# 数据源配置
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/kh96_ssm_airms?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=GMT
username: root
password: root
# mybatis 核心配置
mybatis:
configuration:
map-underscore-to-camel-case: true # 下划线 映射 驼峰
mapper-locations: classpath:mybatis/mapper/*.xml # 自定义mapper映射路径
# config-location: classpath:mybatis-config.xml # mysql配置文件
@Data
public class Quality {
//编号
private Integer id;
//地区id
private Integer did;
//检测时间
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss",timezone =" GMT+8")
private Date monitorTime;
//pm10
private Integer pm10;
//pm25
private Integer pm25;
//监测站
private String monitorStation;
//修改时间
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss",timezone =" GMT+8")
private Date lastModifyTime;
}
public interface QualityMapper {
//根据空气质量编号,修改空质量
Integer updateQualityById(Quality qualityForm);
}
<!--
根据空气质量编号,修改空质量
Integer updateQualityById(Quality qualityForm);
-->
<update id="updateQualityById">
update air_quality
<set>
<if test="id != null"> `id` = #{id},</if>
<if test="did != null"> `did` = #{did},</if>
<if test="monitorTime != null"> `monitor_time` = #{monitorTime},</if>
<if test="pm10 != null"> `pm10` = #{pm10},</if>
<if test="pm25 != null"> `pm25` = #{pm25},</if>
<if test="monitorStation != null"> `monitor_station` = #{monitorStation},</if>
<if test="lastModifyTime != null"> `last_modify_time` = #{lastModifyTime},</if>
</set>
where `id` = #{id}
</update>
//接口
public interface QualityService {
boolean modifyQualityById(Quality qualityForm);
}
//实现类
@Service
public class QualityServiceImpl implements QualityService {
@Autowired
private QualityMapper qualityMapper;
@Override
public boolean modifyQualityById(Quality qualityForm) {
return qualityMapper.updateQualityById(qualityForm) > 0;
}
}
@Slf4j
@RestController
public class AirQualityController {
@Autowired
private QualityService qualityService;
//根据空气质量编号,修改空质量,使用xml映射文件
@PostMapping("/modQuality")
public Map<String,String> testModifyQualityMapperXml(@RequestBody Quality qualityForm){
//返回集合
Map<String,String> returnMap = new HashMap<>();
//调用业务接口,修改空气详情
if(qualityService.modifyQualityById(qualityForm)){
returnMap.put("code","200");
returnMap.put("msg","Success");
return returnMap;
}
returnMap.put("code","9999");
returnMap.put("msg","Fail");
return returnMap;
}
}
测试:
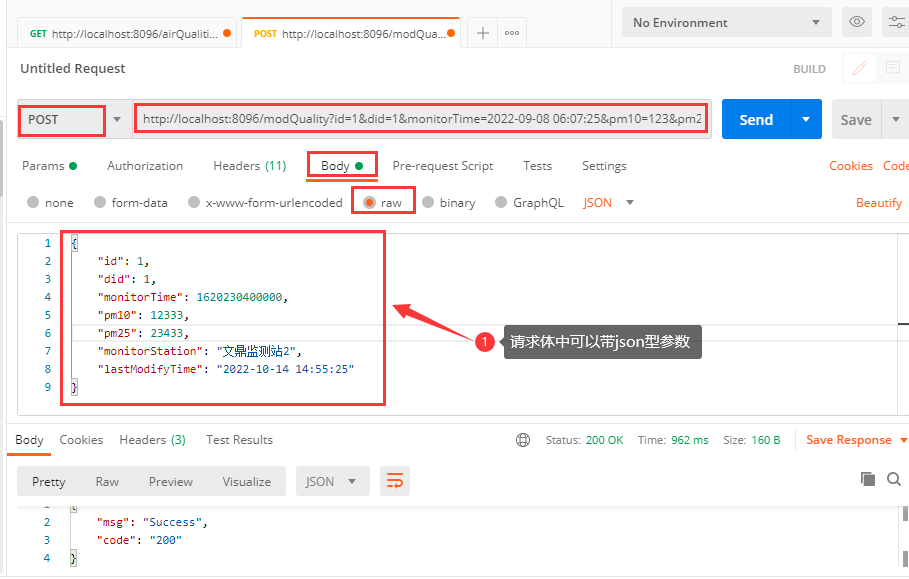
测试结果:


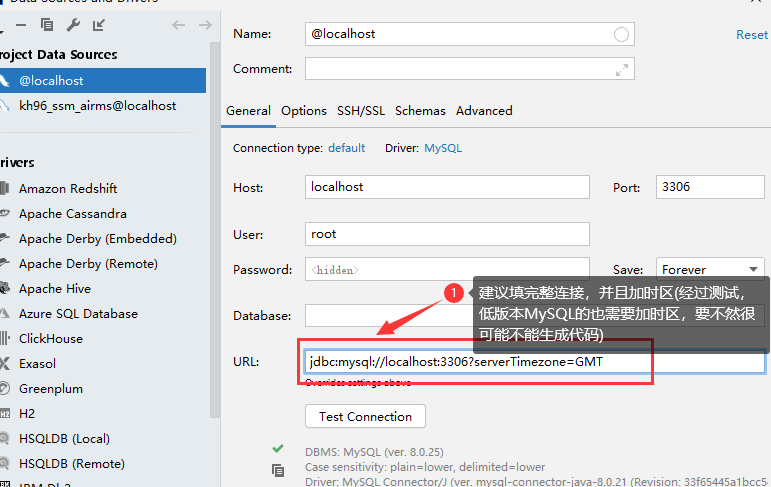
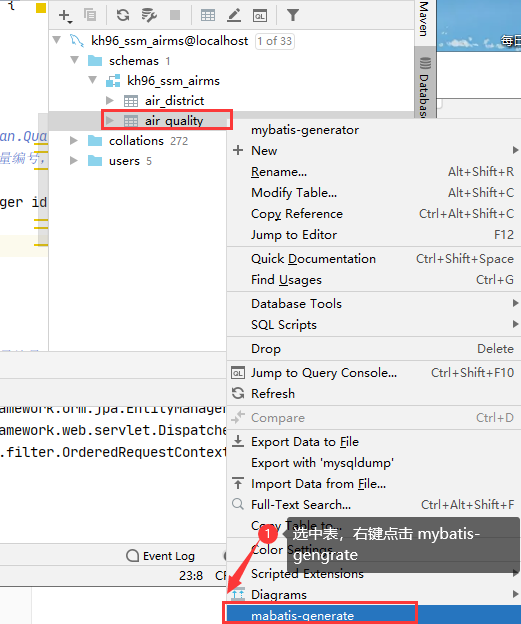

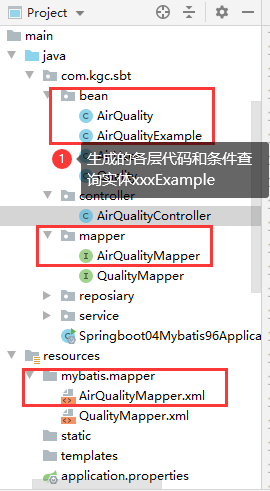
生成的代码:
public interface AirQualityService {
//根据条件查询空气质量列表
List<AirQuality> getQualityListByExample(AirQualityExample airQualityExample);
}
@Service
public class AirQualityServiceImpl implements AirQualityService {
@Autowired(required = false)
private AirQualityMapper airQualityMapper;
@Override
public List<AirQuality> getQualityListByExample(AirQualityExample airQualityExample) {
return airQualityMapper.selectByExample(airQualityExample);
}
}
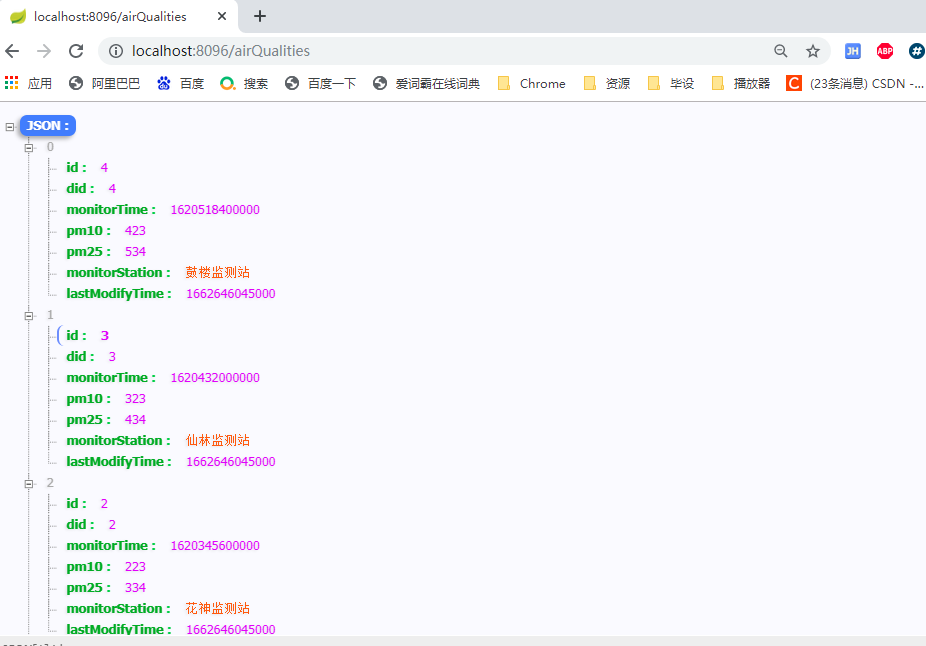
@GetMapping("/airQualities")
public List<AirQuality> testAirQualityListUseBackward(){
log.info("------ 根据 查询条件,查询空气质量的列表 --------");
//创建查询条件对象
AirQualityExample airQualityExample = new AirQualityExample();
//如果需要去重,增加条件
airQualityExample.setDistinct(true);
//如果需要排序,增加排序条件
airQualityExample.setOrderByClause(" id desc ");
//添加自定义查询 条件,监测站名称中包含检测的
AirQualityExample.Criteria criteria = airQualityExample.createCriteria();
//criteria.andMonitorStationLike("%"+monitorStation+"%");
criteria.andMonitorStationLike("%监测%");
//区域编号 大于1
//criteria.andDidGreaterThan(1);
//区域编号在指定列表中
//criteria.andDidIn(Arrays.asList(1,2,3,4,5));
//增加or的查询条件
AirQualityExample.Criteria criteriaOr = airQualityExample.createCriteria();
criteriaOr.andPm10GreaterThan(100);
//拼接or的查询条件
airQualityExample.or(criteriaOr);
//如果需要分页,增加分页参数 limit ${offset}, ${limit}
//起始行 (偏移量参数)
airQualityExample.setOffset(2l);
//返回数据量
airQualityExample.setLimit(5);
//调用业务接口,查询空气质量列表
List<AirQuality> qualityListByExample = airQualityService.getQualityListByExample(airQualityExample);
return qualityListByExample;
}
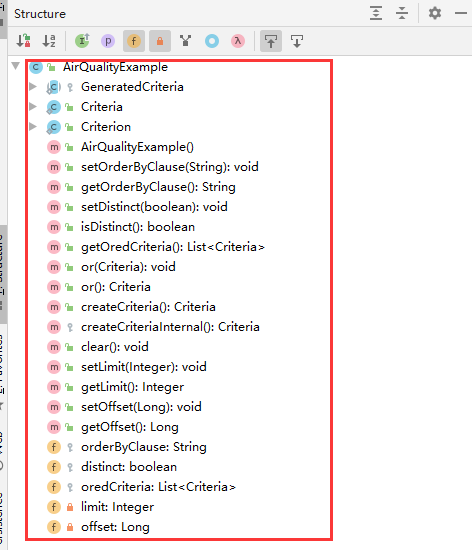

protected List<Criteria> oredCriteria; //oredCriteria 是一个 Criteria 的 集合
//创建条件类 方法
public Criteria createCriteria() {
Criteria criteria = createCriteriaInternal();
if (oredCriteria.size() == 0) {
oredCriteria.add(criteria); // 创建第一个Criteria的时候会自动加入集合中
}
return criteria;
}
//or 拼接 条件 方法
public void or(Criteria criteria) {
oredCriteria.add(criteria); //其他Criteria 条件,调用方法拼接时 也会 动加入集合中
}
# jpa 核心配置
spring:
jpa:
show-sql: true # 显示sql查询
hibernate:
ddl-auto: update #如果不存在,就新建,如果存在只更新
注意:
1、如果数据库没有该表会自动生成该表;
2、如果该表已经存在,也需要填写这些注解信息,要不然会出现实体跟数据库不对应的错误;
@SuppressWarnings("all") //会爆红不过没有事,抑制警告就好
@Data
@Entity
@Table(name = "air_user",catalog = "kh96_ssm_airms")
//指定jpa建表的表名,如果指定,默认使用类名作为表名,catalog是指定数据库实例名
public class AirUser {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
//用户名
@Column(name = "name",length = 32)
private String name;
//密码
@Column(name = "pwd",length = 32)
private String pwd;
//手机号
@Column(name = "tel",length = 11)
private String tel;
}
启动项目;
public interface AirUserRepository extends JpaRepository<AirUser,Integer> {
}
public interface AirUserService {
//@description : 根据用户编号,查询用户详情
AirUser getAirUserById(Integer id);
}
@Service
public class AirUserServiceImpl implements AirUserService {
@Autowired
private AirUserRepository airUserRepository;
@Override
public AirUser getAirUserById(Integer id) {
return airUserRepository.findOne(id);
}
}
@RestController
public class AirQualityController {
@Autowired
private AirUserService airUserService;
@GetMapping("/airUser")
public AirUser AirUserTestAirUserUserJPA(@RequestParam("Id") Integer Id){
return airUserService.getAirUserById(Id);
}
}

public interface AirUserService {
//根据 name 模糊查询,根据 tel 精确查询 ,分页查询 用户列表
List<AirUser> getAirUsersByPage(String name,String tel,Integer pageNo,Integer pageSize);
}
创建查询实体对象
创建条件查询对象,放入查询实体对象和匹配器
创建排序对象
通过条件对象 和 分页对象 分页条件 查询
@Service
public class AirUserServiceImpl implements AirUserService {
@Autowired
private AirUserRepository airUserRepository;
@Override
public List<AirUser> getAirUsersByPage(String name, String tel, Integer pageNo, Integer pageSize) {
//创建查询实体对象
AirUser airUserForm = new AirUser();
airUserForm.setName(name);
airUserForm.setTel(tel);
//创建匹配器,组装查询条件
ExampleMatcher matching = ExampleMatcher.matching();
//注意:propertyPath 实体属性
//注意这里添加一个条件后一点过要重新接收返回的 ExampleMatcher 否者条件没有添加进去
matching = matching.withMatcher("name", matcher -> matcher.contains());// 模糊查询name
matching = matching.withMatcher("tel",matcher -> matcher.exact()); //精确查询电话
//创建条件查询对象,放入 查询实体 和 匹配器
Example<AirUser> airUserExample = Example.of(airUserForm,matching);
//一步到位,简洁方便 推荐
// Example<AirUser> airUserExample = Example.of(airUserForm, ExampleMatcher.matching()
// .withMatcher("name", matcher -> matcher.contains())
// .withMatcher("tel", matcher -> matcher.exact()));
//定义排序规则
Sort.Order order = new Sort.Order(Sort.Direction.DESC, "id");
//sort 对象封装排序规则
Sort sort = new Sort(order);
//分页对象 @param page zero-based page index. 所以我们的页码需要减1 处理
//放入 分页参数 和排序规则
PageRequest pageRequest = new PageRequest(pageNo - 1, pageSize,sort);
//通过条件对象 和 分页对象 分页条件 查询
Page<AirUser> airUserPage = airUserRepository.findAll(airUserExample, pageRequest);
// 查询返回的分页对象中,可以获取符合条件的所有条数
// long totalCount = airUserPage.getTotalElements();
//可以获取总页数
// int totalPages = airUserPage.getTotalPages();
//获取分页条件查询的 数据
List<AirUser> airUserList = airUserPage.getContent();
return airUserList;
}
}
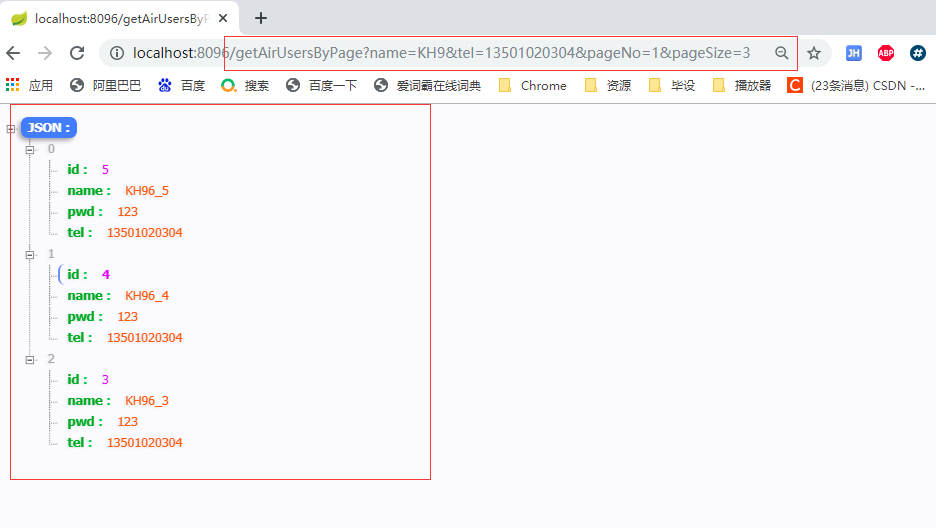
//根据 name 模糊查询,根据 tel 精确查询 ,分页查询 用户列表
@GetMapping("/getAirUsersByPage")
public List<AirUser> getAirUsersByPage(@RequestParam(value = "name",required = false,defaultValue = "") String name,
@RequestParam(value = "tel",required = false,defaultValue = "13501020304") String tel,
@RequestParam(value = "pageNo",required = false,defaultValue = "1") Integer pageNo,
@RequestParam(value = "pageSize",required = false,defaultValue = "3") Integer pageSize){
log.info("------ 根据 name 模糊查询,根据 tel 精确查询 ,分页查询 用户列表 ------");
return airUserService.getAirUsersByPage(name, tel, pageNo, pageSize);
}
| 方法名 | 作用 |
|---|---|
| ignoreCase | 与字符串不区分大小写的匹配 |
| caseSensitive | 与字符串区分大小写的匹配 |
| contains | 与字符串模糊匹配,%{str}% |
| endsWith | 与字符串模糊匹配,% |
| startsWith | 与字符串模糊匹配,{str}% |
| exact | 与字符串精确匹配 |
| storeDefaultMatching | 默认匹配模式 |
| regex | 将字符串视为正则表达式进行匹配 |
jpa 模糊查询部分参考:-->https://blog.csdn.net/weixin_43481812/article/details/115615691
// 如果数据库默认建表不是utf-8字符集,增加一个类,解决jpa自动创建表,字符集不支持中文(主要是8一下的数据库有足够问题)
public class MyMySQL57InnoDBDialect extends MySQL57InnoDBDialect {
@Override
public String getTableTypeString() {
return " ENGINE=InnoDB DEFAULT CHARSET=utf8 ";
}
}
spring:
jpa:
properties:
hibernate:
dialect: com.kgc.sbt.config.MyMySQL57InnoDBDialect
# 自定义 配置类的路径
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.3.4</version>
</dependency>
#mybatis-plus 配置
mybatis-plus:
configuration:
map-underscore-to-camel-case: true #下划线映射驼峰
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 开启 mybatis 标准日志
mybatis-plus的分页拦截器,有这个分页才有效果;
@Configuration
public class MybatisPlusConfig {
// mybatis-plus的分页拦截器
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor(){
MybatisPlusInterceptor mybatisPlusInterceptor = new MybatisPlusInterceptor();
mybatisPlusInterceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return mybatisPlusInterceptor;
}
}
注意:要@MapperScan("com.kgc.sbt.mapper");
public interface ContactMapper extends BaseMapper<Contact> {
//特殊sql,可以自己添加 接口并实现
}
// 根据 联系人 姓名 获取联系人详情
List<ContactVO> getContactByName(String contactName,Integer pageNo,Integer pageSize);
@Override
public List<ContactVO> getContactByName(String contactName, Integer pageNo, Integer pageSize) {
//mybatis-plus,创建一个查询对象,直接用
QueryWrapper<Contact> contactQueryWrapper = new QueryWrapper<>();
contactQueryWrapper.likeRight("cname",contactName);
contactQueryWrapper.orderByDesc("id");
//or 条件拼接
contactQueryWrapper.or().eq("cname","李四");
//创建分页对象
Page<Contact> contactPage = new Page<>(pageNo,pageSize);
//查询联系人对象
Page<Contact> contactResultPage = contactMapper.selectPage(contactPage, contactQueryWrapper);
//处理返回的结果结果列表,将状态进行转化为描述
List<ContactVO> contactVOList = contactResultPage.getRecords().stream().map(contact -> {
//创建新的VO 实体对象
ContactVO contactVO = new ContactVO();
//拷贝实体属性
BeanUtils.copyProperties(contact,contactVO);
//处理状态说明(可以定义枚举,也可以定义工具类)
contactVO.setStatusDesc(contact.getStatus() == 1 ? "正常" : "异常");
return contactVO;
}).collect(Collectors.toList());
log.info("------ 总页数:{},总条数:{},当前页:{},条数:{} -----",contactPage.getPages(),contactPage.getCurrent(),pageNo,pageSize);
return contactVOList;
}
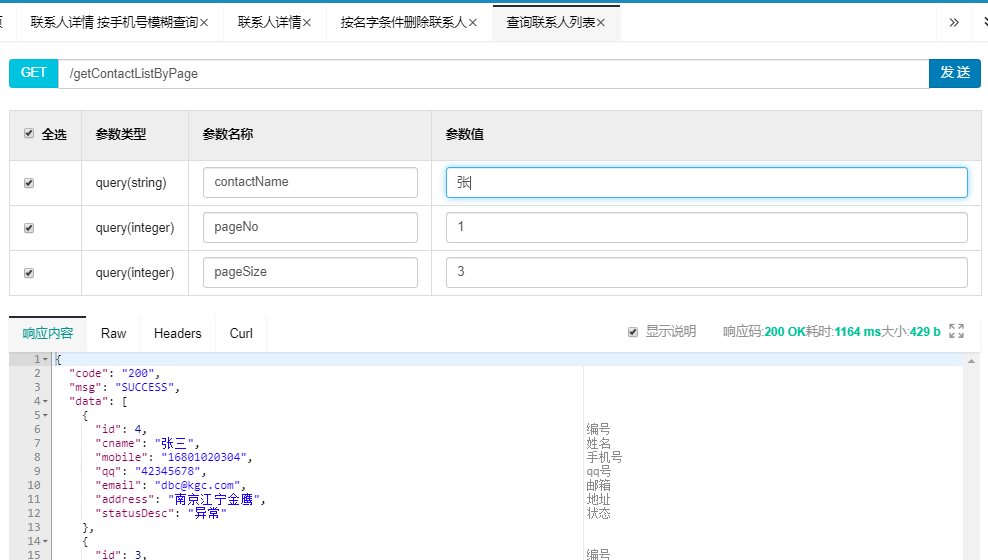
@@GetMapping("/contactByPage")
public RequestResult<List<ContactVO>> getContactListByPage(@RequestParam(value = ("contactName"),required = false) String contactName,
@RequestParam(value = ("pageNo"),required = false,defaultValue = "1") Integer pageNo,
@RequestParam(value = ("pageSize"),required = false,defaultValue = "3") Integer pageSize){
return ResultBuildUtil.success(contactService.getContactByName(contactName,pageNo,pageSize));
}
测试结果:
如果您希望在Spring中启用定时任务功能,则需要在主类上添加 @EnableScheduling 注解。这样Spring才会扫描 @Scheduled 注解并执行定时任务。在大多数情况下,只需要在主类上添加 @EnableScheduling 注解即可,不需要在Service层或其他类中再次添加。以下是一个示例,演示如何在SpringBoot中启用定时任务功能:@SpringBootApplication@EnableSchedulingpublicclassApplication{publicstaticvoidmain(String[]args){SpringApplication.ru
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
1.依赖导入org.springframework.bootspring-boot-starter-weborg.springframework.bootspring-boot-starter-validation2.validation常用注解@Null被注释的元素必须为null@NotNull被注释的元素不能为null,可以为空字符串@AssertTrue被注释的元素必须为true@AssertFalse被注释的元素必须为false@Min(value)被注释的元素必须是一个数字,其值必须大于等于指定的最小值@Max(value)被注释的元素必须是一个数字,其值必须小于等于指定的最大值@D
我正在尝试找到一种更好的方法将IRB与我的常规ruby开发集成。目前我很少在我的代码中使用IRB。我只用它来验证语法或尝试一些小的东西。我知道我可以将我自己的代码加载到ruby中作为一个require'mycode'但这通常不符合我的编程风格。有时我要检查的变量超出范围或在循环内。有没有一种简单的方法可以启动我的脚本并在IRB内的某个点卡住?我想我正在寻找一种更简单的方法来调试我的ruby代码而不破坏我的F5(编译)键。也许有经验的ruby开发者可以和我分享一个更精简的开发方法。 最佳答案 安装ruby-debugg
我开始了一个小型网络项目并使用Drupal来构建它。到目前为止,还不错:您可以快速建立一个不错的面向CMS的网站,通过模块添加社交功能,并且您有一个广泛的API可以在一个架构良好的平台中进行自定义。现在问题来了:网站的增长超出了最初的计划,我发现自己正处于认真开始为它编写代码的境地。由于Drupal项目,我对PHP有了新的认识,但我想用Ruby来做。我会感觉更舒服,以后维护起来更容易,我可以在其他Ruby/Rails应用程序中重用它。随着时间的推移,我想我会用Ruby重写Drupal中的现有部分。基于此,问题是:是否有人将两者(成功或失败的故事)结合起来?这是一个相当大的决定,但我在G
华为认证分等级的,相当于初中高三个等级,当然高级是比较难考的,也是含金量最高的。我就慢慢给你介绍一下。1.了解华为认证华为认证网络工程师是由华为公司认证与采购部推出的独立认证体系,与之前的华为认证不同,简称HCIA。同时华为认证是华为技术有限公司凭借多年信息通信技术人才培养经验,以及对行业发展的理解,以层次化的职业技术认证为指引,推出的覆盖IP、IT、CT以及ICT融合技术领域的认证体系,是ICT全技术领域认证体系。2.怎么考取华为认证网络工程师?要考取华为认证网络工程师必须选择最近的Prometric授权考试中心APTC报名并参加GB0-190的考试,考试通过后,以获得由华为统一签发的“华
Iparking停车收费管理系统-可商用介绍Iparking是一款基于springBoot的停车收费管理系统,支持封闭车场和路边车场,支持微信支付宝多种支付渠道,支持多种硬件,涵盖了停车场管理系统的所有基础功能。技术栈Springboot,MybatisPlus,Beetl,Mysql,Redis,RabbitMQ,UniApp功能云端功能序号模块功能描述1系统管理菜单管理配置系统菜单2系统管理组织管理管理组织机构3系统管理角色管理配置系统角色,包含数据权限和功能权限配置4系统管理用户管理管理后台用户5系统管理租户管理多租户管理6系统管理公众号配置租户公众号配置7系统管理操作日志审计日志8系统
大家好,我叫胡飞虎,花名虎仔,目前负责云效旗下产品Codeup代码托管的设计与开发。代码作为企业最核心的数据资产,除了被构建、部署之外还有更大的价值。为了帮助企业和团队挖掘更多源代码价值以赋能日常代码研发、运维等工作,云效代码团队在大数据和智能化方向进行了一系列的探索和实践(例如代码搜索与推荐),本文主要介绍我们如何通过直接打通源代码来提高研发与运维效率。随着微服务架构的流行,一个业务流程需要多个微服务共同完成。一旦出现问题,运维人员在面对数量多、调用链路复杂的情况下,很难快速锁定导致问题发生的罪魁祸首:代码。为了提高排查效率,目前常见的解决方案是:链路跟踪+日志分析工具相结合。即通过链路跟踪
查看原文>>>基于”PLUS模型+“生态系统服务多情景模拟预测实践技术应用目录第一章、理论基础与软件讲解第二章、数据获取与制备第三章、土地利用格局模拟第四章、生态系统服务评估第五章、时空变化及驱动机制分析第六章、论文撰写技巧及案例分析基于ArcGISPro、Python、USLE、INVEST模型等多技术融合的生态系统服务构建生态安全格局基于生态系统服务(InVEST模型)的人类活动、重大工程生态成效评估、论文写作等具体应用基于ArcGISPro、R、INVEST等多技术融合下生态系统服务权衡与协同动态分析实践应用 本文从数据、方法、实践三方面对生态系统服务多情景预测进行讲解。内容涵盖多
项目背景和意义 目的:本课题主要目标是设计并能够实现一个基于微信校园跑腿小程序系统,前台用户使用小程序发布跑腿任何和接跑腿任务,后台管理使用基于PHP+MySql的B/S架构;通过后台管理跑腿的用户、查看跑腿信息和对应订单。意义:手机网络时代,大学生通过手机网购日常用品、外卖外卖、代取快递等已不再是稀奇的事情。此外,不少高校还流行着校园有偿工作,校园跑腿就成了大学生创业服务项目。 因为你在校园里,所以不会有进入的限制。并不是所有的外卖平台都可以随意进入校园,比如小黄和小蓝的双打外卖平台。许多大学禁止送餐进入学校,更不用说送餐进入宿舍了。这一措施使得校园服务市场的竞争相对不