更多技术交流、求职机会、试用福利,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
埋点数据作为推荐、搜索、产品优化的基石,其数据质量的重要性不言而喻,而要保障埋点数据的质量,埋点验证则首当其冲。工欲善其事必先利其器,要做好埋点验证会面临很多技术挑战:易用性、准确性、实时性、稳定性、扩展性,如何攻克这些挑战呢,其实还是技术,这也是本文的主旨所在。
目前埋点验证已在字节内部得到广泛使用,通过一键扫码开启验证、实时上报验证、自动生成验证报告,解决了埋点数据验证难、埋点质量保障难的问题。
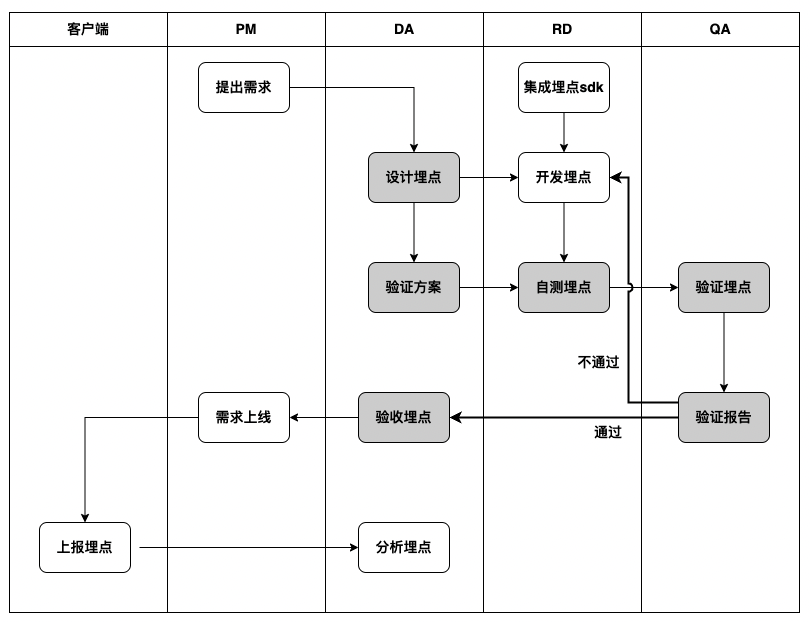
埋点生命周期:4+6
4 个角色:PM、DA、RD、QA
6 个节点:提出需求、设计埋点、开发埋点、测试埋点、上报埋点、分析埋点
埋点验证流程:3+3+3
3 个角色:DA、RD、QA
3 个节点:设计埋点、测试埋点、验收埋点
3 个物料:埋点验证方案、埋点验证工具、埋点验证报告
先简单介绍一下产品,以便大家能对平台有整体认识,方便大家更加轻松地理解技术,平台主要包括三部分:埋点验证方案、埋点验证工具、埋点验证报告,三者相辅相成,极大的降低了用户的埋点验证成本。
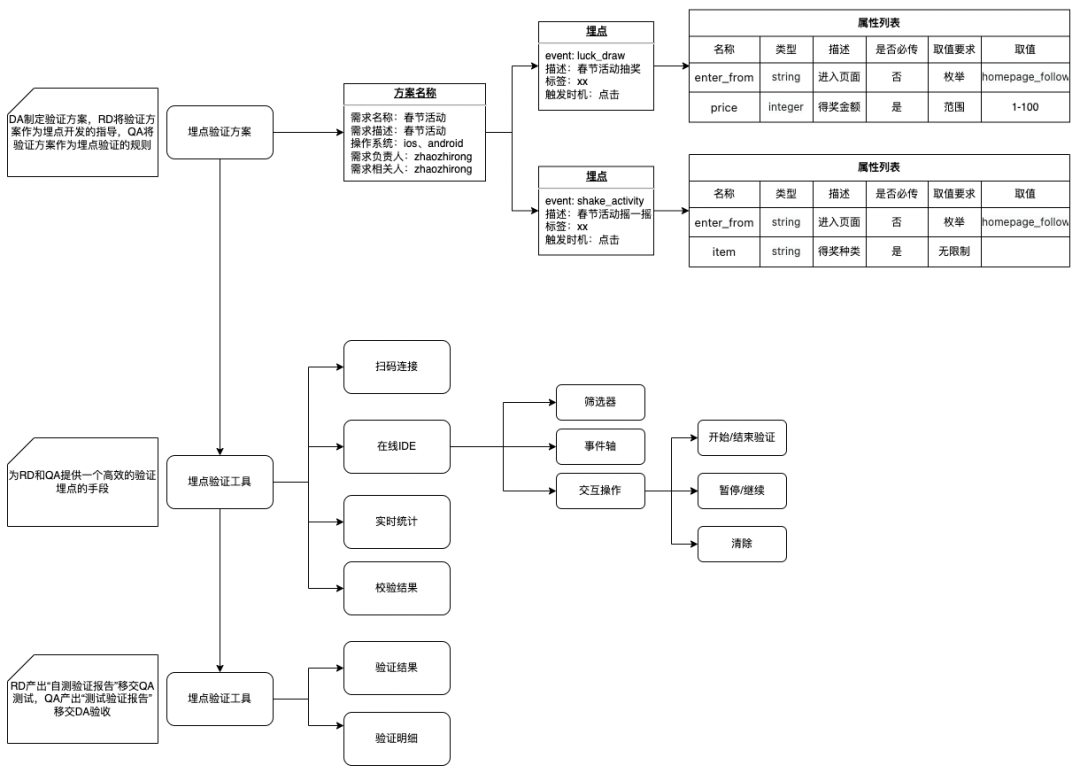
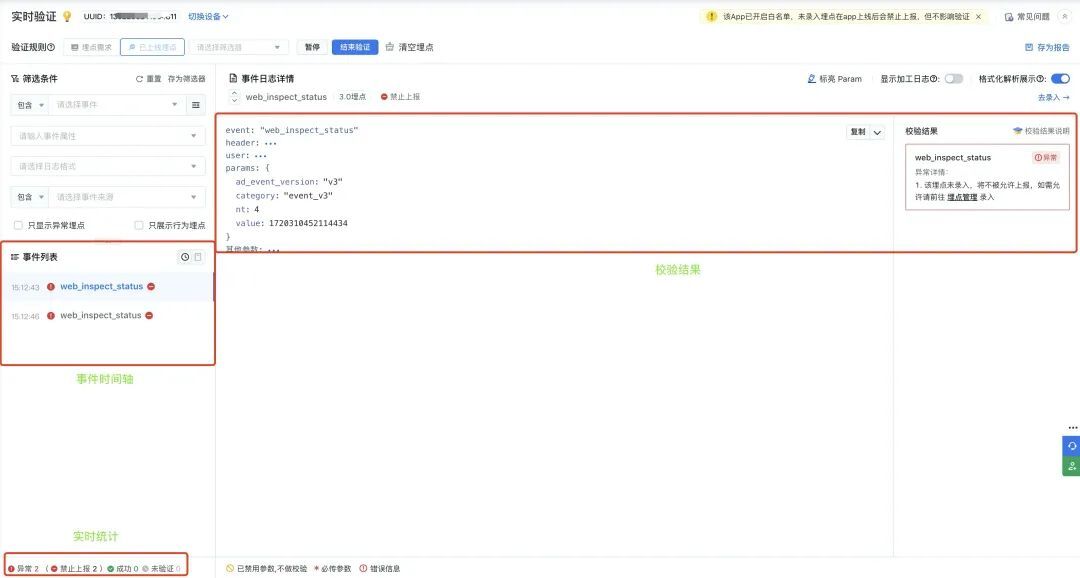
附埋点验证工具图
埋点验证的链路很长,可以简单概括为三个环节:埋点上报、埋点接收、埋点验证,每个环节都有一定的复杂性,此处先介绍整体流程,让大家可以快速对全流程有所认识。其次将主要聚焦于“埋点验证”环节,此环节的重中之重是埋点验证引擎,它包括 4 个部分:规则生成器、规则选择器、埋点验证器和埋点推送器,通过对埋点验证引擎的详解让大家对“埋点如何验证”有更深的理解。
埋点上报环节重点是丰富的 SDK(客户端、服务端、JS、Chrome 插件),要做到简单易用并且保证埋点实时上报。
埋点接收环节重点是数据接收服务(客户端-applog、Web 端-mcs、服务端-databus)、数据保存服务(消息队列),要保证服务稳定并且保证埋点不丢失。
埋点验证环节重点是埋点验证引擎,要确保服务高性能并且保证埋点验证结果的准确性。
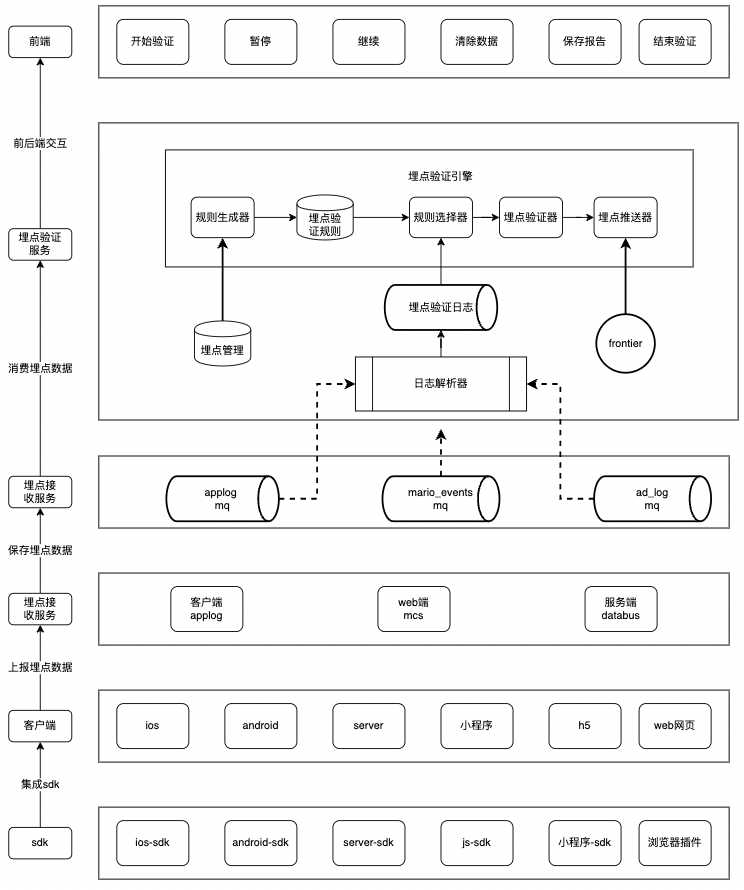
规则生成器将“埋点验证方案”转换为“验证规则”。埋点验证方案是验证规则的逻辑视图,方便用户操作,降低验证规则的编写和维护成本。通过逻辑视图和物理视图两层逻辑,确保了埋点验证引擎底层不受业务变化的影响。
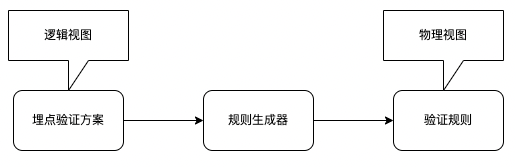
埋点方案
埋点验证方案支持 2 种:
按需求验证:即新建需求计划,针对某次需求验证、
按元数据验证:即按元数据验证,元数据是指所有需求的并集
按元数据验证:
埋点名称:video_play
参数信息
(名称、类型、是否必填、值校验、是否是场景条件)
enter_from,string,必传,固定值(login),是
duration,integer,必传,值无限制,否
type,integer,必传,枚举(1,2,3),否
埋点数据:
{
"app_id":100,
"event":"click",
"params":{
"enter_from":"login",
"duration":1,
"type":3
}
}
埋点规则
{
"app_id":100,
"event_name":"video_play",
"logical_filter":{
"enter_from":"login"
},
"meta":{
"required_field":[
"duration",
"enter_from",
"type"
],
"scene":{
"condition":"enter_from=login",
"name":"登录页"
},
"validate_field":[
"duration",
"enter_from",
"type"
]
},
"physical_validation":"{\"$schema\":\"https://json-schema.org/draft/2019-09/schema\",\"type\":\"object\",\"properties\":{\"params\":{\"type\":\"object\",\"properties\":{\"duration\":{\"type\":\"integer\"},\"enter_from\":{\"type\":\"string\",\"enum\":[\"login\"]},\"type\":{\"type\":\"integer\",\"enum\":[1,2,3]}},\"required\":[\"duration\",\"enter_from\",\"type\"]}},\"required\":[\"params\"]}",
"source":"schema_scene"
}
埋点规则字段说明
app_id:应用 id
event_name:埋点名称
logical_filter:用于“规则选择器”
physical_validation:用于“埋点验证器”
source:区分规则来源:按需求验证、按元数据验证
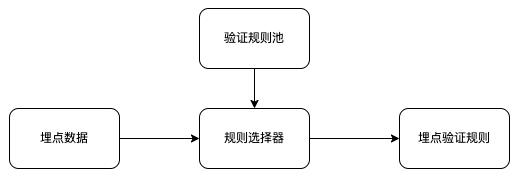
规则选择器将依据“埋点”中的关键信息,从“验证规则池”中选择出对应的“埋点验证规则”。
选择逻辑:具体数据参考“规则生成器”
根据“埋点数据”中 app_id 和 event 从“验证规则池”中筛选出“匹配的规则”
将“埋点数据”的 parms 字段和“匹配的规则”的 login_filter 规字段进行匹配,选择出最终的“埋点验证规则”
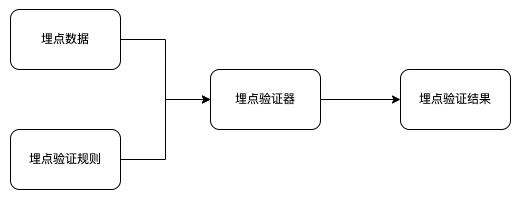
埋点验证器将依据“基础验证规则”以及“规则选择器”产出的“埋点验证规则”,对“埋点数据”进行验证并产出“验证结果”。
基础验证规则:埋点是否登记;埋点是否禁用;是否是 debug 埋点;
埋点验证规则:参数是否丢失;参数类型是否正确;参数取值是否符合预期:枚举、范围、正则;
埋点验证结果:验证结果提供双语格式,用户可自行选择中文或者英文;
埋点推送器将“埋点验证结果”推送到前端,推送的过程存在数据交互频繁、数据体积大、数据传输稳定性的要求,这里我们自建 Push 服务进行数据传输,保证数据实时可达。

易用性:快速接入埋点验证,快速开始埋点验证
准确性:埋点验证结果准确、用户可信
实时性:埋点数据实时可见
稳定性:埋点数据可靠不丢失
扩展性:快速接入新的埋点数据格式
快速接入埋点验证,快速开始埋点验证
快速接入埋点验证
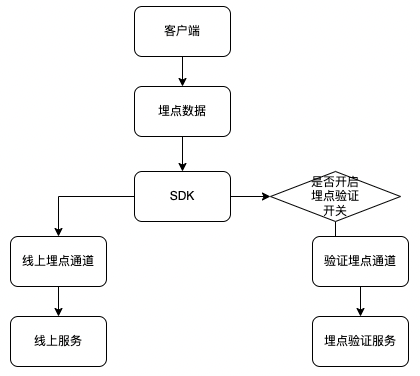
SDK 提供“埋点验证开关”,客户端集成 SDK 的时候,可根据不同环境来配置是否开启“埋点验证开关”
SDK 层判断如果开启“埋点验证开关”,埋点数据会双发,此过程对业务是透明的
双发的原因或者为什么不从“线上埋点通道”取数?这里主要考虑两个原因:
“线上埋点通道”数据量太大
SDK 层线上上报逻辑是采用微批的形式,默认 1 分钟从客户端上报一次,而埋点验证要求实时性,所以采用单独的通道
快速开始埋点验证
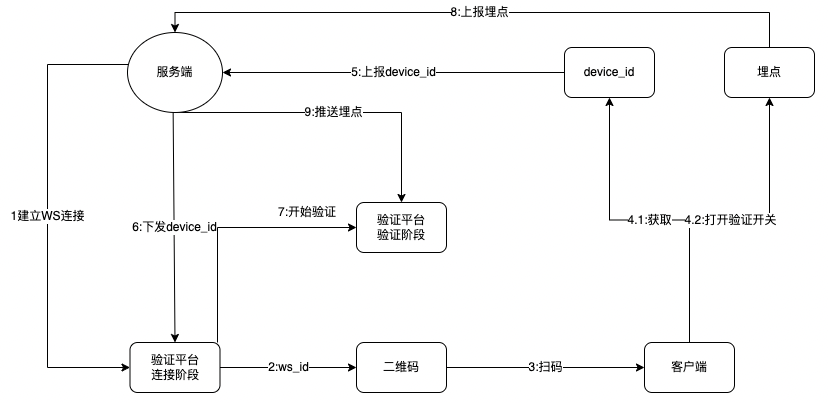
连接流程
建立 WS 连接:服务端和验证平台建立长连接,用于通信
ws_id:验证平台根据 ws_id 生成二维码
扫码:客户端扫描二维码
获取并打开验证开关:客户端获取设备信息并且打开埋点验证开关
上报 device_id:客户端将长连接信息和设备信息上报至服务端
下发 device_id:服务端将设备信息推送到验证平台
开始验证:埋点验证平台进入验证阶段
上报埋点:客户端开始上报埋点
推送埋点:服务端将埋点推送到验证平台
下发原理
客户端上报的埋点数据中含有设备信息
用户通过扫码在验证平台回填设备信息
服务端接收到埋点数据后,将埋点数据中的设备信息和验证平台的设备信息进行匹配,如果匹配则将埋点数据进行下发
埋点验证结果准确、用户可信
埋点验证引擎必须保证埋点验证结果的准确性,才能降低验证成本。针对埋点数据本身的格式验证,我们采用了 JsonSchema 作为验证手段,以支持完善的验证规则、可信的验证结果。上文中的“规则生成器”、“规则选择器”、“埋点验证器”也都在一定程度上保证了埋点验证结果的准确性。
event:video_play
埋点名称:video_play
参数信息
(名称、类型、是否必填、值校验、是否是场景条件)
enter_from,string,必传,固定值(login),是
duration,integer,必传,值无限制,否
type,integer,必传,枚举(1,2,3),否
jsonSchema
{
"$schema":"https://json-schema.org/draft/2019-09/schema",
"type":"object",
"properties":{
"params":{
"type":"object",
"properties":{
"duration":{
"type":"integer"
},
"enter_from":{
"type":"string",
"enum":[
"login"
]
},
"type":{
"type":"integer",
"enum":[
1,
2,
3
]
}
},
"required":[
"duration",
"enter_from",
"type"
]
}
},
"required":[
"params"
]
}
event:video_play
{
"app_id":100,
"event":"click",
"params":{
"enter_from":"login",
"duration":1,
"type":3
}
}
event:video_play
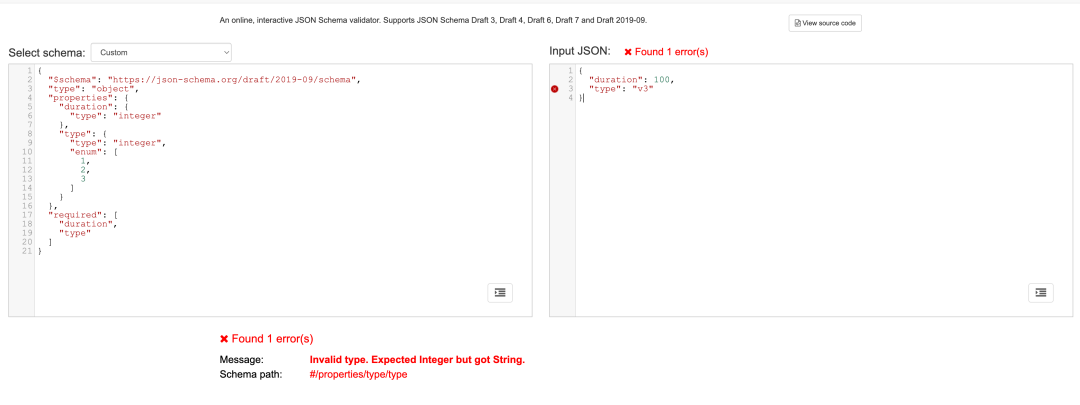
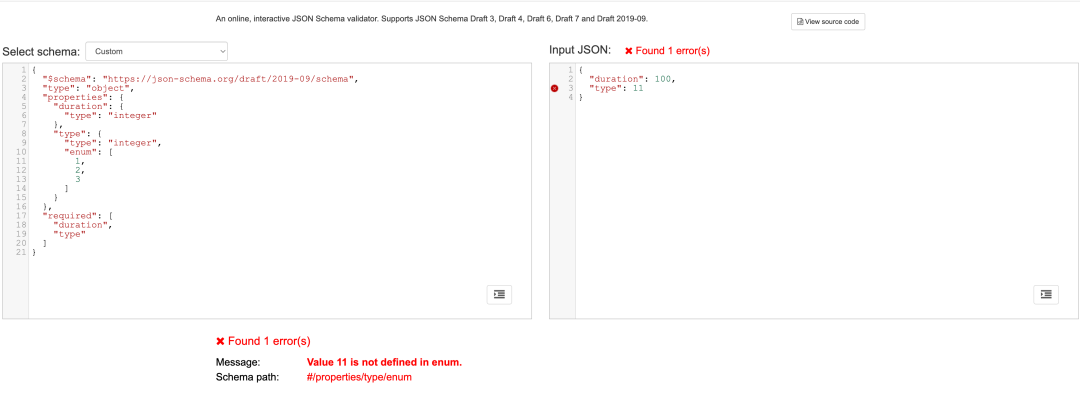
测试地址:https://www.jsonschemavalidator.net/
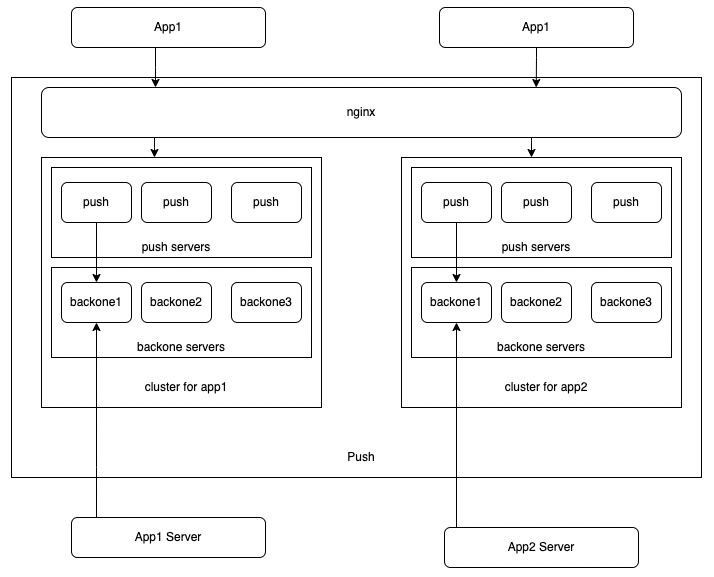
埋点数据实时可见
埋点验证场景下,服务端和验证平台需要频繁地进行数据交互,所以我们自建了 Push 服务(基于 WebSocket 的封装),能够保证数据的实时畅通性
基于 WebSocket 实现一套通用长连接通讯协议,能实现同一个客户端上的不同业务共享同一个长连接通道,并实现可靠的心跳机制。
客户端和服务端基于通用长连接通讯协议实现一个稳定可靠的全双工通道。
客户端实现一个通用的 SDK,服务端实现一个通用接入层。
客户端 SDK,服务端接入层,都要很方便后续 service 接入。
Push 服务定期做打点监控,同时开放 http 的 Admin 接口,方便系统的监控和查看服务状态
连接稳定性:Push 服务分为两个组件 Push 和 Backone,实现了业务和推送解耦。push 面向客户端连接,设计尽可能简单,需保持大量客户端活跃连接,避免了业务服务更新时不影响客户端连接
服务隔离性:不同的业务服务接入 push 服务,会根据接入信息做集群隔离,避免业务之间互相影响
横向扩展性:当业务服务不断增多时,只需对 push 服务做横向扩容即可支持
埋点数据可靠不丢失
定义:服务级别协议 (service-level agreement,即 SLA) 是服务提供方与客户之间的正式承诺,用来量化服务水平(质量、可用性、责任)
埋点验证服务:服务的特征是实时,所以衡量埋点验证不可用的手段是“数据延迟”,即埋点从“上报”->“验证平台”的 p99 超过 3s 即视为不可用,日常 p99 在 1s
为了保证“SLA”,我们做了一系列的保护措施
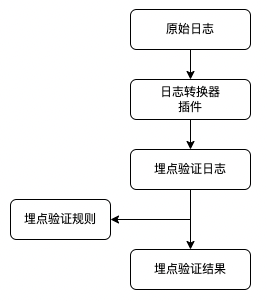
日志转换器:客户端、服务端、web 端上报的是原始日志格式,需要转换为埋点验证日志格式后进行验证
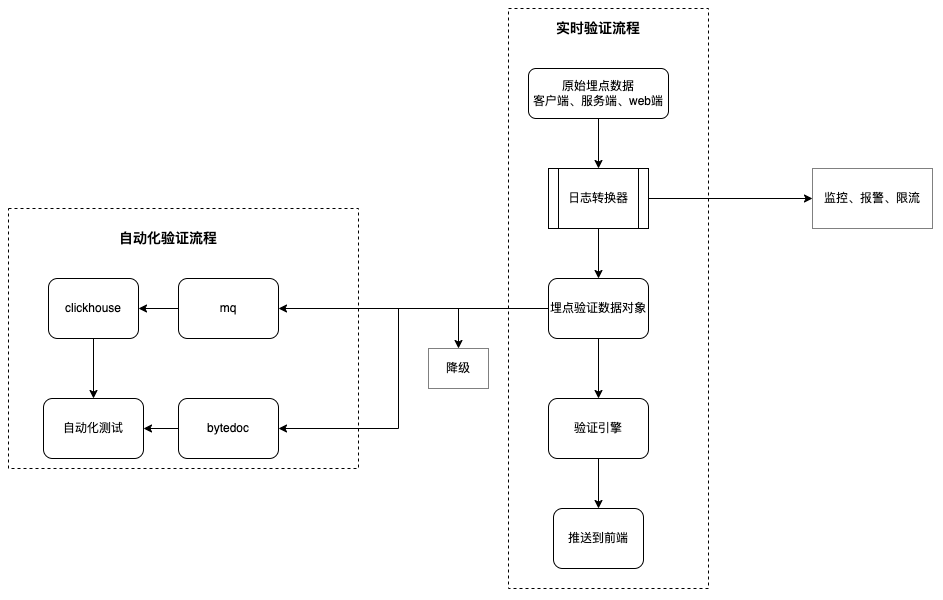
快速接入新的埋点数据格式
提供可插拔的“日志转换器插件”,服务高内聚,可支持各种日志格式快速接入、验证
埋点验证是保障埋点质量的有效方式,此方式属于事前验证,适用于埋点频繁变化的业务场景,需要一定程度的人工介入,能够解决基本的埋点质量问题。但是对于核心埋点场景来说,这种方式的验证成本较高,需要重复的人力投入,为了解决核心埋点验证成本高的问题,我们正在探索落地其他方式:
回归验证(自动化验证):伴随每次发版,核心埋点都需要进行回归验证,目前我们通过内部其他团队的合作实现了自动化验证功能来支撑回归验证,当前已有一部分业务正在使用,极大地降低了验证核心埋点的成本
事后验证:经过事前验证、回归验证,埋点质量基本能得到很好的保障。但为了更好的保障我们也在探索事后验证的场景和落地:
质量大盘:通过“规则引擎”,结合“质量模型”对埋点数据进行质量评估,得出各个维度的“质量评分”,然后针对质量问题进行专项修复,进一步提高埋点质量。
质量工具:提供监控计划,业务可以针对自己关注的埋点配置监控报警,当线上出现质量问题,会发送质量报告给业务,及时止损。
全链路埋点质量保障:事前验证、回归验证、事后验证贯穿埋点的生命周期,打通这三个流程,从而形成埋点质量保障全链路,彻底解决埋点质量问题。
我正在使用Ruby,我正在与一个网络端点通信,该端点在发送消息本身之前需要格式化“header”。header中的第一个字段必须是消息长度,它被定义为网络字节顺序中的2二进制字节消息长度。比如我的消息长度是1024。如何将1024表示为二进制双字节? 最佳答案 Ruby(以及Perl和Python等)中字节整理的标准工具是pack和unpack。ruby的packisinArray.您的长度应该是两个字节长,并且按网络字节顺序排列,这听起来像是n格式说明符的工作:n|Integer|16-bitunsigned,network(bi
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭9年前。我正在创建一个Sinatra应用程序,它采用上传的CSV文件并将其内容放入哈希中。当我像这样在我的app.rb中引用这个散列时:hash=extract_values(path_to_filename)我不断收到此错误消息:undefinedmethod`bytesize'forHash:0x007fc5e28f2b90#object_idfile:utils.rblocation:bytesiz
有没有一种方法可以查看ruby中为类分配的内存大小?我构建了一个自定义类,我想知道它在内存中的大小。那么C语言中有没有类似sizeof()的函数呢?我只是想像这样初始化一个新类test=MyClass.new并试图找到一种方法来打印出已分配给内存的类的大小。这在ruby中甚至可能吗? 最佳答案 没有以与C相同的方式计算类大小的语言功能。对象的内存大小取决于实现。这取决于基类对象的实现。估计使用的内存也不简单。例如,如果字符串很短,则可以嵌入到RString结构中,但如果它们很长(NevercreateRubystringsl
一文解决关于VLAN所有的疑惑VLAN基本概念为什么需要VLAN?怎么在交换机上划分VLAN,VLAN的工作原理有了子网,已经隔离了广播,还需要VLAN干啥?只进行子网划分,不进行VLAN划分VLAN划分与子网划分附加VLAN信息的方法VLAN划分交换机的端口类型(Access和Trunk)一、访问链接二、汇聚链接汇聚链接VLAN间通信为什么要进行VLAN间通信?路由器实现VLAN间通信路由器和交换机的连接方式通信细节三层交换机实现VLAN间通信加速VLAN间通信三层交换机与路由器三层交换机路由器路由器和交换机配合构建LAN的实例使用VLAN设计局域网的特点VLAN增加网络的灵活性不使用VLA
同时Ruby1.9wascompilingtobytecode,它无法将预编译的脚本保存到磁盘。我们被告知期待Ruby2toallowsavingcompiledbytecode到磁盘,但我没有听到太多关于它的讨论,也没有看到无数的博客文章描述如何通过编译获得性能,我希望看到它是否真的在Ruby2.x的某个地方实现。AfocusedGooglesearch似乎没有返回任何有用的东西。在2.1(或更早版本)中可以吗?如果没有,这是否仍在路线图上? 最佳答案 有一半可能。从here下载扩展并编译它。需要库iseq.so好的,现在字节码的
在Ruby中计算一个字节是奇校验还是偶校验的最佳方法是什么?我有一个可用的版本:result="AB".to_i(16).to_s(2).count('1').odd?=>true不过,将数字转换为字符串并计算“1”似乎是一种糟糕的计算奇偶校验的方法。有什么更好的方法吗?我希望能够计算3DESkey的奇偶校验。最终,我想将偶数字节转换为奇数。谢谢,丹 最佳答案 除非你拥有的速度不够快,否则请保留它。它清晰简洁,性能比您想象的要好。我们将根据数组查找对所有内容进行基准测试,这是我测试过的最快的方法:ODD_PARITY=[false,
为什么需要NFT市场?NFTMarketplace允许用户购买、出售、交易、查看或创建自己的NFT,就像他们需要一个市场来购买物理或数字世界中的大多数产品一样。几乎每个人都可以进入NFT市场,但要做到这一点,用户必须满足以下要求:一个NFT市场用户账户,允许您在给定平台上购买NFT。你需要一个与区块链兼容的加密钱包来购买NFT。NFTMarketplace非常重要,因为它连接了买卖双方,并为用户提供了多种工具来快速创建自己的NFT。艺术家可以在市场上列出要出售的NFT,买家可以通过投标过程探索市场并购买物品。NFT市场开发过程解释创建NFT市场是一个耗时的过程,需要编程知识和理解。那么搭建NF
在Ruby中是否有一种平台无关的方式将EOF符号写入字符串。在*nix中,我认为符号是^D,但在Windows中是^Z,这就是我问的原因。 最佳答案 EOF不是一个字符,它是一个状态。终端使用控制字符来表示此状态(C-d)。没有这样的事情是“读一个EOF字符”,写一个也是一样的。如果您正在写入文件,请在完成后将其关闭。看这个mailinglistpost:ItsoundslikeyouarethinkingofEOFasanin-bandbutspecialcharactervaluethatmarkstheendoffile.It
✅作者简介:大家好,我是小杨📃个人主页:「小杨」的csdn博客🔥系列专栏:小杨带你玩转C语言【初阶】🐳希望大家多多支持🥰一起进步呀!大家好呀!我是小杨。小杨花几天的时间将C语言中的操作符这部分知识做了一个大总结,在方便自己复习的同时也能够帮助到大家。通篇字数在一万字左右,可以算作是非常详细了,一文就可以带领大家彻底掌握操作符这部分内容,文章很长建议先收藏再看,防止下次想看就找不到啦。文章目录✍1,算术操作符✍2,移位操作符 🔍2.1,左移操作符 🔍2.2,右移操作符 ✨2.2.1,算术移位 ✨2.2.2,逻辑移位✍3,位操作符 🔍3.1,按位与&
近年来,随着信息化时代的到来,三维全景拼接以视频监控领域为代表的智能硬件公司迅速崛起,随后全国各地在视频监控领域进行了大量的建设。但随着摄像头数量的增加,视频监控画面离散、庞杂、关联性差等诸多问题日渐凸显。如何优化现有视频技术,助力管理者或使用者有效、直观、准确地掌控现场实时动态,成为我国信息化前行路上面临的新课题。视频融合技术平台解决方案北京智汇云舟科技有限公司成立于2012年,专注于创新性的“视频孪生(实时实景数字孪生)”技术研发与应用。公司依托自研三维地理信息引擎(3DGIS),融合建筑信息模型(BIM)、视频监控(Video)、人工智能(AI)及物联网(IOT)等多种技术,并在此基础上