利用LabelImg工具打标,输出格式选择为PascalVOC,得到xml格式的文件
"""将打标好的图片和xml分别放在img和xml文件夹中"""
import os
import glob
import shutil
root_path = os.getcwd() # 当前工作目录
xml_file_path = r'D:\YOLO\0506\labels\\' # 存放打标后xml文件的路径
png_file_path = r'D:\YOLO\0506\images\\' # 原始图片数据集的路径
png_name_list = []
xml_name_list = []
for xml_name in glob.glob(xml_file_path + "*.xml"):
filepath, temp_file_name = os.path.split(xml_name) # 将全路径分割成目录和文件名
filename, extension = os.path.splitext(temp_file_name) # 分离文件名与扩展名
png_name_list.append(filename + '.png')
xml_name_list.append(filename + '.xml')
new_dataset_png = root_path + '\\datasets\\HDA\\img\\' # 新的存放图片文件的目录
if not os.path.exists(new_dataset_png):
os.makedirs(new_dataset_png)
new_dataset_xml = root_path + '\\datasets\\HDA\\xml\\' # 新的存放xml文件的目录
if not os.path.exists(new_dataset_xml):
os.makedirs(new_dataset_xml)
for i in range(len(png_name_list)): # 将源文件的内容复制到目标文件
shutil.copy(png_file_path + str(png_name_list[i]), new_dataset_png)
shutil.copy(xml_file_path + str(xml_name_list[i]), new_dataset_xml)
运行以上代码后,当前代码路径下的目录框架如下:

目标检测的坐标格式有:
VOC(XML)格式:
(Xmin, Ymin, Xmax, Ymax),分别代表左上角和右下角的两个坐标
YOLO(TXT)格式:
(Xcenter, Ycenter, W, H),其中x,y,w,h为归一化后的数值,分别代表中心点坐标和宽、高
COCO(JSON)格式:
(Xmin, Ymin, W, H),其中x,y,w,h均不是归一化后的数值,分别代表左上角坐标和宽、高
由于不同格式的坐标表示方式不同,所以需要进行转换,将转换后的坐标文件存放到txt目录下
"""将xml格式的坐标转换成txt格式,放入txt文件夹中"""
import xml.etree.ElementTree as ET
import os
import glob
classes = ["A", "T"]
# 将xml格式的坐标转换成txt格式的坐标:(Xmin,Ymin,Xmax,Ymax)–>(X,Y,W,H)
def convert(size, box):
dw = 1.0 / size[0]
dh = 1.0 / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
y = y * dh
w = w * dw
h = h * dh
return x, y, w, h
def convert_annotation(img_name, xml_path, txt_path):
in_file = open(xml_path + img_name[:-3] + 'xml') # xml文件路径
out_file = open(txt_path + img_name[:-3] + 'txt', 'w') # 转换后的txt文件存放路径
xml_text = in_file.read()
root = ET.fromstring(xml_text)
in_file.close()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
print(cls)
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == '__main__':
path = os.getcwd()
xml_path = path + '\\datasets\\HDA\\xml\\'
img_path = path + '\\datasets\\HDA\\img\\'
txt_path = path + '\\datasets\\HDA\\txt\\'
if not os.path.exists(txt_path):
os.makedirs(txt_path)
for image_path in glob.glob(img_path + "*.png"):
# 每一张图片都对应一个xml文件,这里写xml对应的图片的路径
image_name = image_path.split('\\')[-1]
try:
convert_annotation(image_name, xml_path, txt_path)
except:
print('This picture has not xml file')
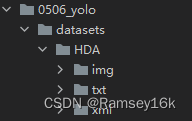
运行以上代码后,当前代码路径下的目录框架如下所示,可以看到,多了一个txt目录
"""
将数据集划分成训练集、测试集、验证集
仅仅是把划分好的png和xml文件名写入到不同集合的txt文件
"""
import os
import random
root_path = os.getcwd()
xml_file_path = root_path + '\\datasets\\HDA\\xml'
config_txt_save_path = root_path + '\\datasets\\HDA\\config'
if not os.path.exists(config_txt_save_path):
os.makedirs(config_txt_save_path)
train_test_percent = 0.9 # (训练集+验证集) / (训练集+验证集+测试集)
train_val_percent = 0.9 # 训练集 / (训练集+验证集)
total_xml = os.listdir(xml_file_path)
num = len(total_xml)
train_val_size = int(num * train_test_percent) # 训练集+验证集数量
test_size = int(num - train_val_size) # 测试集数量
val_size = int(train_val_size * train_val_percent) # 验证集数量
train_size = int(train_val_size - val_size) # 训练集数量
train_val = random.sample(range(num), train_val_size)
train = random.sample(train_val, val_size)
print("train and valid size:", train_val_size)
print("train size:", train_size)
print("test size:", test_size)
print("valid size:", val_size)
test_txt = open(config_txt_save_path + '\\test.txt', 'w')
train_txt = open(config_txt_save_path + '\\train.txt', 'w')
val_txt = open(config_txt_save_path + '\\val.txt', 'w')
img_test_txt = open(config_txt_save_path + '\\img_test.txt', 'w')
img_train_txt = open(config_txt_save_path + '\\img_train.txt', 'w')
img_val_txt = open(config_txt_save_path + '\\img_val.txt', 'w')
for i in range(num):
txt_name = total_xml[i][:-4] + '.txt' + '\n'
img_name = total_xml[i][:-4] + '.png' + '\n'
if i in train_val:
if i in train:
train_txt.write(txt_name)
img_train_txt.write(img_name)
else:
val_txt.write(txt_name)
img_val_txt.write(img_name)
else:
test_txt.write(txt_name)
img_test_txt.write(img_name)
train_txt.close()
val_txt.close()
test_txt.close()
img_train_txt.close()
img_val_txt.close()
img_test_txt.close()
运行以上代码后,当前代码路径下的目录框架如下所示,可以看到,多了一个config目录

"""重构数据集,根据txt文件划分图片,分别创建训练集、验证集、测试集的图片文件夹"""
import os
import shutil
# 获取分割好的train\test\valid名称
img_train_txt = []
img_test_txt = []
img_valid_txt = []
label_train_txt = []
label_test_txt = []
label_valid_txt = []
path = os.getcwd() + '\\datasets\\HDA\\config\\'
for line in open(path + "img_train.txt"):
line = line.strip('\n')
img_train_txt.append(line)
for line1 in open(path + "img_test.txt"):
line1 = line1.strip('\n')
img_test_txt.append(line1)
for line2 in open(path + "img_val.txt"):
line2 = line2.strip('\n')
img_valid_txt.append(line2)
for line3 in open(path + "train.txt"):
line3 = line3.strip('\n')
label_train_txt.append(line3)
for line4 in open(path + "test.txt"):
line4 = line4.strip('\n')
label_test_txt.append(line4)
for line5 in open(path + "val.txt"):
line5 = line5.strip('\n')
label_valid_txt.append(line5)
# 建立图片的3种集合文件夹
new_train_img_dir = 'datasets\\HDA\\split\\images\\train\\'
new_test_img_dir = 'datasets\\HDA\\split\\images\\test\\'
new_valid_img_dir = 'datasets\\HDA\\split\\images\\val\\'
# 建立label的3种集合文件夹
new_train_label_dir = 'datasets\\HDA\\split\\labels\\train\\'
new_test_label_dir = 'datasets\\HDA\\split\\labels\\test\\'
new_valid_label_dir = 'datasets\\HDA\\split\\labels\\val\\'
if not os.path.exists(new_train_img_dir):
os.makedirs(new_train_img_dir)
if not os.path.exists(new_test_img_dir):
os.makedirs(new_test_img_dir)
if not os.path.exists(new_valid_img_dir):
os.makedirs(new_valid_img_dir)
if not os.path.exists(new_train_label_dir):
os.makedirs(new_train_label_dir)
if not os.path.exists(new_test_label_dir):
os.makedirs(new_test_label_dir)
if not os.path.exists(new_valid_label_dir):
os.makedirs(new_valid_label_dir)
# 将图片从原始目录移动到训练集、验证集、测试集目录
origin_img_dir = 'datasets\\HDA\\img\\'
origin_label_dir = 'datasets\\HDA\\txt\\'
# 小数据建议:copy 大数据建议:move
for i in range(len(img_train_txt)):
shutil.copy(origin_img_dir + str(img_train_txt[i]), new_train_img_dir)
shutil.copy(origin_label_dir + str(label_train_txt[i]), new_train_label_dir)
for j in range(len(img_test_txt)):
shutil.copy(origin_img_dir + str(img_test_txt[j]), new_test_img_dir)
shutil.copy(origin_label_dir + str(label_test_txt[j]), new_test_label_dir)
for k in range(len(img_valid_txt)):
shutil.copy(origin_img_dir + str(img_valid_txt[k]), new_valid_img_dir)
shutil.copy(origin_label_dir + str(label_valid_txt[k]), new_valid_label_dir)
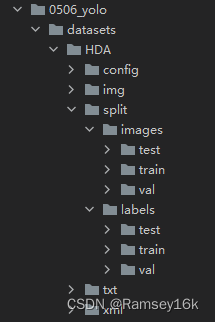
运行以上代码后,当前代码路径下的目录框架如下所示,可以看到,多了一个split目录,split目录下又包括images和labels目录,分别代表图片和标签,这2个目录下都分别有训练集、验证集和测试集的目录。
至此,对原始图片数据集的预处理完成,可以开始训练了
pt文件也就是PyTorch的模型文件,我使用的是yolov5x.pt
其他类型的model也可以在GitHub找到,进入https://github.com/ultralytics/yolov5/releases/tag/v6.1,划到页面最下方,Assets下有各种模型

下载好的YOLOv5项目结构如下所示:

将下载好的YOLOv5代码上传到有GPU的服务器
在服务器的YOLOv5文件夹中新建一个目录weights,存放yolov5x.pt
在服务器的YOLOv5文件夹中新建一个目录datasets,并新建一个当前项目的目录(便于日后针对不同项目管理),存放之前split目录下的images和labels,我这里是datasets/0506HDA
注:上传到服务器的时候需要将images和labels打成压缩包,例如dataset.zip,然后使用 unzip dataset.zip解压缩
在models目录下新建一个针对当前任务制定的模型配置文件,我的是yolov5x_hdl.yaml,具体细节参见(3)
在datasets/0506HDA目录下新建一个训练所用的yaml文件,我的是hdl.yaml,具体细节参见(3)
python train.py --data datasets/0506HDA/hdl.yaml --cfg models/yolov5x_hdl.yaml --weights weights/yolov5x.pt --epoch 400
其中,–cfg 指定训练所用的模型,–data 指定数据文件,默认使用data/coco128.yaml,–weights 指定模型权重, –epoch 指定训练轮数
# Parameters
nc: 2 # number of classes
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
hdl.yaml存放训练集、验证集、测试集的目录,以及类别信息,这是我在data/coco128.yaml的基础上修改的
原始的coco128.yaml指定了训练集、验证集、测试集的路径,以及分类个数和名字,内容如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 80 # number of classes
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # class names
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco128.zip
我根据自己的需求修改后内容如下:
train: ../yolov5/datasets/0506HDA/images/train/ # train images (relative to 'path') 128 images
val: ../yolov5/datasets/0506HDA/images/val/ # val images (relative to 'path') 128 images
test: ../yolov5/datasets/0506HDA/images/test/ # test images (optional)
# Classes
nc: 2 # number of classes
names: ['A', 'T'] # class names
训练完成后,模型的各项信息会保存在yolov5/runs/train/目录下,如果是默认的话,会有exp+数字命名的各种目录,此时进入数字最大的那个(我的是exp3),也就是最后一次训练得到的模型,即可看到训练结果。
训练效果最好的模型参数保存在exp3/weights/best.pt中
检测命令如下:
python detect.py --source /mnt/seqdata2/Public_shared/tmp_cyf/CYCLONE-291/images/20211210171717_LAB256V2_5K_PC28_34_Z3_h49_5C20_J4_AD3_2020SEP_LiuJiaDun --weights ./runs/train/exp3/weights/best.pt --line-thickness 1 --save-txt --save-conf
其中, –source 指定待检测的数据集目录,–weights 指定权重,这里我们使用训练过的最佳模型
检测结果会存放在yolov5/runs/detect/目录下
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案