. 机头、存储带宽和Cache都均匀分布到各个节点上,系统IOPS、吞吐量和Cache随着节点扩容线性增加

(9)FusionStorage快速数据重建
1. FusionStorage中的每个硬盘都保存了多个DHT分区(Partition),这些分区的副本按照策略分散在系统中的其他节点。当FusionStorage检测到硬盘或者节点硬件发生故障时,自动在后台启动数据修复
2. 由于分区的副本被分散到多个不同的存储节点上,数据修复时,将会在不同的节点上同时启动数据重建,每个节点上只需重建一小部分数据,多个节点并行工作,有效避免单个节点重建大量数据所产生的性能瓶颈,对上层业务的影响做到最小化

(10)FusionStorage Cache写机制
1. OSD在收到VBS发送的写IO操作时,会将写IO缓存在SSD cache后完成本节点写操作
2. OSD会周期将缓存在SSD cache中的写IO数据批量写入到硬盘,写Cache有一个水位值,未到刷盘周期超过设定水位值也会将Cache中数据写入到硬盘中
3. FusionStorage支持大块直通,按缺省配置大于256KB的块直接落盘不写Cache,这个配置可以修改
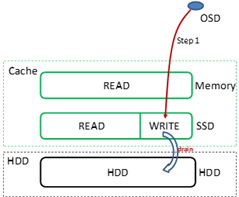
HDD:机械盘
(11)FusionStorage Cache读机制
1. FusionStorage的读缓存采用分层机制,第一层为内存cache,内存cache采用LRU机制缓存数据
2. 第二层为SSD cache,SSD cache采用热点读机制,系统会统计每个读取的数据,并统计热点访问因子,当达到阈值时,系统会自动缓存数据到SSD中,同时会将长时间未被访问的数据移出SSD
3. FusionStorage预读机制,统计读数据的相关性,读取某块数据时自动将相关性高的块读出并缓存到SSD中

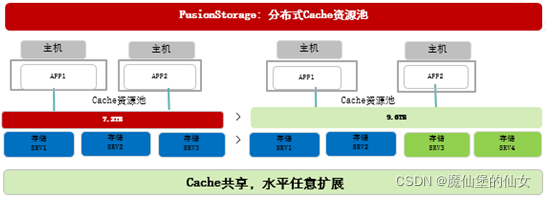
(12)FusionStorage 分布式Cache
1. FusionStorage集群内各服务器节点的缓存和带宽都均匀分布到各个服务器节点上,不存在独立存储系统中大量磁盘共享计算设备和存储设备之间有限带宽的问题
2. FusionStorage支持将服务器部分内存用作读缓存,NVDIMM和SSD用作写缓存,数据缓存均匀分布到各个节点上,所有服务器的缓存总容量远大于采用外置独立存储的方案。即使采用大容量低成本的SATA硬盘,FusionStorage仍然可以发挥很高的IO性能,整体性能提升1~3倍
3. FusionStorage支持SSD用作数据缓存,除具备通常的写缓存外,增加热点数据统计和缓存功能,加上其大容量的优势,进一步提升了系统性能
(13)FusionStorage SSD存储与Infiniband网络
1. SSD存储介质:
(1)通过在存储节点上配置SSD盘或PCI-E SSD卡,FusionStorage可以将存储节点上的SSD组成1个虚拟存储资源池,为应用提供高性能读写能力
2. Infiniband高速网络:
(1)56Gbps FDR InfiniBand,节点间超高速互联
(2)标准成熟多级胖树组网,平滑容量扩容
(3)近似无阻塞通信网络,数据交换无瓶颈
(4)纳秒级通信时延,计算存储信息及时传递
(5)无损网络QOS,数据传送无丢失
(6)主备端口多平面通信,提高传输可靠性
(14)FusionStorage掉电保护
1. 系统运行过程中可能会出现服务器突然掉电的情况,FusionStorage使用保电介质来保存元数据和缓存数据,以防掉电而丢失
2. FusionStorage支持的保电介质为NVDIMM内存条(持久化保存,能做持久化数据存储)或SSD。程序运行过程中会把元数据和缓存数据写入保电介质中,节点异常掉电并重启后,系统自动恢复保电介质中的元数据和缓存数据

(1)FusionStorage 读IO流程
1. APP下发读IO请求到OS,OS转发该IO请求到本服务器的VBS模块;VBS根据读IO信息中的LUN和LBA信息,通过数据路由机制确定数据所在的Primary OSD;如果此时Primary OSD故障,VBS会选择secondary OSD读取所需数据
2. Primary OSD接收到读IO请求后,按照Cache机制中的“Read cache机制”获取到读IO所需数据,并返回读IO成功给VBS

(2)FusionStorage 写IO流程
1. APP下发写IO请求到OS,OS转发该IO请求到本服务器的VBS模块;VBS根据写IO信息中的LUN和LBA信息,通过数据路由机制确定数据所在的Primary OSD
2. Primary OSD接收到写IO请求后,同时以同步方式写入到本服务器SSD cache以及数据副本所在其他服务器的secondary OSD,secondary OSD也会同步写入本服务器SSD cache。Primary OSD接收到两个都写成功后,返回写IO成功给VBS;同时,SSD cache中的数据会异步刷入到硬盘
3. VBS返回写IO成功,如果是3副本场景,primary OSD会同时同步写IO操作到secondary OSD和third OSD

(3)FusionStorage 数据处理过程

(1)FusionStorage分布式存储软件总体框架

FS参与的盘越多,并发的就越多,性能就越好。
集群故障自愈:一个key-value成为partition存在一主一备两个OSD上,现在备OSD坏了,MDC会自动又找一个备OSD存上去。
其中某块盘坏了,管理员就拔下来换上新空白盘。
FusionStorage(非虚拟化存储):
①支持快照特性
②精简配置磁盘
③链接克隆(比虚拟化数据存储能力强,虚拟化数据存储一个母盘最多链接克隆128个差分盘,FS的一个母卷最多链接克隆2048个)
(2)FusionStorage块存储功能 - SCSI/iSCSI块接口
1. FusionStorage通过VBS以SCSI或iSCSI方式提供块接口:
(1)SCSI方式:安装VBS的物理部署、FusionSphere或KVM等采用SCSI方式
(2)iSCSI方式:安装VBS以外的虚拟机或主机提供存储访问,VMware、MS SQL Server集群采用iSCSI模式。走TCP、IP的。
SCSI和iSCSI都是业务平面。
用的SCSI还是iSCSI方式只跟VBS有关系。(没有IP的内部访问走SCSI,有IP的互访走iSCSI。)
(1)应用想要用计算资源先找OS内核,内核去找VBS用的SCSI方式。
(2)
1)应用服务器(SCSI启动器)去另一台服务器上找VBS(SCSI目标器)(软件机头)用的IP/TCP的SCSI方式(块接口)。
2)图二:硬盘直射到CVM虚拟机(裸设备映射RDM),VBS与iSCSI目标器之间IP可达。


(3)FusionStorage精简配置功能

1. 相比传统方式分配物理存储资源,精简配置可显著提高存储空间利用率
2. FusionStorage天然支持自动精简配置,和传统SAN相比不会带来性能下降
(4)FusionStorage快照功能
1. FusionStorage快照机制,将用户卷数据在某个时间点的状态保存下来,可用作导出数据、恢复数据之用
2. FusionStorage快照数据在存储时采用ROW(Redirect-On-Write)机制,快照不会引起原卷性能下降
3. 无限次快照:快照元数据分布式存储,水平扩展,无集中式瓶颈,理论上可支持无限次快照
4. 卷恢复速度快:无需数据搬迁,从快照恢复卷1S内完成(传统SAN在几小时级别)

(5)FusionStorage链接克隆功能
1. FusionStorage支持一个卷快照创建多个克隆卷,对克隆卷修改不影响原始快照和其它克隆卷
2. 克隆卷继承普通卷所有功能:克隆卷可支持创建快照、从快照恢复及作为母卷再次克隆操作
3. 支持批量进行虚拟机卷部署,在1秒时间内创建上百个虚拟机卷
4. 支持1:2048的链接克隆比,提升存储空间利用率

(6)FusionStorage自定义存储SLA
1. 根据业务诉求,用户可自定义多种资源池SLA规格
2. 同一个虚拟机的不同的数据卷可归属不同的存储池

(7)FusionStorage跨资源池的卷冷迁移
1. 跨资源池卷冷迁移:把卷从源资源池 迁移到目的资源池,即【创建目标卷】 à 【卷数据复制】 à【删除源卷】 à【目标卷改名】 à【完成】整个过程的实现
(1)迁移过程中,源卷不能有写数据的操作,所以叫做“冷”迁移
(2)亦可通过工具调用复制接口
2. 场景1:资源池之间的容量平衡,容量满的池迁移到一个空闲的池。
3. 场景2:卷在不同性能的资源池之间的迁移,从低性能的池向高性能的池迁移

(1)FusionStorage跨服务器故障容忍
1. 数据可靠是第一位的,FusionStorage建议3副本配置部署
2. Google,facebook的副本数>=3副本
3. 左侧双故障节点情况,为3副本情形下
4. 如果服务器在同一个机柜,无法抗拒机柜整体断电断网等故障类型

(2)FusionStorage跨机柜故障容忍
FS添加服务器时的图。

创建存储资源池的图。
若选择服务器级别(2副本),则不允许2台服务器同时出故障。
若选择机柜级别(2副本),2个机柜很难同时挂掉(不放在同一机房)。
1. 机柜间要求有独立网络和电力供应
2. 如果机柜整体在同一个机房,无法抗拒机房整体断电断网,自然灾害等故障类型
3. 小于12台服务器不能使用机柜级安全
4. 超过64台服务器,必须使用机柜级安全

场景:

机柜级别这样规划:

这种情况下,一个机柜挂掉,其他机柜没挂数据依旧存在。
(3)FusionStorage跨机房故障容忍

(4)FusionStorage跨机房数据访问及流动
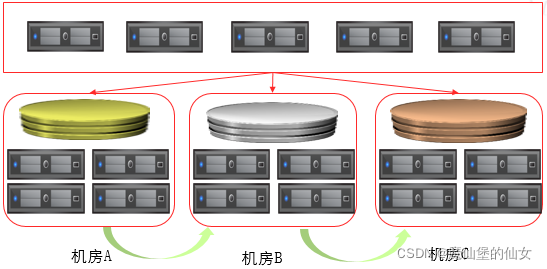
1. 支持数据跨机房访问
2. 支持数据卷从一个资源池迁移到另一个存储池,应用可以不修改
(1)VAAI-Copy offload

1. Copy Offload:拷贝虚拟磁盘文件的操作,比如虚拟机克隆或通过模板部署新的虚拟机,可以通过阵列离线进行的方式实现硬件加速,而不是在ESX服务器端进行文件级的拷贝操作。这种技术同样可以应用于Storage vMotion功能,将一个虚拟机的数据从一台存储移动到另一台
(2)VAAI-Block Zeroing

1. Block Zeroing:在所有虚拟磁盘初始写入之前,必须进行清零操作,在该格式化过程中,大量的零数据从ESX/ESXi主机发送到要清零的阵列上的磁盘数据块是一项耗时且耗资源的过程。通过VMware Block Zeroing操作,阵列可以处理所有的清零过程,更为高效
(3)VAAI-Automatic Test and Set

1. Atomic Test and Set(ATS):VMFS文件系统允许多主机对同一共享逻辑卷的并发访问,这是vMotion运行的必要条件。VMFS有一个内置的安全机制,防止虚拟机被超过一台的主机同时运行或修改。 使用Atomic Test and Set(ATS)命令是一种硬件辅助的锁定机制,可以离线地对存储阵列个别磁盘数据块而非整个逻辑卷加锁。这可以使得余下的逻辑卷在锁定期间继续被主机访问,十分有助于避免性能下降
(4)VAAI- UNMAP/Reclaim

1. UNMAP/Reclaim command:VMFS 是文件系统,二下层为块。当删除或迁移虚拟机后,VMFS端看空间大,二下层未做实际的空间回收。ESXi 5.0后可通知下层回收,需要下层实现接口适配,当虚拟机从一个DataStore迁走或删除立即调用Unmap,阵列上的空间立即被回收
(1)FusionStorage逻辑架构

服务器5:可以通过VBS访问其他服务器的OSD进程所管的硬盘。
服务器6:负责IO数据的读写,维持两块盘
1. FSM(FusionStorage Manager):VM形态。FusionStorage管理模块,提供告警、监控、日志、配置等操作维护功能。一般情况下FSM主备节点部署。对管理员提供管理视图、运营、运维,把物理服务器组成池子。每个FSM虚拟机中都有一个自己的Gauss DB.
2. FSA(FusionStorage Agent):装在物理服务器上(是个软件)。代理进程,部署在各节点上,实现各节点与FSM通信。FSA包含MDC、VBS和OSD三种不同的进程。根据系统不同配置要求,分别在不同的节点上启用不同的进程组合来完成特定的功能。最多4096个。(因为物理服务器最多4096个)
服务器的操作系统必须是FSA能兼容的操作系统。(如:Cent OS、CNA(服务器)、Linux等(开源的))
FSA上有Driver的,使这些服务器能识别硬盘。
3. MDC(MetaData Controller):元数据控制器,实现对分布式集群的状态控制,以及控制数据分布式规则、数据重建规则等。MDC默认部署在3个节点的ZK(Zookeeper)盘上,形成MDC集群。管理节点。MDC控制器的后台必须有一个所谓的数据库。记录一些系统元数据、规则、表、视图、数据重建规则、VBS进程状态和位置、OSD进程状态和位置、全网拓扑等等。
ZK:是保证数据一致性的分布式的协调文件(是一个分布式文件系统)。一主多从。放数据存储。

4. VBS(Virtual Block System):虚拟块存储管理组件(块客户端)(块接口=SCSI接口(对外))(软件)称为块客户端,负责卷元数据的管理,提供分布式集群接入点服务,使计算资源能够通过VBS访问分布式存储资源。每个节点上默认部署一个VBS进程,形成VBS集群。节点上也可以通过部署多个VBS来提升IO性能。计算节点。访问软件存储池的入口。
5. OSD(Object Storage Device):对象存储设备服务,执行具体的I/O操作。在每个服务器上部署多个OSD进程,一块磁盘默认对应部署一个OSD进程。在SSD卡作主存时,为了充分发挥SSD卡的性能,可以在1张SSD卡上部署多个OSD进程进行管理,例如2.4TB的SSD卡可以部署6个OSD进程,每个OSD进程负责管理400GB。存储节点。


SQL:SCSI启动器(initiator)
VBS:SCSI目标器(target)
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
system-view进入系统视图quit退到系统视图sysname交换机命名vlan20创建vlan(进入vlan20)displayvlan显示vlanundovlan20删除vlan20displayvlan20显示vlan里的端口20Interfacee1/0/24进入端口24portlink-typeaccessvlan20把当前端口放入vlan20undoporte1/0/10删除当前VLAN端口10displaycurrent-configuration显示当前配置02配置交换机支持TELNETinterfacevlan1进入VLAN1ipaddress192.168.3.100
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or