(1)运行中的程序的一个副本,是被载入内存的一个指令集合,是资源分配的单位
(2)进程创建:
(3)进程具有的特征:
(4)进程和线程的区别:
怎么查看进程中的线程?
第一步:先查看系统进程号:pstree -p
第二步:grep -i threads /proc/PID号/status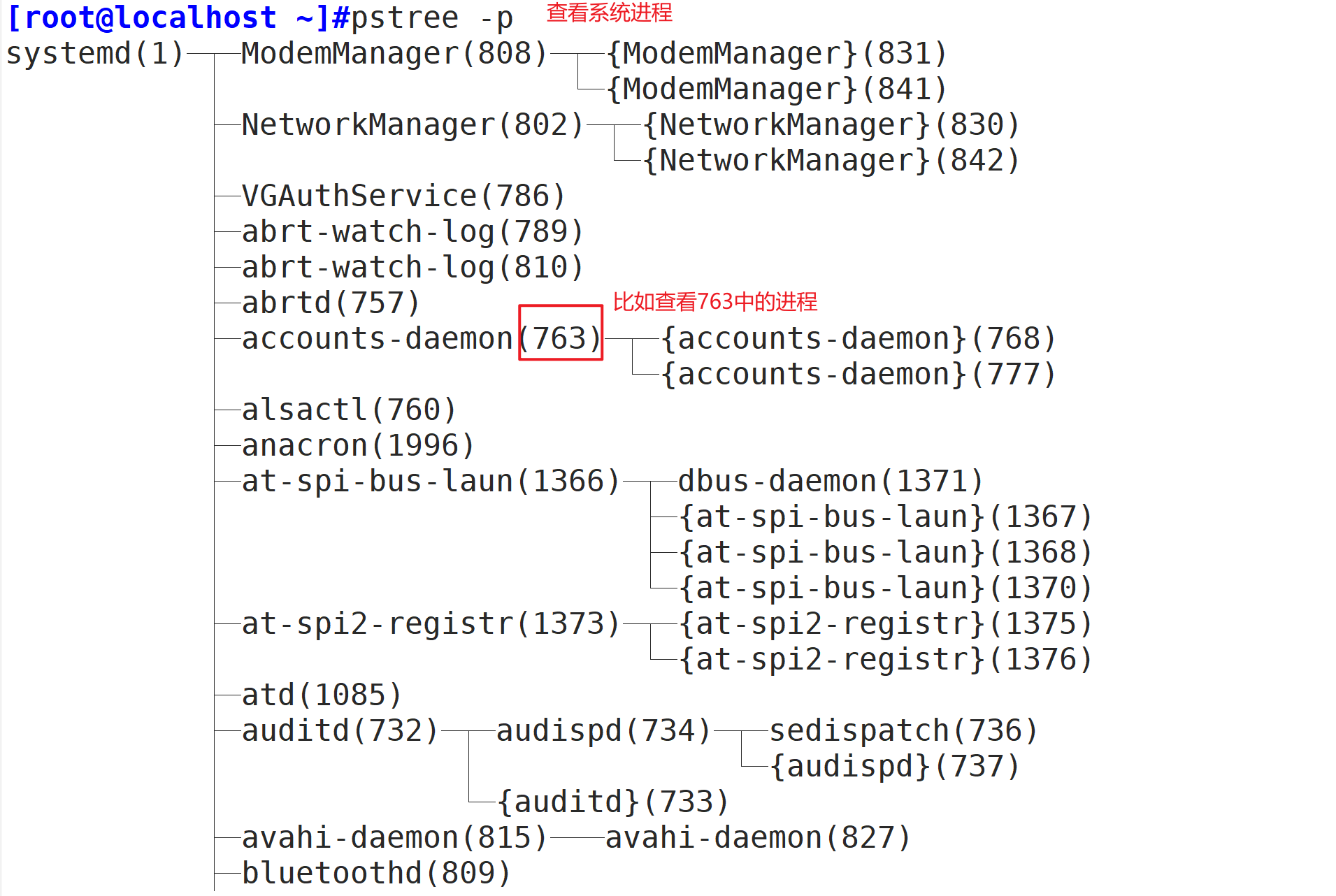

内存使用会出现的问题:
比如虚拟机本身可使用的内存(一般通过启动时的VM参数指定)太少。
应用用的太多,并且用完没释放,浪费了。此时就会造成内存泄露或者内存溢出。
使用的解决办法:
(1)限制java进程的max heap,并且降低java程序的worker数量,从而降低内存使用
(2)给系统增加swap空间
(1)进程更多的状态:
(2)僵尸进程:
一个进程结束了,但是如果该进程的父进程先结束了,那么该进程就不会变成僵尸进程,因为每个进程结束的时候,系统都会扫描当前系统中所运行的所有进程,看有没有哪个进程是刚刚结束的这个进程的子进程,如果是的话,就由Init来接管它,成为它的父进程子进程退出后init会回收其占用的相关资源。但是当子进程比父进程先结束,而父进程又没有回收子进程,释放子进程占用的资源,此时子进程将成为一个僵厂进程。




总结:父进程退出子进程没有退出 ,那么这些子进程就没有父进程来管理了, 就变成僵尸进程。子进程已经结束了,父进程没有意识到。
同一主机:
不同主机:socket=IP和端口号
进程优先级调整:
操作系统分类:
(1)协作式多任务:早期 windows 系统使用,即一个任务得到了CPU时间,除非它自己放弃使用CPU ,否则将完全霸占CPU ,所以任务之间需要协作,使用一段时间的 CPU ,主动放弃使用。
(2)抢占式多任务:Linux内核,CPU的总控制权在操作系统手中,操作系统会轮流询问每一个任务是否需要使用 CPU ,需要使用的话就让它用,不过在一定时间后,操作系统会剥夺当前任务的 CPU 使用权,把它排在询问队列的最后,再去询问下一个任务。
进程类型分类:
(1)守护进程: daemon,在系统引导过程中启动的进程,和终端无关进程
(2)前台进程:跟终端相关,通过终端启动的进程
注意:两者可相互转化
按进程资源使用的分类:
(1)CPU-Bound:CPU 密集型,非交互
(2)IO-Bound:IO 密集型,交互
ps可以查看进程当前状态的快照,默认显示当前终端中的进程,Linux系统各进程的相关信息均保存在/proc/数字 目录/status下的各文件中
1 查看静态的进程统计信息
2 "ps aux" 可以查看系统中所有的进程;
3 "ps -le" 可以查看系统中所有的进程,而且还能看到进程的父进程的 PID 和进程优先级;
4 "ps -l" 只能看到当前 Shell 产生的进程;
5
6 常用选项
7 -a:显示当前终端下的所有进程信息,包括其他用户的进程。与“x”选项结合时将示系统中所有的进程信息。
8 -u:使用以用户为主的格式输出进程信息。
9 -x:显示当前用户在所有终端下的进程信息。
10 -e:显示系统内的所有进程信息。
11 -l:使用长(Long)格式显示进程信息。
12 -f:使用完整的(Full)格式显示进程信
13 -k:对属性排序,属性前加 - 表示倒序
14 -o:显示定制的信息 pid、cmd、%cpu、%mem
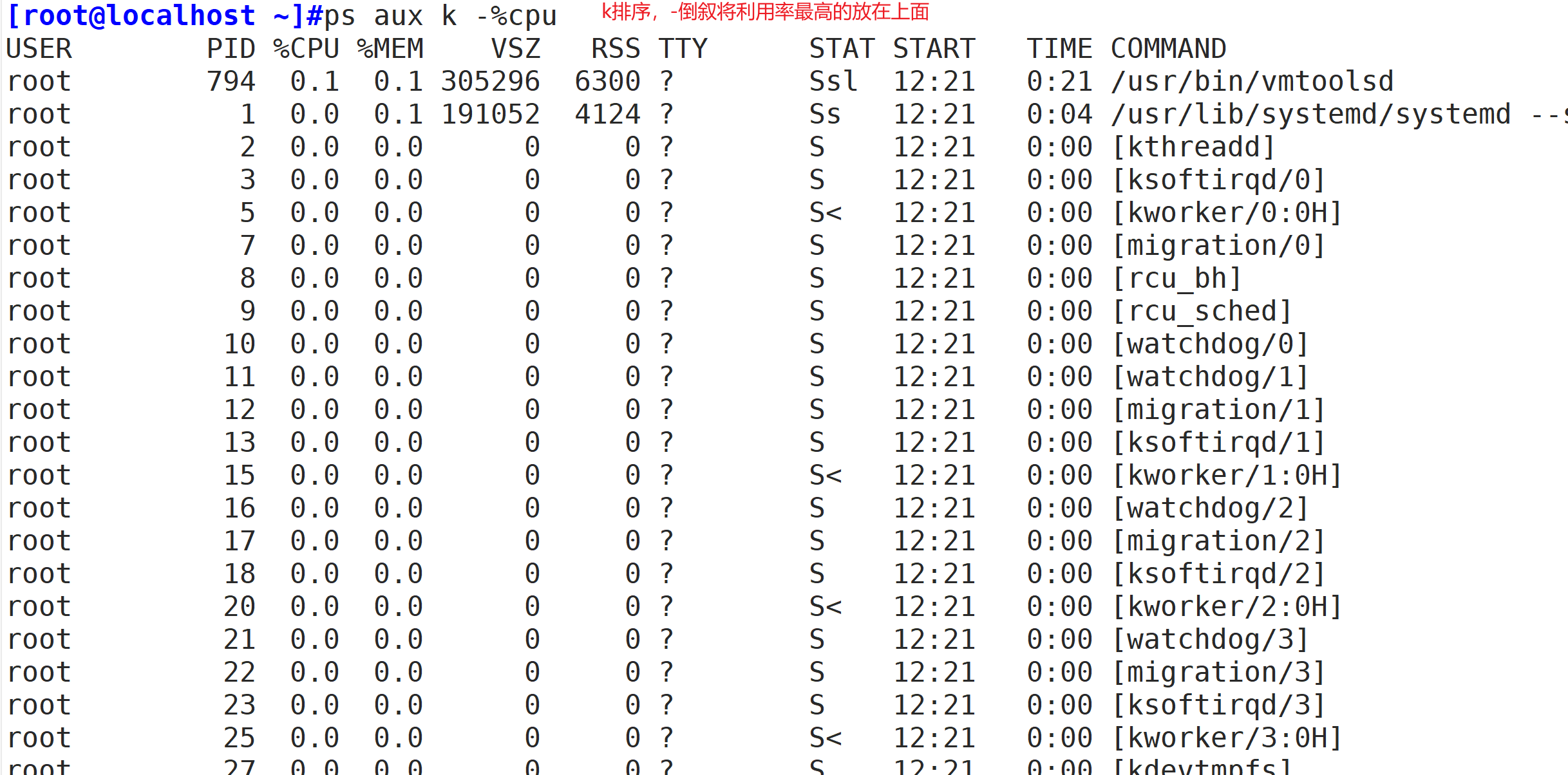
PRI (最终值) = PRI (原始值) + NI修改 NI 值时有几个注意事项:



top 命令可以动态地持续监听进程地运行状态,与此同时,该命令还提供了一个交互界面,用户可以根据需要,人性化地定制自己的输出,进而更清楚地了进程的运行状态。
1 选项:
2 -d 秒数:指定 top 命令每隔几秒更新。默认是 3 秒;
3 -b:使用批处理模式输出。一般和"-n"选项合用,用于把 top 命令重定向到文件中;
4 -n 次数:指定 top 命令执行的次数。一般和"-"选项合用;
5 -p 进程PID:仅查看指定 ID 的进程;
6 -s:使 top 命令在安全模式中运行,避免在交互模式中出现错误;
7 -u 用户名:只监听某个用户的进程;
8
9 在 top 命令的显示窗口中,还可以使用如下按键,进行一下交互操作:
10 ? 或 h:显示交互模式的帮助;
11 c:按照 CPU 的使用率排序,默认就是此选项;
12 M:按照内存的使用率排序;
13 N:按照 PID 排序;
14 T:按照 CPU 的累积运算时间排序,也就是按照 TIME+ 项排序;
15 k:按照 PID 给予某个进程一个信号。一般用于中止某个进程,信号 9 是强制中止的信号;
16 r:按照 PID 给某个进程重设优先级(Nice)值;
17 q:退出 top 命令;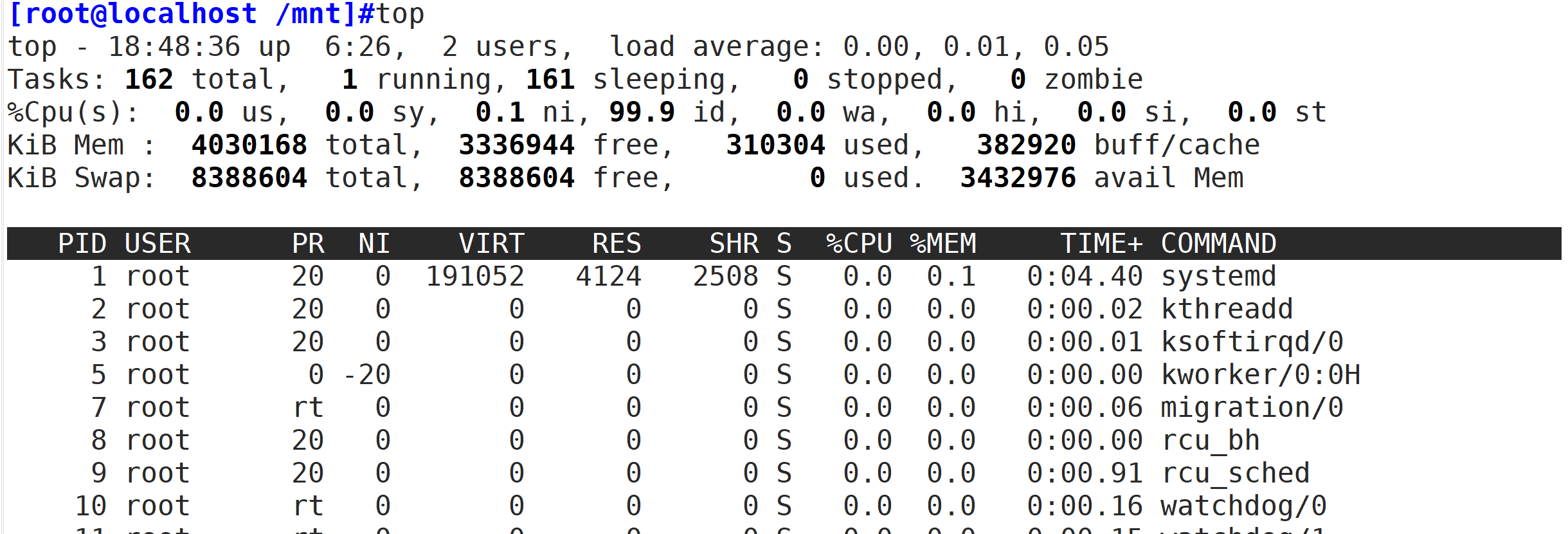
缓冲(buffer)和缓存(cache)的区别:
简单来说,缓存(cache)是用来加速数据从硬盘中"读取"的,而缓冲(buffer)是用来加速数据"写入"硬盘的。
pgrep命令:查看指定的进程
-U 指定用户
-l: 显示进程名
-a: 显示完整格式的进程名
-P: 显示指定进程的子进程


pstree:以树形结构列出进程信息
常用选项:
-a:显示启动每个进程对应的完整指令,包括启动进程的路径、参数等
-p:显示PID
-T:不显示线程thread,默认显示线程
-u:显示用户切换
-H:pid高亮显示指定进程及其前辈进程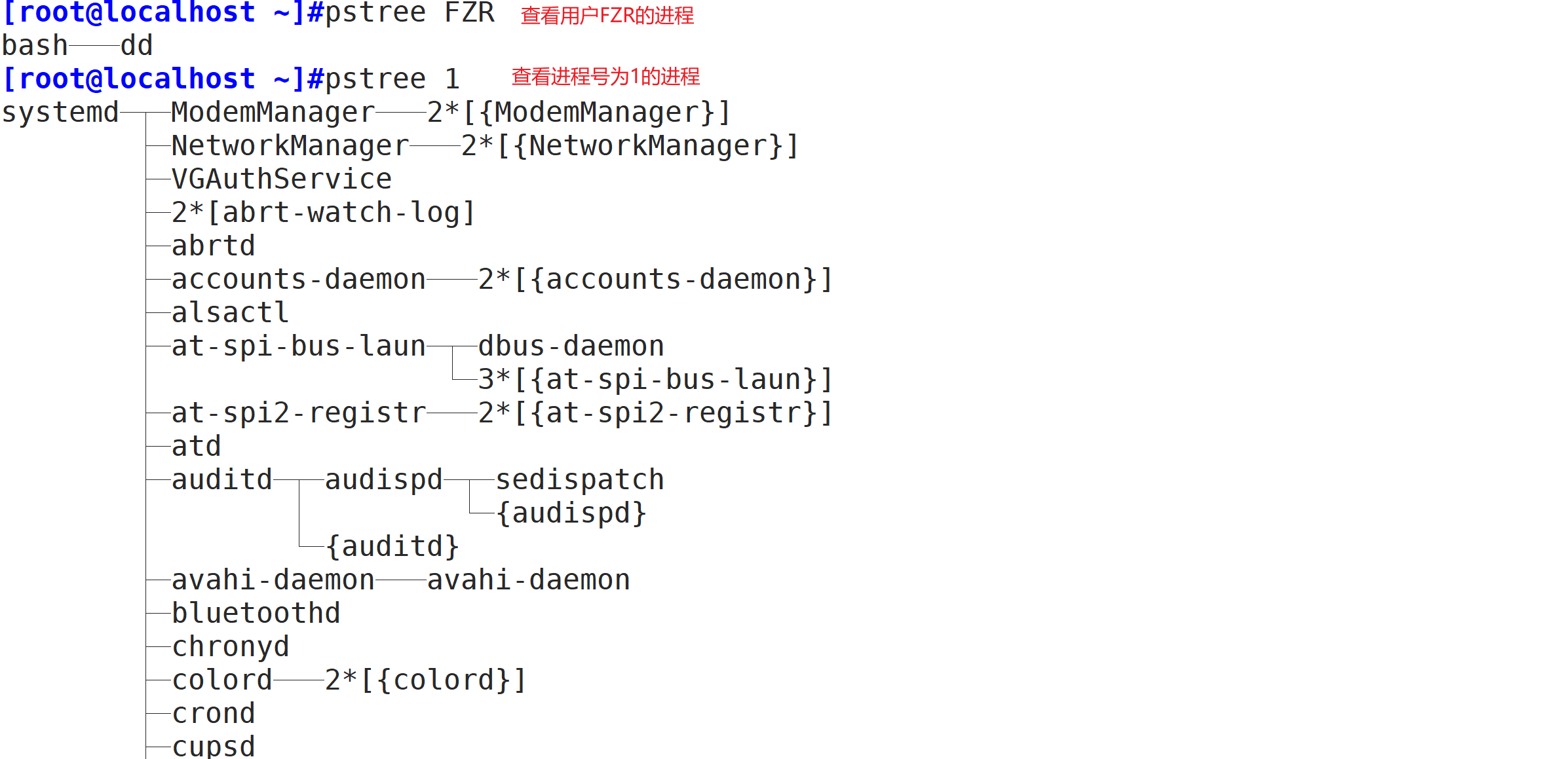
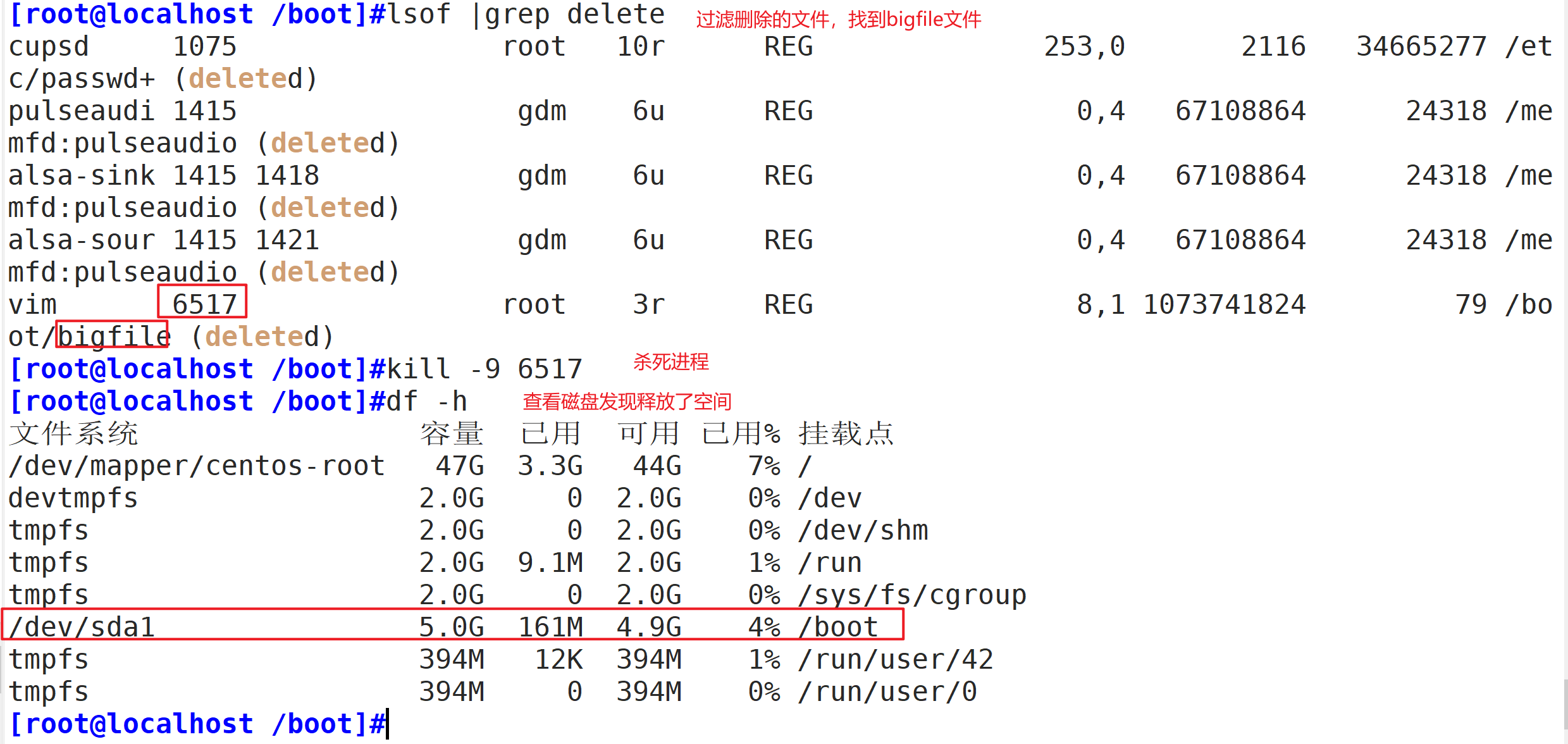
lsof:是列举系统中已经被打开的文件。通过 lsof 命令,我们就可以根据文件找到对应的进程信息,也可以根据进程信息找到进程打开的文件。
lsof [选项]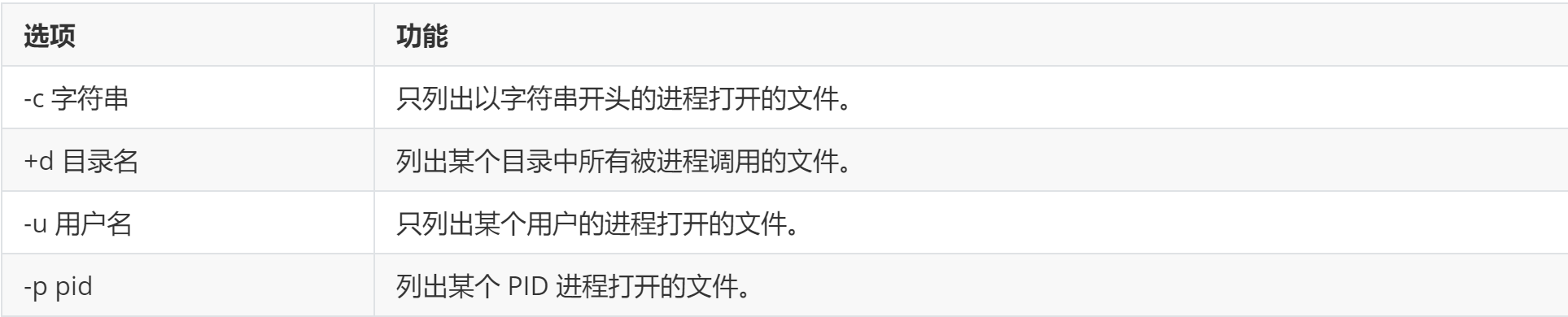


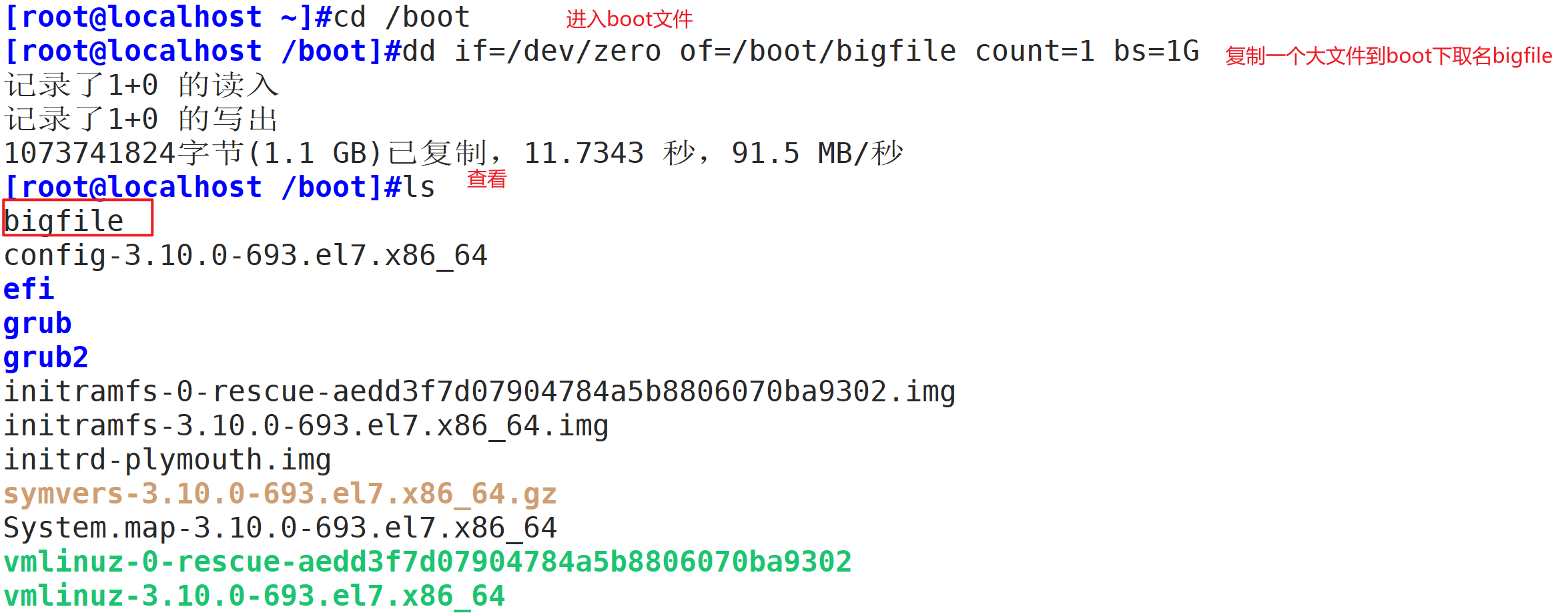
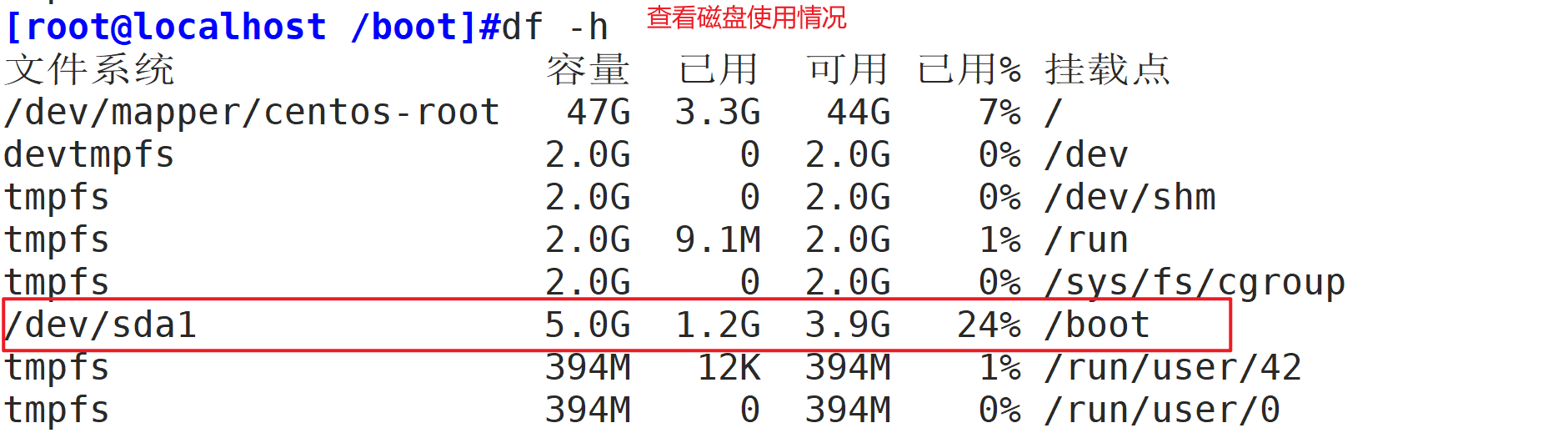
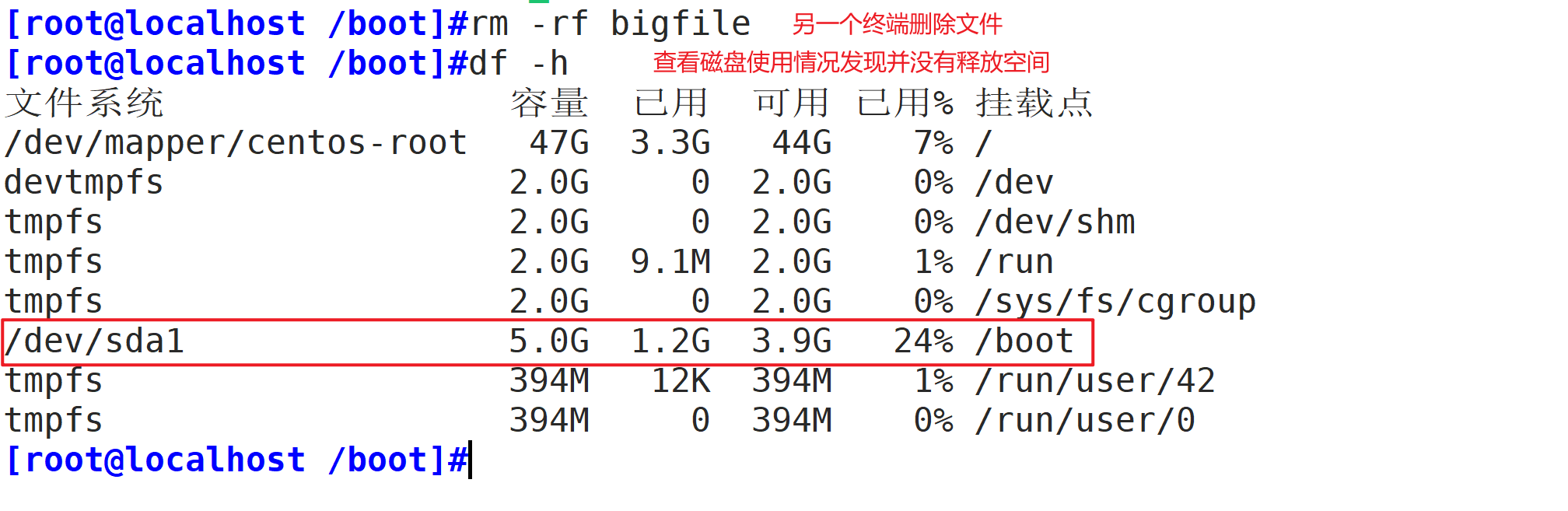
实验:删除大文件不释放空间


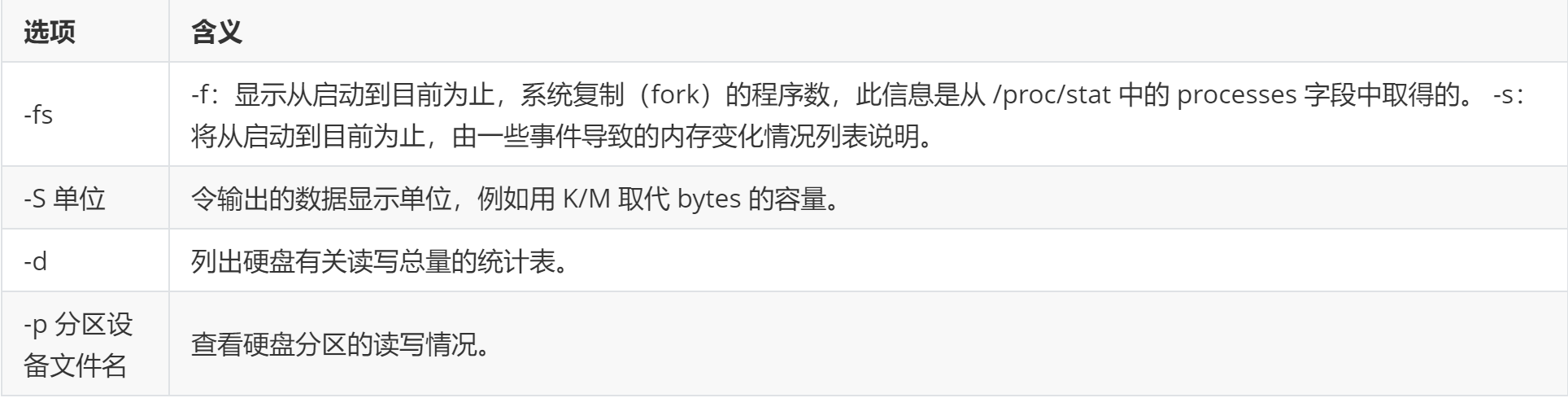
vmstat命令:可用来监控 CPU 使用、进程状态、内存使用、虚拟内存使用、硬盘输入/输出状态等信息。


五大系统资源:
cpu利用率:怎么查看(top,ps aux)
内存利用率:(free)
磁盘:(df,fdisk -l,lsblk)
磁盘读写性能:(dd,vmstat,iostat)
带宽:网络资源
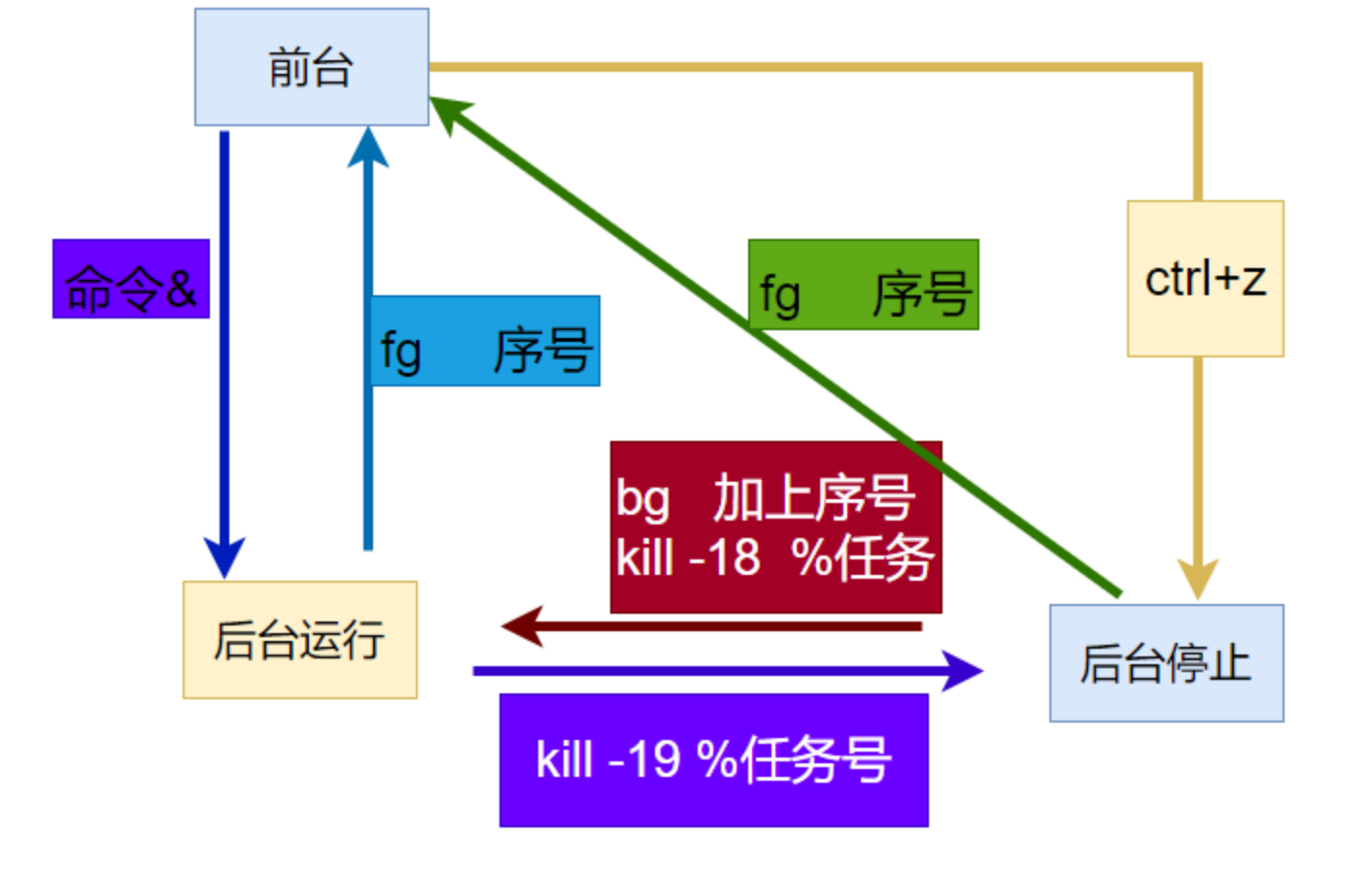
"命令&",把命令放入后台执行(具有交互性质的命令不建议放入后台比如ping命令)
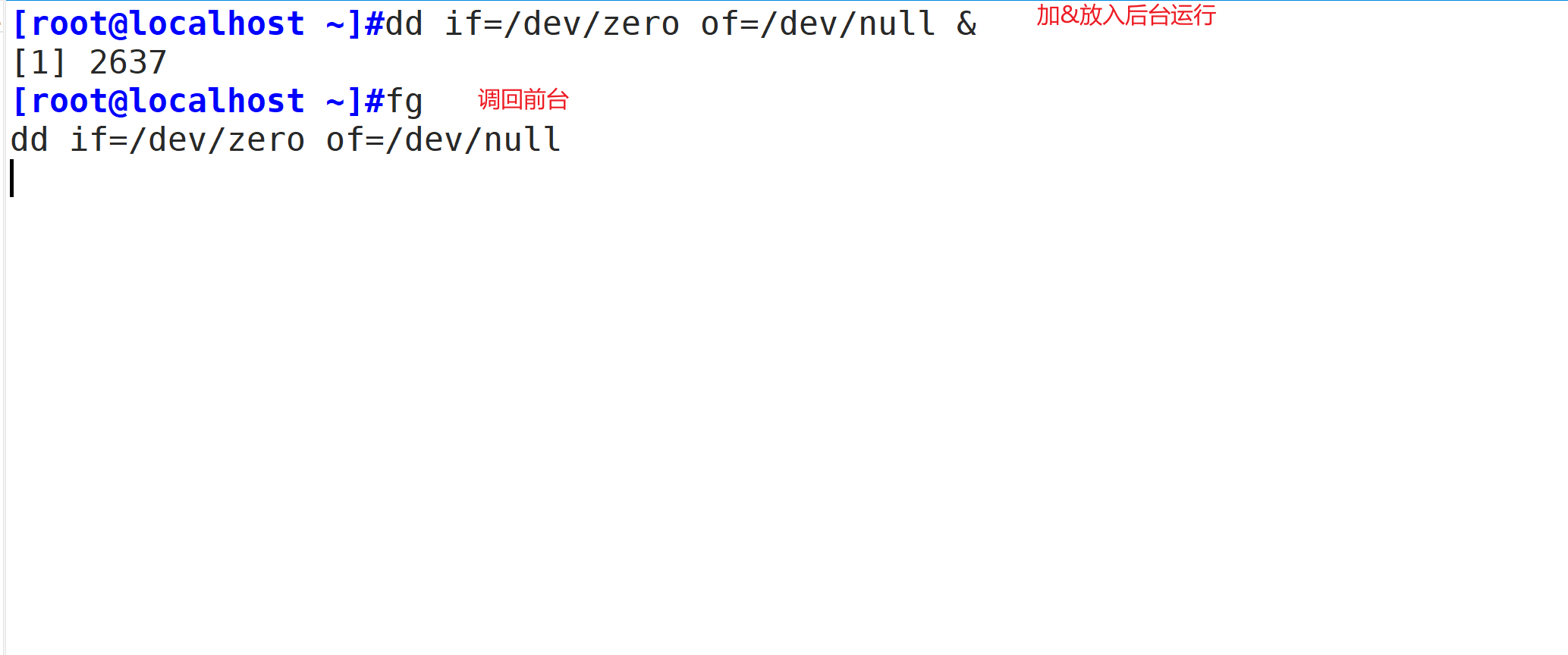

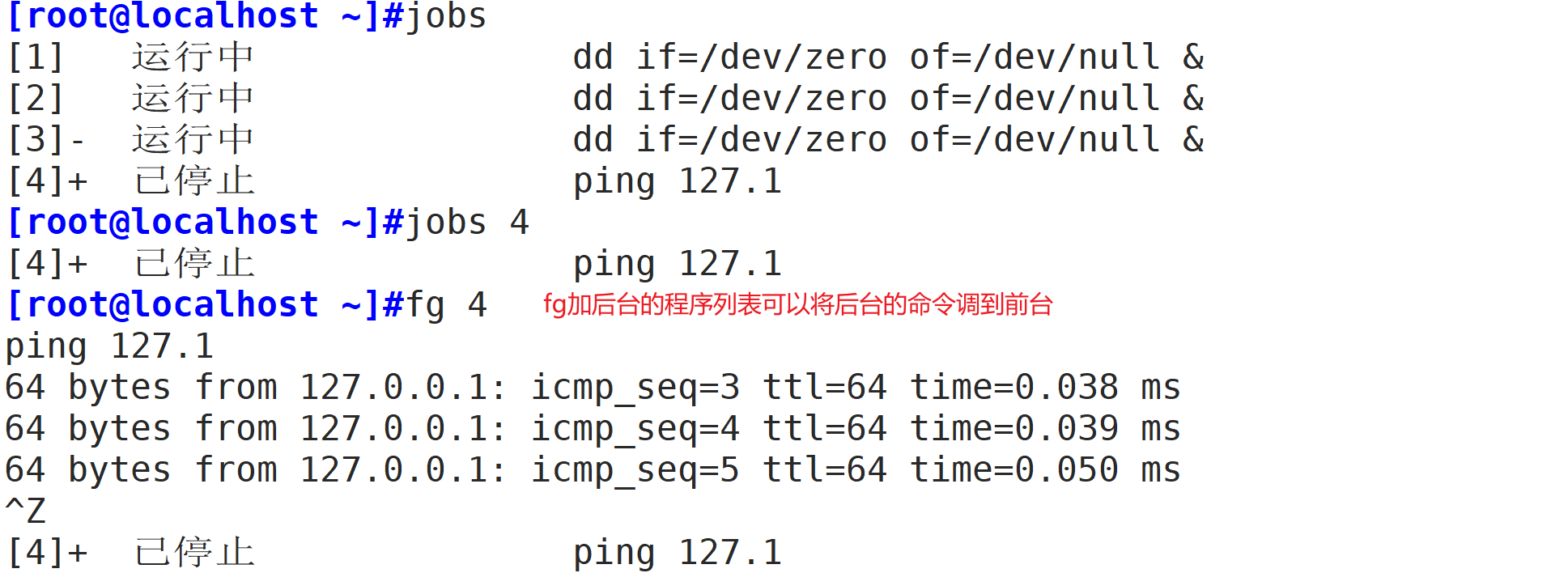
让作业运行于后台(并行执行):
运行中的作业:Ctrl+z

jobs,fg,bs命令使用

(1)kill
命令格式:
kill [信号] PID
kill 命令会向操作系统内核发送一个信号(多是终止信号)和目标进程的 PID,然后系统内核根据收到的信号类型,对指定进程进行相应的操作。(2)killall
命令格式:
killall [选项] [信号] 进程名
killall 也是用于关闭进程的一个命令,但和 kill 不同的是,killall 命令不再依靠 PID 来杀死单个进程,而是通过程序的进程名来杀死一类进程,也正是由于这一点,该命令常与 ps、pstree 等命令配合使用
-i:交互式,询问是否要杀死某个进程
-I:忽略进程名的大小写HH:MM YYYY-MM-DD:规定在某年某月的某一天的特殊时刻进行该项任务


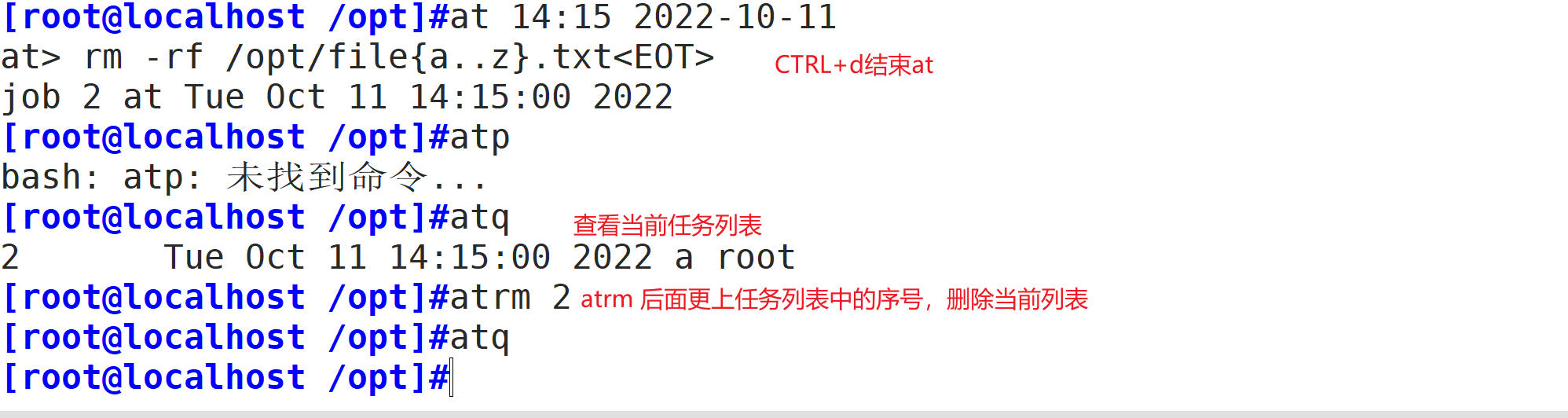
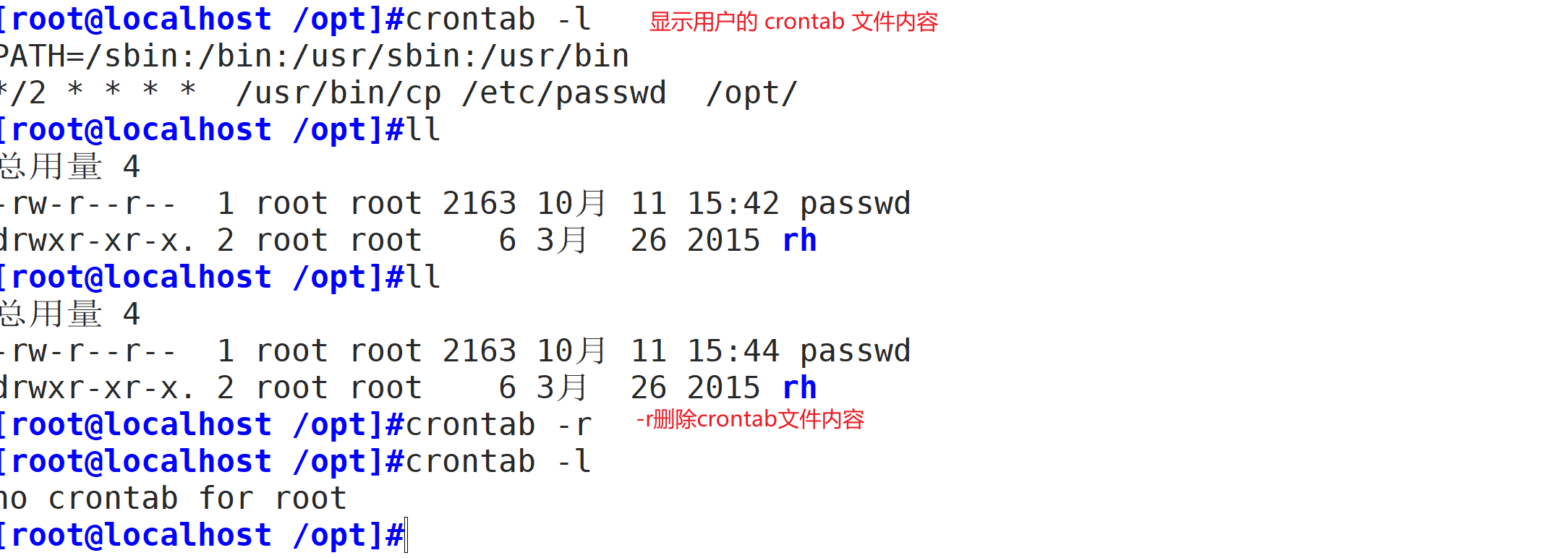
1 crontab [选项] [file]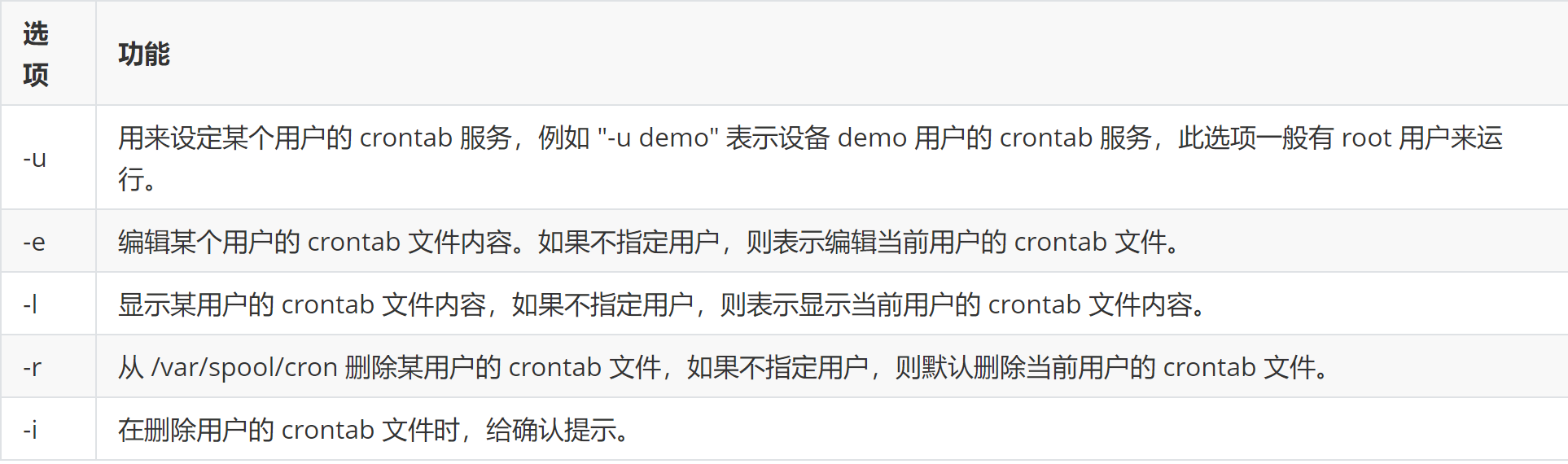
在书写 crontab 定时任务时,需要注意以下几个事项:


我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
我正在尝试使用以下代码通过将ffmpeg实用程序作为子进程运行并获取其输出并解析它来确定视频分辨率:IO.popen'ffmpeg-i'+path_to_filedo|ffmpegIO|#myparsegoeshereend...但是ffmpeg输出仍然连接到标准输出并且ffmepgIO.readlines是空的。ffmpeg实用程序是否需要一些特殊处理?或者还有其他方法可以获得ffmpeg输出吗?我在WinXP和FedoraLinux下测试了这段代码-结果是一样的。 最佳答案 要跟进mouviciel的评论,您需要使用类似pope
我目前正在用Ruby编写一个项目,它使用ActiveRecordgem进行数据库交互,我正在尝试使用ActiveRecord::Base.logger记录所有数据库事件具有以下代码的属性ActiveRecord::Base.logger=Logger.new(File.open('logs/database.log','a'))这适用于迁移等(出于某种原因似乎需要启用日志记录,因为它在禁用时会出现NilClass错误)但是当我尝试运行包含调用ActiveRecord对象的线程守护程序的项目时脚本失败并出现以下错误/System/Library/Frameworks/Ruby.frame
我想从rubyrake脚本运行一个可执行文件,比如foo.exe我希望将foo.exe的STDOUT和STDERR输出直接写入我正在运行rake任务的控制台.当进程完成时,我想将退出代码捕获到一个变量中。我如何实现这一目标?我一直在玩backticks、process.spawn、system但我无法获得我想要的所有行为,只有部分更新:我在Windows上,在标准命令提示符下,而不是cygwin 最佳答案 system获取您想要的STDOUT行为。它还返回true作为零退出代码,这可能很有用。$?填充了有关最后一次system调
A/ctohttp://wiki.nginx.org/CoreModule#usermaster进程曾经以root用户运行,是否可以以不同的用户运行nginxmaster进程? 最佳答案 只需以非root身份运行init脚本(即/etc/init.d/nginxstart),就可以用不同的用户运行nginxmaster进程。如果这真的是你想要做的,你将需要确保日志和pid目录(通常是/var/log/nginx&/var/run/nginx.pid)对该用户是可写的,并且您所有的listen调用都是针对大于1024的端口(因为绑定(
我以前没有使用过cron,所以我不能确定我这样做是对的。我想要自动化的任务似乎没有运行。我在终端中执行了这些步骤:sudogeminstall每当切换到应用程序目录无论何时。(这创建了文件schedule.rb)我将此代码添加到schedule.rb:every10.minutesdorunner"User.vote",environment=>"development"endevery:hourdorunner"Digest.rss",:environment=>"development"end我将此代码添加到deploy.rb:after"deploy:symlink","depl