目录
Attention机制与Self-Attention机制的区别
传统的Attention机制发生在Target的元素和Source中的所有元素之间。
简单讲就是说Attention机制中的权重的计算需要Target来参与。即在Encoder-Decoder 模型中,Attention权值的计算不仅需要Encoder中的隐状态而且还需要Decoder中的隐状态。
Self-Attention:
不是输入语句和输出语句之间的Attention机制,而是输入语句内部元素之间或者输出语句内部元素之间发生的Attention机制。
例如在Transformer中在计算权重参数时,将文字向量转成对应的KQV,只需要在Source处进行对应的矩阵操作,用不到Target中的信息。
神经网络接收的输入是很多大小不一的向量,并且不同向量向量之间有一定的关系,但是实际训练的时候无法充分发挥这些输入之间的关系而导致模型训练结果效果极差。比如机器翻译问题(序列到序列的问题,机器自己决定多少个标签),词性标注问题(一个向量对应一个标签),语义分析问题(多个向量对应一个标签)等文字处理问题。
针对全连接神经网络对于多个相关的输入无法建立起相关性的这个问题,通过自注意力机制来解决,自注意力机制实际上是想让机器注意到整个输入中不同部分之间的相关性。
针对输入是一组向量,输出也是一组向量,输入长度为N(N可变化)的向量,输出同样为长度为N 的向量。
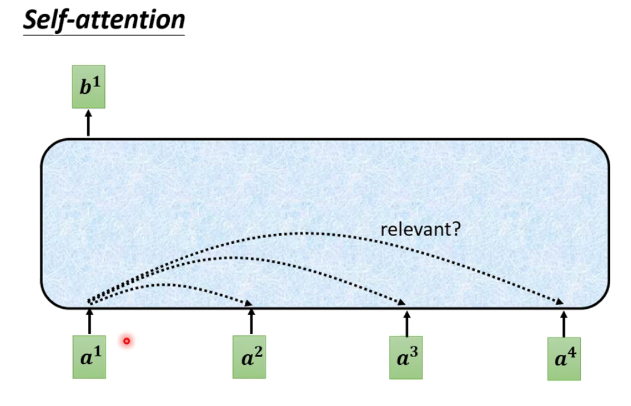
对于每一个输入向量a,经过蓝色部分self-attention之后都输出一个向量b,这个向量b是考虑了所有的输入向量对a1产生的影响才得到的,这里有四个词向量a对应就会输出四个向量b。
下面以b1的输出为例
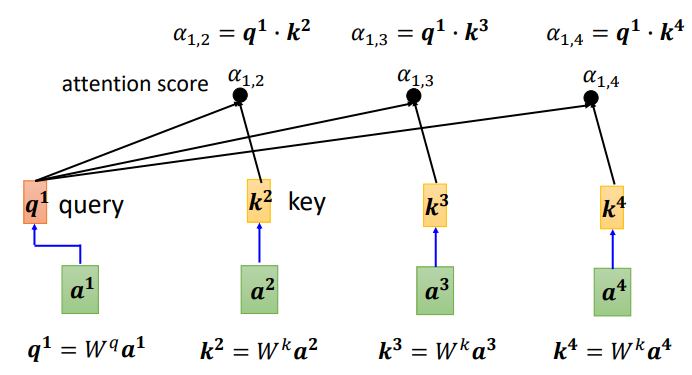
首先,如何计算sequence中各向量与a1的关联程度,有下面两种方法
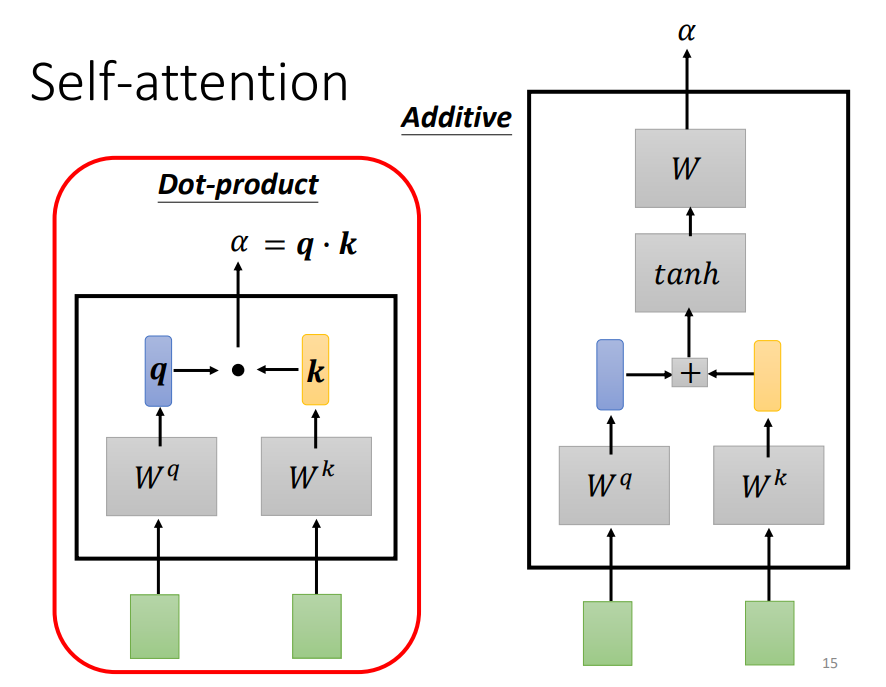
Dot-product方法是将两个向量乘上不同的矩阵w,得到q和k,做点积得到α,transformer中就用到了Dot-product。
上图中绿色的部分就是输入向量a1和a2,灰色的Wq和Wk为权重矩阵,需要学习来更新,用a1去和Wq相乘,得到一个向量q,然后使用a2和Wk相乘,得到一个数值k。最后使用q和k做点积,得到α。α也就是表示两个向量之间的相关联程度。
上图右边加性模型这种机制也是输入向量与权重矩阵相乘,后相加,然后使用tanh投射到一个新的函数空间内,再与权重矩阵相乘,得到最后的结果。
可以计算每一个α(又称为attention score),q称为query,k称为key
另外,也可以计算a1和自己的关联性,再得到各向量与a1的相关程度之后,用softmax计算出一个attention distribution,这样就把相关程度归一化,通过数值就可以看出哪些向量是和a1最有关系。
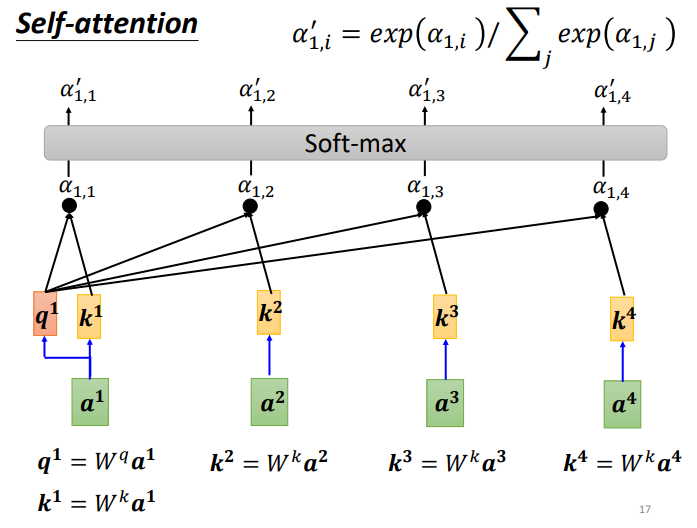
下面需要根据 α′ 抽取sequence里重要的资讯:
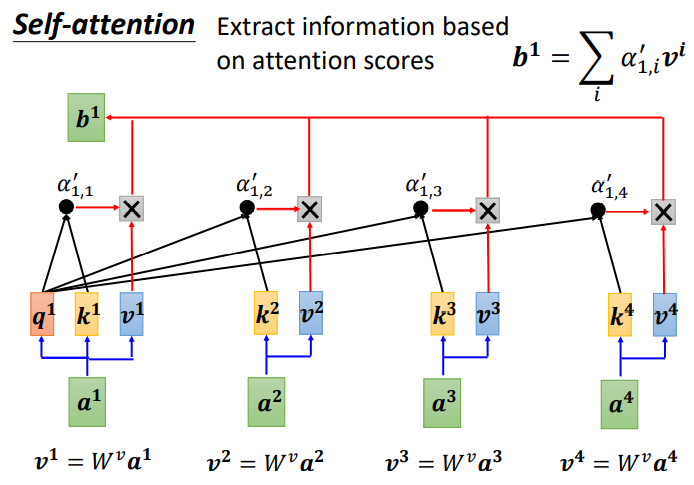
先求v,v就是键值value,v和q、k计算方式相同,也是用输入a乘以权重矩阵W,得到v后,与对应的α′ 相乘,每一个v乘与α'后求和,得到输出b1。
如果 a1 和 a2 关联性比较高, α1,2′ 就比较大,那么,得到的输出 b1 就可能比较接近 v2 ,即attention score决定了该vector在结果中占的分量;
用矩阵运算表示b1的生成:
Step 1:q、k、v的矩阵形式生成
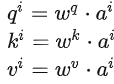
写成矩阵形式:
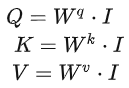
把4个输入a拼成一个矩阵,这个矩阵有4个column,也就是a1到a4,
乘上相应的权重矩阵W,得到相应的矩阵Q、K、V,分别表示query,key和value。
三个W是我们需要学习的参数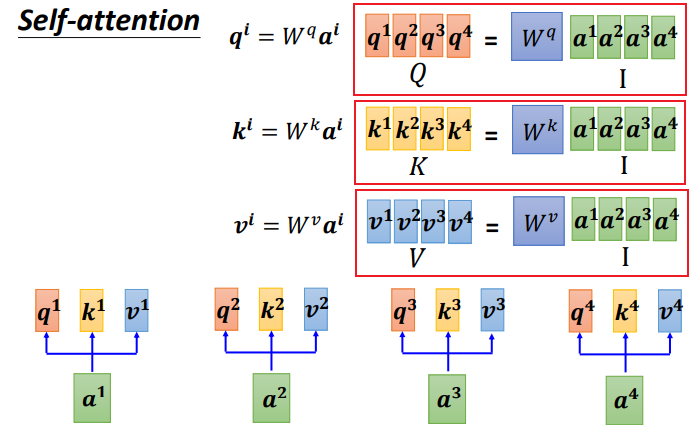
Step 2:利用得到的Q和K计算每两个输入向量之间的相关性,也就是计算attention的值α, α的计算方法有多种,通常采用点乘的方式。
先针对q1,通过与k1到k4拼接成的矩阵K相乘,得到拼接成的矩阵。
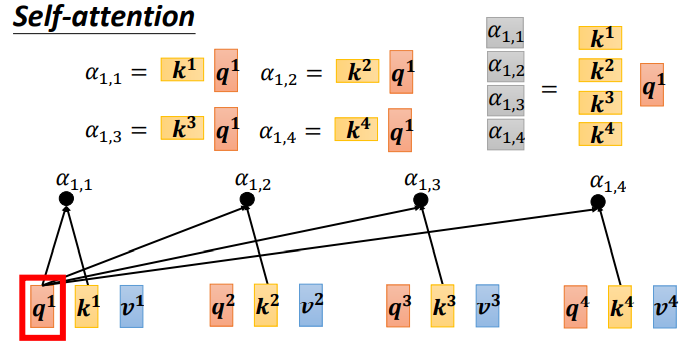
同样,q1到q4也可以拼接成矩阵Q直接与矩阵K相乘:

公式为:
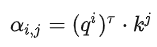
矩阵形式:
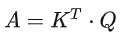
矩阵A中的每一个值记录了对应的两个输入向量的Attention的大小α,A'是经过softmax归一化后的矩阵。
Step 3:利用得到的A'和V,计算每个输入向量a对应的self-attention层的输出向量b:
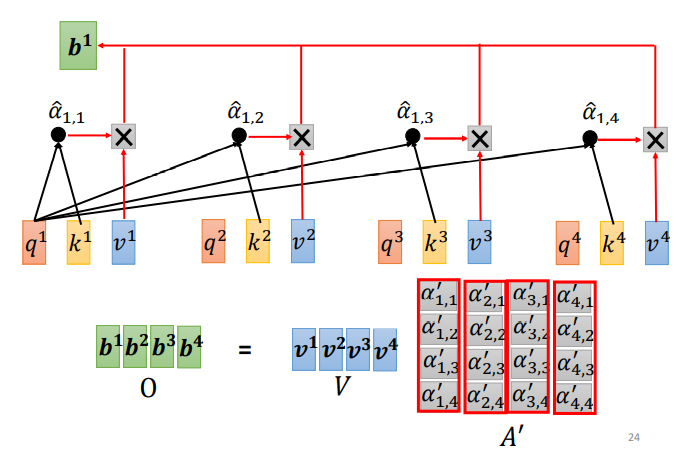
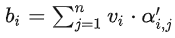
写成矩阵形式:
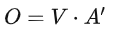
对self-attention操作过程做个总结,输入是I,输出是O:
矩阵Wq、 Wk 、Wv是需要学习的参数。
self-attention的进阶版本Multi-head Self-attention,多头自注意力机制
因为相关性有很多种不同的形式,有很多种不同的定义,所以有时不能只有一个q,要有多个q,不同的q负责不同种类的相关性。
对于1个输入a
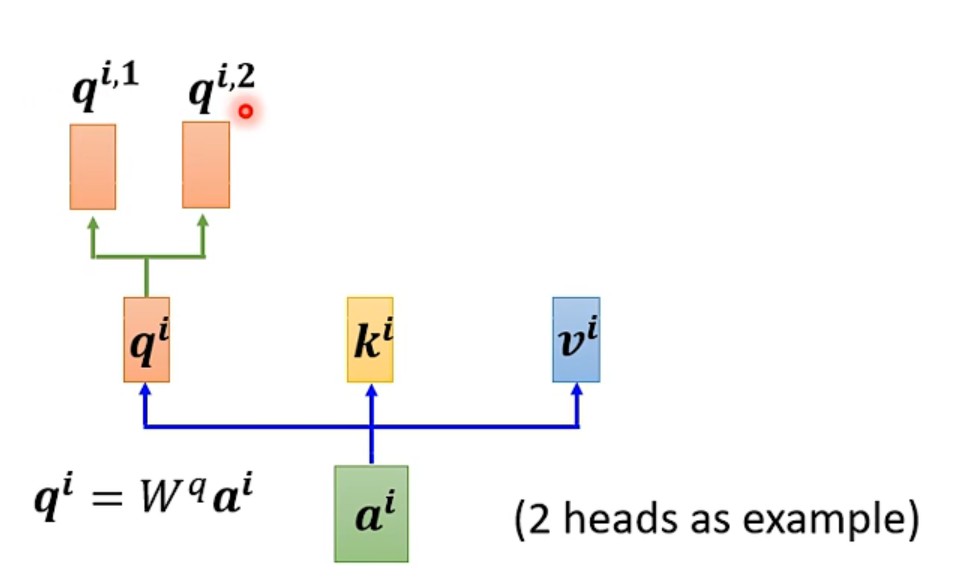
首先,和上面一样,用a乘权重矩阵W得到,然后再用
乘两个不同的W,得到两个不同的
,i代表的是位置,1和2代表的是这个位置的第几个q。
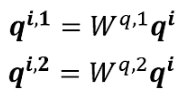
这上面这个图中,有两个head,代表这个问题有两种不同的相关性。
同样,k和v也需要有多个,两个k、v的计算方式和q相同,都是先算出来ki和vi,然后再乘两个不同的权重矩阵。
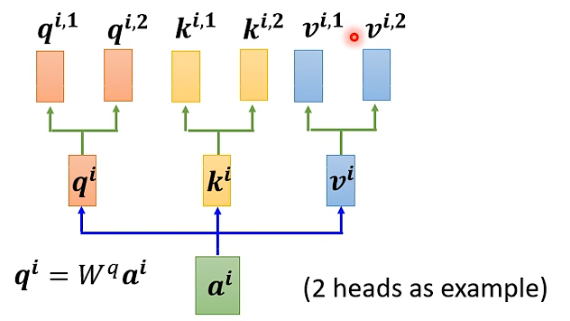
对于多个输入向量也一样,每个向量都有多个head:
算出来q、k、v之后怎么做self-attention呢?
和上面讲的过程一样,只不过是1那类的一起做,2那类的一起做,两个独立的过程,算出来两个b。
对于1:
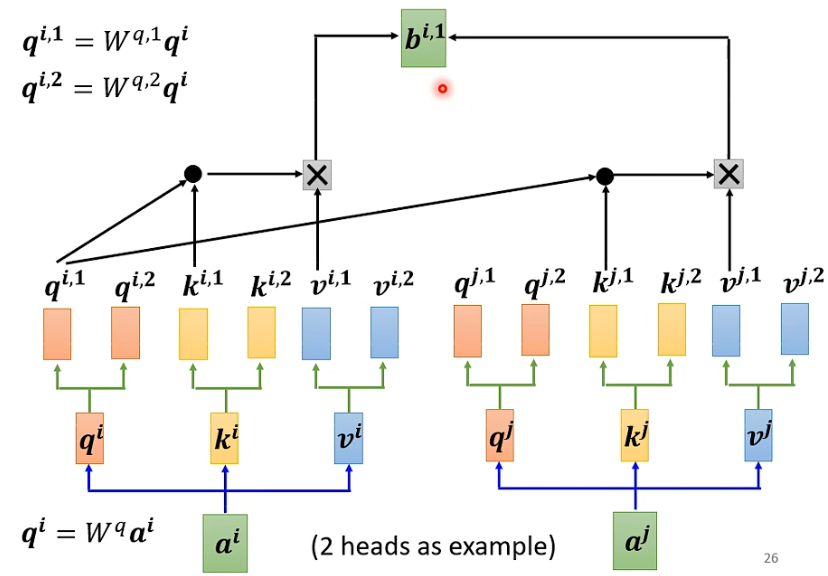
对于2:
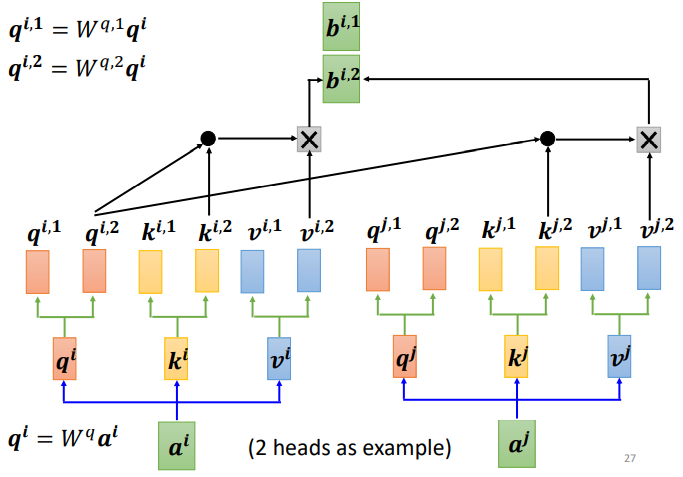
这只是两个head的例子,有多个head过程也一样,都是分开算b。
最后,把拼接成矩阵再乘权重矩阵W,得到
,也就是这个self- attention向量ai的输出,如下图所示:
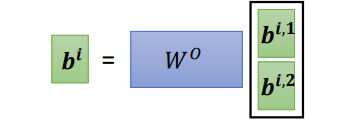
在训练self attention的时候,实际上对于位置的信息是缺失的,没有前后的区别,上面讲的a1,a2,a3不代表输入的顺序,只是指输入的向量数量,不像rnn,对于输入有明显的前后顺序,比如在翻译任务里面,对于“机器学习”,机器学习依次输入。而self-attention的输入是同时输入,输出也是同时产生然后输出的。
如何在Self-Attention里面体现位置信息呢?就是使用Positional Encoding
也就是新引入了一个位置向量,非常简单,如下图所示:
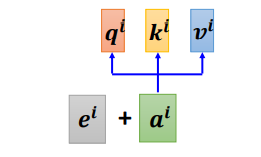
每一个位置设置一个vector,叫做positional vector,用表示,不同的位置有一个专属的ei。
如果ai加上了ei,就会体现出位置的信息,i是多少,位置就是多少。
vector长度是人为设定的,也可以从数据中训练出来。
Self-attention和RNN的主要区别在于:
1.Self-attention可以考虑全部的输入,而RNN似乎只能考虑之前的输入(左边)。但是当使用双向RNN的时候可以避免这一问题。
2.Self-attention可以容易地考虑比较久之前的输入,而RNN的最早输入由于经过了很多层网络的处理变得较难考虑。
3.Self-attention可以并行计算,而RNN不同层之间具有先后顺序。
1.Self-attention可以考虑全部的输入,而RNN似乎只能考虑之前的输入(左边)。但是当使用双向RNN的时候可以避免这一问题。
比如,对于第一个RNN,只考虑了深蓝色的输入,绿色及绿色后面的输入不会考虑,而Self-Attention对于4个输入全部考虑
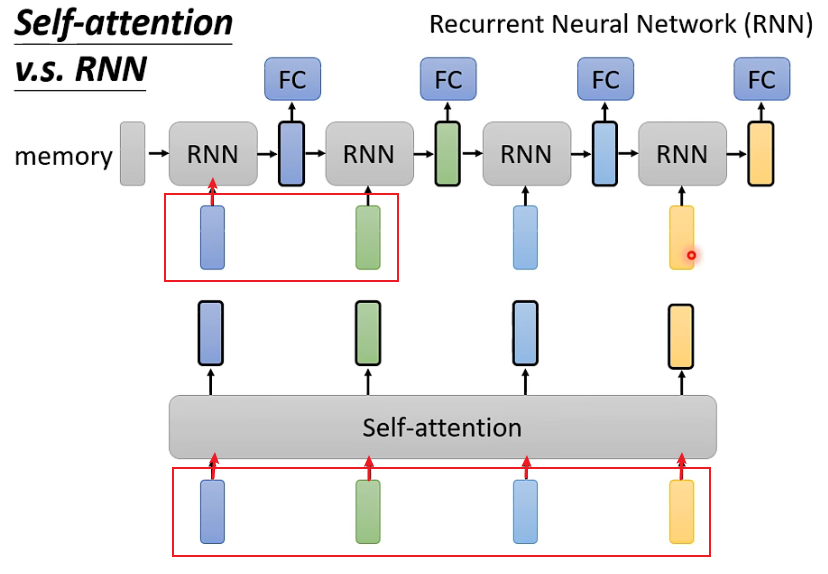
2.Self-attention可以容易地考虑比较久之前的输入,而RNN的最早输入由于经过了很多层网络的处理变得较难考虑。
比如对于最后一个RNN的黄色输出,想要包含最开始的蓝色输入,必须保证蓝色输入在经过每层时信息都不丢失,但如果一个sequence很长,就很难保证。而Self-attention每个输出都和所有输入直接有关。
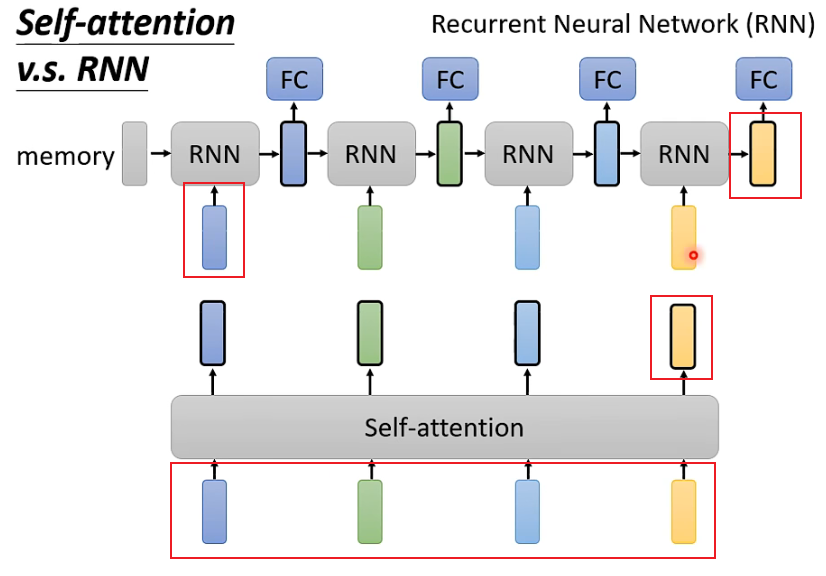
3.Self-attention可以并行计算,而RNN不同层之间具有先后顺序。
Self-attention的输入是同时输入,输出也是同时输出。
参考:
第四节 2021 - 自注意力机制(Self-attention)(上)_哔哩哔哩_bilibili
(53条消息) Attention机制与Self-Attention机制的区别_At_a_lost的博客-CSDN博客_attention和self attention的区别
Self-Attention 自注意力机制 - 知乎 (zhihu.com)
【自然语言处理】:自注意力机制(self-attention)原理介绍 - Geeksongs - 博客园 (cnblogs.com)
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
#app/models/product.rbclassProduct我从Controller调用方法1。当我运行程序时。我收到一个错误:method_missing(atlinemethod2(param2)).rbenv/versions/2.3.1/lib/ruby/gems/2.3.0/gems/activerecord-5.0.0/lib/active_record/relation/batches.rb:59:in`block(2levels)infind_each... 最佳答案 classProduct说明:第一个是类
我明白了defa(&block)block.call(self)end和defa()yieldselfend导致相同的结果,如果我假设有这样一个blocka{}。我的问题是-因为我偶然发现了一些这样的代码,它是否有任何区别或者是否有任何优势(如果我不使用变量/引用block):defa(&block)yieldselfend这是一个我不理解&block用法的具体案例:defrule(code,name,&block)@rules=[]if@rules.nil?@rules 最佳答案 我能想到的唯一优点就是自省(introspecti
我正在尝试获得良好的Ruby编码风格。为防止意外调用具有相同名称的局部变量,我总是在适当的地方使用self.。但是现在我偶然发现了这个:classMyClass上面的代码导致错误privatemethodsanitize_namecalled但是当删除self.并仅使用sanitize_name时,它会起作用。这是为什么? 最佳答案 发生这种情况是因为无法使用显式接收器调用私有(private)方法,并且说self.sanitize_name是显式指定应该接收sanitize_name的对象(self),而不是依赖于隐式接收器(也是
我的rails3.1.6应用程序中有一个自定义访问器方法,它为一个属性分配一个值,即使该值不存在。my_attr属性是一个序列化的哈希,除非为空白,否则应与给定值合并指定了值,在这种情况下,它将当前值设置为空值。(添加了检查以确保值是它们应该的值,但为简洁起见被删除,因为它们不是我的问题的一部分。)我的setter定义为:defmy_attr=(new_val)cur_val=read_attribute(:my_attr)#storecurrentvalue#makesureweareworkingwithahash,andresetvalueifablankvalueisgiven
我试图将一个类的实例化限制为一个类(不使用单例),但我做不到。我尝试使用类变量(@@)但没有成功。我用谷歌搜索并发现了这个:classA@count=0class我搜索了'class'的解释,希望能找到更好的(或者更简单和干净的),但再次,没有运气。最后,经过一些测试后我得出结论,'class'只是一个block包装器,您可以在其中定义class方法。那么,这是正确的吗?问候! 最佳答案 class符号打开了对象的特征类。特征类是一个匿名类,用于存储特定于实例的行为。在类的情况下,特征类有时称为元类。Ruby使用特征类来实现所谓的“
哪个是更好的做法;通过@property或self.property使用访问器操作属性? 最佳答案 如果您只是使用直接访问器,那么请坚持使用@property(除非您来自Python并且被@sigilhehe关闭)否则:这完全取决于您。但是self.property在某些需要确保属性已初始设置的情况下很有用:defproperty@property||=[]end#don'tneedtocheckif@propertyis`nil`firstself.property另请注意,在@property上使用self.property会产
这个问题在这里已经有了答案:Isitpossibletohaveclass.property=xreturnsomethingotherthanx?(3个答案)关闭8年前。我想迭代一个字符串数组,并将它们中的每一个分配给类User的一个新实例,我希望我会得到一个User对象数组:classUserdefname=(name)@name=nameselfendendoriginal_array=["aaa","bbb","bbb"]result=original_array.collect{|str|User.new.name=str}但结果是一个字符串数组!putsresult.ins
在下面的片段中,是否可以从模块外部引用FOO常量,如果可以,如何?moduleXclass 最佳答案 class或classObjectdefmetaclassclass 关于ruby-类中的常量 https://stackoverflow.com/questions/2281057/
为什么我可以这样改变“self”:self.map!{|x|x*2}或者这样:self.replace(self.map{|x|x*2})但不是这样:self=self.map{|x|x*2}为什么Ruby不允许我更改“self”变量指向的对象,但允许我更改对象的属性? 最佳答案 不是答案,只是一个线索。a=[1,2]=>[1,2]a.object_id=>2938a.map!{|x|x*2}=>[2,4]a.object_id#differentdatabutstillthesameobject=>2938a.replace(a.