执行步骤:
snyc给主服务器bgsave操作,将生成RDB文件,将生成的RDB文件同步给从服务。并使用一个缓冲区记录从现在开始的写命令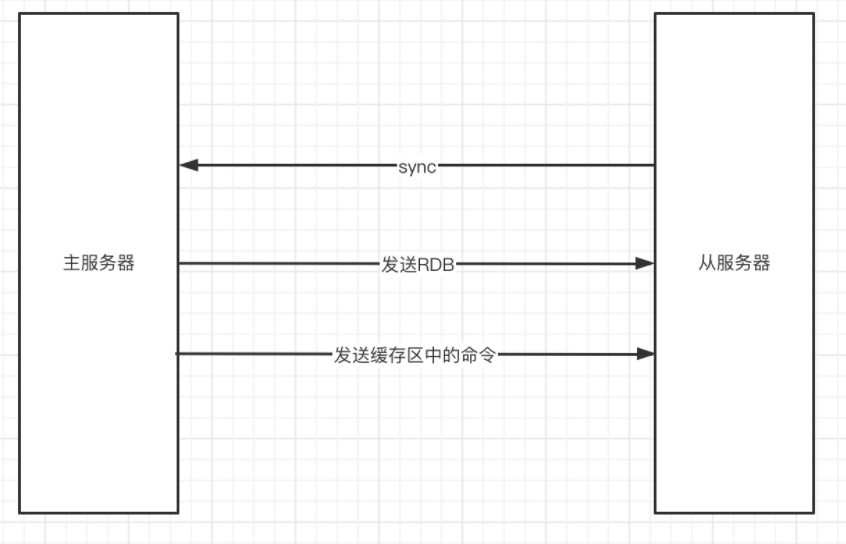
同步完成之后,后续的命令都是通过传播的方式发送给从服务器的。即当主服务执行完一条命令后,将该命令发送给从服务,完成数据的同步。
场景:
sync进行全量的复制,这就是很耗费资源的。毕竟如果断开时间短,如中间网络抖动,导致中间短暂性断开,再次复制全量数据,成本太高。关于sync命令:
bgsave命令来生成RDB文件,这个操作会耗费主服务器的大量CPU、内存和磁盘IO资源。psnyc具备完整重同步(full resynchronization)和部分重同步(partial resynchronization)。
其中,完整重同步和sync的首次同步是一致的,通过主服务器生成RDB文件进行全量数据的同步,如果存在多个从服务器,主服务器仅会生成一份RDB文件,分别同步给各个从服务器。部分重同步则解决了sync断开重连的问题,当断开重连后,主服务器在条件允许的前提下,仅会发送断开期间的写命令。部分重同步的主要实现由以下三部分组成:
主服务器记录的是自己发给从服务器的偏移量,从服务器记录的是自己接受到的数据偏移量。比如:当前主从服务器的偏移量均为100,在有新的写入命令后,主服务器的偏移量变成了110,而从服务器的是100,此时会有短暂的不一致,待主服务器将新写入命令同步给从服务器后,从服务器的偏移量会变更为110,此时主从服务器又是保持一致的数据了。
一个固定长度的先进先出队列,默认1M,可通过配置repl_backlog_size调整其大小。当收到一条写入命令,除了发给从服务器外,还会将命令写入到复制积压缓冲区一份。
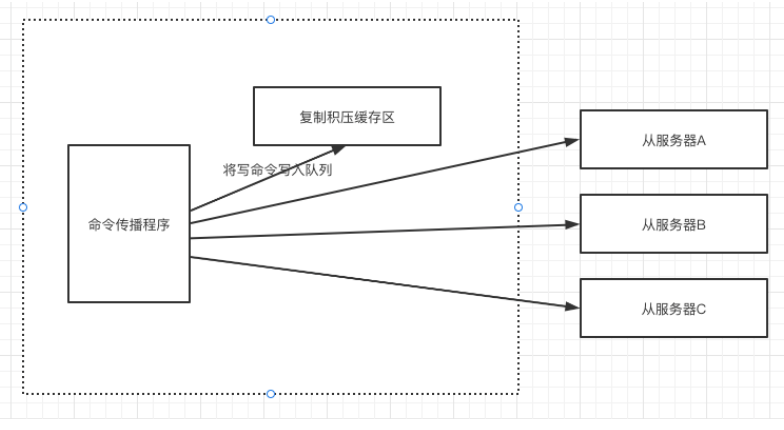
当从服务器A与主服务器断开后,中间的写入命令会无法同步给从服务器A,之后,重连后,从服务器会将其复制偏移量告知主服务器,如果该偏移量还在复制积压缓冲区中,则直接将复制积压缓冲区该偏移量后的命令发送给从服务器。
每个redis实例在启动时候,都会随机生成一个长度为40的唯一字符串来标识当前运行的redis节点。当从服务器对主服务器进行首次复制时,则将自己的runID发送给从服务器,从服务器会将这个ID保存起来。当从服务器与主服务器断开后重连时,会向主服务器发送当前存储的runID,主服务器收到后,会判断与当前自己的runID是否一致,如果不一致,则进行全量复制;如果一致,则判断复制偏移量是否还在复制积压缓冲区中,如果还在,则进行部分重同步。
psync <runId> <offset>
首次发送时为psync ? -1,之后发送的为上次master的runID和当前的复制偏移量。
由于每次实例重启都会重新生成runID,或者发生故障迁移后,新Master的runId必然与上一次的不一致,仍会导致完整重同步。
解决了psnyc的缺陷,简称:psync2
第一步,在redis关闭时,通过shutdown save,都会调用rdbSaveInfoAuxFields函数,把当前实例的repl-id和repl-offset保存到RDB文件中。
第二步,重启后加载RDB文件中的复制信息。把其中repl_id和repl_offset加载到实例中,分别赋给master_replid和master_repl_offset两个变量值。
当从库开启了AOF持久化,redis加载顺序发生变化优先加载AOF文件,但是由于aof文件中没有复制信息,所以导致重启后从实例依旧使用全量复制!
第三步:向主库上报复制信息,判断是否进行部分同步。
redis从库默认开始复制积压缓冲区,方便从库切换为主库,其他从库可以直接从master节点获取缺失的命令。通过两组replId实现。
第一组:master_replid和master_repl_offset:如果redis是主实例,则表示为自己的replid和复制偏移量; 如果redis是从实例,则表示为自己主实例的replid1和同步主实例的复制偏移量。
第二组:master_replid2和second_repl_offset:无论主从,都表示自己上次主实例repid1和复制偏移量;用于兄弟实例或级联复制,主库故障切换psync。
判断是否使用部分复制条件:如果从库提供的master_replid与master的replid不同,且与master的replid2不同,或同步速度快于master; 就必须进行全量复制,否则执行部分复制。
公众号:慢行的蜗牛
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
类似的问题,但对于java,Keepingi18nresourcessynced如何保持i18nyamllocals的key同步?即,当将key添加到en.yml时,如何将它们添加到nb.yml或ru.yml?如果我在my_title:"atitle"旁边添加键my_label:"sometextinenglish"我想把它给我的其他本地人我指定,因为我不能做所有的翻译,它应该回到其他语言的英语例如en.ymlsomegroup:my_tile:"atitleinenglish"my_label:"sometextinenglish"othergroup:...我想发出命令,将整个键和
目录FIFO一.自定义同步FIFO1.1代码设计1.2Testbech1.3行为仿真***学习位宽计算函数$clog2()***$clog2()系统函数使用,可以不关注***分布式资源或者BLOCKBRAM二.异步FIFO2.1在FIFO判满的时候有两种方式:2.2异步FIFO为什么要使用格雷码2.2.1介绍格雷码2.2.2格雷码在异步FIFO中的应用2.2.2格雷码判满2.4二进制与格雷码之间的转换2.4.1二进制码转换为格雷码的方法2.4.2格雷码转换为二进制码的方法2.3实现框图2.5实现及仿真代码2.6仿真图验证2.7结论FIFO 这篇更多的是记录FIFO学习,参考了众多优秀的文章,
数据同步的方式数据同步的2大方式基于SQL查询的CDC(ChangeDataCapture):离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据。也就是我们说的基于SQL查询抽取;无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;不保障实时性,基于离线调度存在天然的延迟;工具软件以Kettle(ApacheHop最新版)、DataX为代表,需要结合任务调度系统使用。基于日志的CDC:实时消费日志,流处理,例如MySQL的binlog日志完整记录了数据库中的变更,可以把binlog文件当作流的数据源;保障数据一致性,因为binlog文件包含了所有历史变更
IGH主站通信测试linuxcnc配置基础机器人控制LinuxCNC与EtherCAT介绍&&PDO&SDO,搭建环境步骤需要配置IGH主站的查看这篇文章linux系统学习笔记7——一次性安装igh-ethercat主站CSP模式DC同步方式preemrt实时补丁直接上代码,这部分是直接控制使用csp模式控制一个从站运动使能后直接运动,10s,每秒607a(目标位置)增加100.注意:急停按下ESC代码分为两部分,一个是通信线程主要负责和伺服通信,使能伺服,读取和写入寄存器值。第二个是操作线程,负责修改位置的值,和监控按键。使用此代码,首先根据手册1.修改PDO条目,要和自己的伺服一致2.修改
为什么新的JavaScript模块request同步?它应该只用于作业队列吗?有什么方法可以在ArangoDB中发出异步http(s)请求吗? 最佳答案 完全披露:我是ArangoDB开发团队的一员,主要从事Foxx和所有JavaScript方面的工作。我也是写org/arangodb/request的人模块。ArangoDB是一个不同于Node.js的环境,尽管有许多相似之处(例如使用V8JavaScript引擎)。与Node.js(或浏览器)不同,ArangoDB使用基于线程的并发模型并且没有事件循环。然而,线程并没有在Java
我有两个关于Firebasewebplatform的相关问题的synchronisationoflocally-modifieddatatotheserver:EveryclientsharingaFirebasedatabasemaintainsitsowninternalversionofanyactivedata.Whendataisupdatedorsaved,itiswrittentothislocalversionofthedatabase.TheFirebaseclientthensynchronizesthatdatawiththeFirebaseserversandw
我有需要同步工作的promise对象。例如,第二个promise不应该在第一个promise完成之前起作用。如果第一个拒绝第一个必须再次执行。我已经实现了一些示例。这个效果很好。调用getVal,等待2000ms,返回,i++,再次调用getVal.....getVal(){returnnewPromise(function(resolve,reject){setTimeout(function(){resolve(19)},2000);});}asyncpromiseController(){for(vari=0;i但我需要控制一组promise对象。我想做的是我有一个数据,我把它分
我编写了一个JavaScript函数,它使用XmlHttpRequest异步调用Web服务。我被要求让这个函数在页面呈现之前完成它的工作。我想我可以使AJAX请求同步,但我不希望这使页面挂起太久-如果未收到响应,我想在1秒后中止请求。是否可以中止同步XmlHttpRequest? 最佳答案 你不能:http://www.hunlock.com/blogs/Snippets:_Synchronous_AJAX说:“同步AJAX(真正的SJAX——同步Javascript和XML)是模态的,这意味着javascript将停止处理您的程序
是否有任何同步原语,如障碍、信号量、锁、监视器,...JavaScript/WebWorkers或者是否有一些可用的库使我能够使用这些东西(我正在考虑Java中的java.util.concurrent之类的东西)?Worker是否具有将它们与线程区分开来的晦涩属性(例如,它们可以与主线程共享内存)?是否有某种限制可以产生多少worker(例如,出于安全原因或其他原因......)?我需要特别注意什么吗? 最佳答案 网络worker没有共享内存的概念;复制线程之间传递的所有消息。话虽如此,您没有屏障、信号量、锁和监视器,因为您在网络