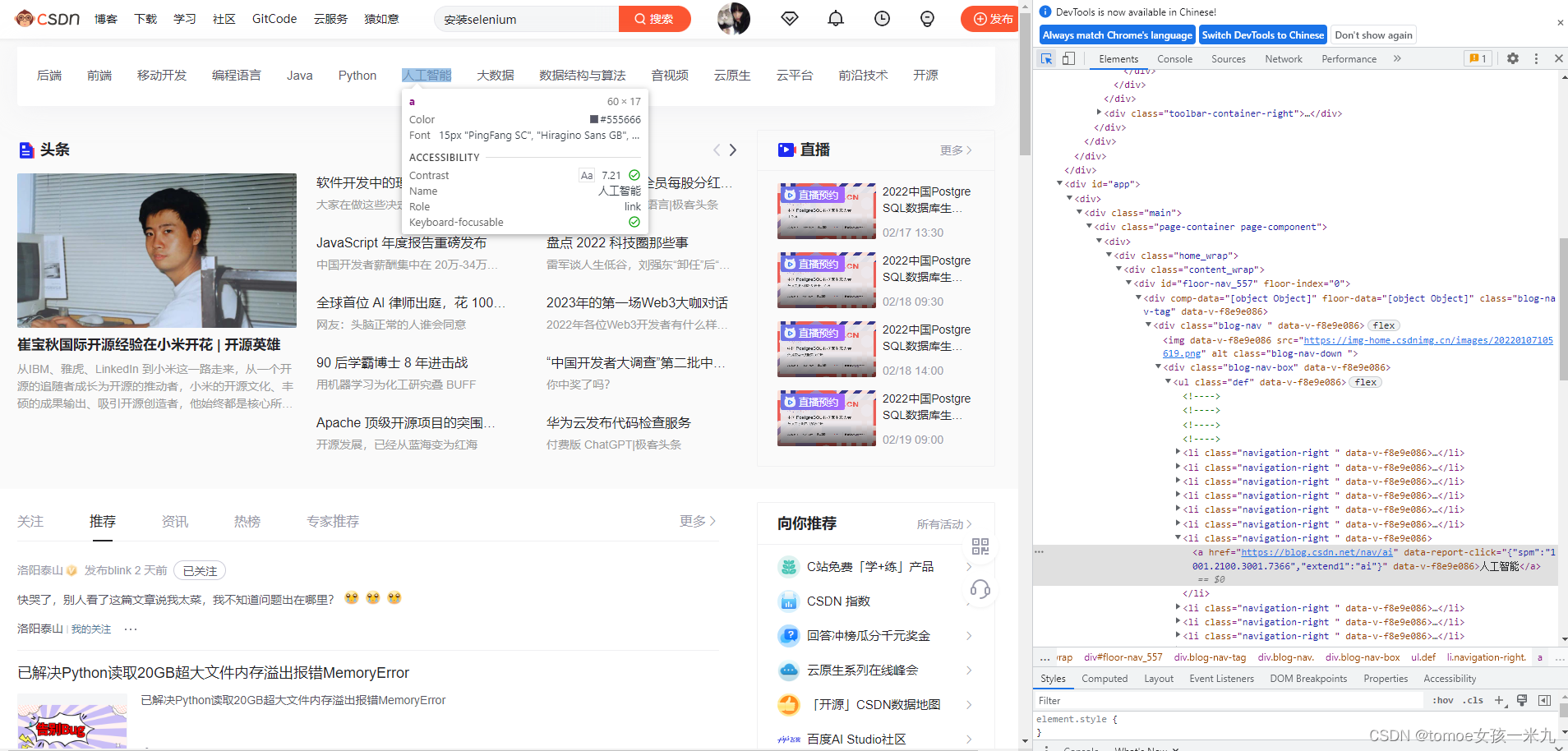
1、通过页面开发者工具(点击键盘F12或者空白处右击点击检查)中的element,查看页面html代码;
2、点击开发者工具左上角鼠标按钮;
3、鼠标移动至需要定位元素位置;
4、高亮显示;
5、右击选择定位方式。
from selenium import webdriver
import time
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
url = 'https://www.csdn.net/'
browser.get(url)
browser.maximize_window()
time.sleep(5)
# browser.close()
browser.quit()
注意:
关闭浏览器close和quit的区别:
以下是两个函数的描述,可见close() 只关闭当前窗口;quit() 退出驱动程序并关闭所有相关窗口。
def close(self) -> None:
"""
Closes the current window.
:Usage:
::
driver.close()
"""
self.execute(Command.CLOSE)
def quit(self) -> None:
"""
Quits the driver and closes every associated window.
:Usage:
::
driver.quit()
"""
try:
self.execute(Command.QUIT)
finally:
self.stop_client()
self.command_executor.close()
browser = webdriver.Chrome()
browser.get('https://www.csdn.net/')
browser.maximize_window()
time.sleep(5)
browser.quit()
使用find_element函数来定位元素。
id值在一个页面中是唯一的。
browser = webdriver.Chrome()
browser.get('https://www.csdn.net/')
browser.maximize_window()
time.sleep(5)
browser.find_element(By.ID, "toolbar-search-input").send_keys("python")
time.sleep(5)
browser.find_element(By.ID, "toolbar-search-button").click()
time.sleep(5)
browser.quit()
name属性在同一个表单中唯一,但在页面不唯一。若有两个name属性相同的元素,使用该方法会定位到name属性第一次出现的地方。

browser.find_element(By.NAME, "username").click()
class属性同样不唯一,页面中可能会出现多个,使用该方法定位到的也是第一个拥有该class属性的元素。

browser.find_element(By.CLASS_NAME, "blog-nav-box").click()
传入的参数格式:标签名[属性名=属性值],通过标签与属性的组合来唯一的定位页面元素
browser.find_element(By.CSS_SELECTOR, "input[id='toolbar-search-input']").click()
这种方法只适合定位链接元素
browser.find_element(By.By.LINK_TEXT, "Python").click()
browser = webdriver.Chrome()
browser.get('https://www.csdn.net/')
browser.maximize_window()
browser.find_element(By.XPATH, '//*[@id="csdn-toolbar"]/div/div/div[3]/div/div[3]/a').click()
browser.find_element(By.XPATH, '//*[@id="toolbar-search-input"]').send_keys("人工智能")
browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]').click()
time.sleep(5)
browser.quit()
| / | 表示一个层级,从根节点开始定位(绝对路径) |
|---|---|
| // | 表示多个层级,从任意位置开始定位 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| * | 匹配任何元素节点 |
| //* | 选取文档中的所有元素 |
|---|---|
| @* | 匹配任何属性节点 |
| //title[@*] | 选取所有带有属性的title元素 |
| /div/div[3] | 选取div下的第三个div的元素 |
|---|---|
| //div | 选取所有div元素,不管他们在文档中的位置 |
| div//title | 选取div元素的后代的所有title元素 |
| //@lang | 选取名为lang的所有属性 |
| //title[@lang='eng] | 选取所有title元素,并且带有值为eng的lang属性 |
| //div|//title | 选取文档中的所有div和title元素 |
# 清除文本框内容:使用clear()方法
browser.find_element(By.XPATH, '//*[@id="toolbar-search-input"]').clear()
# 点击
browser.find_element(By.XPATH, '//*[@id="toolbar-search-button"]').click()
# 填写文本内容
browser.find_element(By.XPATH, '//*[@id="toolbar-search-input"]').send_keys("人工智能")
# 获取元素的属性信息:使用get_attribute(“属性名”)
browser.find_element(by, element_value).get_attribute('value')
# 切换fram框架, "frame_value"可以是id、name属性值,也可以是序号index,假如有2个iframe
# 第一个序号就是0
browser.switch_to.frame(frame_value)
# 切换窗口
handles = browser.window_handles # 获取当前全部窗口句柄集合
now_handle = driver.current_window_handle # 获取当前窗口句柄
browser.switch_to.window(now_handle) # 切换至当前窗口
# 切换alert
# accept - 点击【确认】按钮
# dismiss - 点击【取消】按钮(如有按钮)
# send_keys - 输入内容(如有输入框)
alert = switch_to.alert().accept() #点击确认
def open_browser0(public_devices):
"""
打开浏览器------无头模式
:param public_devices:
"""
global browser
ch_options = Options()
ch_options.add_argument("--headless") # 为chrome设置无头模式 options=ch_options
public_devices.driver = webdriver.Chrome()
log.info("打开浏览器:%s" % public_devices.driver)
browser = public_devices.driver
browser.get("http://%s" % public_devices.path)
log.info("get_url: %s" % public_devices.path)
browser.maximize_window()
time.sleep(2)
def close_browser():
"""
logout,并关闭浏览器
"""
global browser
browser.quit()
log.info("关闭浏览器")
@exist
def logout(element_value, element_type):
"""
退出登录
"""
global browser
alert_prencence()
res = browser.switch_to.default_content()
log.info("切换至默认frame")
click_element_by(element_value, element_type)
log.info("退出登录")
def execute(cmd):
"""
执行命令
:param cmd:
"""
global browser
log.info(browser.execute(cmd))
def refresh():
"""
刷新页面
"""
global browser
browser.refresh()
log.info("刷新页面")
time.sleep(2)
@exist
def check_element(node_element):
"""
判断用户是否可见该节点元素
:param node_element:
:return:
"""
if node_element.is_displayed():
return True
else:
return False
def switch_to_frame(frame_value):
"""
切换fame
:param frame_value:
"""
global browser
browser.switch_to.frame(frame_value)
log.info("切换frame到:%s" % frame_value)
def switch_to_window(window_value, window_type):
"""
切换浏览器窗口
:param window_value:
:param window_type:
"""
global browser
handles = browser.window_handles
log.info(browser.switch_to.window(handles[window_value]))
@exist
def set_element_text(element_value, set_value, element_type):
"""
输入框输入
:param element_value:元素定位
:param set_value:要设置的值
:param element_type:元素类型,支持id、xpath、link_text、partial_link_text、name、tag_name、class_name、css_selector
"""
global browser
by = whichType(element_type)
browser.find_element(by, element_value).send_keys(set_value)
log.info("输入:%s", set_value)
time.sleep(2)
@exist
def clear_element_text(element_value, element_type='XPATH'):
"""
清空输入框
:param element_value:元素定位
:param element_type:元素类型,支持id、xpath、link_text、partial_link_text、name、tag_name、class_name、css_selector
"""
global browser
by = whichType(element_type)
log.info(browser.find_element(by, element_value).clear())
time.sleep(2)
@exist
def get_text(element_value, element_type):
"""
获取元素,并打印
:param element_value:元素定位
:param element_type:元素类型,支持id、xpath、link_text、partial_link_text、name、tag_name、class_name、css_selector
"""
global browser
by = whichType(element_type)
element = browser.find_elements(by, element_value)
res = element.__getattribute__('text')
log.info("获取元素", res)
return res
@exist
def get_element_attribute(element_value, element_type):
"""
获取元素属性并返回
:param element_value:元素定位
:param element_type:元素类型,支持id、xpath、link_text、partial_link_text、name、tag_name、class_name、css_selector
:return:
"""
global browser
by = whichType(element_type)
attribute = browser.find_element(by, element_value).get_attribute('value')
log.info("获取元素属性:%s", attribute)
return attribute
@exist
def click_element_by(element_value, element_type):
"""
点击元素
:param element_value:元素定位
:param element_type:元素类型,支持id、xpath、link_text、partial_link_text、name、tag_name、class_name、css_selector
"""
global browser
by = whichType(element_type)
log.info("点击元素 %s", element_value)
browser.find_element(by, element_value).click()
time.sleep(2)
def alert_prencence():
result = EC.alert_is_present()(browser)
if result:
log.info(result.text)
result.accept()
else:
log.info("未弹出!")
通过添加装饰器,不改变原函数代码、不改变函数返回值,判断元素是否存在。
def exist(func):
"""
装饰器,判断元素是否存在
:param func:需要判断元素的函数
:return:函数
"""
global browser
def wrapper(*args, **kwargs):
keys = inspect.signature(func).parameters # 得到的是不可迭代对象
keys_str = str(keys)
if keys_str.find('element_type') >= 0 and keys_str.find('element_value') >= 0:
# 变成list后,可根据索引获取参数名对应的参数值
keys_lis = list(keys)
index_type = keys_lis.index("element_type") # 获取元素类型索引
index_value = keys_lis.index("element_value") # 获取元素值索引
element_type = whichType(args[index_type]) # 取对应索引参数值
element_value = args[index_value]
try:
WebDriverWait(browser, 5, 0.5).until(EC.presence_of_element_located((element_type, element_value)))
return func(*args, **kwargs)
except TimeoutException as e:
log.error("timeout")
raise ElementnotFoundException(element_type, element_value)
return wrapper
class ElementnotFoundException(Exception):
"""
自定义异常
:param
:return:字符串
"""
def __init__(self, element_type, element_value):
self.element_type = element_type
self.element_value = element_value
def __str__(self):
log.error("\n找不到元素: %s" % self.element_value)
# return "\n找不到元素: %s" % self.element_value
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我是HanamiWorld的新人。我已经写了这段代码:moduleWeb::Views::HomeclassIndexincludeWeb::ViewincludeHanami::Helpers::HtmlHelperdeftitlehtml.headerdoh1'Testsearchengine',id:'title'hrdiv(id:'test')dolink_to('Home',"/",class:'mnu_orizontal')link_to('About',"/",class:'mnu_orizontal')endendendendend我在模板上调用了title方法。htm
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
require'mechanize'agent=Mechanize.newlogin=agent.get('http://www.schoolnet.ch/DE/HomeDE.htm')agent.clicklogin.link_withtext:/Login/然后我得到Mechanize::UnsupportedSchemeError。 最佳答案 Mechanize不支持javascript但您可以将搜索字段添加到表单并为其分配搜索词并使用mechanize提交表单form=page.forms.firstform.add_fie
在Ruby中,是否有一种简单的方法可以将n维数组中的每个元素乘以一个数字?这样:[1,2,3,4,5].multiplied_by2==[2,4,6,8,10]和[[1,2,3],[1,2,3]].multiplied_by2==[[2,4,6],[2,4,6]]?(很明显,我编写了multiplied_by函数以区别于*,它似乎连接了数组的多个副本,不幸的是这不是我需要的)。谢谢! 最佳答案 它的长格式等价物是:[1,2,3,4,5].collect{|n|n*2}其实并没有那么复杂。你总是可以使你的multiply_by方法:c
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],
我有一个非常简单的Controller来管理我的Rails应用程序中的静态页面:classPagesController我怎样才能让View模板返回它自己的名字,这样我就可以做这样的事情:#pricing.html.erb#-->"Pricing"感谢您的帮助。 最佳答案 4.3RoutingParametersTheparamshashwillalwayscontainthe:controllerand:actionkeys,butyoushouldusethemethodscontroller_nameandaction_nam