给你比个心,渴望留住你 ^ V ^
文章目录
JUC ==> java.util.concurrent
与前五种方式不一样的是
例如:我们需要用一个线程去算 1 + 2 + 3 + ······ + 1000,前五种线程创建方式的话应该将此结果赋值给捕获到的变量才行~

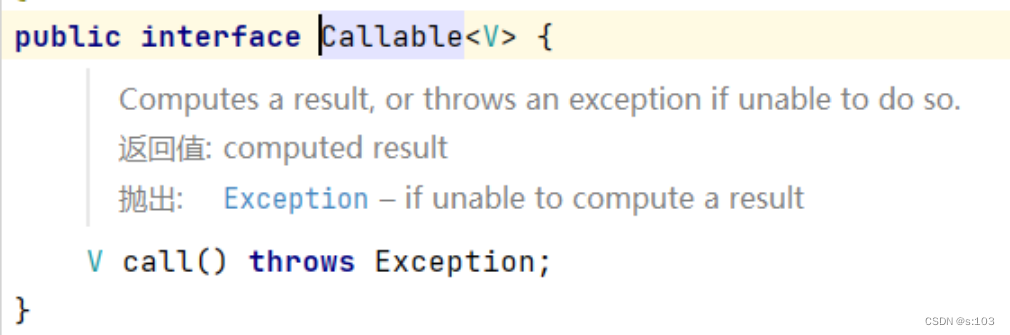
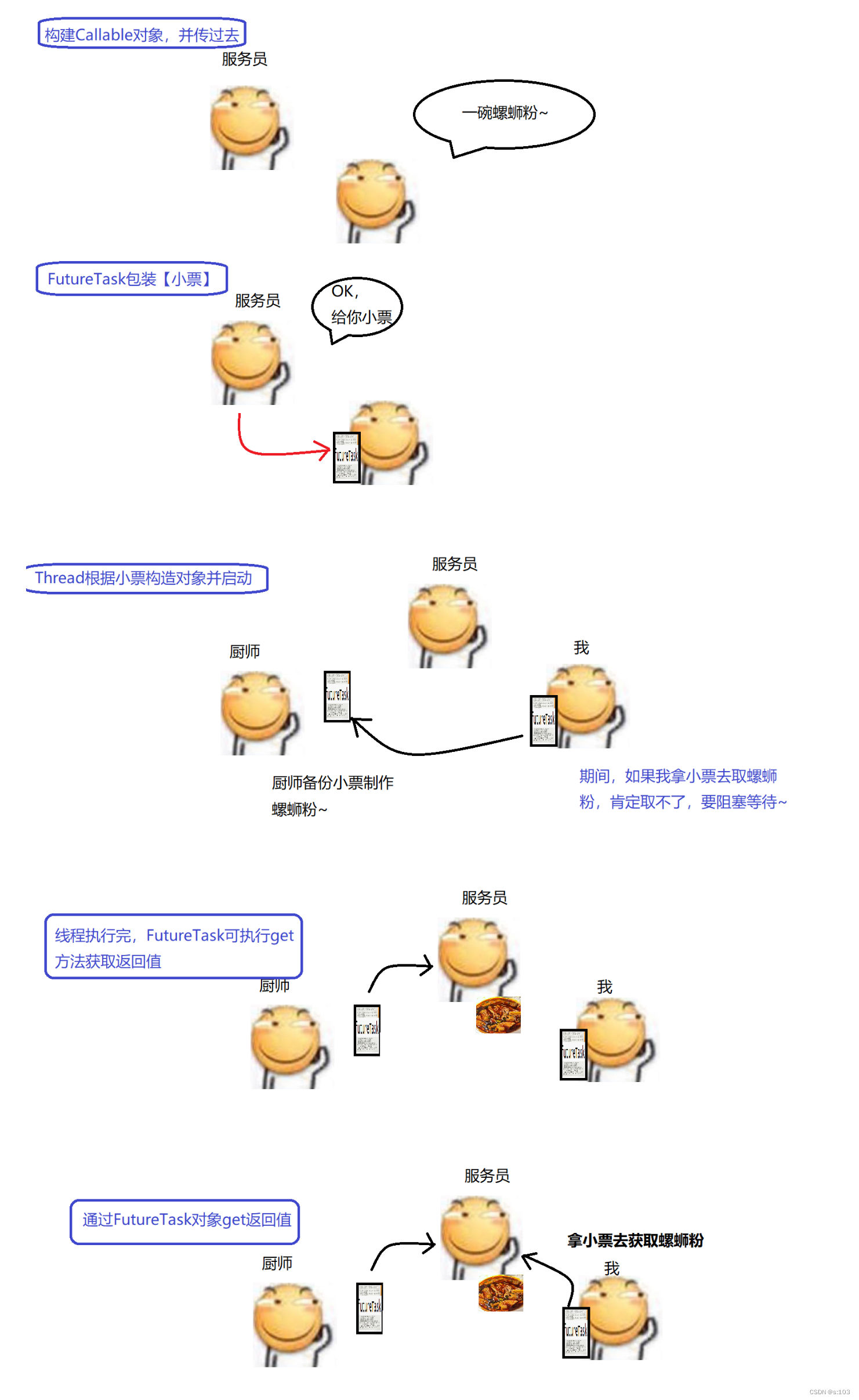
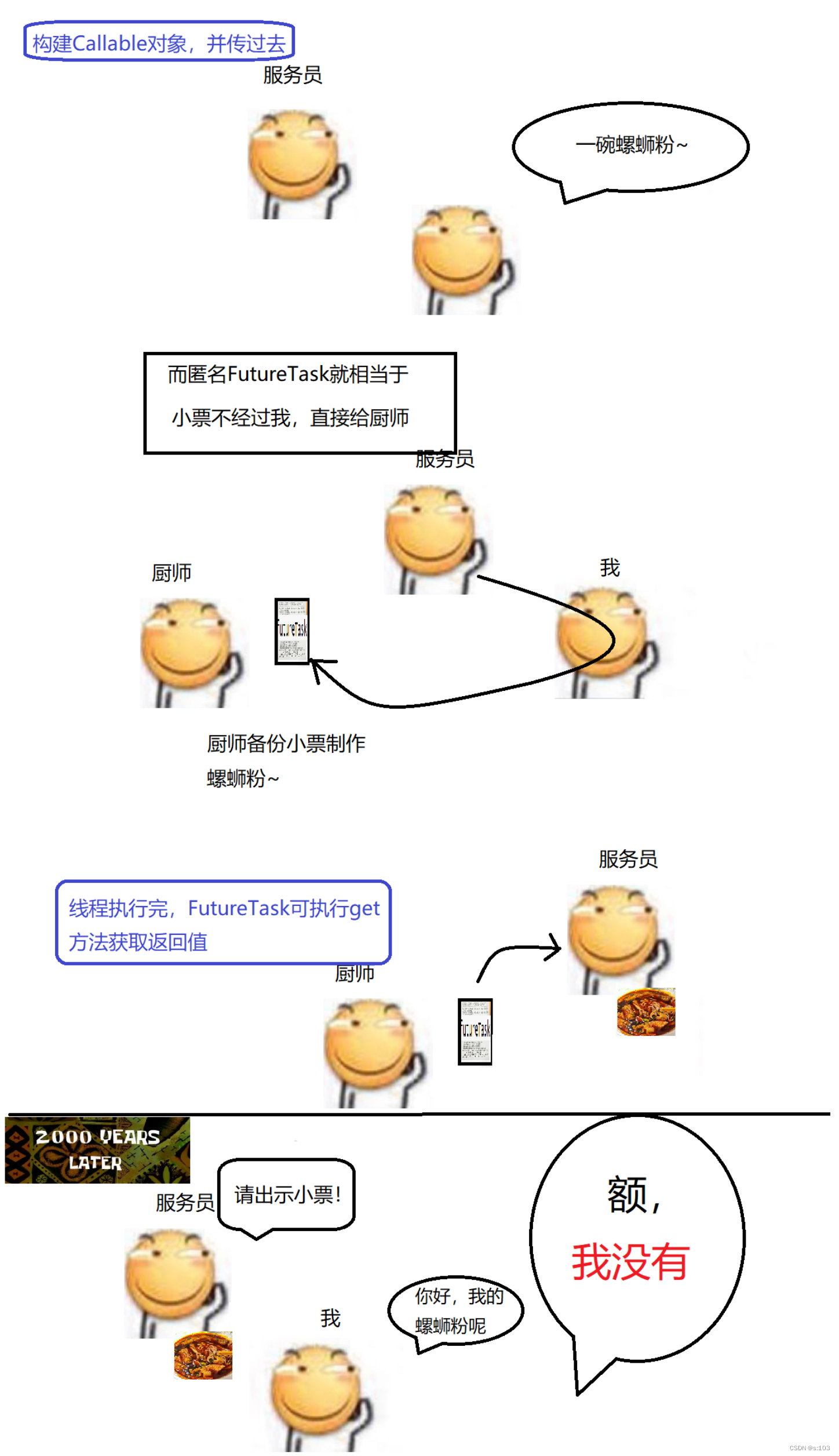
而Callable对象是不能直接传给Thread构造方法的,“Callable” ===> 仅仅只能“可召唤的”

将这个任务传给Thread的构造方法就OK了~
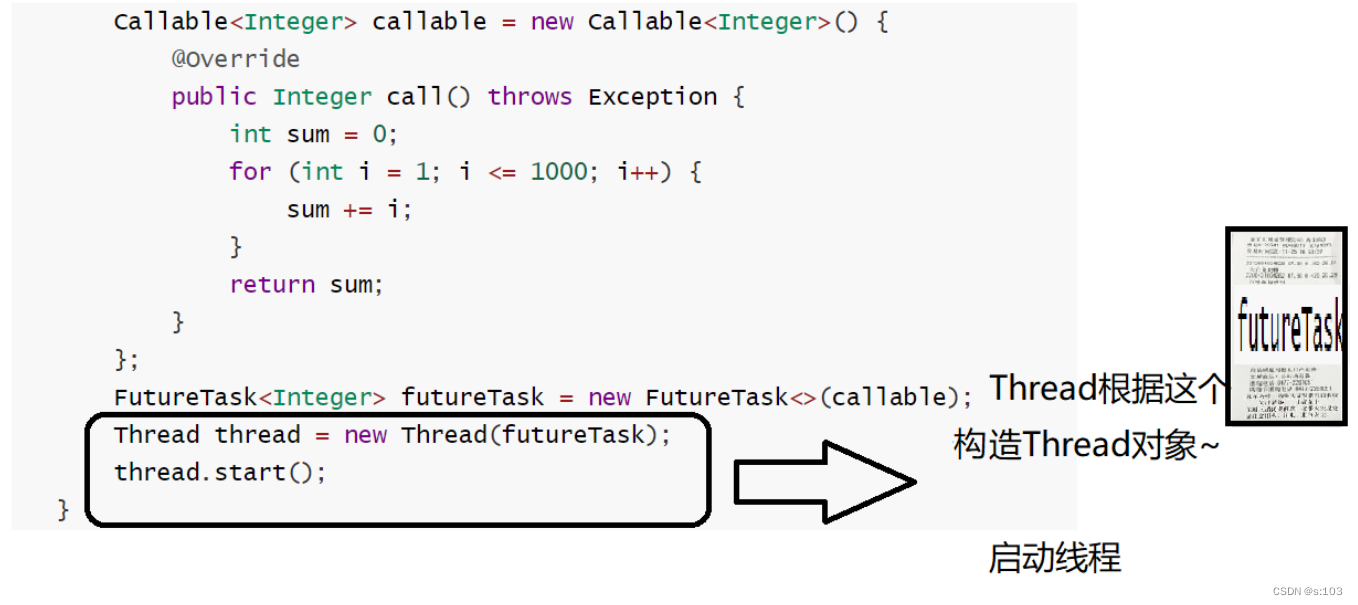
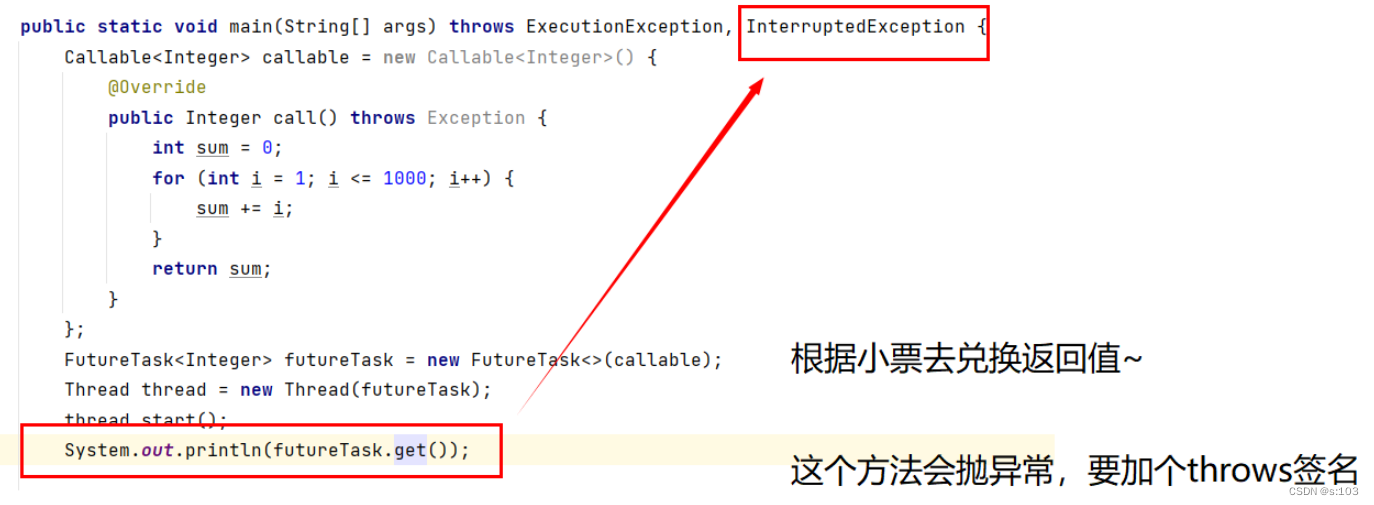
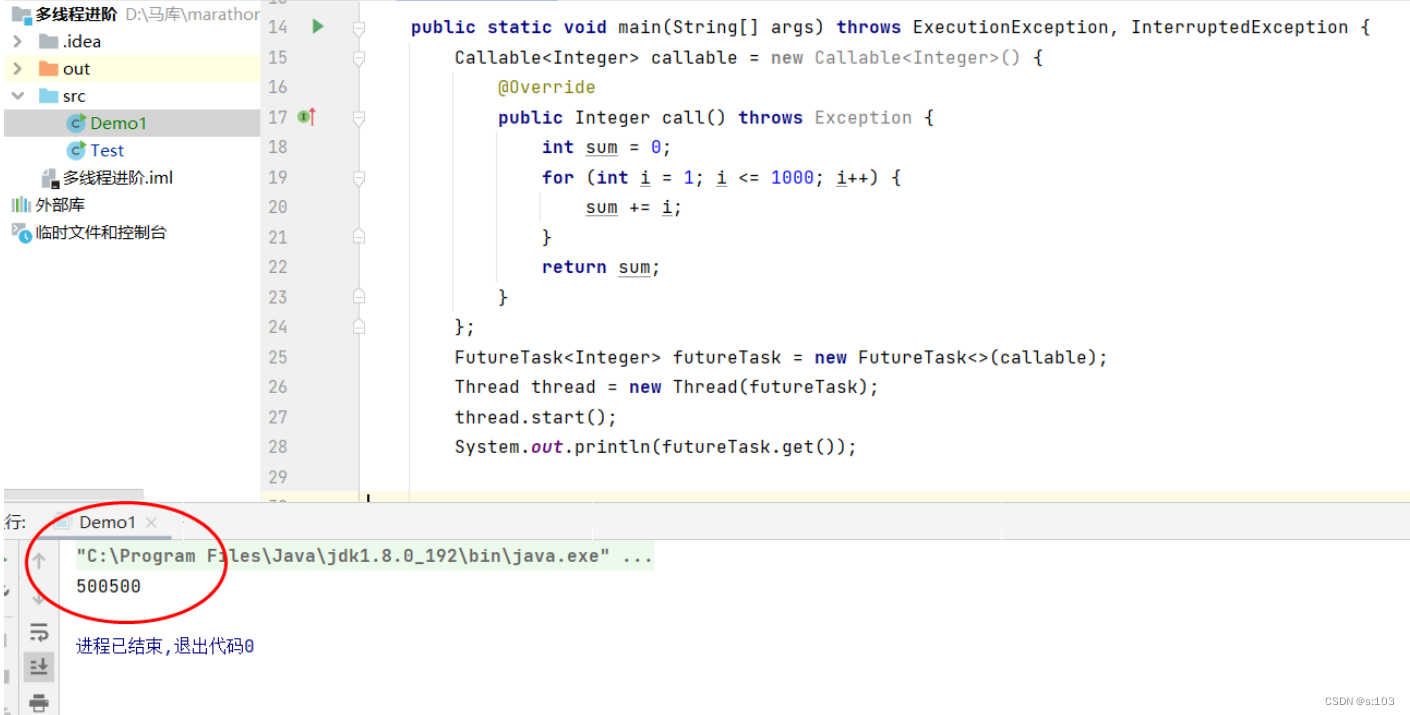
Thread thread = new Thread(new FutureTask<Integer>(() -> {
int sum = 0;
for (int i = 1; i <= 1000; i++) {
sum += i;
}
return sum;
}));
thread.start();
那么就不符合我们要获得返回值的需求

ReentrantLock是一个重要的补充!


顺便提一嘴:
一些公司有一些编程规范,要求不能使用Executors去构造线程池,得用ThreadPoolExecutor去构造
你以后开公司也可以规范:“打工人们,你们只能用Executors去构造线程池!”

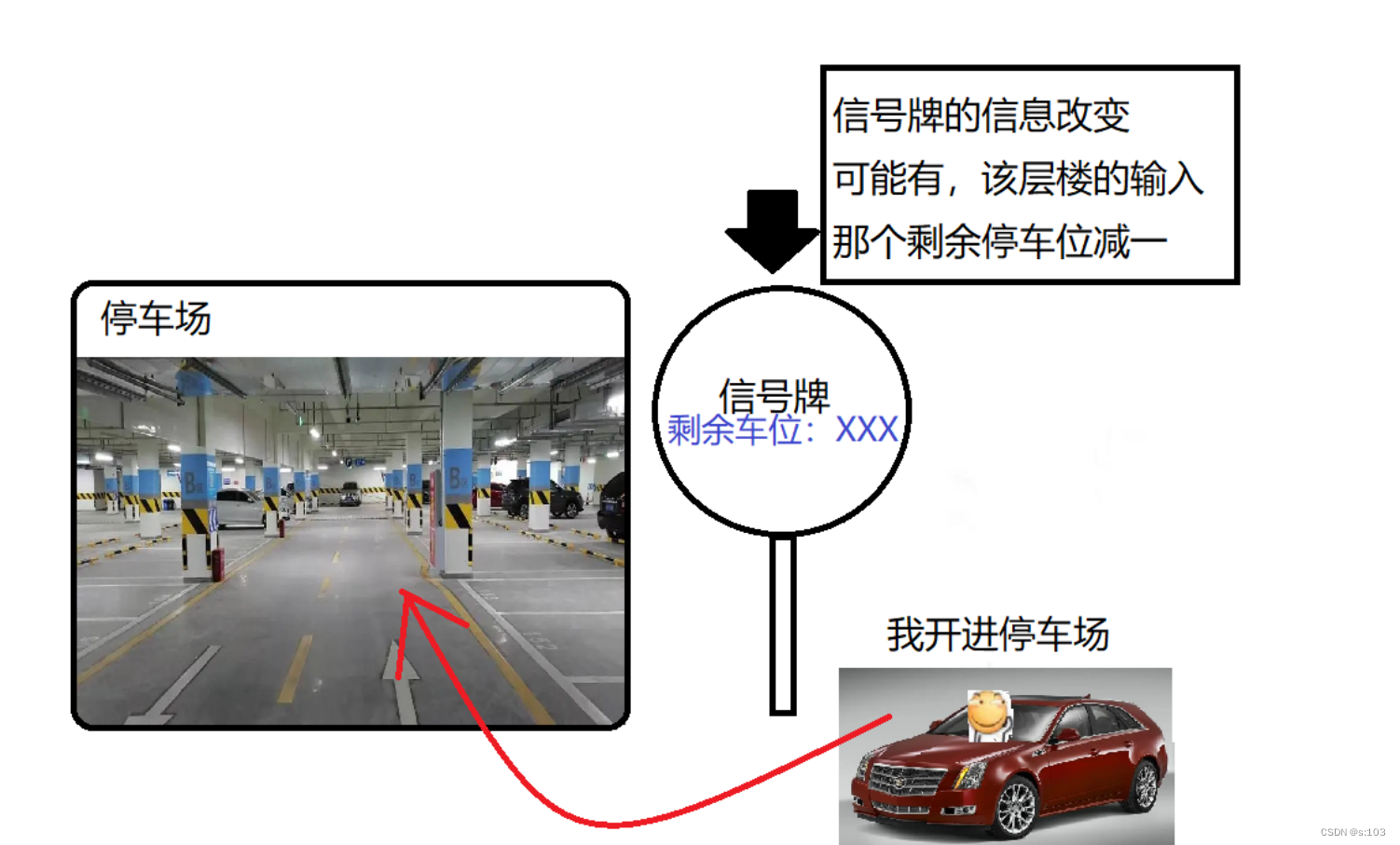
如果信号牌显示剩余为0,我就无法进入停车场,只能阻塞等待~
Semaphore本质其实就是个特殊的计数器,描述“可用资源”个数
所谓的“锁”本质上就是个计数器为1的信号量 Semaphore对象
取值要么是0,要么是1,===> 二元信号量
所以,信号量 Semaphore是更广义的锁~
CountDownLatch ==> 倒数弹簧锁
指的是多个线程运行的倒数一名线程结束,锁才能解除~
- 是特别针对特有的场景组件!

比如下图的下载任务1 2 3 4
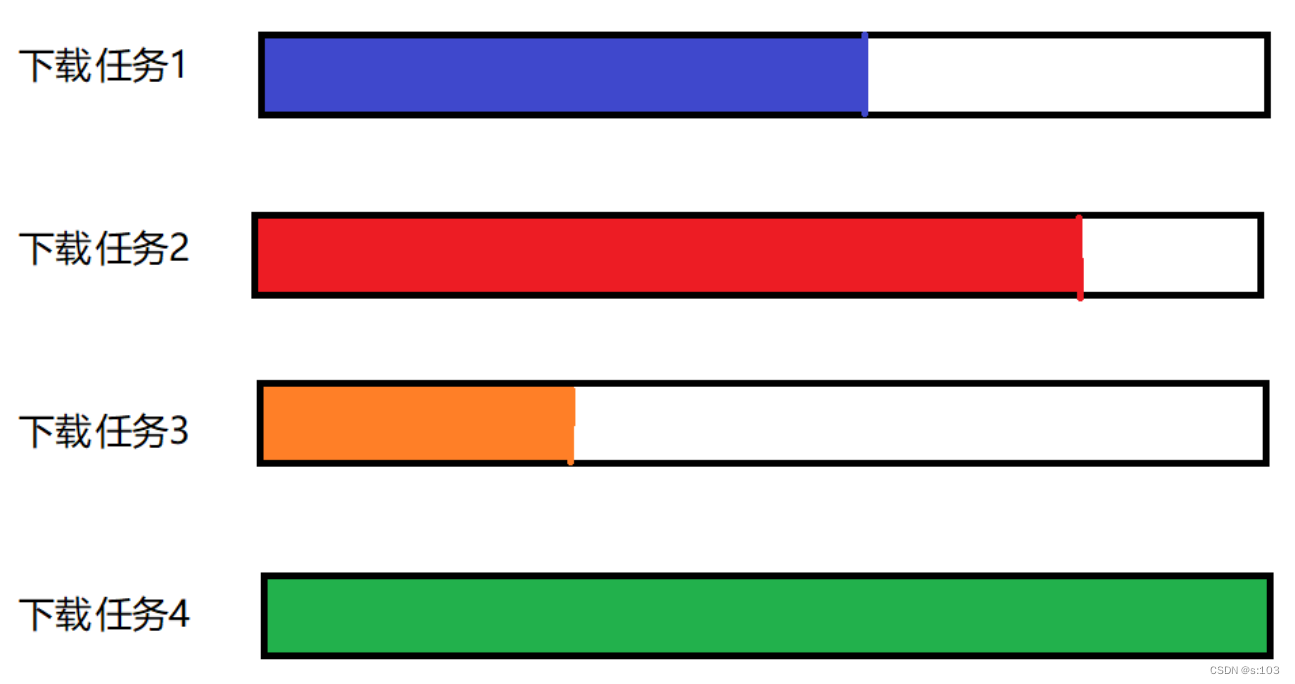
显然,下载完毕应该是所有的线程,都把对应的资源下载好才算下载完毕~
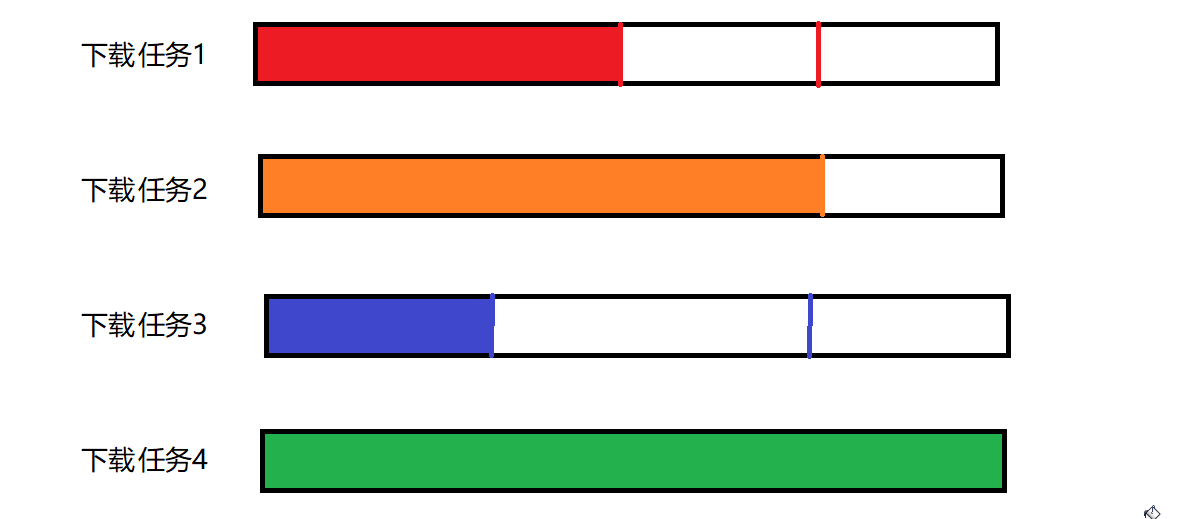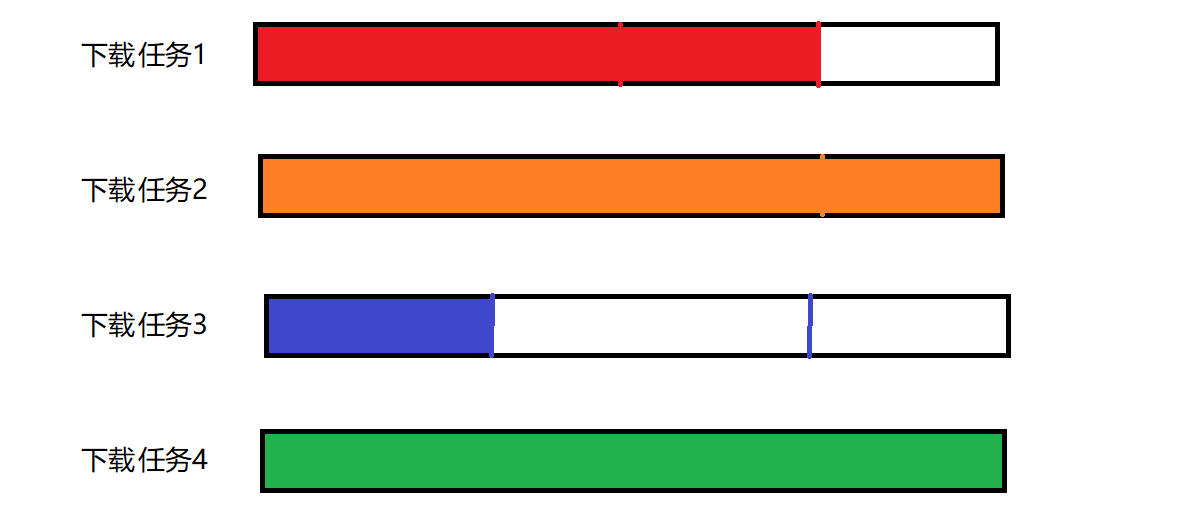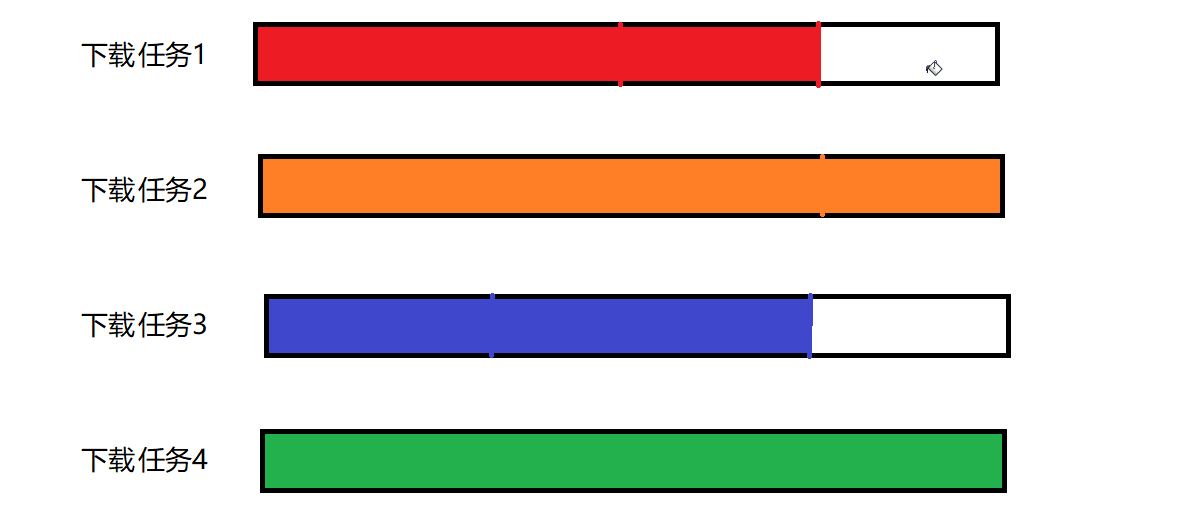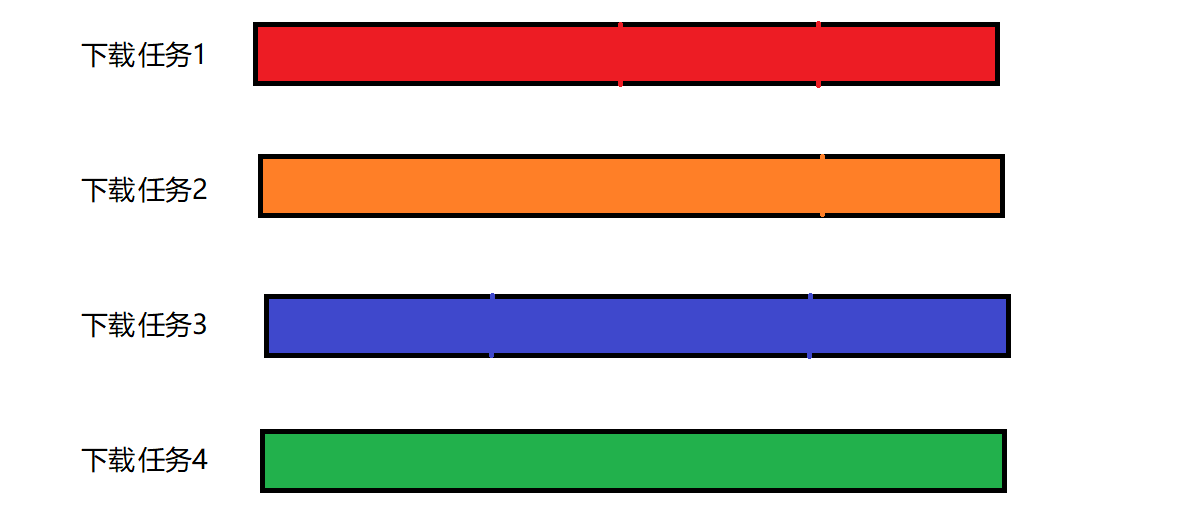
使用方式:
static int count = 0;
static Object object = new Object();
public static void main(String[] args) throws InterruptedException {
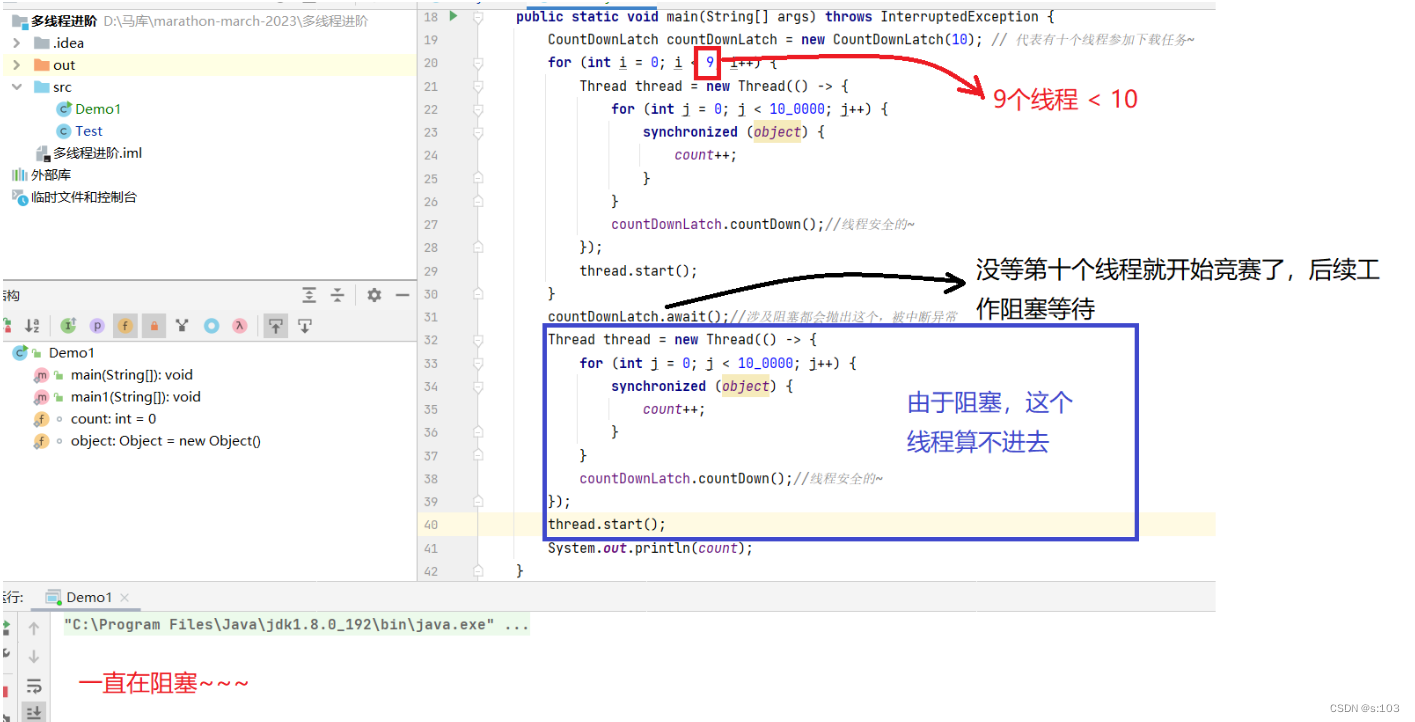
CountDownLatch countDownLatch = new CountDownLatch(10); // 代表有十个线程参加下载任务~
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(() -> {
for (int j = 0; j < 10_0000; j++) {
synchronized (object) {
count++;
}
}
countDownLatch.countDown();//线程安全的~
});
thread.start();
}
countDownLatch.await();//涉及阻塞都会抛出这个,被中断异常
System.out.println(count);
}
在此对象所在的线程里,创建十个线程
然后构造CountDownLatch对象,---- 传入竞赛的线程数
然后调用countDownLatch.await()方法
如果参赛选手不够,main线程就会一直等第10个人下场,那当然等不到呀~

这种只有顺序表有~
这个是不通过加锁实现的线程安全
而是通过 — 多个线程修改不同变量~
顾名思义:修改的时候 就 拷贝一份
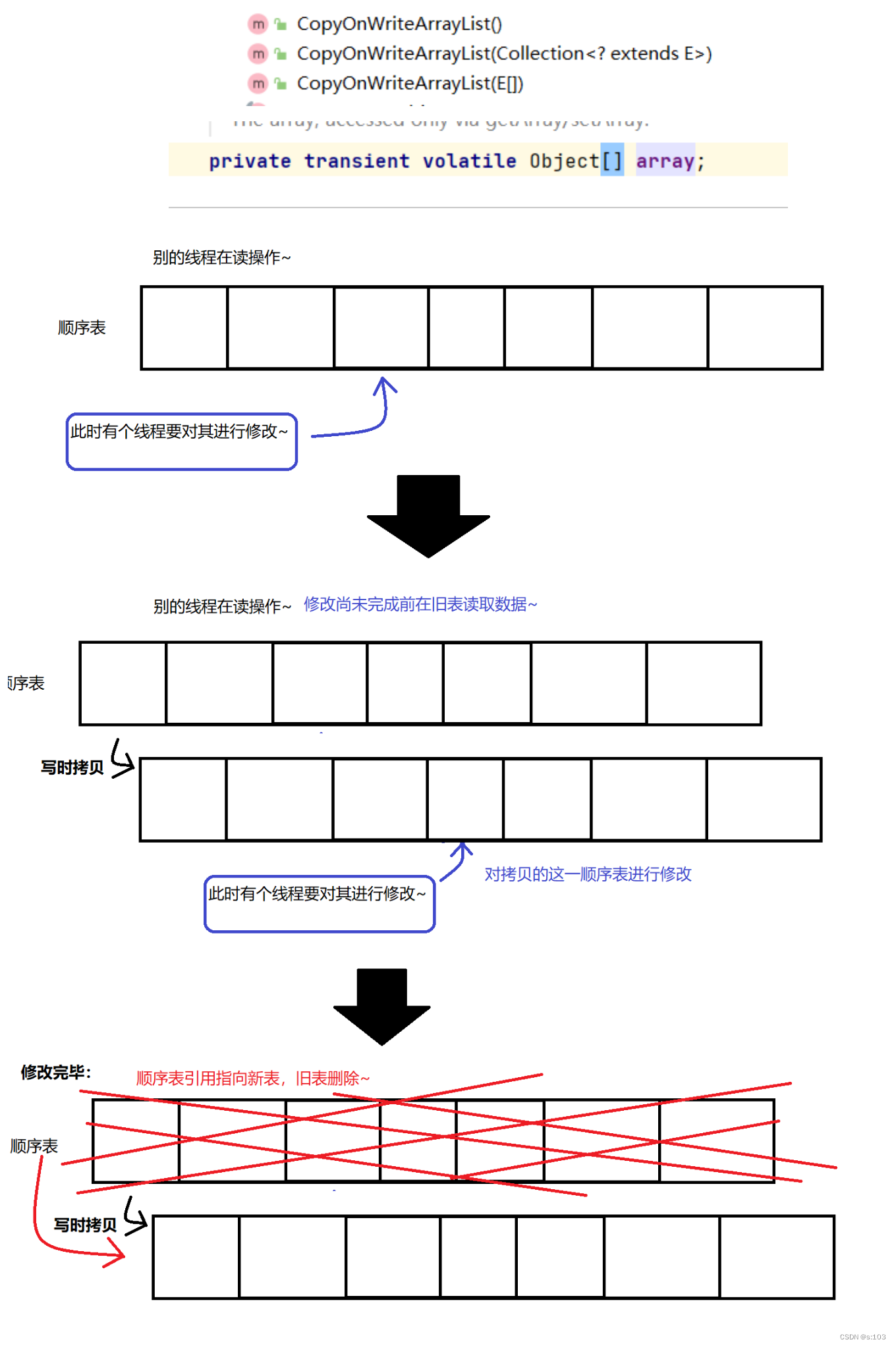
一个例子:

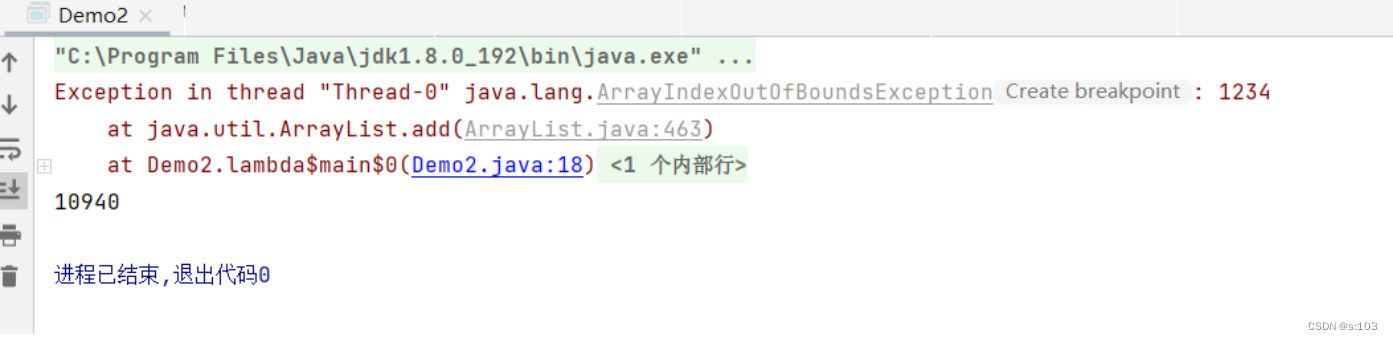
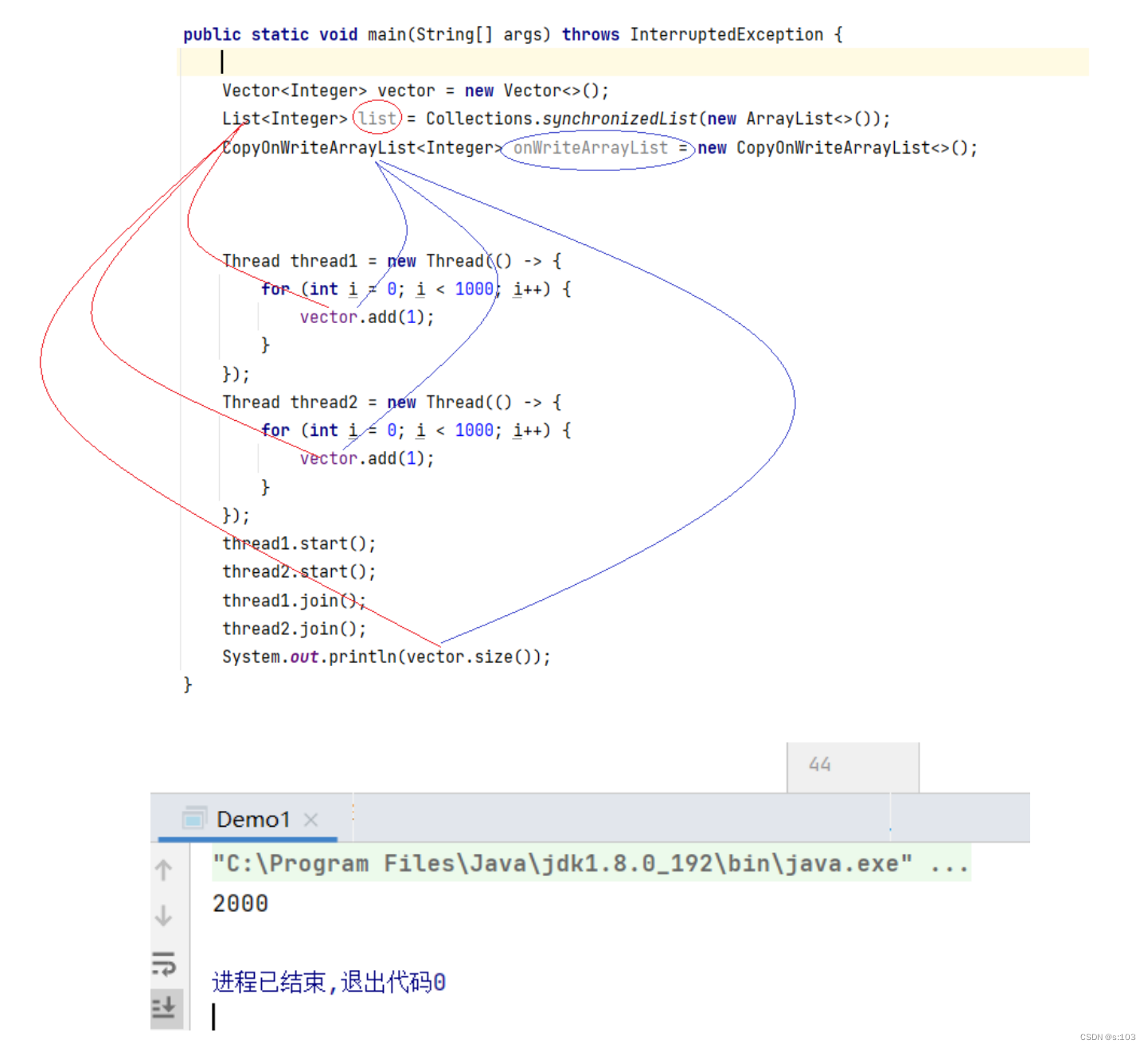
public static void main(String[] args) throws InterruptedException {
List<Integer> arrayList = new ArrayList<>();
arrayList.add(1);
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
arrayList.add(1);
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
arrayList.add(1);
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(arrayList.size());
}
结果:
手动加锁:
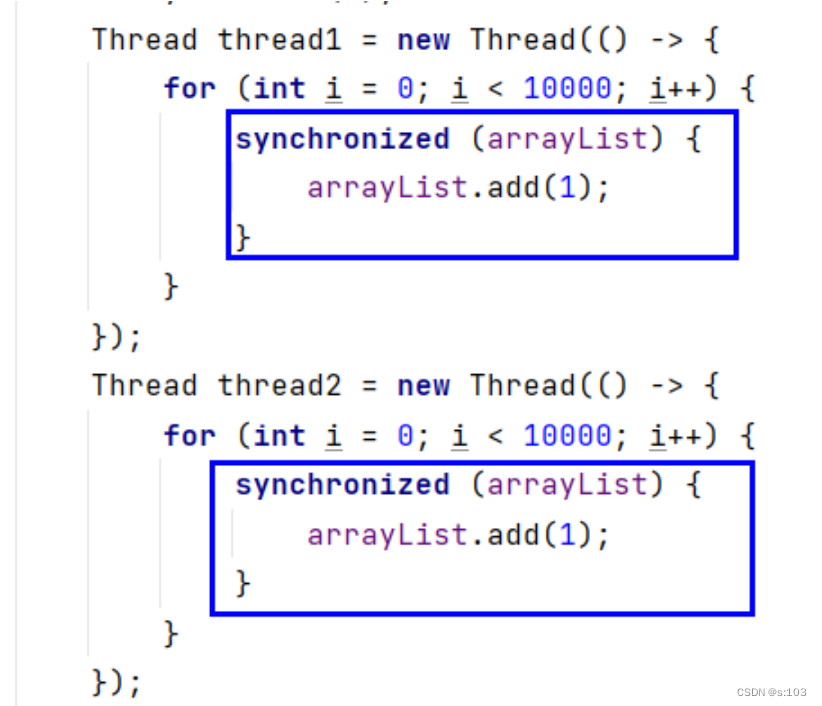

public static void main(String[] args) throws InterruptedException {
Vector<Integer> vector = new Vector<>();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
vector.add(1);
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 1000; i++) {
vector.add(1);
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(vector.size());
}
public static void main(String[] args) throws InterruptedException {
Vector<Integer> vector = new Vector<>();
vector.add(0);
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
vector.set(0, vector.get(0) + 1);
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
vector.set(0, vector.get(0) + 1);
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(vector);
}
必须手动套锁这些操作:
其他方式也一样:

Queue ==> BlockingQueue
Deque ==> BlockingDeque
PriorityQueue ==> PriorityBlockingQueue
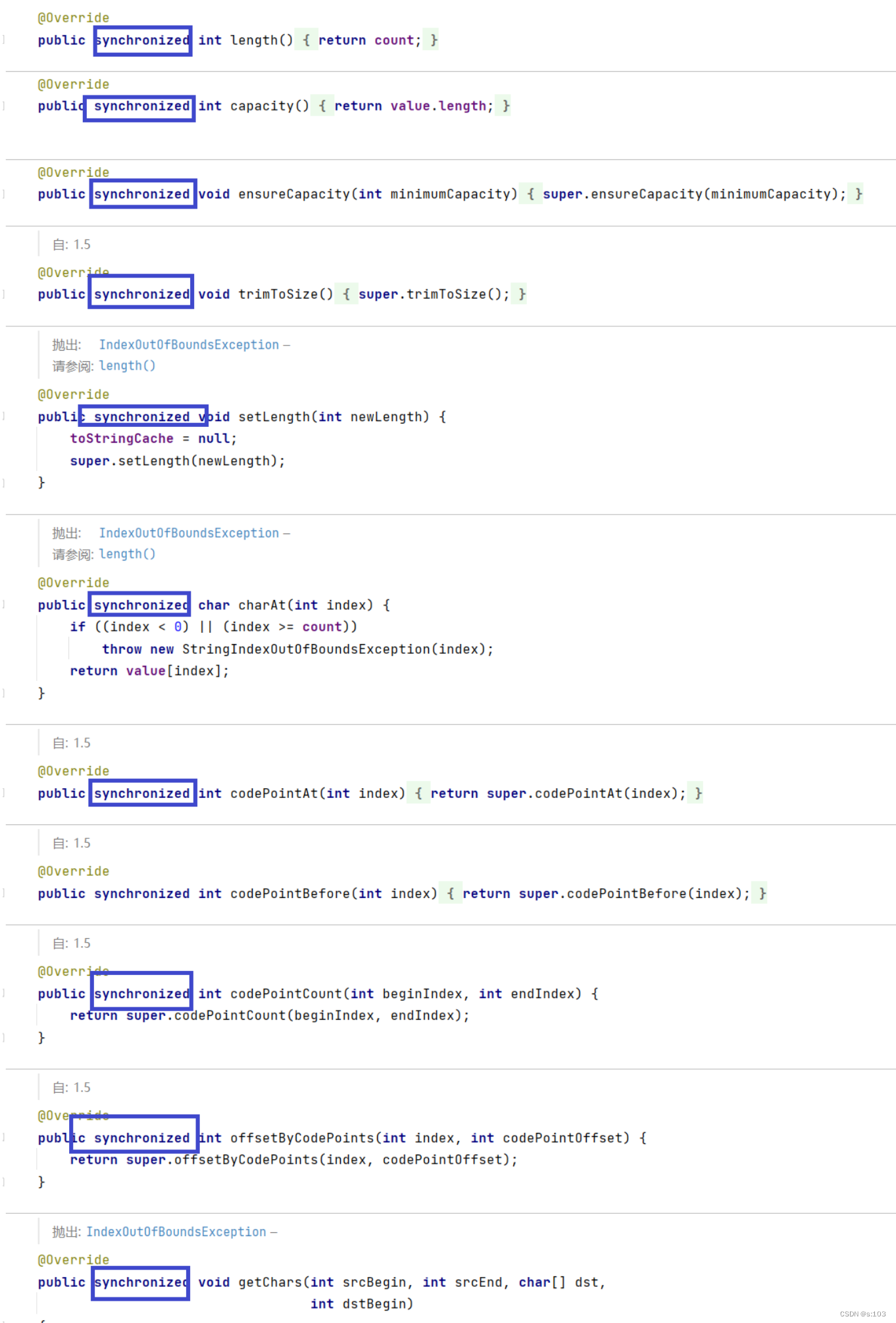
HashTable很简单粗暴,给关键方法加synchronized,针对整个表加锁
ConcurrentHashMap对局部进行加锁
HashTable是针对整个哈希表加锁,任何增删改查都会触发锁竞争!
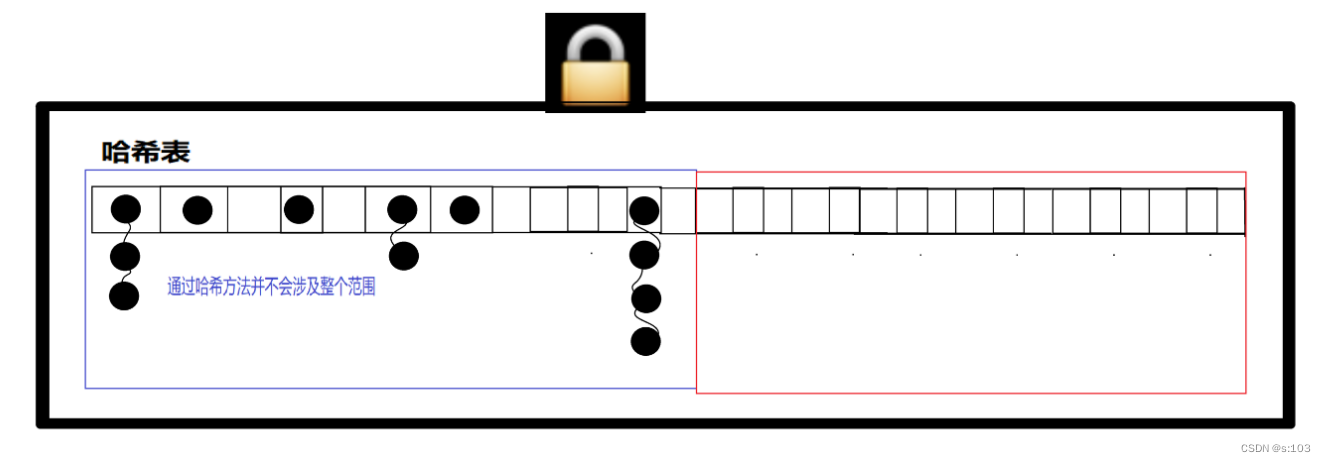
ConcurrentHashMap则很好的解决这一点,它降低了锁的粒度,让每一个链表都分配一把锁,这样线程修改不同链表,不会触发锁的阻塞等待
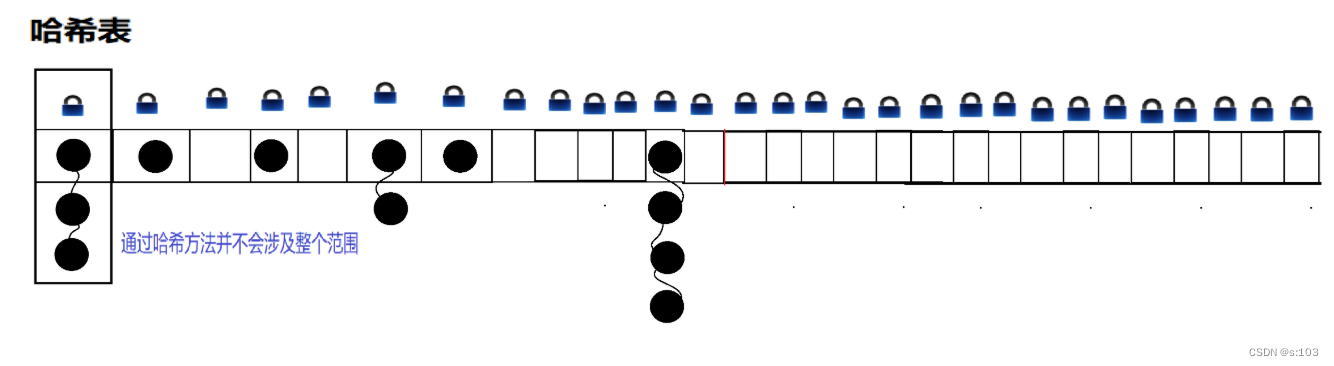
补充:java1.7之前ConcurrentHashMap用的是分段锁,java1.8之后则是每个链表都有一把锁
分段锁:
有的操作,例如获取 / 更新元素个数,就可以直接使用CAS完成,不必加锁~
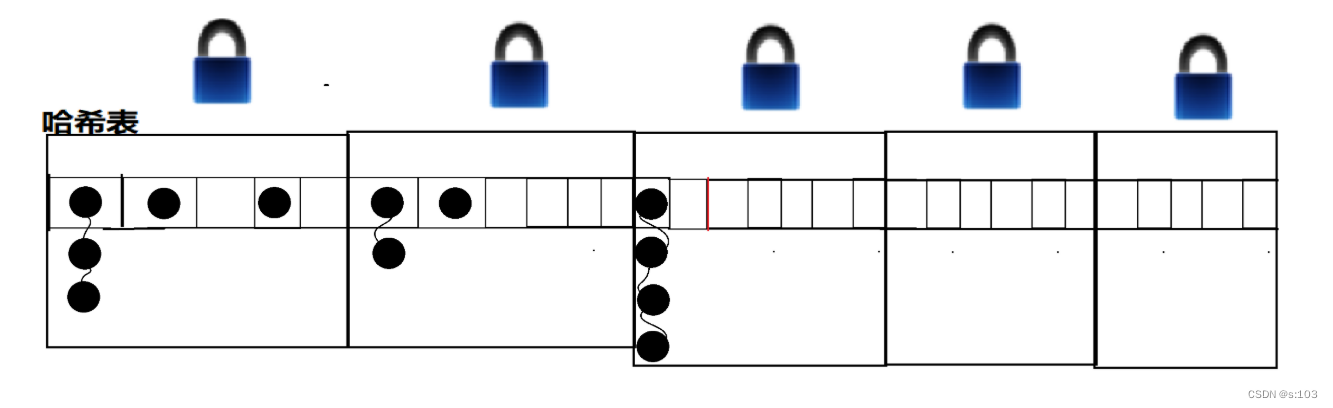
哈希表由于负载因子的原因,元素达到一定个数就会触发扩容机制
HashMap以及HashTable都没有解决这个问题
而ConcurrentHashMap很好解决了这个问题
也就是说当我们 put 触发扩容的时候,就会创建一个更大的内存空间,并不会把所有元素都搬运过去,也不会删除原表
我们现在就拥有两份hash表~
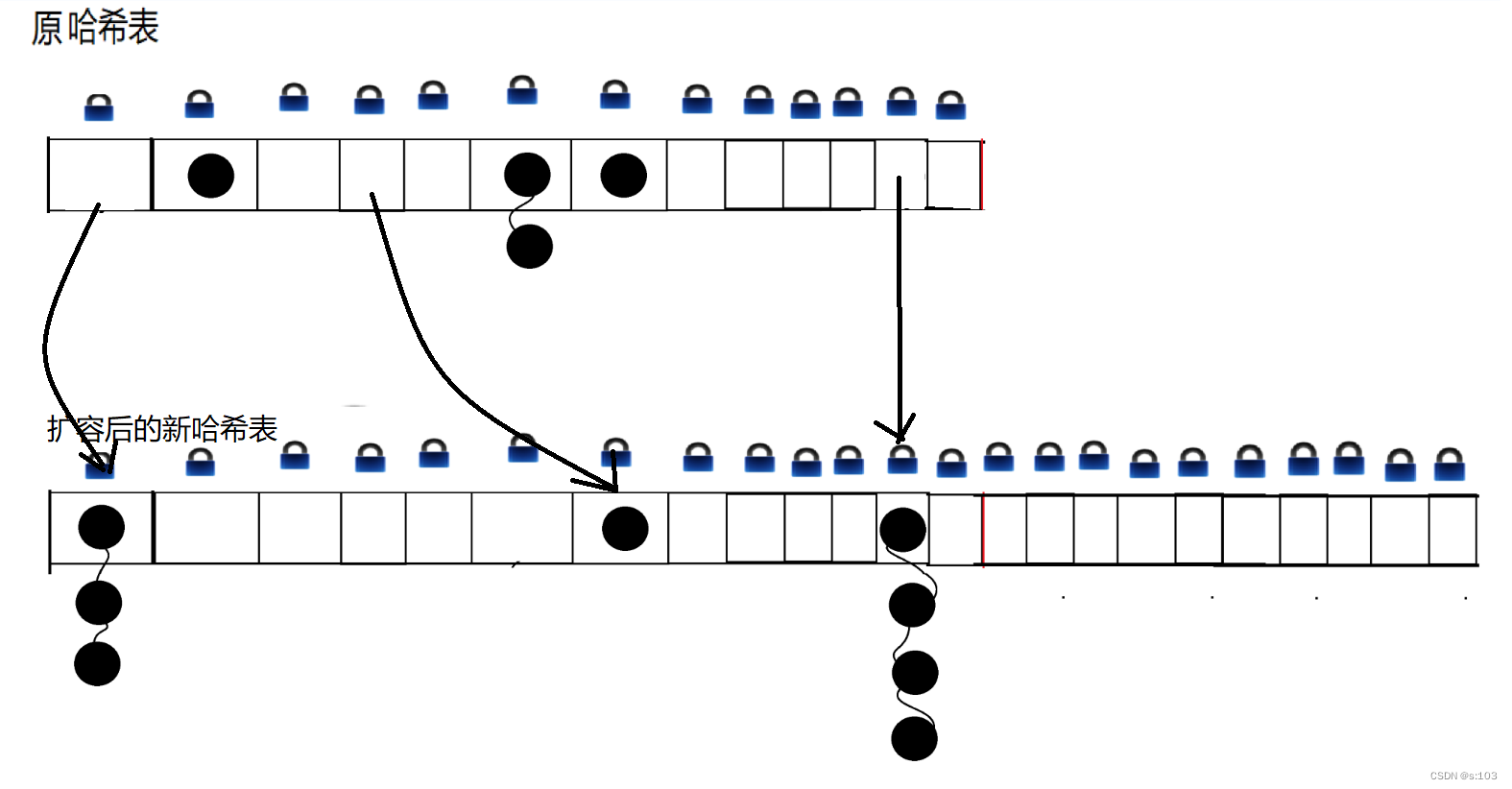
并且在每次操作过程中,哈希表都会再运一些过去~
补充:Set本身就是个Map,只不过key对应value不重要~
public static void main(String[] args) throws InterruptedException {
Map<Integer, Integer> map1 = new HashMap<>();
Map<Integer, Integer> map2 = new Hashtable<>();
Map<Integer, Integer> map3 = new ConcurrentHashMap<>();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 1000000; i++) {
map1.put(i % 1000, i);
map2.put(i % 1000, i);
map3.put(i % 1000, i);
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 1000000; i++) {
map1.put(i % 1000, i);
map2.put(i % 1000, i);
map3.put(i % 1000, i);
}
});
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println(map1.size());
System.out.println(map2.size());
System.out.println(map3.size());
System.out.println(map1);
System.out.println(map2);
System.out.println(map3);
//ConcurrentHashMap和HashTable打印方法不同,刚好相反~
}
测试结果:
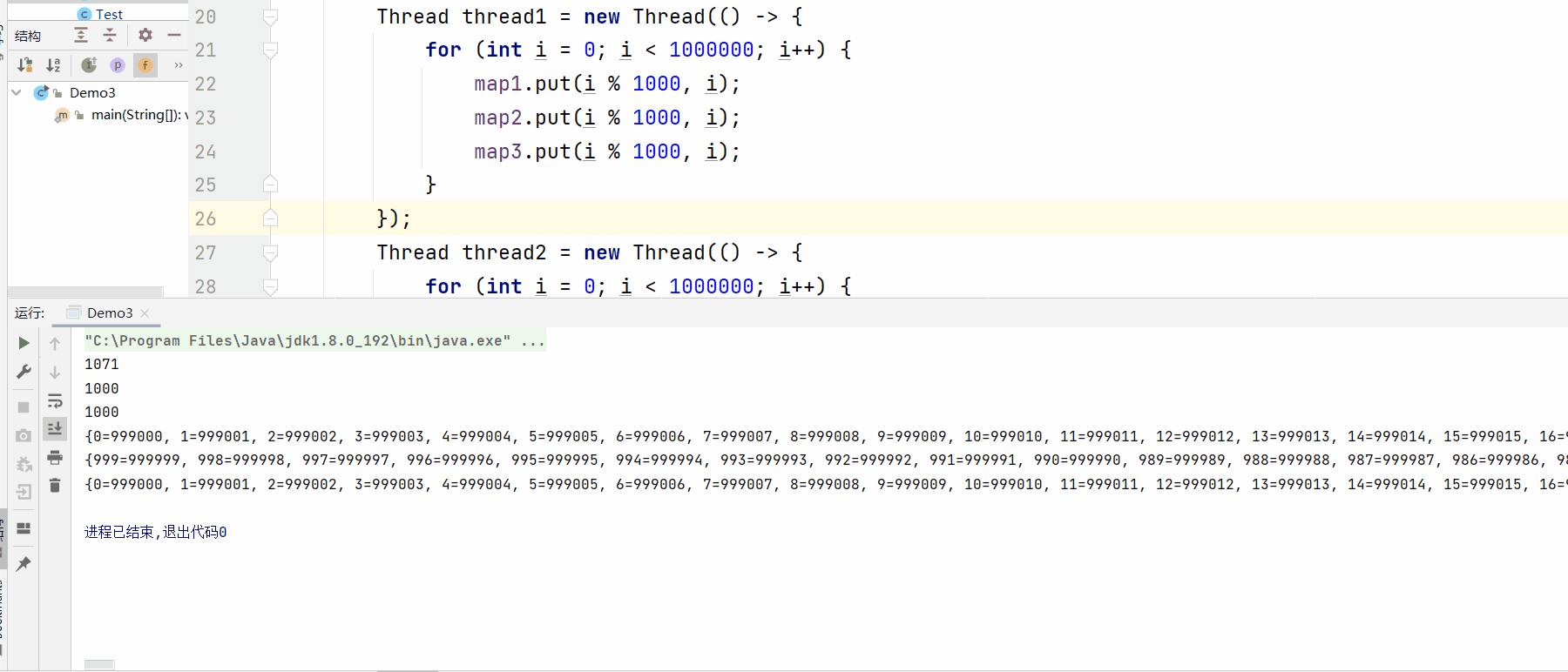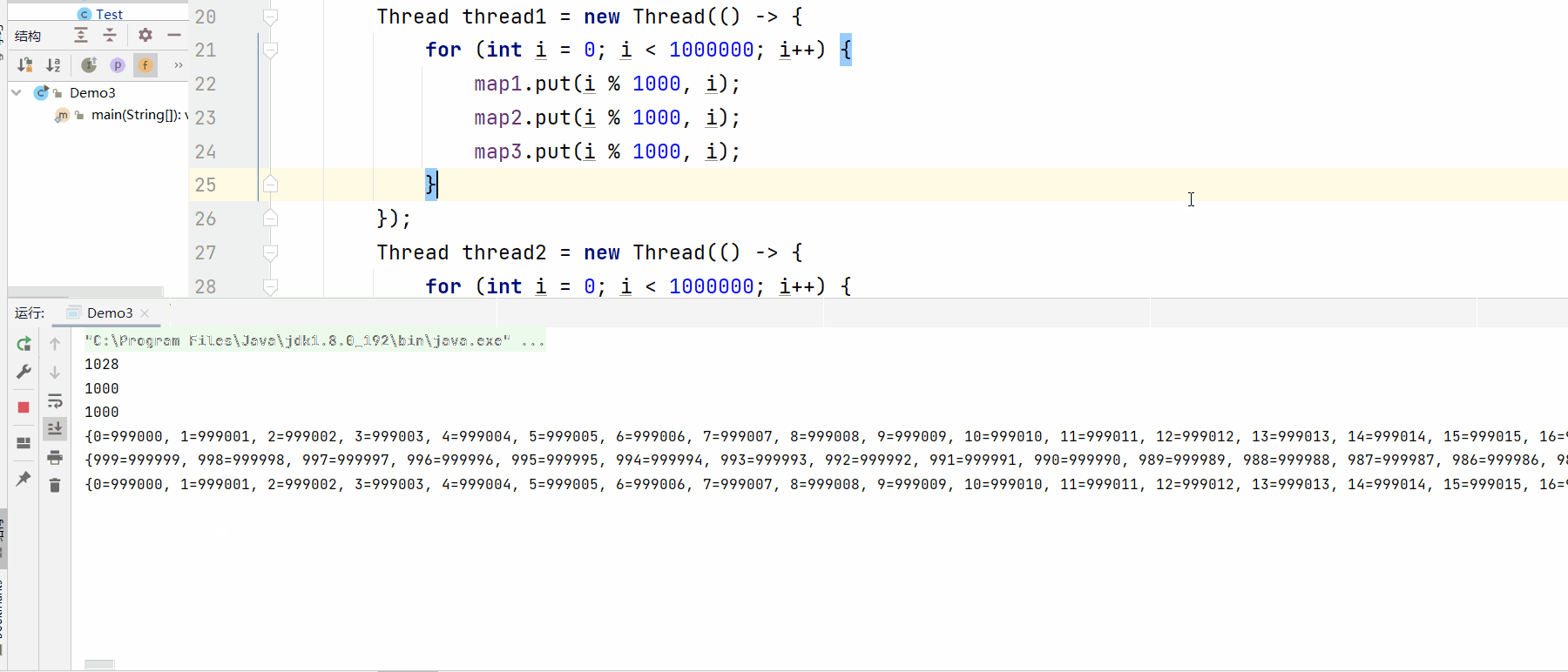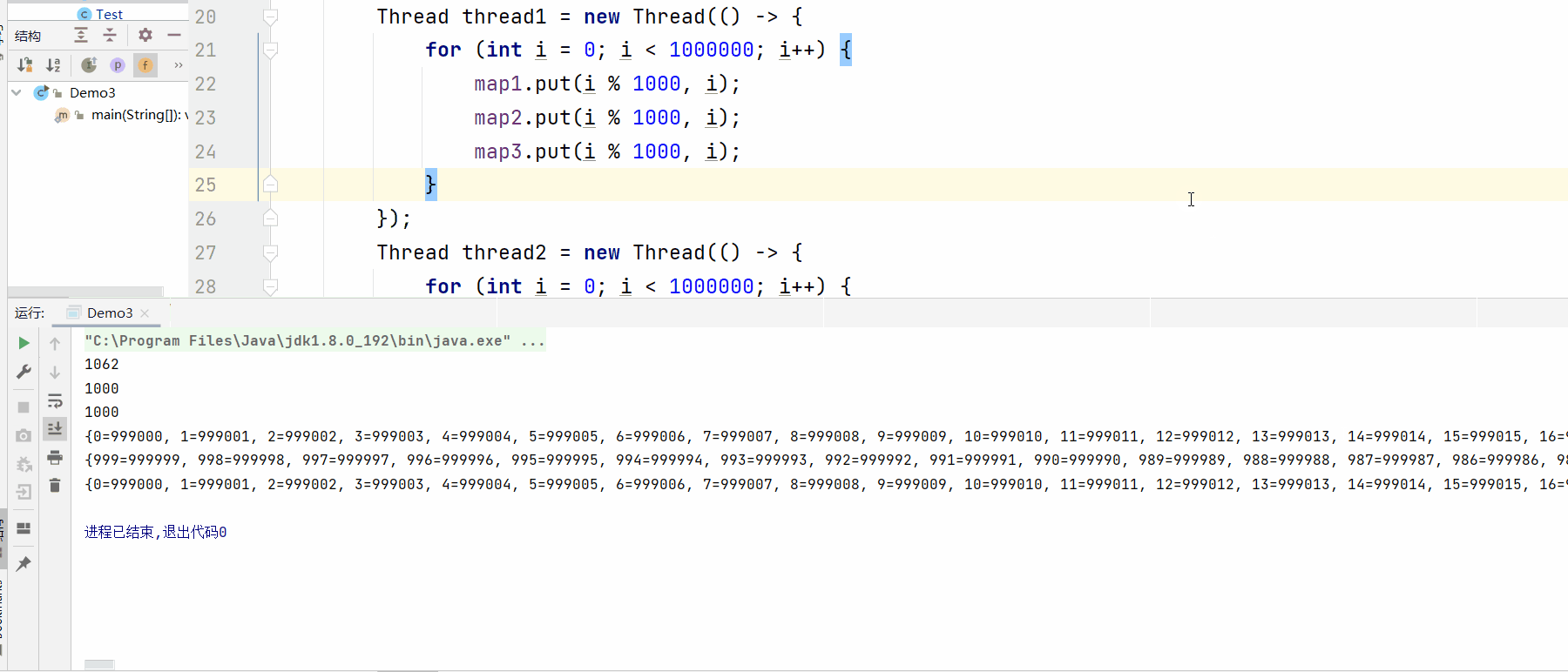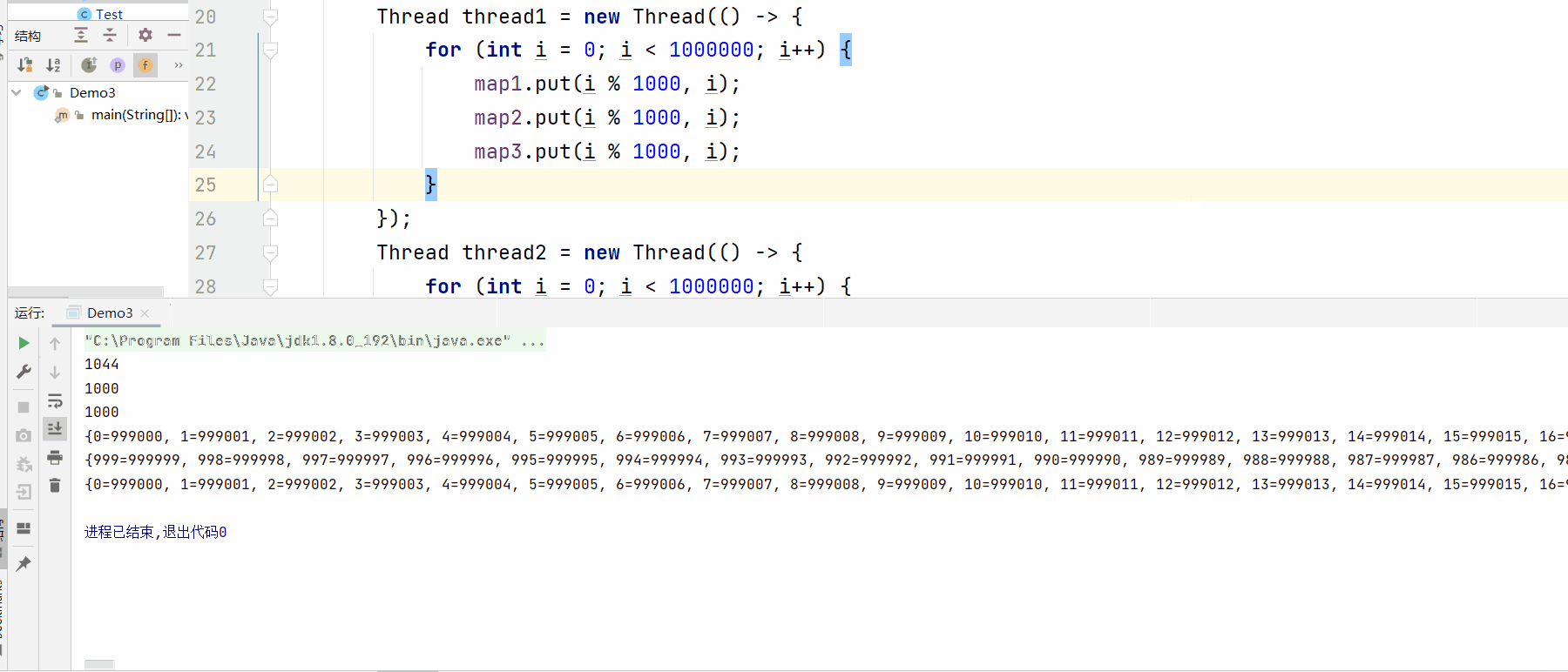
测试:
public static void main(String[] args) throws InterruptedException {
StringBuilder stringBuilder = new StringBuilder();
StringBuffer stringBuffer = new StringBuffer();
Thread t1 = new Thread(() -> {
for (int i = 0; i< 5000; i++) {
stringBuffer.append(1);
stringBuilder.append(1);
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 5000; i++) {
stringBuffer.append(1);
stringBuilder.append(1);
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(stringBuilder.length());
System.out.println(stringBuffer.length());
}
测试结果:
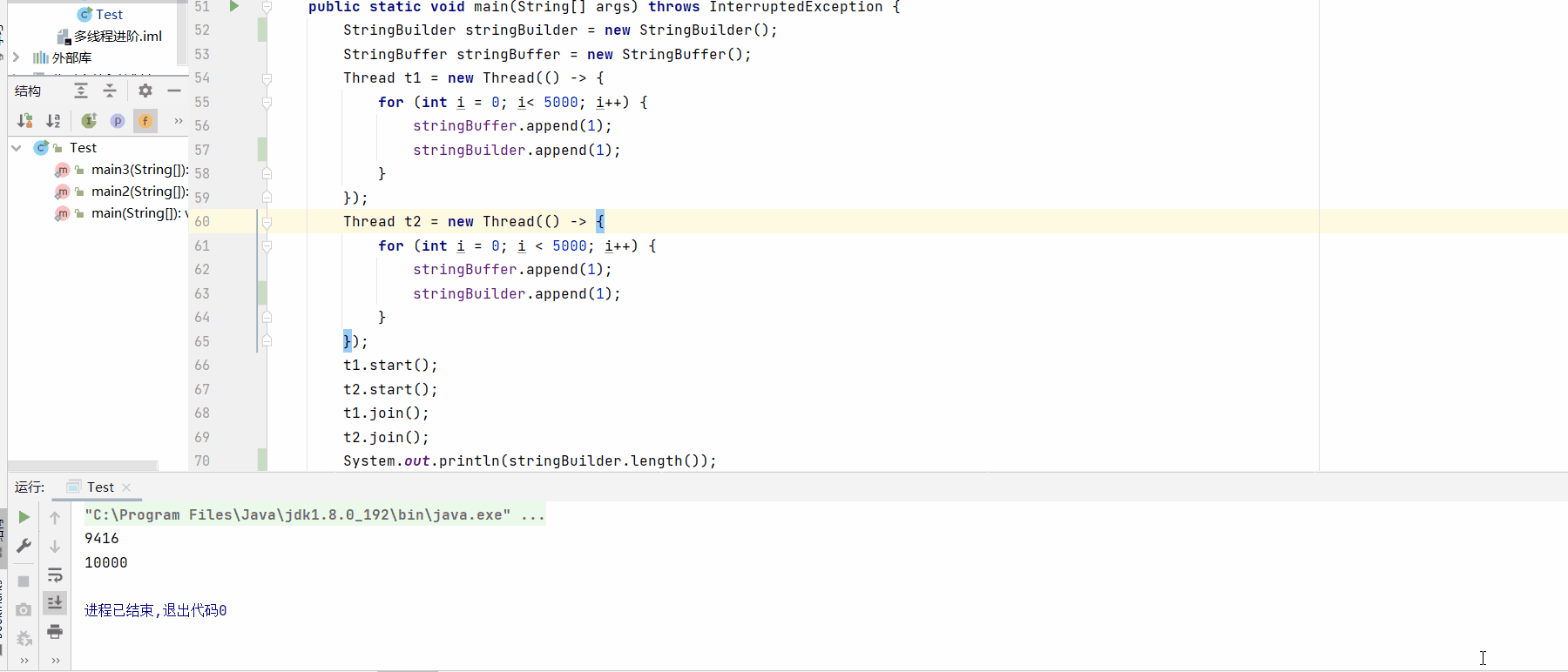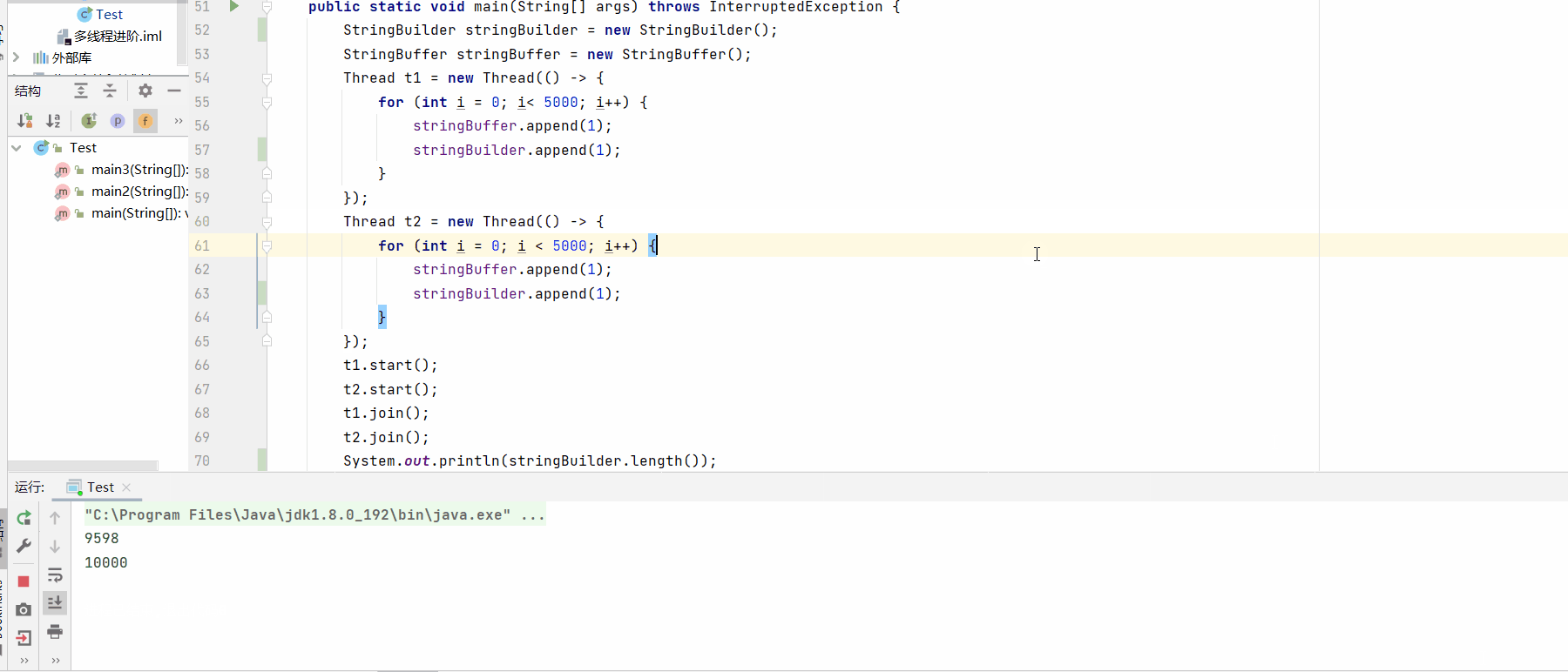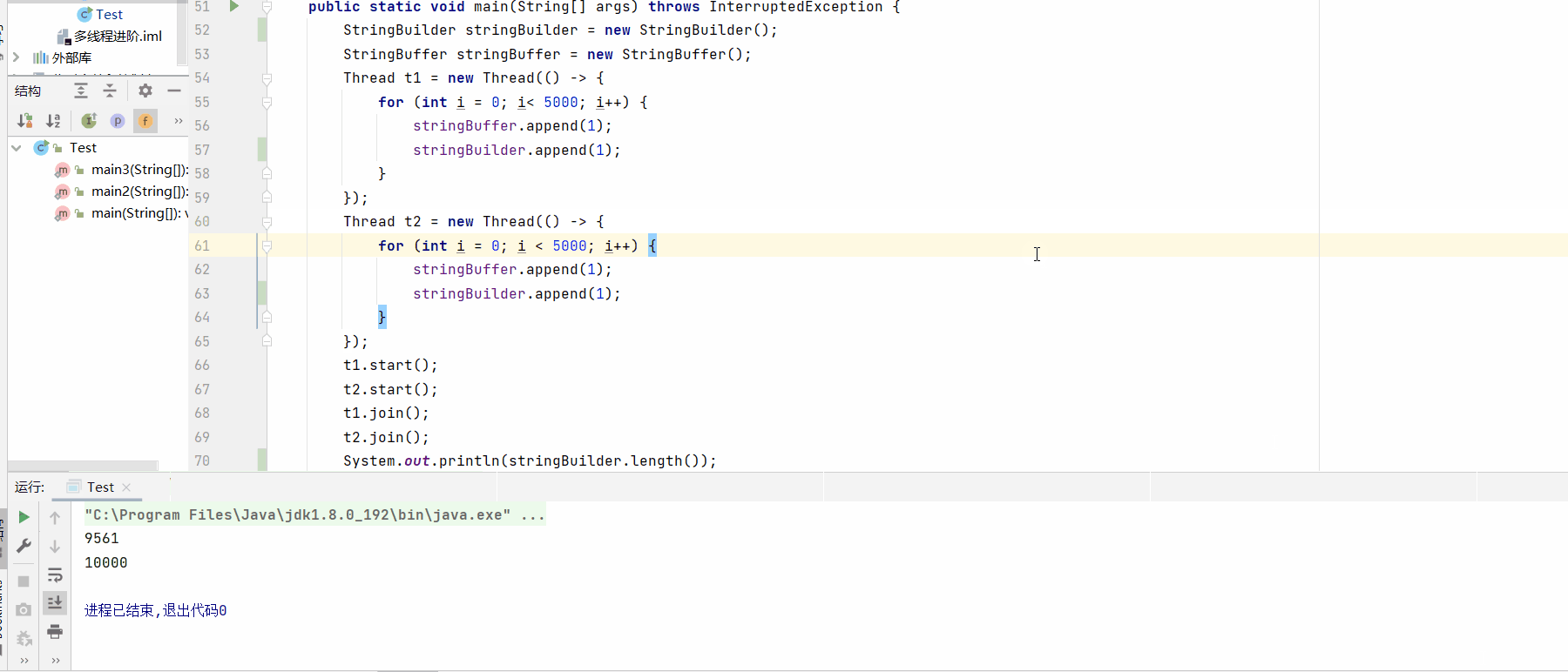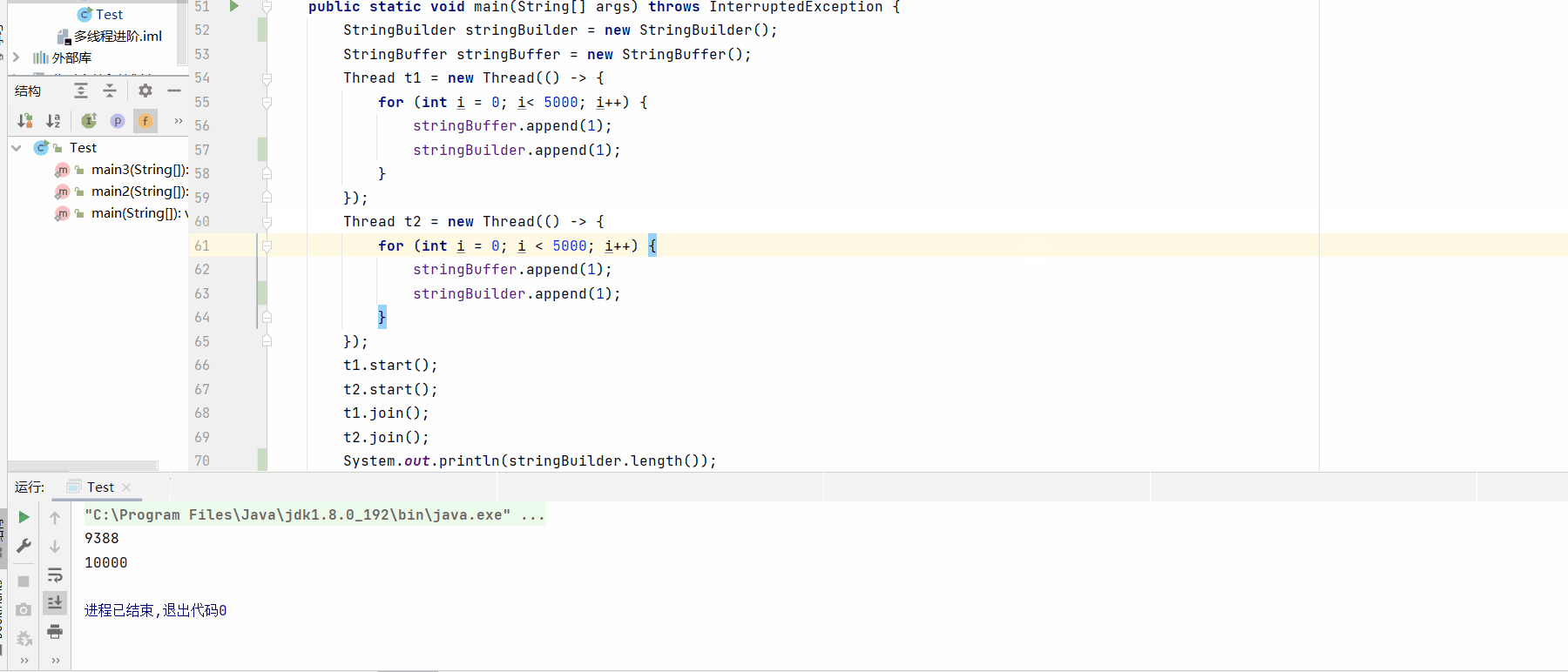
文章到此结束!谢谢观看 可以叫我 小马,
我可能写的不好或者有错误,但是一起加油鸭🦆!
多线程的讲解完结撒花✿✿ヽ(°▽°)ノ✿
但这是结束也是开始,多线程是JavaEE编程的重要手段!
敬请期待后续内容!
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer