好家伙,写题,题目代码在最后
来吧,
这一端被称为栈顶,相对地,把另一端称为栈底。
向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;
从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。 ——百度百科
上图
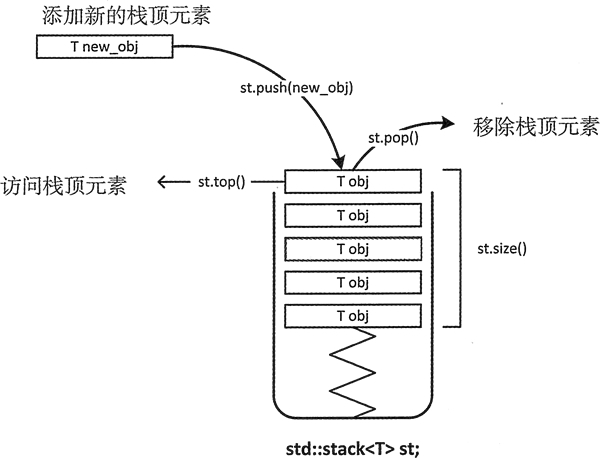
总之,我们记住这玩意"先进后出"就行了
举个栗子,(假设水倒入杯子后不会流动)
就像你烧了一壶水,拿个杯子倒水,然后喝了一口
你喝的第一口水是你最后倒进去的
而你最先倒进去的水在最下面
最后倒进去的水最先喝到
最先倒进去的最后喝到
这就是先进后出了
(是不是拿固体举例子会比较好...)
方法以及标识:
//头文件
#include <stack>
//实例化字符类型的栈
stack <char> sta;常用方法:
1.1.sta.top()方法
函数用于访问栈顶元素
1.2.sta.pop()
函数用于移除栈顶元素
1.3.sta.size()
函数返回堆栈元素的数量。堆栈元素的数量是指堆栈的大小。
堆栈元素的大小是非常重要的信息,因为基于它我们可以推断出许多其他内容,例如所需的空间等。
1.4.sta.push(new_obj)
函数用于在栈顶添加新元素
1.5.sta.empty()
函数用于测试容器是否为空
输入一串字符串,该字符串只能由各种不同的括号组成,设计算法,测试该字符串中的括号是否匹配。
如:“({[]})”该字符串中括号是匹配的,字符串“[{{}(”是不匹配的,要求采用栈的思想来完成该题目
我们用栈去解决这个题目(不然为什么会有上面的内容)
这种对称的题目用栈来做就是很舒服
利用栈的先进后出的特点,我们可以进行左右括号的匹配,“(){}”,在右括号“)}”左边最近的左括号必须是相对应的“({”,否则就不合法
先把左半边的括号全部入栈,然后按入栈的反顺序依次去查对应右括号,(如先入"{("那么就先查")}")
若果出现不匹配,则返回false,
每次匹配一对正确的括号,就要将其出栈,为后面的括号腾出空间。
上代码:
#include <iostream>
#include <stack>
using namespace std;
bool isValid(string s) {
stack <char> sta;
char c,b;
int l=s.length();
for(int i=0;i<l;i++)
{
//将所有的左半边括号入栈
if(s[i]=='(' || s[i]=='[' || s[i]=='{')
{
sta.push(s[i]);
}
//对后面的元素逐一检查
//三种情况
//1.栈空了,返回false
//2.成功匹配,将成功匹配的字符出栈
//3.其他情况,返回false
else if(s[i]==')')
{
if(sta.empty())
return false;
else if(c=sta.top(),c=='(')
sta.pop();
else
return false;
}
else if(s[i]==']')
{
if(sta.empty())
return false;
else if(c=sta.top(),c=='[')
sta.pop();
else
return false;
}
else if(s[i]=='}')
{
if(sta.empty())
return false;
else if(c=sta.top(),c=='{')
sta.pop();
else
return false;
}
}
if(sta.empty())
return true;
else
return false;
}
int main()
{
string s;
cin>>s;
//输入字符
bool b=true;
b=isValid(s);
if(b==true)
cout << "true";
else cout << "false";
return 0;
}
输入样例:
输入: ({}(000))
输出: true
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
如何匹配未被反斜杠转义的平衡定界符对(其本身未被反斜杠转义)(无需考虑嵌套)?例如对于反引号,我试过了,但是转义的反引号没有像转义那样工作。regex=/(?!$1:"how\\"#expected"how\\`are"上面的正则表达式不考虑由反斜杠转义并位于反引号前面的反斜杠,但我愿意考虑。StackOverflow如何做到这一点?这样做的目的并不复杂。我有文档文本,其中包括内联代码的反引号,就像StackOverflow一样,我想在HTML文件中显示它,内联代码用一些spanMaterial装饰。不会有嵌套,但转义反引号或转义反斜杠可能出现在任何地方。
我有一个驼峰式字符串,例如:JustAString。我想按照以下规则形成长度为4的字符串:抓取所有大写字母;如果超过4个大写字母,只保留前4个;如果少于4个大写字母,则将最后大写字母后的字母大写并添加字母,直到长度变为4。以下是可能发生的3种情况:ThisIsMyString将产生TIMS(大写字母);ThisIsOneVeryLongString将产生TIOV(前4个大写字母);MyString将生成MSTR(大写字母+tr大写)。我设法用这个片段解决了前两种情况:str.scan(/[A-Z]/).first(4).join但是,我不太确定如何最好地修改上面的代码片段以处理最后一种
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
我真的为这个而疯狂。我一直在搜索答案并尝试我找到的所有内容,包括相关问题和stackoverflow上的答案,但仍然无法正常工作。我正在使用嵌套资源,但无法使表单正常工作。我总是遇到错误,例如没有路线匹配[PUT]"/galleries/1/photos"表格在这里:/galleries/1/photos/1/edit路线.rbresources:galleriesdoresources:photosendresources:galleriesresources:photos照片Controller.rbdefnew@gallery=Gallery.find(params[:galle
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD