很多大机构都会有个中央数据仓库负责向应用提供数据服务。随着业务的发展,中央数据仓库的负载在持续增加。一方面,数仓是前端应用的数据后台,而前端应用不断增多,用户访问的并发数也不断增长。另一方面,数仓还要承担原始数据的批量离线处理,而批量任务不断增加,其数据量和计算量也在不断增大。所以,常常会出现中央数据库不堪重负的情况。表现出来的现象是:批量处理任务耗时过长,远远超过业务可以容忍的时限;在线数据查询响应太慢,用户长时间等待,满意度越来越差。特别是月末或者年末,计算量达到高峰的时候,这些问题会更加严重。
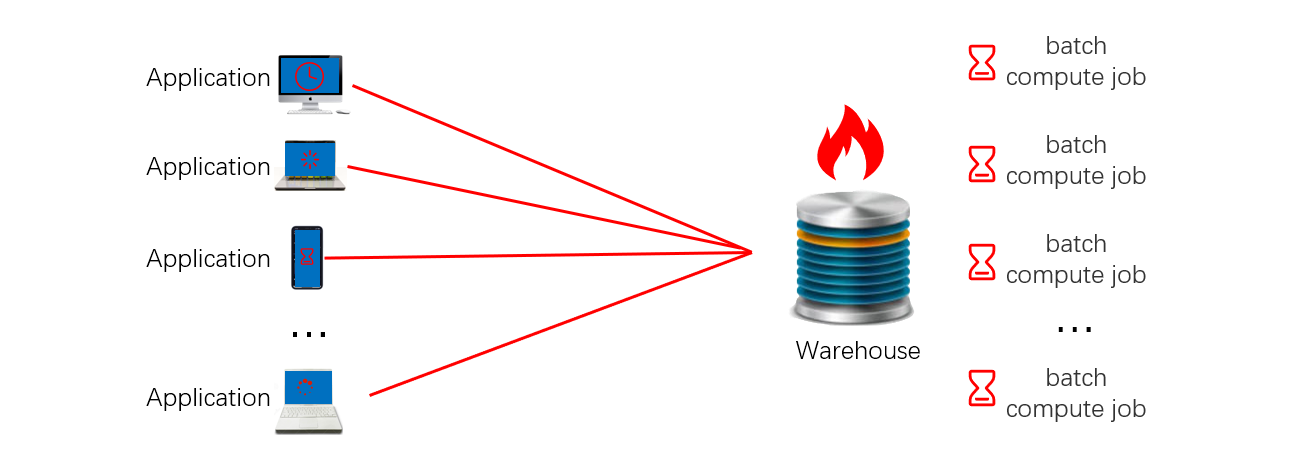
解决这个问题最容易想到的方法是提高中央数据仓库的负载能力,也就是对现有数仓进行扩容或者更换其他数仓产品。但是,数仓扩容涉及的软硬件成本都很高,频繁扩容意味着无法承受的巨大投入。而且,数据仓库一旦达到容量上限,这个办法也就不可行了。
将现有的数据仓库换成其他数仓产品的可行性也不高,这牵扯到多个部门、多种应用,更换的综合成本太高,风险也很大。即使真的换了,也不能保证很好的解决这个问题。
我们发现,现实中的很多应用都有这样一个特点:有一部分小量(热)数据访问频率远高于其它的大量(冷)数据,比如对最近几天数据的查询可能占全部查询的 80% 到 90%。我们可以利用这个特点来解决问题,具体做法是:在中央数据库和前端应用之间增加前置数据库,存放访问频次高的少量热数据。前端应用的查询请求统一提交给前置数据库,由前置库判断查询的是热数据还是冷数据,相应的访问本地数据,或将请求转发给中央数据仓库。最后,将热、冷数据计算结果整合后,统一返回给前端。前置库方案大致是下图这样:
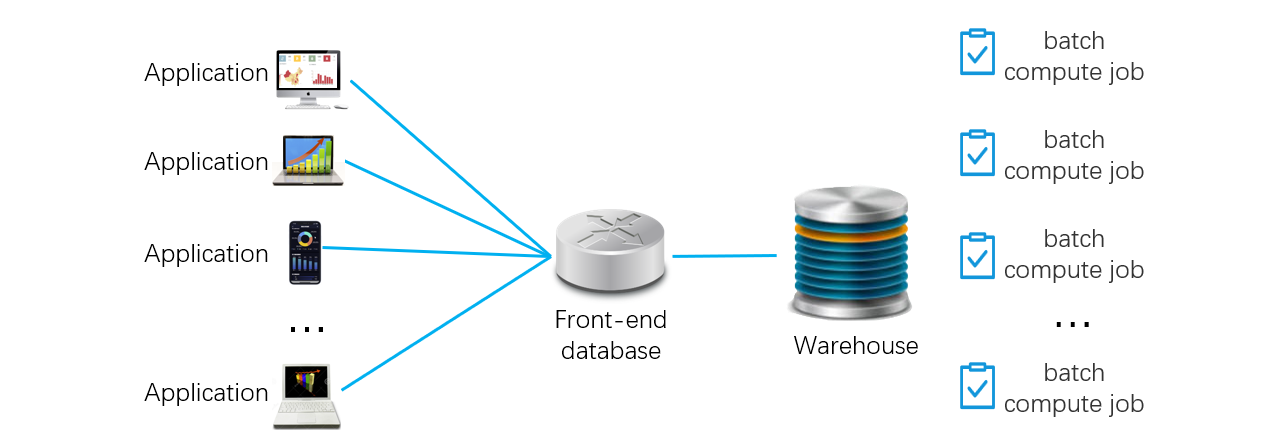
这个方案中,数据流动的路径要遵循一定的数据路由规则:频繁出现的针对少量热数据的查询由前置数据库负责,偶尔出现的针对大量冷数据的查询由中央数仓负责。这样,中央数仓的负载大大降低,不再成为拖累性能的瓶颈。
但是,传统数据库或数仓软件却很难实现这种前置库方案。这是因为,数据库的计算能力是封闭的,只能计算库内的数据,很难实施计算路由规则、查询转发和结果整合等。而且,前置数据库和数据仓库一般是不同类型的软件产品,这时候会更难以实现这类跨库的运算。
按照我们设想的方案,前置库中只会存储少量热数据。如果将传统数据库用作前置库,就只能计算这些热数据,不能计算冷数据,更无法实现冷热数据整合。显然,我们也不可能让前置数据库存储全量数据,这会变成第二个中央数据仓库,不仅带来巨大的成本,也会造成重复建设。
如果不能在前置数据库上实现计算路由,就只能在前端应用上想办法。比如在界面上让用户自己选择数据源,但这会降低应用程序的易用性,影响用户满意度。再比如修改应用程序来实现路由和数据整合,但应用程序端并不擅长处理这类运算,结果会导致代码量会很大,开发维护成本高,还很难通用。
esProc SPL 是专业的结构化、半结构化计算引擎,提供开放的计算能力,数据可以从本地存储读取,也可以来自于各种异构数据源,能够轻松实现上述方案中的各种计算需求,非常适合承担前置数据库的作用。SPL 实现前置数据库的架构图大致是下图这样:
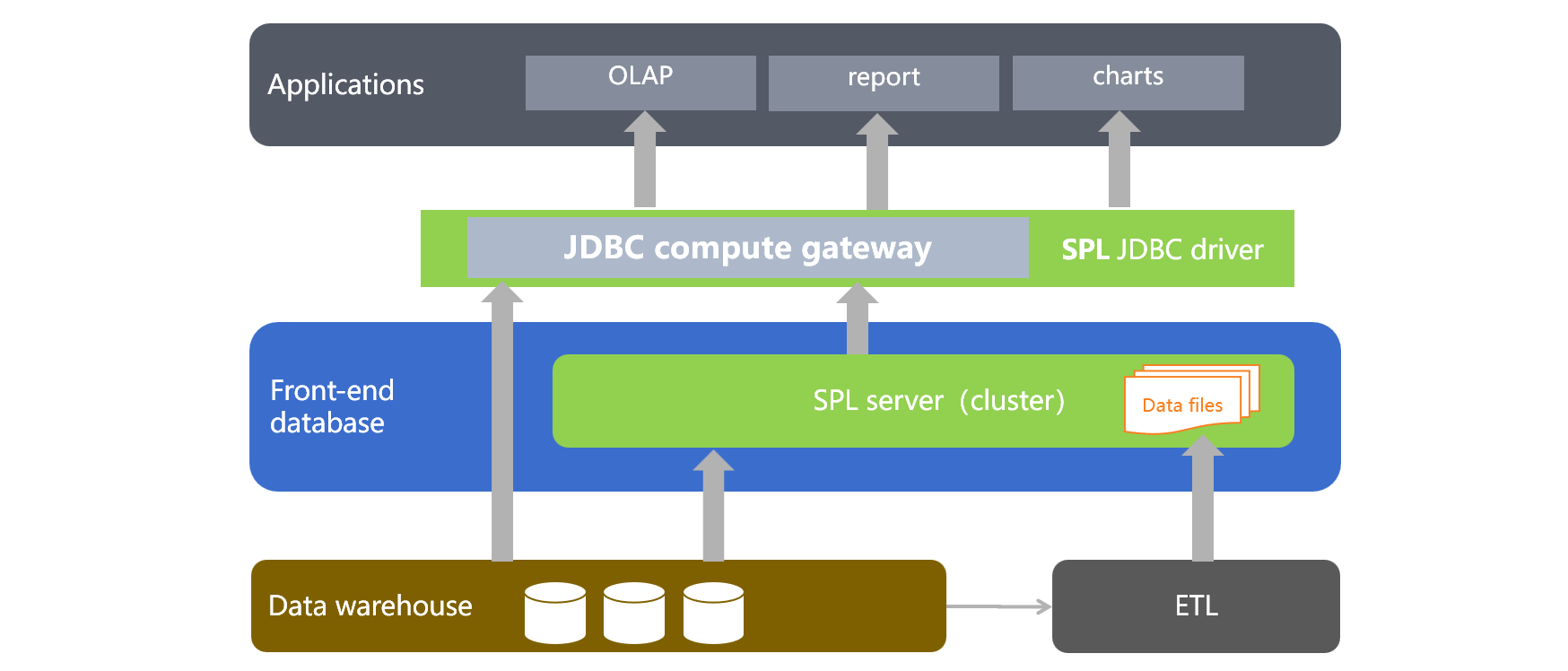
SPL 是轻量级计算引擎,热数据量不大时,可以单机部署,甚至可以直接嵌入前端应用中,系统建设成本相对于传统数据库要低很多。
SPL 实现数据路由规则的代码非常简捷。假设前端应用要按客户分组统计,输入参数是开始和结束年份。前端应用的请求中 90% 以上都是计算今年和去年的数据,所以将这两年的热数据存放在 SPL 的组表 sales.ctx 中,全量数据存仍放在中央数据库的 sales 表中。这时,前端应用的请求提交给前置库后,SPL 实现数据路由的代码大致是这样:
| A | B | |
|---|---|---|
| 1 | =begin_year=2021 | =end_year=2022 |
| 2 | if begin_year>=year(now())-1 | =file(“sales.ctx”).open().cursor@m(…;year(sdate)<=end_year) |
| 3 | return B2.groups(customer;sum(…),avg(…),…) | |
| 4 | else | =connect(“DW”).query(“select customter,sum(…),avg(…) from sales where year(sdate)>=? And year(sdate)<=? group by customer”,begin_year,end_year) |
| 5 | return B4 |
A1、A2:前端提交的开始年份和结束年份,实际应用中应作为参数传入,这里为了方便理解直接写在代码中了。
A2-B3:如果开始年份大于等于去年,则用本地热数据 sales.ctx 计算结果,并返回。这里的过滤、分组计算,SPL 只要一两个函数就可以实现。
A4-B5:其他情况则连接中央数据仓库 DW,执行请求并返回结果。SPL 可以轻松连接各种数据库、数据仓库,很容易转发前端的请求,并统一给前端应用返回结果。
SPL 封装了大量结构化、半结构化计算函数,即使面对非常复杂的计算,也可以用很简捷的代码实现。相反,如果在前端应用中利用 Java 等高级语言来实现简单的过滤、分组汇总计算,也需要编写大量代码。
可路由计算引擎 esProc SPL 实现的前置数据库,将少量高频访问的热数据缓存在本地,可以有效提升系统整体的响应速度,减少用户等待时间。同时,前置数据库将绝大部分查询计算从中央数据仓库分离出来,减轻了中央数仓的负担。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_