目录
完全二叉树的物理结构和逻辑结构:
关于堆和堆元素上下调整算法接口的设计原理分析参见青菜的博客http://t.csdn.cn/MKzyt
http://t.csdn.cn/MKzyt青菜友情提示:想要深刻理解堆排序,必须掌握堆的构建
注意:接下来给出的两个接口是针对小根堆的元素调整算法接口,若需要用到大根堆数据结构,只需在小根堆的元素调整算法接口中将子父结点值比较符号换一下方向即可用于实现大根堆.
函数首部:
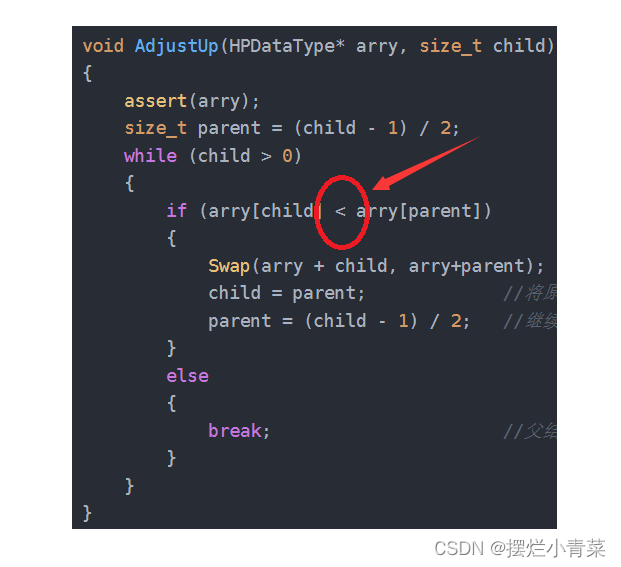
void AdjustUp(HPDataType* arry, size_t child) //child表示孩子结点的编号HPDataType是typedef定义的数据类型,arry是指向堆区数组的指针,child是待调整的结点在完全二叉树中的编号(物理上是其数组下标)
- 算法调用场景:
接口实现:
//元素交换接口 void Swap(HPDataType* e1, HPDataType* e2) { assert(e1 && e2); HPDataType tem = *e1; *e1 = *e2; *e2 = tem; } //小堆元素的向上调整接口 void AdjustUp(HPDataType* arry, size_t child) //child表示待调整的结点的编号 { assert(arry); size_t parent = (child - 1) / 2; //找到child结点的父结点 while (child > 0) //child减小到0时则调整结束(说明待调整结点被调整到了根结点位置) { if (arry[child] < arry[parent]) //父结点大于子结点,则子结点需要上调以保持小堆的结构 { Swap(arry + child, arry+parent); child = parent; //将原父结点作为新的子结点继续迭代过程 parent = (child - 1) / 2; //继续向上找另外一个父结点 } else { break; //父结点不大于子结点,则堆结构任然成立,无需调整 } } }
- 循环的结束分两种情况:
- child减小到0时,说明待调整结点被调整到了根结点的位置(小根堆数据结构恢复)
- 若某次父子结点比较中,父结点的值若大于子结点,则说明小根堆数据结构恢复,break跳出循环即可
- 调用该接口的前提是:待调整的结点的上层结构(包括待调整结点的所在层,但不包括待调整结点本身)满足小根堆的数据结构,比如:
否则的话堆元素的调整将失去意义(因为只有在满足上述前提的情况下,每次调用完该接口,待调整的结点的上层结构将保持小根堆的数据结构,并且以待调整结点为叶结点的上层结构会成为一个堆)
- 大根堆的元素向上调整算法接口:
- 若要将接口改为大根堆元素向上调整算法接口,只需将上图中的红圈中的小于号改为大于号即可
函数首部:
void AdjustDown(HPDataType* arry,size_t size,size_t parent)HPDataType是typedef定义的数据类型,arry是指向堆区数组首地址的指针,size是堆的元素总个数,parent是待调整的结点在完全二叉树中的编号(物理上是其数组下标)
- 算法调用场景:
接口实现:
//元素交换接口 void Swap(HPDataType* e1, HPDataType* e2) { assert(e1 && e2); HPDataType tem = *e1; *e1 = *e2; *e2 = tem; } //小堆元素的向下调整接口 void AdjustDown(HPDataType* arry,size_t size,size_t parent) { assert(arry); size_t child = 2 * parent + 1; //确定父结点的左孩子的编号 while (child < size) //child增加到大于或等于size时则调整结束 { if (child + 1 < size && arry[child + 1] < arry[child]) //确定左右孩子中较小的孩子结点 { ++child; } if ( arry[child] < arry[parent])//父结点大于子结点,则子结点需要上调以保持小堆的结构 { Swap(arry + parent, arry + child); parent = child; //将原子结点作为新的父结点继续迭代过程 child = 2 * parent + 1; //继续向下找另外一个子结点 } else { break; //父结点不大于子结点,则堆结构任然成立,无需调整 } } }
- 算法需要注意的一些边界条件:
- child >= size说明被调整元素已经被交换到了叶结点的位置,小根堆数据结构恢复,终止循环
- 接口中,我们只设计了一个child变量来表示当前父结点的孩子结点编号,因此我们需要先确定左右孩子中哪一个结点值较小,令child等于较小的孩子结点的编号:
if (child + 1 < size && arry[child + 1] > arry[child]) //确定左右孩子中较小的孩子结点 { ++child; }child + 1<size判断语句是为了确定当前父结点的右孩子是否存在;
调用该接口的前提是:待调整的结点位置的左右子树都满足小根堆的数据结构,比如:
否则的话堆元素的调整将失去意义(因为只有在满足上述前提的情况下,每次调用完该接口后,待调整的结点位置的左右子树将保持小根堆的数据结构,并且以待调整结点为根结点的子树会成为一个堆)
大根堆的元素向下调整算法接口:
若要实现大根堆的元素向下调整算法接口,我们只需将上图红圈中的两个小于号改为大于号即可
堆元素上下调整算法接口的实现原理分析参见:http://t.csdn.cn/MKzyt
有了堆元素的上下调整算法接口后,我们便可以利用堆的数据结构来实现高效的排序算法.
现在我们给出一个一百个元素的数组(每个元素随机附一个值):
typedef int HPDataType; int main() { int arr[100] = { 0 }; srand((unsigned int)time(NULL)); for (int i = 0; i < 100; i++) { arr[i] = rand() % 10000; //数组每个元素赋上一个随机值 } return 0; }
堆排序函数接口:
void HeapSort(int * arr,int size);arr是指向待排序数组首地址的指针,size是待排序的数组的元素个数
思路分析:
- 实现堆排序的其中一种非常暴力的思路是:
- 在HeapSort接口中动态开辟一个和待排序数组空间大小相同的Heap数组作为堆
- 然后将待排序数组的元素逐个尾插到Heap数组中同时调用堆元素向上调整算法调整堆尾元素的位置来建堆(排升序则建立小根堆)
- 建堆过程完成后,再逐个取出堆顶数据(按照堆顶元素删除的方式取出,具体参见堆的实现http://t.csdn.cn/vhbJf)(堆顶数据为堆中的最小元素)从待排序数组首地址开始覆盖待排序数组的空间即可完成排序
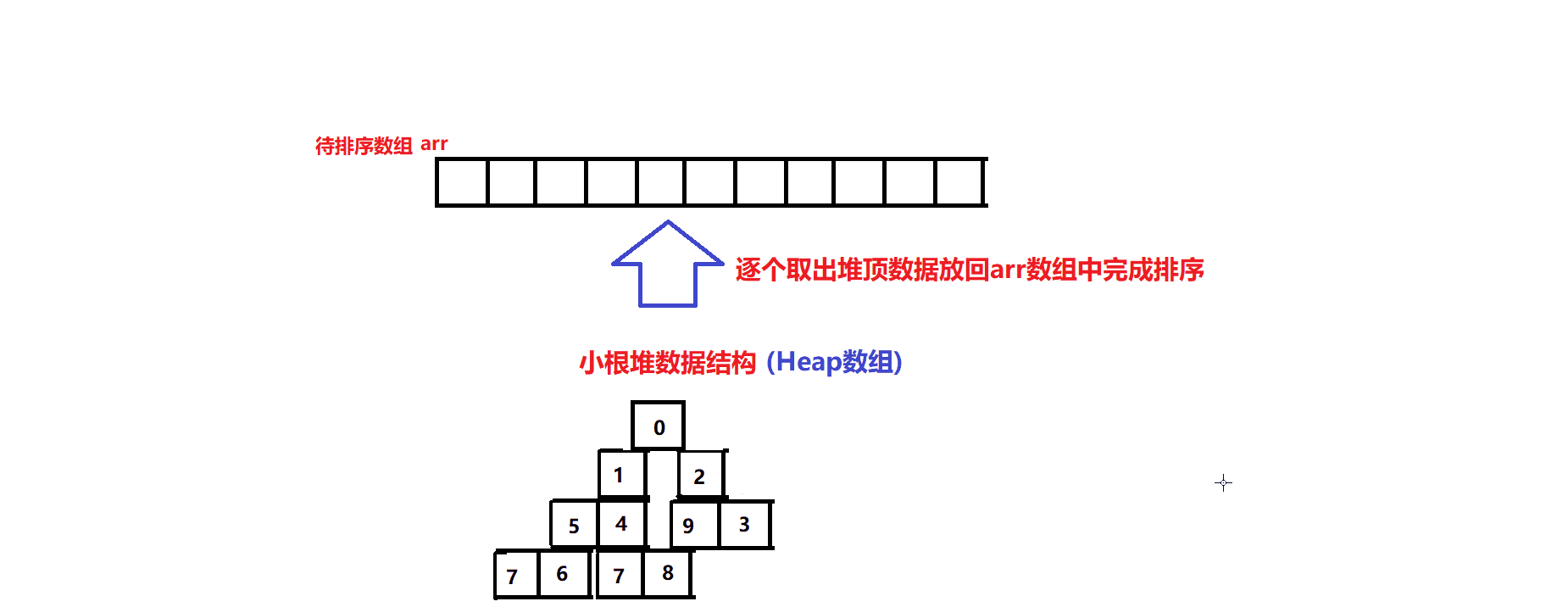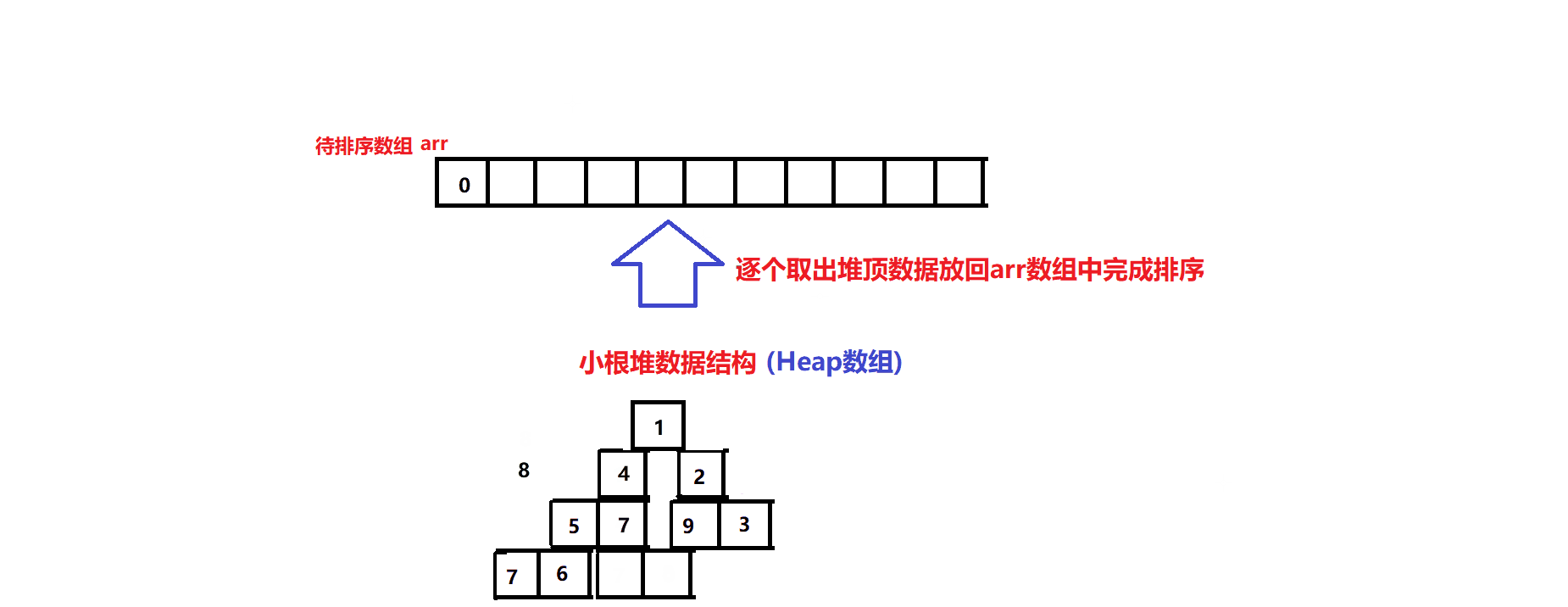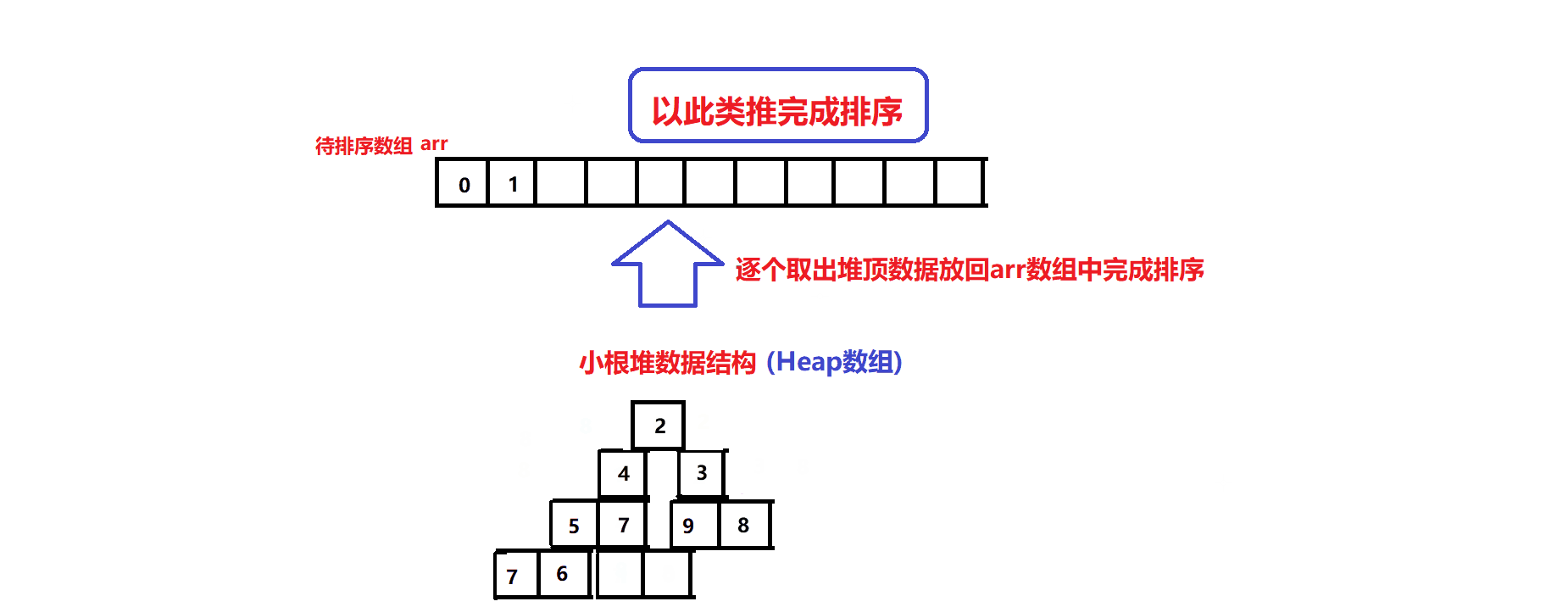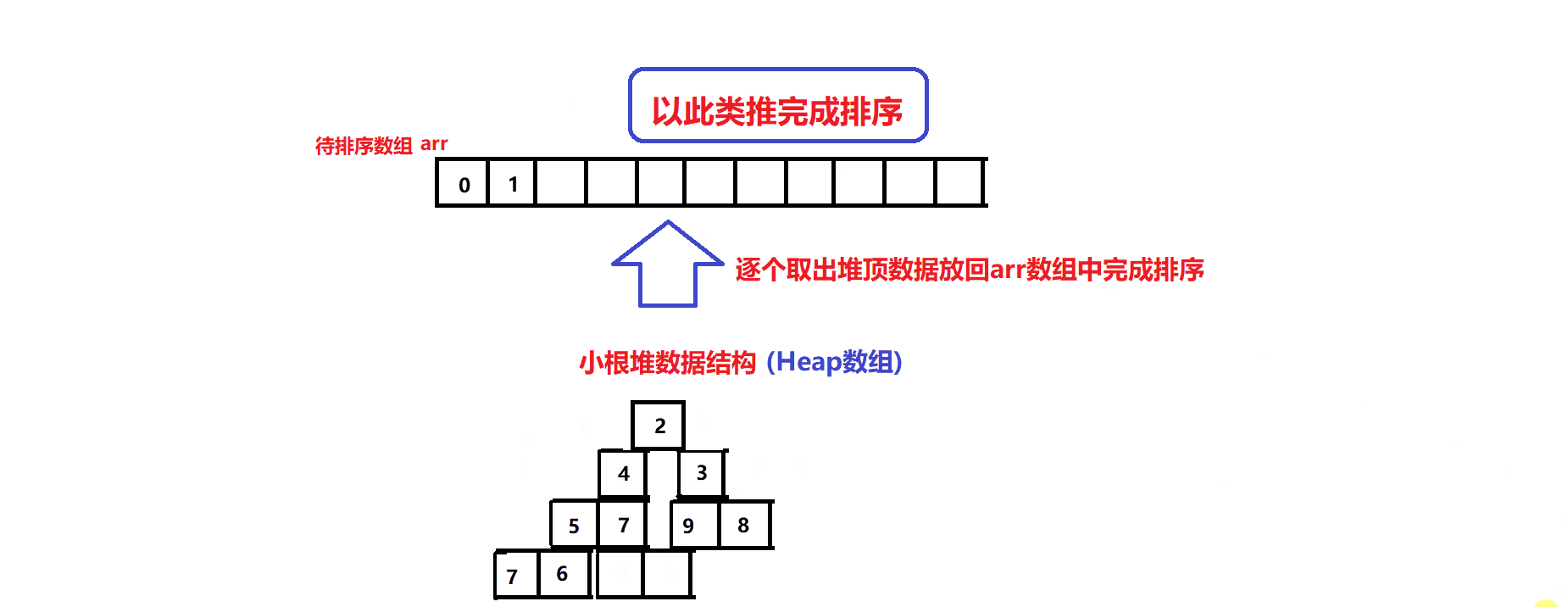
排序算法图解:
- 先将arr中的元素逐个尾插到Heap数组中建堆
- 再逐个将Heap数组的堆顶元素利用堆顶元素删除操作放回到arr数组中,完成升序排序(其原理在于小根堆堆顶元素永远是堆中的最小元素)(堆顶元素删除操作指的是:先将堆顶元素与堆尾元素交换,维护堆尾的下标指针减一(堆元素个数减一),再将堆顶元素向下调整恢复小根堆数据结构):
代码实现:
//元素交换接口 void Swap(HPDataType* e1, HPDataType* e2) { assert(e1 && e2); HPDataType tem = *e1; *e1 = *e2; *e2 = tem; } //小堆元素的向上调整接口 void AdjustUp(HPDataType* arry, size_t child) //child表示待调整的结点的编号 { assert(arry); size_t parent = (child - 1) / 2; //找到child结点的父结点 while (child > 0) //child减小到0时则调整结束(说明待调整结点被调整到了根结点位置) { if (arry[child] < arry[parent]) //父结点大于子结点,则子结点需要上调以保持小堆的结构 { Swap(arry + child, arry+parent); child = parent; //将原父结点作为新的子结点继续迭代过程 parent = (child - 1) / 2; //继续向上找另外一个父结点 } else { break; //父结点不大于子结点,则堆结构任然成立,无需调整 } } } //小堆元素的向下调整接口 void AdjustDown(HPDataType* arry,size_t size,size_t parent) { assert(arry); size_t child = 2 * parent + 1; //确定父结点的左孩子的编号 while (child < size) //child增加到大于或等于size时则调整结束 { if (child + 1 < size && arry[child + 1] < arry[child]) //确定左右孩子中较小的孩子结点 { ++child; } if ( arry[child] < arry[parent])//父结点大于子结点,则子结点需要上调以保持小堆的结构 { Swap(arry + parent, arry + child); parent = child; //将原子结点作为新的父结点继续迭代过程 child = 2 * parent + 1; //继续向下找另外一个子结点 } else { break; //父结点不大于子结点,则堆结构任然成立,无需调整 } } } void HeapSort(int* arr, int size) { assert(arr); int* Heap = (int*)malloc(size * sizeof(int)); assert(Heap); int ptrarr = 0; //维护arr数组的下标指针 int ptrheap = 0; //维护Heap数组的下标指针 //逐个尾插元素建堆 while (ptrarr < size) { Heap[ptrheap] = arr[ptrarr]; //将arr数组中的元素逐个尾插到Heap数组中 AdjustUp(Heap, ptrheap); //每尾插一个元素就将该元素向上调整保持小堆的数据结构 ptrheap++; ptrarr++; } //逐个将堆顶的元素放回arr数组(同时进行删堆操作) ptrarr = 0; int HeapSize = size; while (ptrarr < size) { Swap(&Heap[0], &Heap[HeapSize - 1]); //交换堆顶和堆尾的元素 arr[ptrarr] = Heap[HeapSize-1]; //将原堆顶元素插入arr数组中 HeapSize--; //堆元素个数减一(完成堆数据弹出) ptrarr++; //维护arr的下标指针+1 AdjustDown(Heap, HeapSize, 0); //将交换到堆顶的数据向下调整恢复堆的数据结构 } }排序测试:
int main() { int arr[100] = { 0 }; srand((unsigned int)time(NULL)); for (int i = 0; i < 100; i++) { arr[i] = rand() % 10000; //数组每个元素赋上一个随机值 } HeapSort(arr, 100); for (int i = 0; i < 100; ++i) { printf("%d ", arr[i]); } return 0; }
时空复杂度分析:
- 由于尾插建堆和堆顶删堆的时间复杂度都是O(NlogN),因此排序的时间复杂度为O(NlogN)
- 显然,在HeapSort接口中多开辟了一个Heap数组,排序的空间复杂度为O(N)
- 关于建堆和删堆的时间复杂度证明参见青菜的博客:http://t.csdn.cn/MKzyt
- 该种堆排序代码量很大,数据并发量也很大,而且空间复杂度较高,接下来我们来实现一种最优良的堆排序算法
前面的堆排序算法中引入了Heap数组来建堆,浪费了很多空间。
实际上,我们可以在待排序数组上原地完成堆的构建(即将数组arr调整成堆).
将数组arr调整成堆的思路:
- 现有一个乱序数组arr,逻辑上我们将其看成一颗完全二叉树:
- 接下来我们尝试用堆的元素向下调整算法接口将arr调整成小根堆
- 调用堆元素向下调整接口的前提是:待调整的结点位置的左右子树都满足小根堆的数据结构(因为在满足这个前提的情况下,我们每次调用完该接口后待调整的结点位置的左右子树将保持小根堆的数据结构,并且以待调整结点为根结点的子树会成为一个堆)
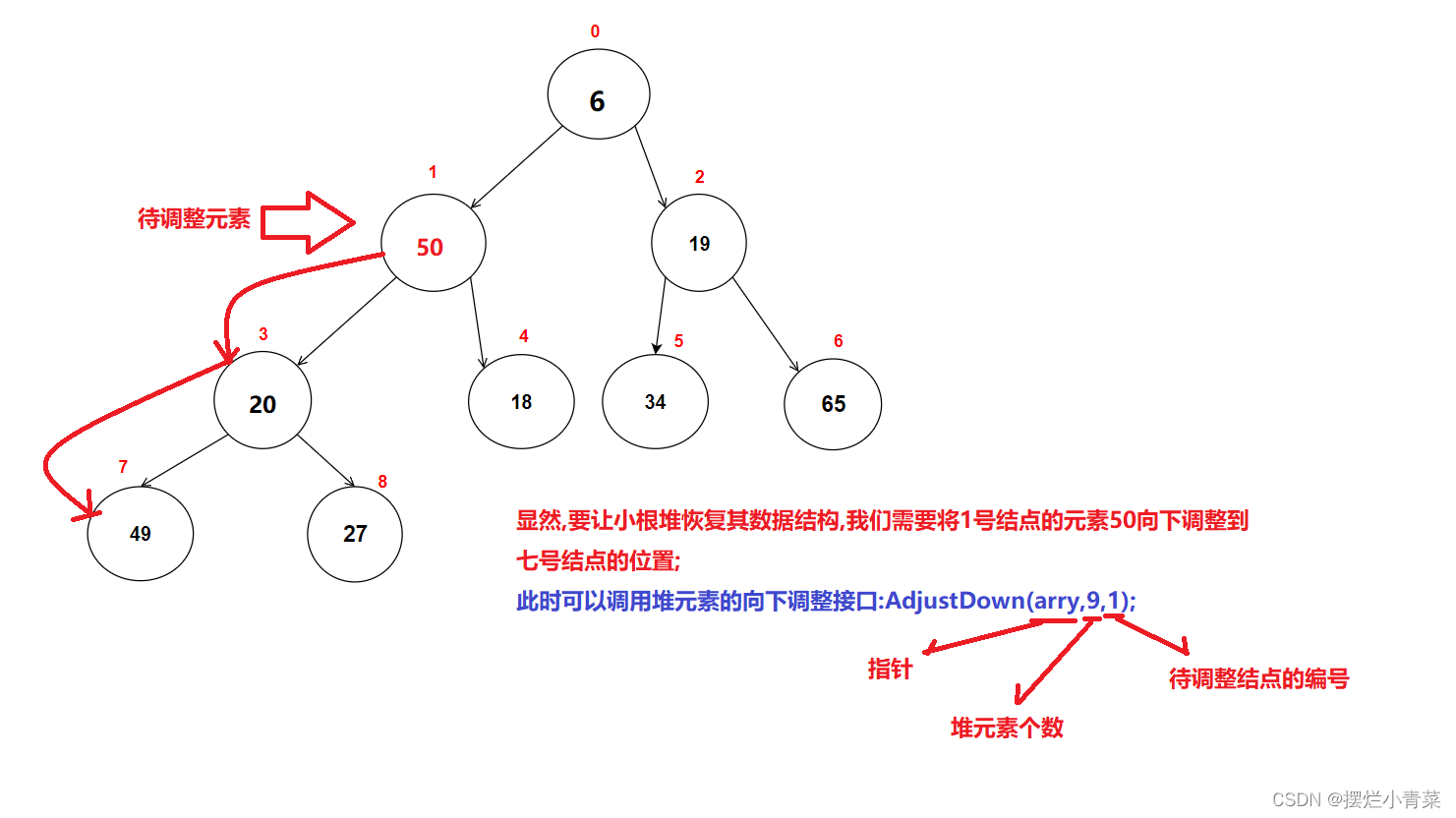
- 由上述前提可知,如果从堆顶(或中间任意一个位置的结点)元素开始调整堆是没有意义的,所以我们只能从堆尾的子结构开始调堆:
- 通过上图的分析,我们可以通过堆尾元素找到第一个要被向下调整的结点,然后从第一个要被向下调整的结点开始依次往前向下调整其他结点直到完成对树的根结点的向下调整之后,整颗完全二叉树就会被调整成堆:
- 调堆小动画:
- 实现将arr数组调整成小根堆的代码:
void HeapSort(int* arr, int size) { assert(arr); int parent = (size - 1 - 1) / 2; //找到第一个要被调整向下调整的元素 for (; parent >= 0; --parent) { AdjustDown(arr, size, parent); //逐个元素向下调整完成堆的构建 } }
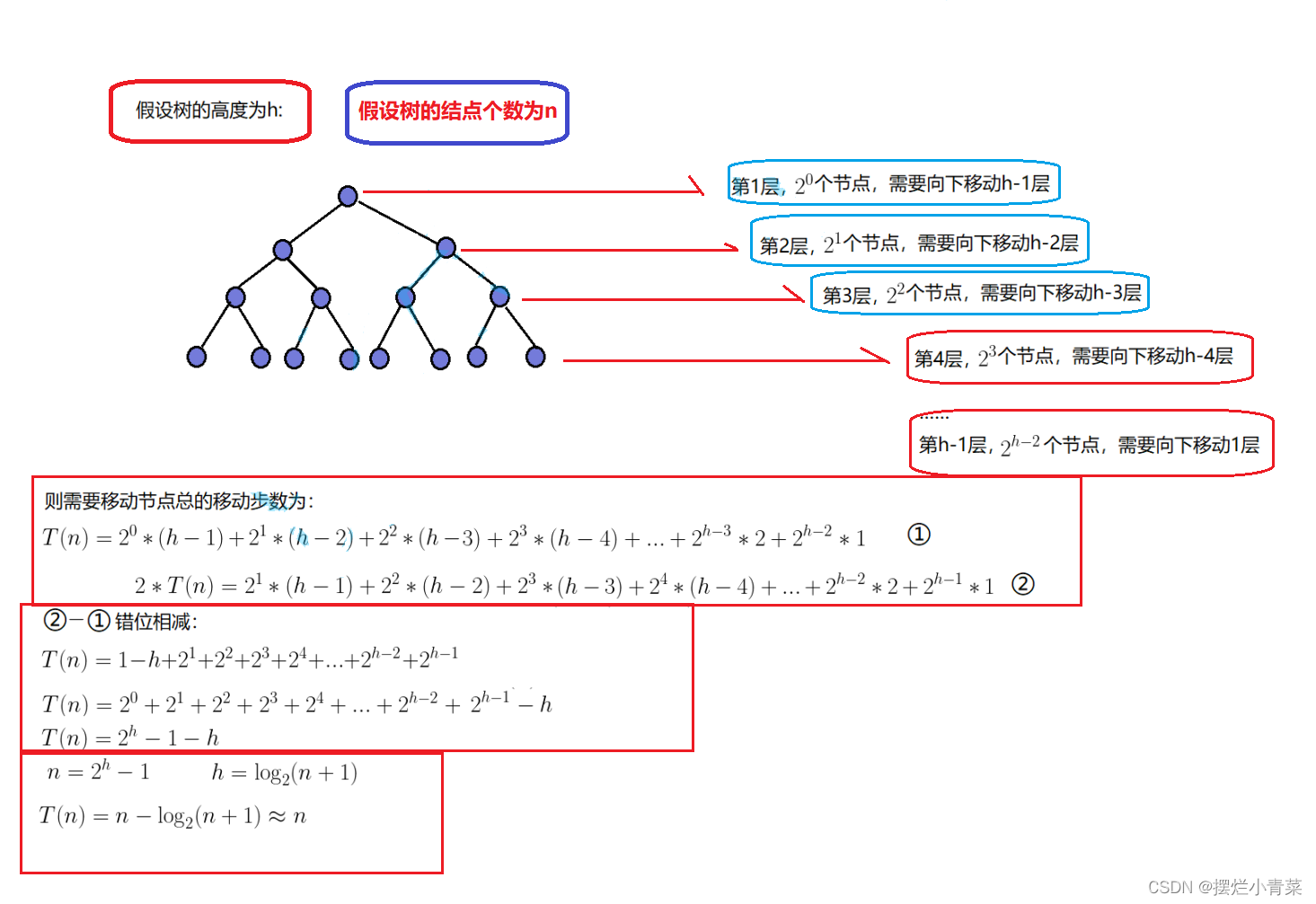
将数组arr调整成堆的时间复杂度分析:
因此假设arr数组中有N个元素,将数组arr调整成堆的时间复杂度为:O(N)
在数组arr数组被调整成堆的基础上完成排序的思路
- 数组arr被调整成小根堆后,我们只需逐个删除堆顶元素就可以完成所有数的降序排序(堆顶的元素是堆中的最值)
- 堆元素删除操作指的是:先将堆顶元素与堆尾元素交换,维护堆尾的下标指针减一(堆元素个数减一),再将堆顶元素向下调整恢复小根堆数据结构(保证堆顶元素永远为堆中的最值))
- 逐个删除堆顶元素完成降序排序的过程图解:
- 整个排序的过程其实相当于每次选出堆顶的数据(堆中的最值)交换到堆尾,因此堆排序是一种选择排序
- 由上述算法设计思路可知:为了完成堆排序我们只需额外设计一个堆元素向下调整算法接口
堆排序代码实现:
//元素交换接口 void Swap(HPDataType* e1, HPDataType* e2) { assert(e1 && e2); HPDataType tem = *e1; *e1 = *e2; *e2 = tem; } //小堆元素的向下调整接口 void AdjustDown(HPDataType* arry,size_t size,size_t parent) { assert(arry); size_t child = 2 * parent + 1; //确定父结点的左孩子的编号 while (child < size) //child增加到大于或等于size时则调整结束 { if (child + 1 < size && arry[child + 1] < arry[child]) //确定左右孩子中较小的孩子结点 { ++child; } if ( arry[child] < arry[parent])//父结点大于子结点,则子结点需要上调以保持小堆的结构 { Swap(arry + parent, arry + child); parent = child; //将原子结点作为新的父结点继续迭代过程 child = 2 * parent + 1; //继续向下找另外一个子结点 } else { break; //父结点不大于子结点,则堆结构任然成立,无需调整 } } } void HeapSort(int* arr, int size) { assert(arr); int parent = (size - 1 - 1) / 2; //找到第一个要被调整向下调整的元素 for (; parent >= 0; --parent) { AdjustDown(arr, size, parent); //逐个元素向下调整完成堆的构建 } while (size > 0) //逐个删除堆顶元素完成降序排序,我们将size作为堆尾指针 { Swap(&arr[0], &arr[size - 1]); //交换堆尾与堆顶元素 size--; //堆尾指针减一,堆元素个数减一 AdjustDown(arr, size, 0); //将堆顶元素向下调整恢复小根堆数据结构 } }排序接口测试:
int main() { int arr[100] = { 0 }; srand((unsigned int)time(NULL)); for (int i = 0; i < 100; i++) { arr[i] = rand() % 10000; //数组每个元素赋上一个随机值 } HeapSort(arr, 100); for (int i = 0; i < 100; ++i) { printf("%d ", arr[i]); } return 0; }
排序时空复杂度分析:
- 逐个删除堆顶元素直到将堆删空的时间复杂度为O(NlogN),证明分析参见青菜的博客:http://t.csdn.cn/vhbJf
- 已知将arr数组调整成堆的时间复杂度为O(N),因此堆排序整体的时间复杂度为O(NlogN)
- 同时易知,堆排序算法的空间复杂度为O(1)
- 可见堆排序是一中高效的选择排序算法
TopK问题指的是,从N个元素数组中,选出K个最值.(K<=N)
Leetcode上面有相关题型.
设计一个算法,找出数组中最小的k个数。以任意顺序返回这k个数均可。(数组元素个数为arrSize)
(k<=arrSize)
示例:
输入: arr = [1,3,5,7,2,4,6,8], k = 4 输出: [1,2,3,4]
题解接口:
int* smallestK(int* arr, int arrSize, int k, int* returnSize) { }arrSize为题设数组的元素个数,k为要找出的最小数的个数,returnSize是结果数组的元素个数
- 本题如果直接对arr数组进行排序理论上是可以解决的,但是时间效率略低(O(NlogN)),有种杀鸡用牛刀的感觉
- 我们可以考虑利用堆数据结构来实现本题的最优解之一:
- 首先创建一个k*sizeof(int)字节大小的数组Heap用于存储大根堆
- 然后将arr中前k个元素尾插到Heap中建立大根堆
- 然后将arr中后(arrSize-k)个元素逐个与Heap堆顶的元素比较,若arr中后(arrSize-k)个元素中的某元素小于Heap堆顶的元素,则将其与Heap堆顶元素交换,再将其进行向下调整操作保持大根堆的数据结构(元素交换入堆)
- 完成arr中后(arrSize-k)个元素与Heap堆顶的遍历比较后,堆中最后剩下的就是arr数组中最小的k个元素
算法图解:
算法的合理性证明:
- 由于大根堆的堆顶元素是堆中的最大元素,因此在arr中后(arrSize-k)个元素与Heap堆顶的遍历比较的过程中没有入堆的元素一定都大于堆中的k个元素,因此最终堆中的k个元素一定是arr数组中最小的k个元素
题解代码:
void Swap(int* e1 ,int* e2) { int tem = *e1; *e1 = *e2; *e2 = tem; } //大堆元素的向上调整接口 void AdjustUp(int * arry, size_t child) //child表示待调整结点的编号 { assert(arry); size_t parent = (child - 1) / 2; while (child > 0) //child减小到0时则调整结束 { if (arry[child] > arry[parent]) //父结点小于子结点,则子结点需要上调以保持大堆的结构 { Swap(arry + child, arry+parent); child = parent; //将原父结点作为新的子结点继续迭代过程 parent = (child - 1) / 2; //继续向上找另外一个父结点 } else { break; //父结点不小于子结点,则堆结构任然成立,无需调整 } } } //大堆元素的向下调整接口 void AdjustDown(int * arry,size_t size,size_t parent) { assert(arry); size_t child = 2 * parent + 1; //确定父结点的左孩子的编号 while (child < size) //child增加到大于或等于size时则调整结束 { if (child + 1 < size && arry[child + 1] > arry[child]) //确定左右孩子中较大的孩子结点 { ++child; } if ( arry[child] > arry[parent])//父结点小于子结点,则子结点需要上调以保持大堆的结构 { Swap(arry + parent, arry + child); parent = child; //将原子结点作为新的父结点继续迭代过程 child = 2 * parent + 1; //继续向下找另外一个子结点 } else { break; //父结点不小于子结点,则堆结构任然成立,无需调整 } } } int* smallestK(int* arr, int arrSize, int k, int* returnSize) { if(0==k) { *returnSize =0; return NULL; } int * Heap = (int*)malloc(k*sizeof(int)); *returnSize = k; //创建一个空间大小为k的数组用于存储堆 int ptrHeap =0; //维护堆尾的指针 while(ptrHeap<k) //将arr数组前k个元素尾插到Heap中完成建堆 { Heap[ptrHeap]=arr[ptrHeap]; AdjustUp(Heap,ptrHeap); ptrHeap++; } int ptrarr = k; //用于遍历arr中后(arrSize-k)个元素的下标指针 while(ptrarr < arrSize) //将arr中后(arrSize-k)个元素逐个与Heap堆顶的元素进行比较 { //如果找到arr中后(arrSize-k)个元素中比堆顶元素小的元素则将该元素替换入堆 //并通过堆元素向下调整接口保持大根堆的数据结构 if(Heap[0]>arr[ptrarr]) { Swap(&Heap[0],&arr[ptrarr]); AdjustDown(Heap,k,0); } ptrarr++; } return Heap; //返回Heap数组作为及结果 }
算法时空复杂度分析:
设数组arr元素个数为N
- 建立Heap数组堆的时间复杂度为O(klogk)
- arr后(N-k)个元素与heap堆顶元素比较并入堆的时间复杂度为O((N-k)logk)(在最坏的情况下,arr后(N-k)个元素每个都进行了交换入堆并且被调整到了堆的叶子结点位置)
- 因此算法的总体时间复杂度为O(Nlogk)
- 易知算法的空间复杂度为O(k)
TopK问题的求解思想有着十分重要的实际意义:
比如在硬盘中有十亿个数据,我们想选出其中的100个最小值,那么利用上面的算法思想我们就可以在极少的内存消耗,极高的时间效率下完成这个工作.

我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
首先回顾一下拉格朗日定理的内容:函数f(x)是在闭区间[a,b]上连续、开区间(a,b)上可导的函数,那么至少存在一个,使得:通过这个表达式我们可以知道,f(x)是函数的主体,a和b可以看作是主体函数f(x)中所取的两个值。那么可以有, 也就意味着我们可以用来替换 这种替换可以用在求某些多项式差的极限中。方法: 外层函数f(x)是一致的,并且h(x)和g(x)是等价无穷小。此时,利用拉格朗日定理,将原式替换为 ,再进行求解,往往会省去复合函数求极限的很多麻烦。使用要注意:1.要先找到主体函数f(x),即外层函数必须相同。2.f(x)找到后,复合部分是等价无穷小。3.要满足作差的形式。如果是加
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非