C语言中有许多类型,比如整形int,字符型char,双精度浮点型double等等。这些类型可以存放一些值或者字符。但是如果我想要一种类型存放一本书,显然是没有的,那么这时候就需要自定义类型了,也就是结构体,这本书有书名,作者,价格,ISBN码等等,我们就专门创建一个结构体来存放这些信息。
下面我们来声明一个名字为Book的结构体类型
struct Book//创建结构体类型需要加上struct关键字 后面就是这个类型的名字Book
{ //大括号内部就可以创建结构体里面的成员变量,以后就可以通过Book类型找到里面的成员
char name[20];
char autor[10];
char ISBN[20];
int price;
};当然结构体的成员也可以是结构体
struct a//声明了结构体a
{
int a;
char b;
float c;
};
struct b//声明了结构体b
{
int a;
char b;
float c;
struct a d;//这个成员的类型是struct a,变量名是d
};还有一种匿名结构体声明,就是声明的时候struct后不加类型名。
struct//这里没有结构体类型名,是匿名结构体
{
char name[20];
char autor[10];
char ISBN[20];
int price;
};那么结构体自己引用自己可以吗?这个叫结构体的自引用,比如下面这个。
struct Node
{
int data;
struct Node next;
};
可以发现运行的时候报错了 ,因为在创建类型为struct Node的变量next时,struct Node类型还没有声明,并且这样的结构体也不能求出其大小,所以这样自引用是错误的。
正确的自引用应该是声明结构体自己的指针。
struct Node
{
int data;
struct Node* next;//正确的自创建是定义一个struct Node*类型的变量,也就是创建结构体的指针
};我们已经声明好了一个结构体变量,就可以像定义int,char类型的变量一样来定义结构体变量。
struct Book
{
char name[20];
char autor[10];
char ISBN[20];
int price;
};
int main()
{
int a;//定义了int类型的变量a
char b;//定义了char类型的变量b
float c;//定义了float类型的变量c
struct Book d;//定义了struct Book类型的变量d
return 0;
}当然也可以在声明完变量之后定义结构体变量。
struct Book
{
char name[20];
char autor[10];
char ISBN[20];
int price;
}; struct Book d;//定义了struct Book类型的变量d下面是结构体的初始化,以及结构体嵌套的初始化。
struct Book
{
char name[20];
char autor[10];
char ISBN[20];
int price;
}; struct Book d = {"C语言深度剖析","陈正冲","978-7-5124-0837-1",29};
//初始化用大括号,每个变量初始化用逗号分隔,字符串要加上""int main()
{
struct Book d = { "C语言深度剖析","陈正冲","978-7-5124-0837-1",29 };
//也可以在主函数定义变量并初始化
return 0;
}可以调试并监视结构体变量里面的值。

然后是嵌套结构体的初始化。
struct a
{
int a;
char b;
float c;
};
struct b
{
int a;
char b;
float c;
struct a d;//创建了struct a类型的结构体变量d
};
int main()
{
struct b test = { 1,'a',1.0f,{2,'b',2.0f}};
//只需再加一个大括号就可以对嵌套结构体初始化,2个以上的嵌套也是同理
//小数后面加上f意思是强制转换成float类型,因为小数默认是double类型
return 0;
}怎么用结构体变量来访问它的成员呢?有两种方法: . 和 -> 。
比如我想把一本书的信息输入并打印出来。
int main()
{
struct Book book;//定义结构体变量,未初始化
printf("请输入书的信息:");
scanf("%s %s %s %d", book.name, book.autor, book.ISBN, &book.price);
//用(结构体变量名).(成员名) 就可以访问成员了
//也可以用 (结构体变量的地址)->(成员名) 也可以访问成员
printf("%s %s %s %d", book.name, book.autor, book.ISBN, book.price);
return 0;
}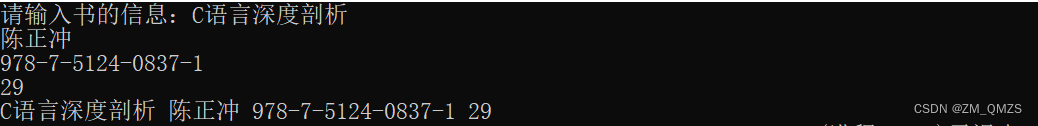
结构体的大小不等于所有成员的大小相加。它存在内存对齐,我们要引出对齐数这个概念。
对齐数就是一个类型的大小,这个类型不包括自定义类型,比如int的对齐数就是4,char对齐数就是1。还有默认对齐数和当前的编译环境有关,Visual Studio的默认对齐数是8。而gcc没有默认对齐数,对齐数就是类型自身大小。
结构体第一个成员在内存中放在内存偏移量为0的位置,这个内存偏移量是相对于结构体变量的地址,也就是第一个成员的地址。而第二个成员会在自身对齐数和默认对齐数中取较小值(这个较小值就是这个成员的对齐数),然后放在内存偏移量是其对齐数的整数倍的位置,以此类推,而结构体的大小必须是最大对齐数(所有成员的对齐数中最大的)的整数倍。
int main()
{
struct S1
{
char c1;//自身对齐数是1,默认对齐数是8,对齐数就取较小值1
int i;//自身对齐数是4,默认对齐数是8,对齐数就取较小值4
char c2;//自身对齐数是1,默认对齐数是8,对齐数就取较小值1
};
printf("%d\n", sizeof(struct S1));
return 0;
}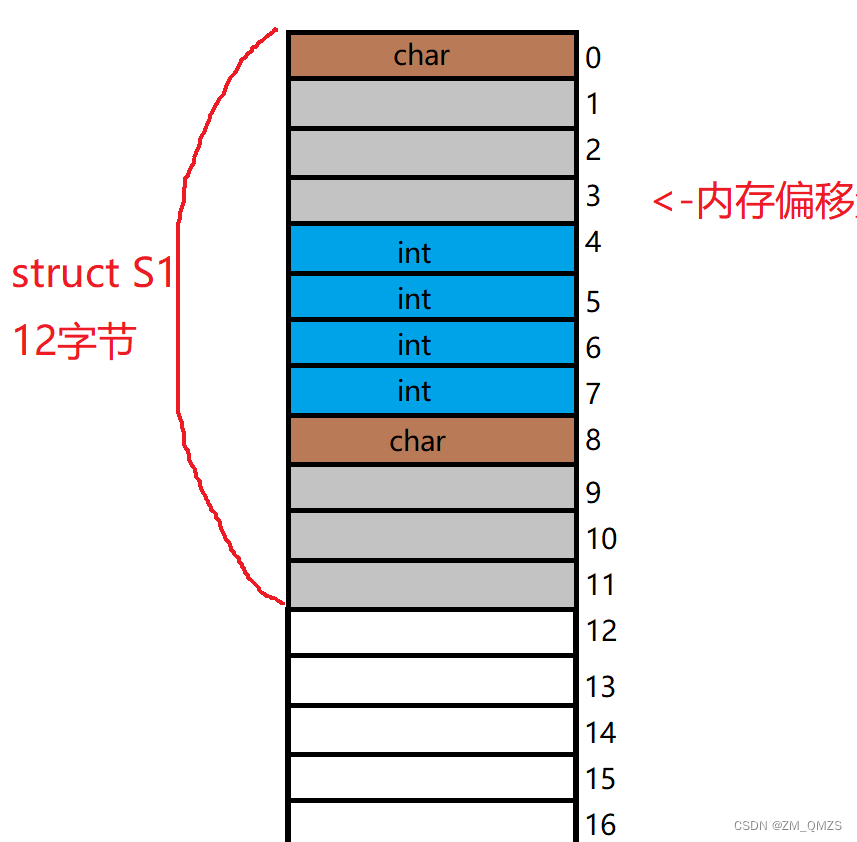
上面代码我们已经分析过了char的对齐数是1,int的对齐数是4,每个成员需要对齐能够整除其对齐数的内存偏移量,比如char对齐的是0偏移量,因为0是1的0倍,而下一个成员int需要对齐4的整数倍,所以放在4偏移量处,而下一个char需要对齐1的倍数的内存偏移量,所以放在8偏移量处。
然后来计算结构体的大小,因为结构体大小必须是所有对齐数中最大的那个对齐数的整数倍,而int是最大的,所以结构体的大小应该是int的对齐数4的整数倍,所以是12字节。虽然第二个char的偏移量是8,但是到第二个char这里已经是9个字节了,并不是8个字节。

上图中灰色的部分是浪费的内存,在大部分情况下这是不可避免的,但是有些时候我们也可以优化一下,增加内存利用率 。
比如我们可以把两个char放在一起创建,这样第二个char就可以对齐偏移量1。从而使整个结构体大小从12个字节变成8个字节。
struct S1
{
char c1;
//这里把两个char放在了一起,而不是把第二个char放在int后面
char c2;
int i;
}; 
问题来了,如果我再加上一个double类型的变量,那么这个结构体大小是多少呢?
很明显,double自身对齐数是8,默认对齐数也是8,那double的对齐数就是8,所以double应该对齐8的整数倍的内存偏移量,那只能是对齐16了,这个结构体所有对齐数中最大的就变成了8,那么结构体大小就应该是8的整数倍,16偏移量放下一个8字节的double就变成了24个字节,刚好是8的整数倍,所以这个结构体大小就是24字节。
int main()
{
struct S1
{
char c1;//自身对齐数是1,默认对齐数是8,对齐数就取较小值1
int i;//自身对齐数是4,默认对齐数是8,对齐数就取较小值4
char c2;//自身对齐数是1,默认对齐数是8,对齐数就取较小值1
double d;//自身对齐数是8,默认对齐数是8,对齐数就取较小值1
};
printf("结构体S1的大小=%d\n", sizeof(struct S1));
return 0;
}
嵌套的结构体需要对齐自己最大对齐数的整数倍,接下来就是结构体的嵌套计算大小。
int main()
{
struct S1
{
int d;
char c;
double i;
};
struct S2
{
char c1;
struct S1 s1;
double d;
};
printf("%d\n", sizeof(struct S2));
}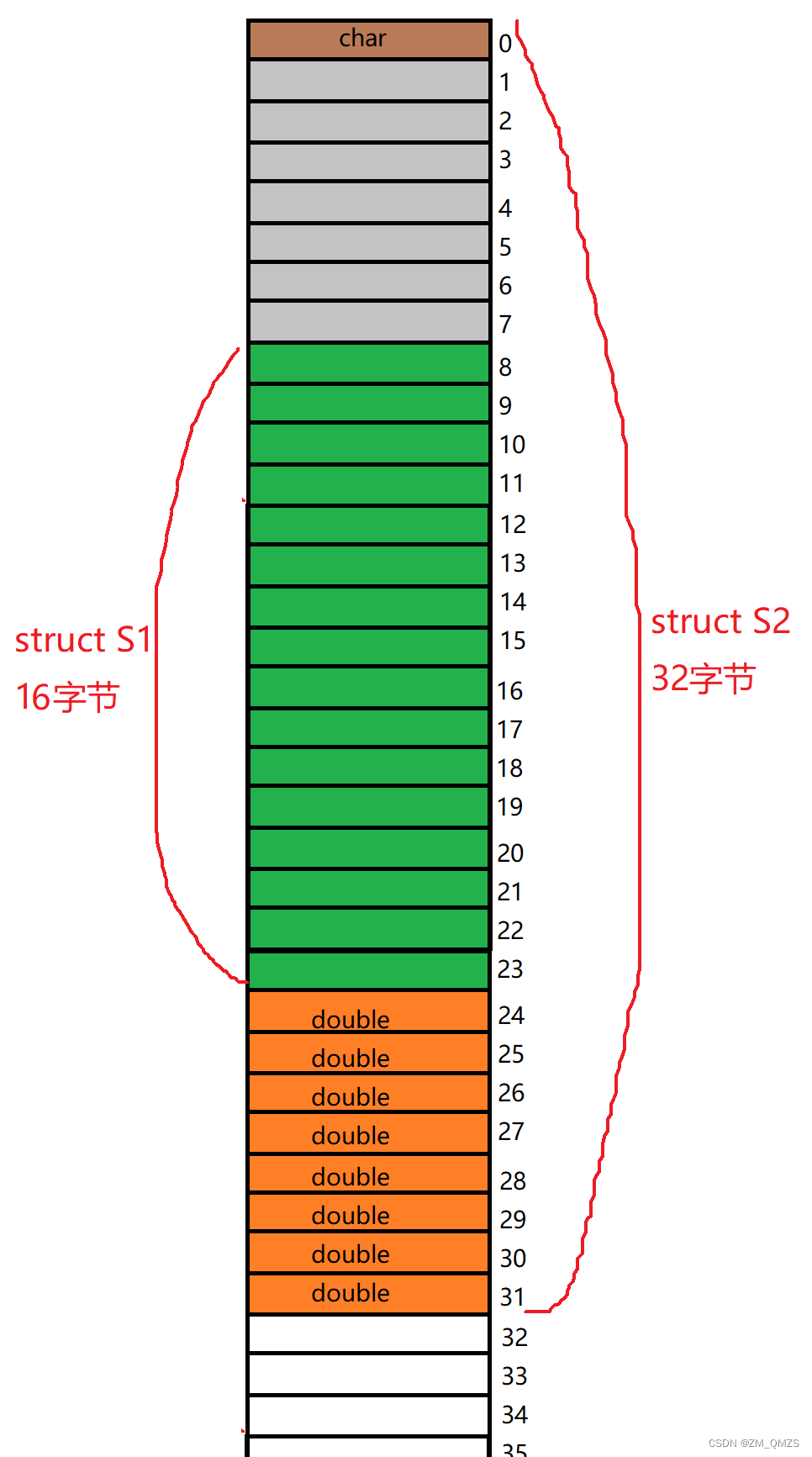
嵌套的结构体要对齐自己最大对齐数的整数倍,steuct S1的最大对齐数是8,所以要对齐8的整数倍。整个结构体的大小是最大对齐数的整数倍(包括嵌套结构体的),所以struct S2的大小是32字节。
内存对齐的优点:
1.不是所有平台的硬件都能访问内存里任意地址的数据,某些硬件平台只能在特定的地址处取特定类型的数据,否则会出错。
2.数据结构应尽可能在自然边界上对齐,对于未对齐的内存,处理器需要做两次访问,而对齐的内存访问只需一次。(CPU一次读取4个字节)
所以这是一种用空间换时间的做法。
TIPS:使用#pragma pack()可以更改最大对齐数。
结构体传参时应传地址而不是结构体变量名,这样不会创建一份结构体临时变量,节省内存空间。
位段是指定结构体成员所占的比特位数。
struct A
{
int a:2;//指定a只能使用2个比特位
int b:5;//指定b只能使用5个比特位
int c:10;//指定c只能使用10个比特位
};
这里指定的比特位大小不能超过其类型的大小,int是4个字节,一个字节是8个比特位,所以指定结构体成员所占的比特位不能超过32。位段可以节省内存空间,在网络通信这方面有比较大的用处。
位段在内存中的存储没有标准定义,不同的编译器可能有所不同,这里仅介绍VS2022的存储方式。

在int类型中,如果下一个位段成员较大,一个字节中剩余的比特位不足以存放时,如果是int类型就会利用剩余的比特位,并使用下一个字节直到存放完这个位段成员。如果是char类型就会舍弃剩余的比特位直接使用下一个字节的空间。
位段存在跨平台的问题,因为位段在内存中的存储没有标准定义,不同编译器对于从内存中读取位段成员和存放位段成员的方式也不同,所以同一个代码在不同的平台上运行的结果就会不同。
枚举就是把可能出现的值一一列举出来,比如生活中的性别只有男,女和未知,一个星期只有星期一到星期天等等,这个叫做枚举变量。
enum Sex//枚举使用enum 后面是创建的类型名
{
MALE,//MALE的值为0
//枚举成员后面用的是,而不是; 第一个成员默认值为0,后面依次递增1
FEMALE,//FEMALE的值为1
SECRET//SECRET的值为2
};当然也可以给成员赋值。
enum Sex
{
MALE=5,//MALE的值为5
FEMALE=15,//FEMALE的值为15
SECRET//SECRET的值为16
};枚举类型变量的创建与初始化。
enum Sex
{
MALE,
FEMALE,
SECRET
}S1=SECRET;//枚举也可以像结构体一样创建变量和初始化
int main()
{
enum Sex S2 = MALE;//定义了枚举变量S2,并赋值MALE(0)
printf("S1大小=%d S2大小=%d", sizeof(S1), sizeof(S2));//输出枚举变量大小(不是值)
return 0;
}
这里可以推测枚举变量大小是4个字节。
枚举可以用于switch语句。
enum Sex
{
MALE,//枚举成员后面用的是,而不是; 第一个成员默认值为0,后面依次递增1
FEMALE,
SECRET
};
int main()
{
int input;
printf("请输入0,1,2表示你的性别是男或女或未知\n");
scanf("%d", &input);
switch (input)
{
case MALE:
printf("男\n");
break;
case FEMALE:
printf("女\n");
break;
case SECRET:
printf("未知\n");
}
return 0;
} 枚举和#define定义的常量有什么不同呢?
枚举和#define定义的常量有什么不同呢?
1.使用方便,一次可以定义多个变量。
2.便于调试,#define定义的常量在预编译时是直接替换成对应的值,而枚举变量是可以通过监视观察到的。
3.相比于#define定义的标识符有类型检查,更加严谨。#define是直接替换文本,不存在类型检查,相对来说不安全。
4.增加代码可读性,在上面的switch语句中可以方便看出每个case分支的功能是什么。
联合体的成员共用一块内存空间,但联合体的大小是取决于最大的那个成员,并且存在内存对齐(是最大对齐数的整数倍)。
union B//联合体关键字是union 后面加上类型名
{
char c;
int i;
}B1;
int main()
{
printf("%p\n", &B1);//输出联合体变量B1的地址和成员c和i的地址
printf("%p\n", &B1.c);
printf("%p\n", &B1.i);
return 0;
}
这可以证明联合体的成员共同占用一个空间。访问不同的成员就是访问不同的字节,比如访问char就是访问第一个字节,访问int就是访问前4个字节。
这个联合体成员的对齐数最大是4,最大的成员也是4,是4的整数倍,所以这个联合体的大小就是4个字节。
union B//联合体关键字是union 后面加上类型名
{
char c[5];//char数组,大小是5个字节
int i;
}B1;
int main()
{
printf("%d\n", sizeof(B1));
return 0;
}
这里最大的成员是char数组,占了5个字节,但是联合体大小要对齐最大对齐数,最大对齐数是int(char的对齐数是1),是4,所以联合体的大小应该是4的整数倍,也就是8个字节。
以上就是自定义类型(结构体,位段,枚举,联合体)的全部内容,如有错误还请指出。

我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>