
世界上最幸福的事之一,莫过于经过一番努力后,所有东西正慢慢变成你想要的样子。
文章标记颜色说明:
- 黄色:重要标题
- 红色:用来标记结论
- 绿色:用来标记一级论点
- 蓝色:用来标记二级论点
Kubernetes (k8s) 是一个容器编排平台,允许在容器中运行应用程序和服务。今天学习一下DNS。
希望这篇文章能让你不仅有一定的收获,而且可以愉快的学习,如果有什么建议,都可以留言和我交流
这是这篇文章所在的专栏,欢迎订阅:【深入解析k8s】专栏
简单介绍一下这个专栏要做的事:
主要是深入解析每个知识点,帮助大家完全掌握k8s,以下是已更新的章节
| 序号 | 文章 |
| 第一讲 | 深入解析 k8s:入门指南(一) |
| 第二讲 | 深入解析 k8s:入门指南(二) |
| 第三讲 | 深入解析Pod对象(一) |
| 第四讲 | 深入解析Pod对象(二) |
| 第五讲 | 深入解析无状态服务 |
| 第六讲 | 深入解析有状态服务 |
| 第七讲 | 深入解析控制器 |
| 第八讲 | 深入解析 ReplicaSet |
| 第九讲 | 深入解析滚动升级 |
| 第十讲 | 深入解析StatefulSet(一) |
| 第十一讲 | 深入解析StatefulSet(二) |
| 第十二讲 | 深入解析DaemonSet |
| 第十三讲 | 深入解析Job |
| 第十四讲 | 深入解析etcd |
我们先来了解一下什么是DNS:
DNS(Domain Name System)是互联网上用于域名解析的分布式数据库系统。
它将域名和 IP 地址之间建立了一种映射关系,使得用户可以使用易于记忆的域名来访问互联网上的各种资源,而不必记住它们的 IP 地址。
DNS(Domain Name System)的工作原理可以分为以下几个步骤:
域名解析请求:当用户在浏览器中输入一个域名时,浏览器会向本地 DNS 服务器发送一个域名解析请求。
本地 DNS 服务器查询:本地 DNS 服务器会首先查询自己的缓存,如果缓存中存在该域名的 IP 地址,则直接返回给浏览器。如果缓存中不存在,则本地 DNS 服务器会向根域名服务器发送一个查询请求。
根域名服务器响应:根域名服务器会返回给本地 DNS 服务器一个下一级域名服务器的 IP 地址。根域名服务器只负责返回下一级域名服务器的 IP 地址,不负责具体的域名解析工作。
顶级域名服务器查询:本地 DNS 服务器收到根域名服务器的响应后,会向下一级域名服务器发送一个查询请求,查询顶级域名服务器的 IP 地址。
顶级域名服务器响应:顶级域名服务器会返回给本地 DNS 服务器一个权威域名服务器的 IP 地址。
权威域名服务器查询:本地 DNS 服务器收到顶级域名服务器的响应后,会向权威域名服务器发送一个查询请求,查询该域名对应的 IP 地址。
权威域名服务器响应:权威域名服务器会返回给本地 DNS 服务器该域名对应的 IP 地址。
本地 DNS 服务器缓存:本地 DNS 服务器将该域名和 IP 地址的映射关系存储在缓存中,以便下一次查询时可以直接返回给浏览器。
浏览器访问:本地 DNS 服务器将该域名对应的 IP 地址返回给浏览器,浏览器通过该 IP 地址访问该域名对应的服务器。
DNS 的工作原理是一个分布式的系统,它可以支持海量的域名解析请求,并且具有高可用性和可靠性。在实际应用中,DNS 的性能和可靠性对于互联网服务的稳定运行具有非常重要的作用。
example.com域名解析示例:
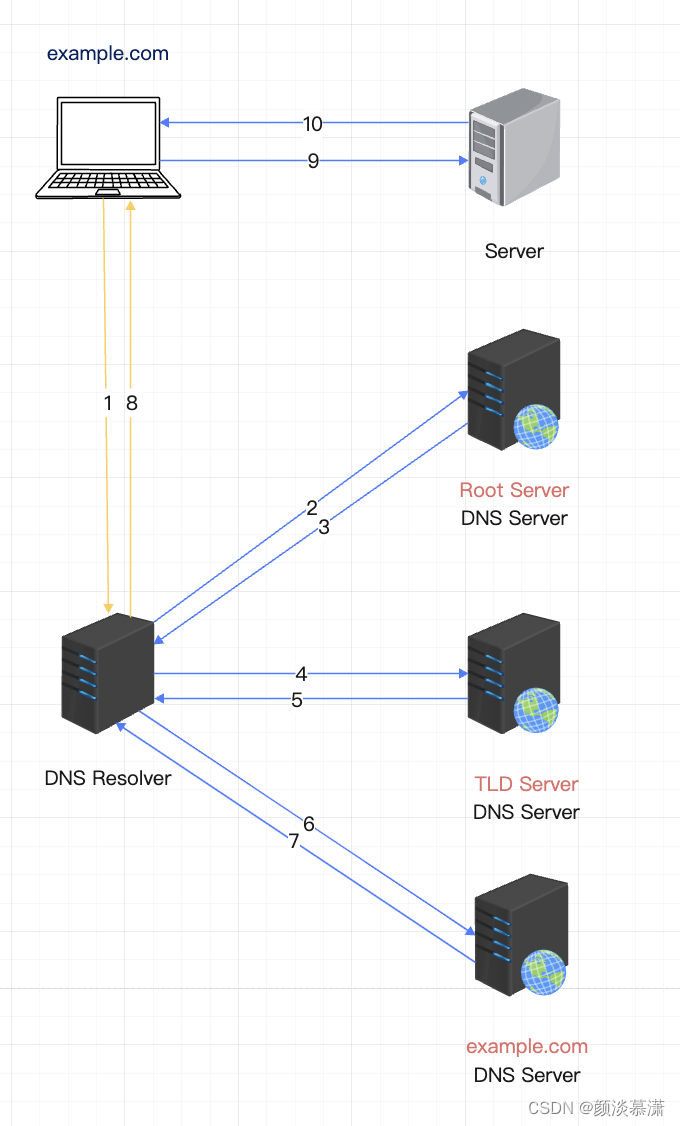
其他DNS的信息,专门还有一篇文章讲解,这里就不展开了,下面我们来看下k8s中,dns的k8s类型
在 Kubernetes 中,有两种常见的 DNS 服务器:
- kube-dns 也是(Cluster DNS)
- CoreDNS
这两个都是 Kubernetes 集群中的默认 DNS 服务器,用于为 Pod 和 Service 提供域名解析服务。
kube-dns 是 Kubernetes 集群中最早的 DNS 解决方案,它由三个组件组成:
- kube-dns
- etcd
- dnsmasq
kube-dns 组件负责接收 DNS 请求,并将请求转发到 etcd 中存储的 DNS 记录中;
etcd 是一个分布式键值存储系统,用于存储 DNS 记录;
dnsmasq 是一个轻量级的 DNS 服务器,用于解析 DNS 请求并返回相应的 IP 地址。
kube-dns 的工作原理如下:
当一个 Pod 或 Service 需要解析一个域名时,它会向 Kubernetes 集群中的 DNS 服务器发送 DNS 请求。
kube-dns 组件会接收到这个请求,并根据请求中的域名和命名空间信息来查找相应的 Pod 或 Service,并返回对应的 IP 地址。
kube-dns 的优点在于它已经被广泛使用,并且在一些旧版本的 Kubernetes 中仍然是默认的 DNS 解决方案。
但是 kube-dns 的可扩展性和灵活性比较有限,而且它的性能也不如 CoreDNS。
CoreDNS 是一个开源的 DNS 服务器,它是 Kubernetes 集群中默认的 DNS 服务器。
与 kube-dns 不同,CoreDNS 可以支持更多的插件,并且具有更好的可扩展性和灵活性。
在 Kubernetes 中,CoreDNS 主要用于为 Pod 和 Service 提供域名解析服务。
当一个 Pod 或 Service 需要解析一个域名时,它会向 Kubernetes 集群中的 DNS 服务器发送 DNS 请求。
如果 CoreDNS 是 Kubernetes 集群中的默认 DNS 服务器,它就会接收到这个请求,并根据请求中的域名和命名空间信息来查找相应的 Pod 或 Service,并返回对应的 IP 地址。
CoreDNS 的工作原理可以分为以下几个步骤:
监听:CoreDNS 监听 Kubernetes 集群中的 DNS 服务 IP 地址和端口,这个地址一般是
10.96.0.10:53。当一个 Pod 或 Service 需要解析一个域名时,它会向这个地址发送 DNS 请求。转发:CoreDNS 接收到 DNS 请求后,会检查请求中的域名是否以
.cluster.local结尾。如果是,则 CoreDNS 会将请求转发给 Kubernetes 集群内部的 Service 或 Pod。判断:如果请求中的域名是一个 Service 的 DNS 名称,则 CoreDNS 会查找该 Service 的所有后端 Pod 的 IP 地址,并将其中一个返回给请求的 Pod 或 Service。
pod判断:如果请求中的域名是一个 Pod 的 DNS 名称,则 CoreDNS 会直接返回该 Pod 的 IP 地址。
上游判断:如果请求的域名不是以
.cluster.local结尾,则 CoreDNS 会将请求转发给上游 DNS 服务器进行解析。CoreDNS 在 Kubernetes 中的工作原理与 kube-dns 类似,但它具有更好的可扩展性和灵活性。
CoreDNS 可以通过插件进行扩展,例如可以添加文件插件来支持从文件中读取 DNS 记录,也可以添加 forward 插件来支持将 DNS 请求转发给外部 DNS 服务器进行解析。
通过这些插件,CoreDNS 可以满足不同的 DNS 解析需求。
需要注意的是,从 Kubernetes 1.13 版本开始,kube-dns 被 CoreDNS 替代成为了默认的 DNS 解决方案。因此,在新版本的 Kubernetes 中,建议使用 CoreDNS 作为 DNS 解决方案。
在 Kubernetes 中,可以通过修改 kubelet 的启动参数来选择使用哪种类型的 DNS 服务。默认情况下,Kubernetes 使用 Cluster DNS。要使用 CoreDNS,需要在 kubelet 的启动参数中设置
--cluster-dns选项。例如:ini
Copy
--cluster-dns=10.96.0.10 --cluster-domain=cluster.local这将使用 IP 地址为
10.96.0.10的 CoreDNS 服务,并将集群域设置为cluster.local。
DNS 在 Kubernetes 中有以下几种应用:
服务发现:Kubernetes 中的 DNS 服务可以让容器和服务通过域名进行通信,而不用关心容器 IP 地址的变化。每个 Kubernetes Service 都会被分配一个 DNS 名称,可以通过该名称访问该服务中的所有容器。
Pod 间通信:Kubernetes 中的每个 Pod 都会被分配一个唯一的 DNS 名称,可以通过该名称访问同一节点上的其他 Pod。
横向扩展:当一个 Kubernetes Deployment 水平扩展时,新创建的 Pod 也会被自动注册到 DNS 中,从而使得它们可以被其他 Pod 和服务发现。
集群内部域名解析:Kubernetes 集群中的 DNS 服务可以解析集群内部的域名,比如 Kubernetes API Server 的域名和 Service 的域名等。
集群外部域名解析:Kubernetes 集群中的 DNS 服务可以配置为解析集群外部的域名,从而使得容器和服务可以访问外部的服务和资源。
在 Kubernetes 中,每个 Service 都会被分配一个唯一的 DNS 名称。这个 DNS 名称由 Service 名称和所在的命名空间组成。
形式为
servicename.namespace.svc.cluster.local。这个 DNS 名称可以被 Kubernetes 集群中的任何容器和服务使用,通过该名称访问该服务中的所有容器。
这种服务发现机制使得容器和服务可以轻松地进行通信,而不用关心容器 IP 地址的变化。
下面是一个使用 Service 发现机制的示例代码。
假设我们有一个名为
my-service的 Service,它将流量路由到名为my-pod的 Pod。可以在另一个 Pod 中使用my-service的 DNS 名称来访问该服务:
import requests
# 使用 Service 的 DNS 名称访问服务
response = requests.get("http://my-service.namespace.svc.cluster.local")
# 处理响应
if response.status_code == 200:
print("Success!")
else:
print("Error!")
在 Kubernetes 中,每个 Pod 都会被分配一个唯一的 DNS 名称。这个 DNS 名称由 Pod 名称和所在的命名空间组成。
形式为
podname.namespace.pod.cluster.local。这个 DNS 名称可以被同一节点上的其他 Pod 使用,通过该名称访问同一节点上的其他 Pod。
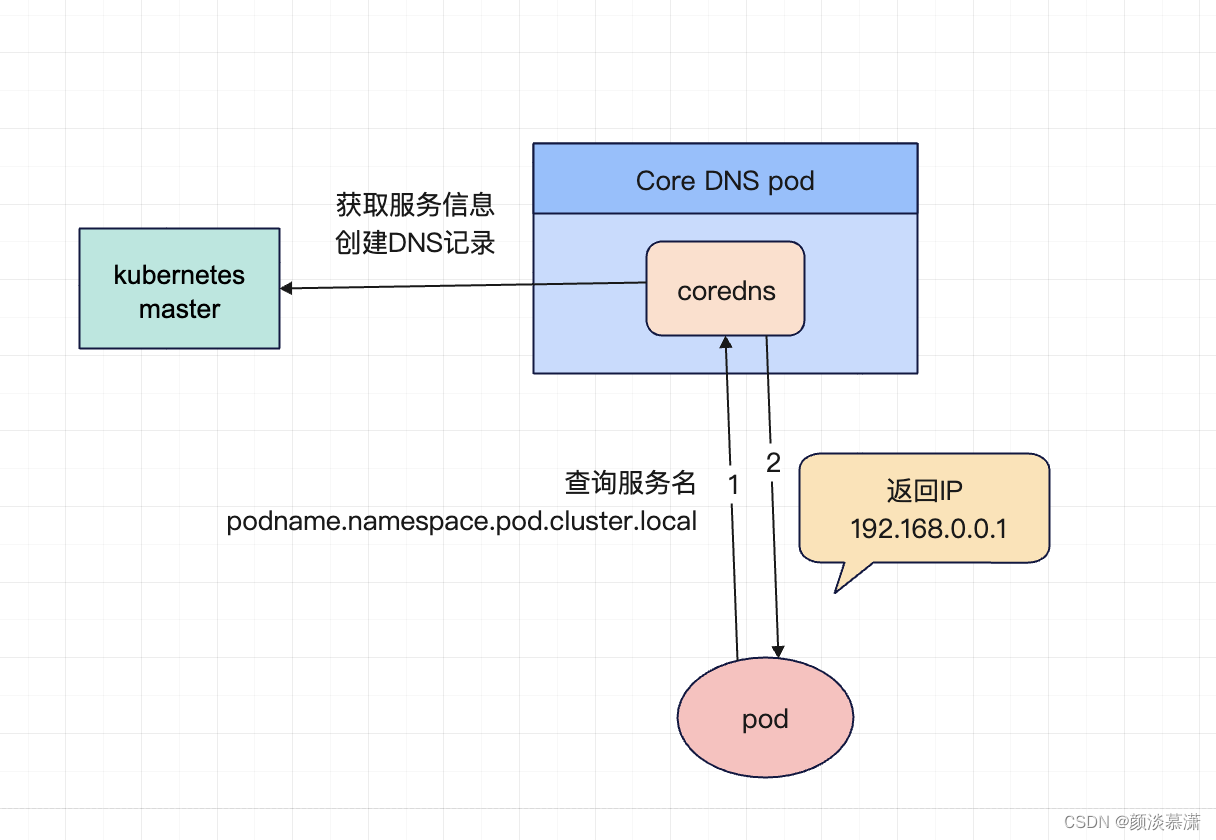
下面是一个使用 Pod 间通信的示例代码。假设有两个名为
pod1和pod2的 Pod,它们都运行在同一个节点上。我们可以在pod1中使用pod2的 DNS 名称来访问pod2:
import requests
# 使用 Pod 的 DNS 名称访问另一个 Pod
response = requests.get("http://pod2.namespace.pod.cluster.local")
# 处理响应
if response.status_code == 200:
print("Success!")
else:
print("Error!")
在 Kubernetes 中,当一个 Deployment 水平扩展时,新创建的 Pod 也会被自动注册到 DNS 中,从而使得它们可以被其他 Pod 和服务发现。
这意味着我们可以轻松地扩展我们的应用程序,并确保所有新创建的 Pod 都可以与其他 Pod 和服务进行通信。
下面是一个使用横向扩展的示例代码。假设有一个名为
my-deployment的 Deployment,它由一个名为my-pod的 Pod 组成。我们可以使用该 Deployment 的名称来访问my-pod,并且可以轻松地扩展 Deployment,以便添加更多的 Pod:
import requests
# 使用 Deployment 的名称访问 Pod
response = requests.get("http://my-deployment.namespace.svc.cluster.local")
# 处理响应
if response.status_code == 200:
print("Success!")
else:
print("Error!")
在 Kubernetes 中,集群内部的域名可以被自动解析。
例如,Kubernetes API Server 的域名为
kubernetes.default.svc.cluster.local,可以被 Kubernetes 集群中的任何容器和服务使用。这个域名可以用于访问 Kubernetes API Server,以及其他需要访问 Kubernetes 集群内部资源的情况。
下面是一个使用集群内部域名解析的示例代码。假设我们需要访问 Kubernetes API Server,我们可以使用
kubernetes.default.svc.cluster.local的 DNS 名称来访问它:
import requests
# 使用 Kubernetes API Server 的 DNS 名称访问它
response= requests.get("https://kubernetes.default.svc.cluster.local/api/v1/namespaces")
# 处理响应
if response.status_code == 200:
print("Success!")
else:
print("Error!")
Kubernetes 集群中的 DNS 服务可以配置为解析集群外部的域名,从而使得容器和服务可以访问外部的服务和资源。
这个功能可以通过在 Kubernetes 中配置外部 DNS 服务器来实现。
下面是一个使用集群外部域名解析的示例代码。假设我们需要访问 Google 的网站,我们可以使用 Google 的域名来访问它:
import requests
# 使用 Google 的域名访问它
response = requests.get("https://www.google.com")
# 处理响应
if response.status_code == 200:
print("Success!")
else:
print("Error!")
需要注意的是,这个示例代码并没有直接使用 Kubernetes 集群中的 DNS 服务来解析 Google 的域名。
为了使用 Kubernetes 集群中的 DNS 服务解析外部域名,需要在 Kubernetes 中配置外部 DNS 服务器。

我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315