作者简介:郑建林,现任深圳市技研智联科技有限公司架构师,技术负责人。多年物联网及金融行业经验,对云计算、区块链、大数据等领域有较深入研究及应用。现主要从事 PaaS 平台建设,为公司各业务产品线提供平台底座如技术中台,数据中台,业务中台等。
深圳市技研智联科技有限公司:为佛山技研智联科技有限公司子公司,前者为三技精密和研华合资公司。提供从工控设备,网关,云平台一体化的专业印染数字化工业互联网平台。
佛山技研智联科技有限公司(以下简称“技研智联”)是由三技精密技术(广东)股份有限公司以及研华科技股份有限公司于 2020 年 8 月合资成立,是一家专注于为纺织企业提供自动化控制系统软件、工业互联网应用平台、数字化转型与智能制造整体解决方案,并为企业提供行业软件咨询、实施、集成等服务的高新技术企业,专精特新中小企业。
公司发展至今已经是 100 多人规模专业技术产品团队,自主研发的 iTEX 智慧纺织云平台,目前已经连接 70 多家工厂,2000 多台设备,能够把工厂各个系统、各类跨业务的数据在同一个平台上打通,让企业实现基于数据和流程的业务协同。
公司较早就开始拥抱云原生容器化部署,支持客户在公有云 iTEX 云平台使用 SaaS 产品,同时支持用户按私有云方式私有化部署安装使用。目前 IT 和运维团队规模 5 人,主要满足自身研发上云和客户安装部署运维需求。
本人为深圳市技研智联科技有限公司架构师和技术负责人,负责整个公司基础平台搭建设计,所在团队为整个公司产品业务提供基础 PaaS 平台,包括技术中台,数据中台,业务中台等。原先业务团队主要做 SaaS 云平台和边缘控制相关产品。使用超融合服务器上分割部署 K8s 集群,通过 Rancher 来管理服务器集群。DevOps 用的 git 支持的脚步打 Docker 镜像方式,手动发布服务。存在服务器资源不足,扩展性欠缺,运维管理不便,技术框架差异等问题,随着业务发展需要底层资源管理,技术框架,公共服务统一服务化迫在眉睫。
作为公司基础服务平台团队,需要提供统一易用的容器服务发布部署管理一站式平台,期间对比了 Openshift,Rancher,KubeSphere 这几大开源 PaaS 容器管理平台,对比特点如下(希望尽量客观,各个平台组件不断发展,若有失正确望见谅):
表 1 开源 PaaS 容器管理平台对比
| 开源 PaaS | Rancher | Openshift | KubeSphere |
|---|---|---|---|
| 开发团队 | Rancher | 红帽 | 青云科技 |
| 容器平台 | 好 | 好 | 好 |
| 监控 | 好 | 好 | 好 |
| devops | 一般 | 一般 | 好 |
| 多集群支持 | 好 | 一般 | 良好 |
| 应用市场支持 | 无 | Operator | Helm |
| 多租户 | 支持一般 | 支持一般 | 支持良好 |
| 交互 | 良好 | 良好 | 好 |
| 安装 | 轻 | 重 | 重 |
一方面 KubeSphere 优秀的交互体验一下击中了研发人员的心理,同时本着融合产品模块化开发的初衷,最终选择了 KubeSphere,希望能提高交互效果,另外期望可以提升整体产品底层设施稳定性和开发效率。
K8s 集群基于腾讯云服务器 centos7.9 系统采用三个 Master 节点高可用集群多个 Worker 节点方案搭建,使用稳定 K8s v1.23.5 版本。分为开发,测试,预发布和生产四个私有网络 K8s 集群。
网络采用 Calico CNI。相比 Flannel,Calico 网络插件具有如下优势:
集群网络为腾讯云 VPC 私有网络外网不可访问,对外采用负载均衡统一接入经过 APISIX 流量网关后再到业务网关处理。服务之间都是内网通过 K8s 虚拟网络解析服务名访问。
出于成本考虑,存储主要采用腾讯云 CBS 云硬盘存储,通过 NFS 挂载到 PV 中供服务绑定 PVC 使用。对性能要求高的也可以使用腾讯云上提供的其他高性能存储服务。
在使用 KubeSphere 之前公司公有云服务都部署在超融合服务器环境,使用 GitLab 的 CI 能力,在 Rancher 上发布服务。开发测试环境开发人员进行代码编译打包然后发布,生产环境开发人员打 tag 推送镜像,然后统一由运维人员使用 Rancher 进行发布部署。CI/CD 流程架构图如下:
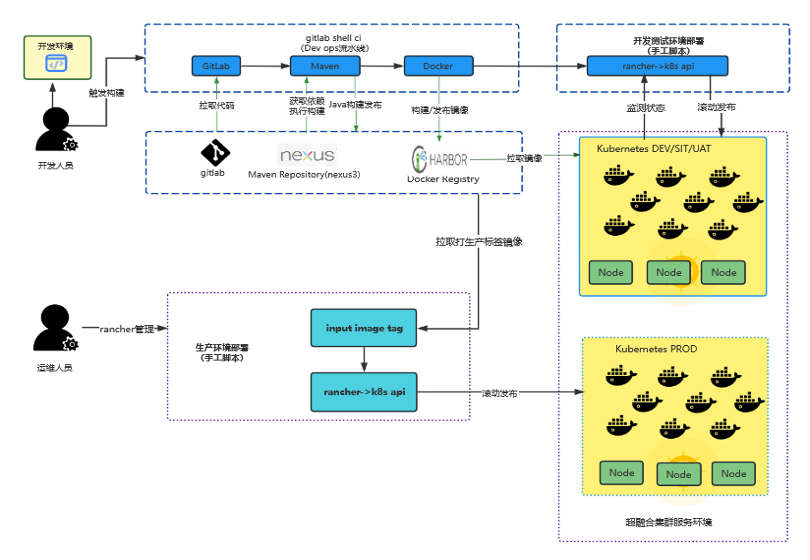
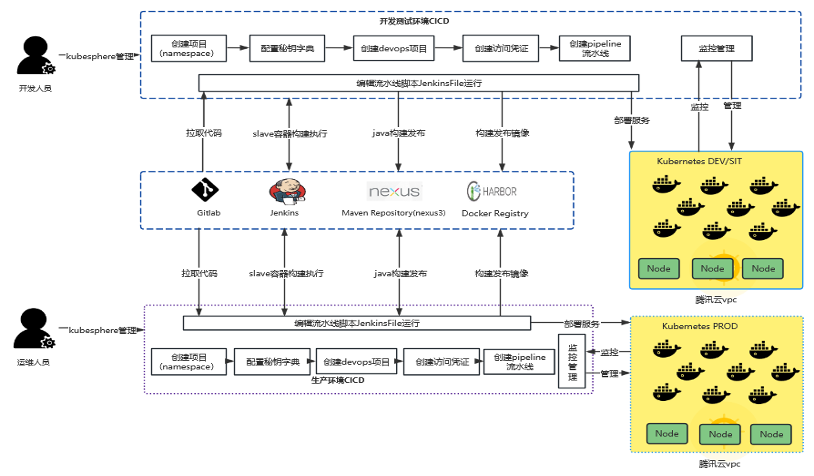
改用 KubeSphere 后开发人员集成发布在 KubeSphere DevOps 项目里完成整个流程的编辑运行查看等操作。基于 Jenkins 脚本编排流水线,生产环境由运维人员进行 DevOps 项目授权操作。操作起来更流畅,能实现更复杂的流水线编排,但 Jenkins 容器镜像相对较大会吃资源一点。基于 KubepShere CI/CD 流程架构图如下:
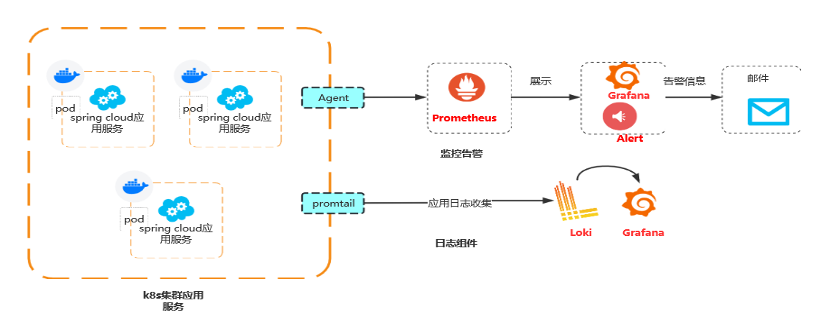
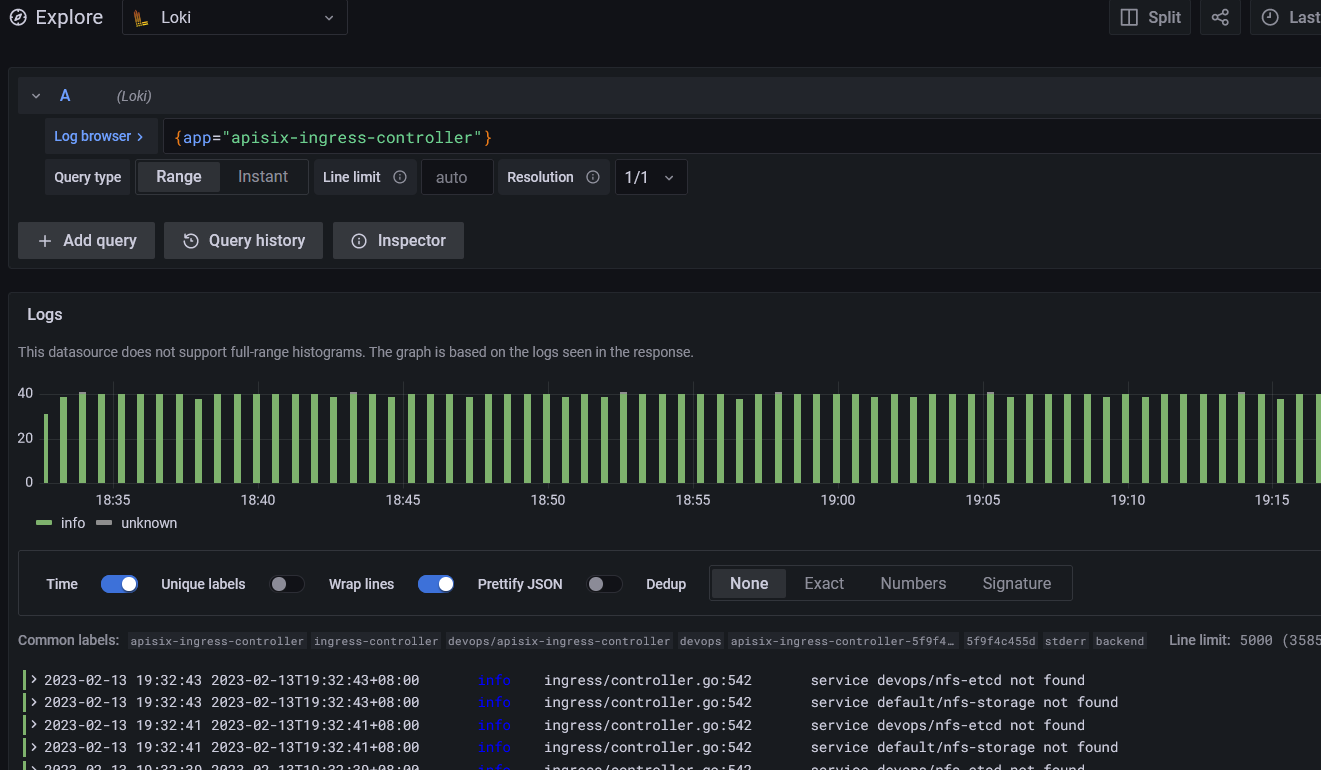
日志监控采用更为轻量的 Loki 系统组件来采集处理,并用 Grafana 进行可视化展示,监控使用 Prometheus,同样使用 Grafana 来展示。
各个应用普遍存在自己的账号角色体系,管理起来会比较繁琐,因此打通产品应用账号和 KubepShere 账号体系能极大提高配置使用体验,幸好 KubepShere 提供了 oauth 授权接口模板,只需要按照例子配置 url 及 client_id,写好回调处理接口即可打通账号授权登录。授权登录架构图如下:
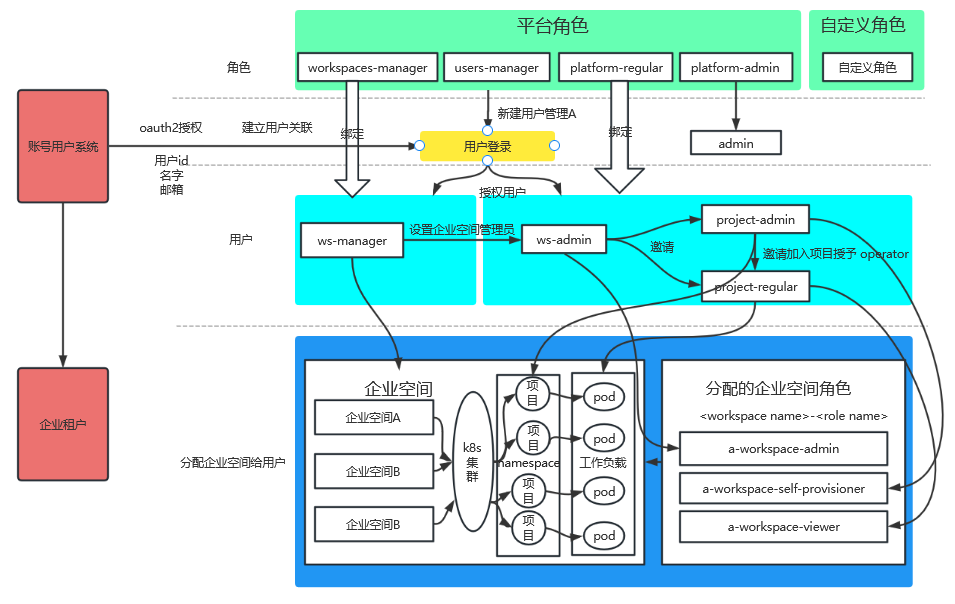
打通应用系统账号跟 KubepShere 账号授权后,用户及权限管理更容易便捷,KubeSphere 集成效果如下图:

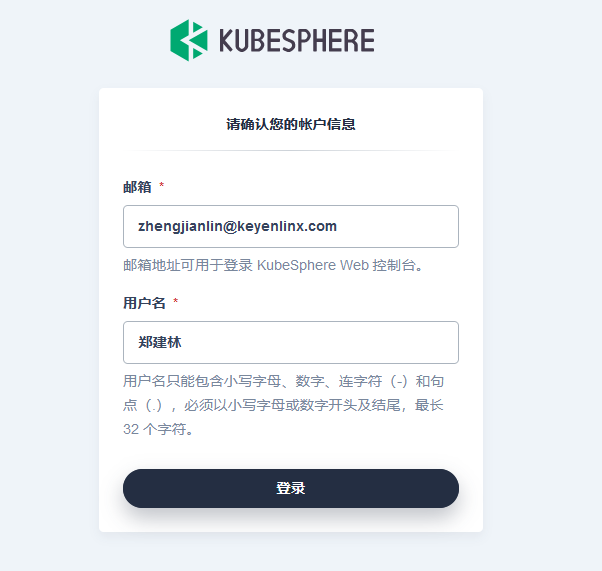
初次登录 KubeSphere 授权个人信息即可,后续登录无需重复授权操作。目前不足之处是企业租户和角色没有和我们平台应用打通,需要各自配置。授权信息需要账号 ID,账号名字以及邮箱等。第一次授权确认账号信息如下图所示:
应用服务发布部署功能更全面,方便统一管理控制。
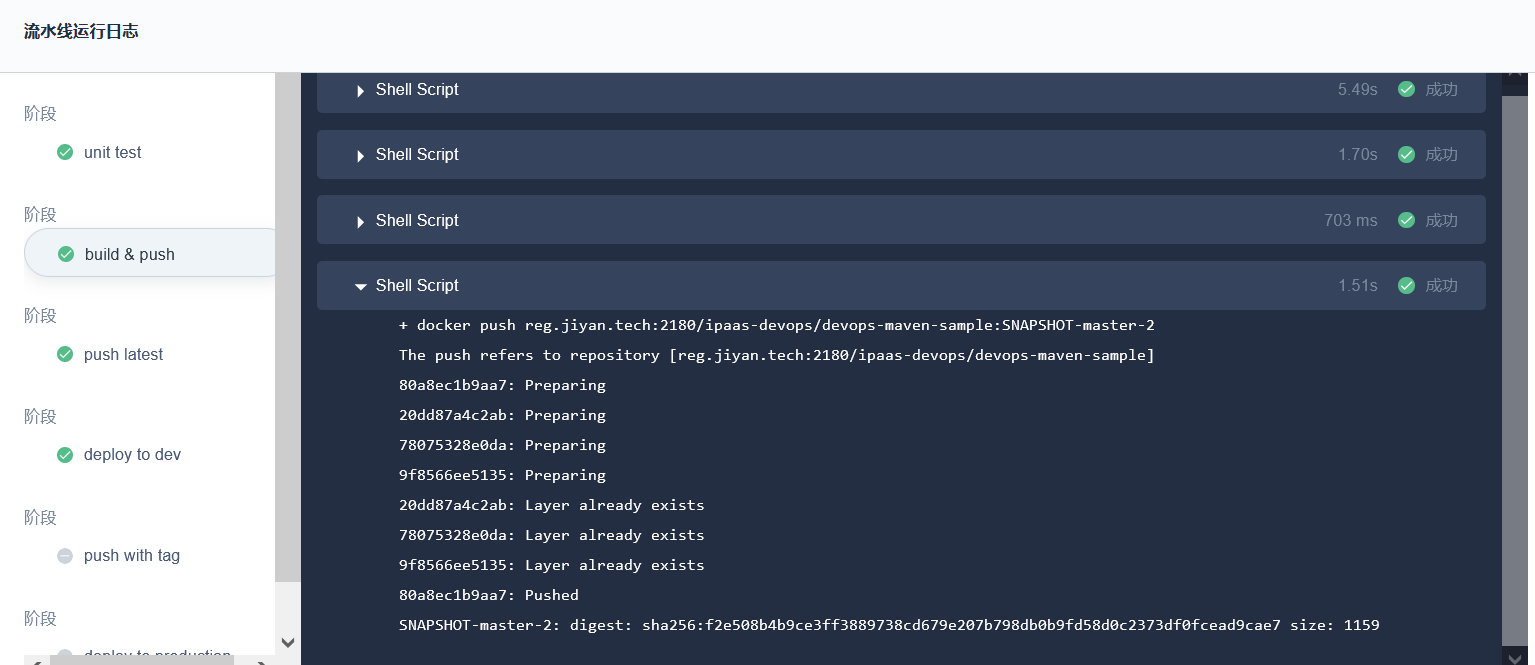
在使用过程中也出现过偶尔卡住需要取消重新运行情况,多个流水线同时运行需要较长时间排队问题,后续运行效率这块希望能够优化。
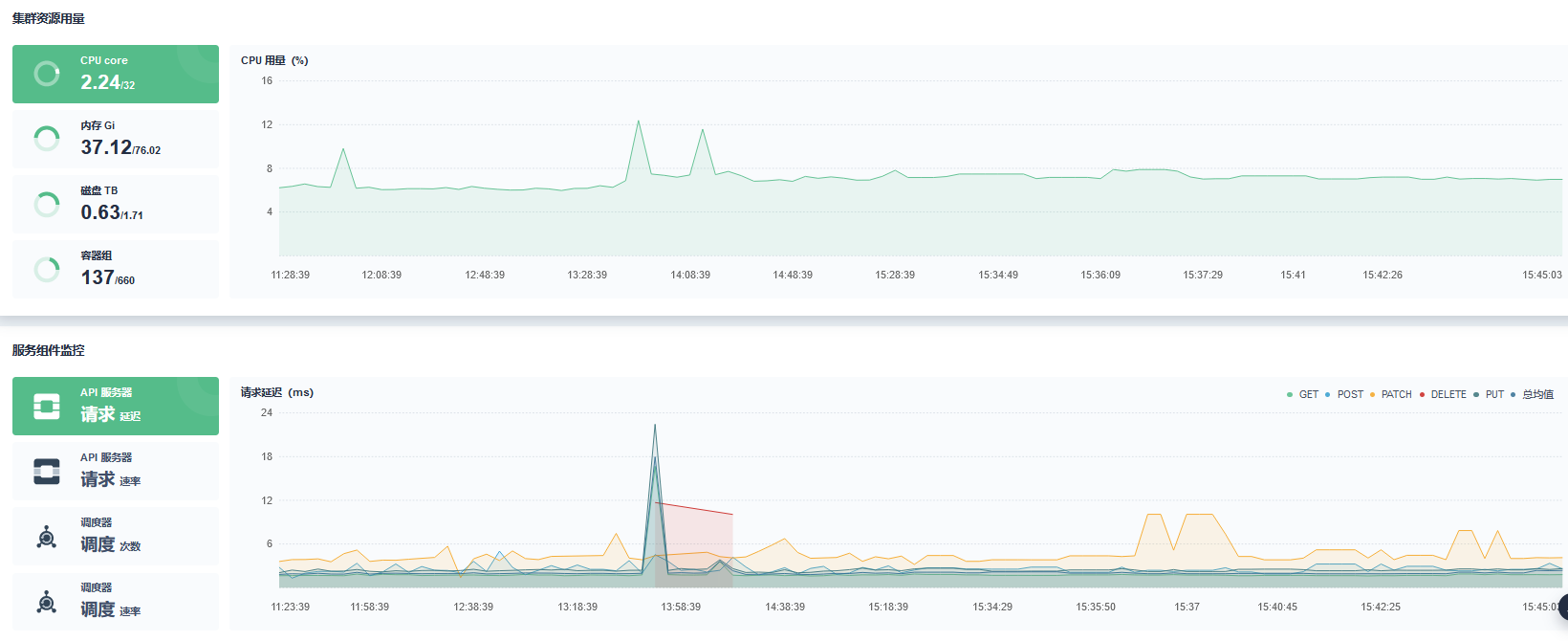
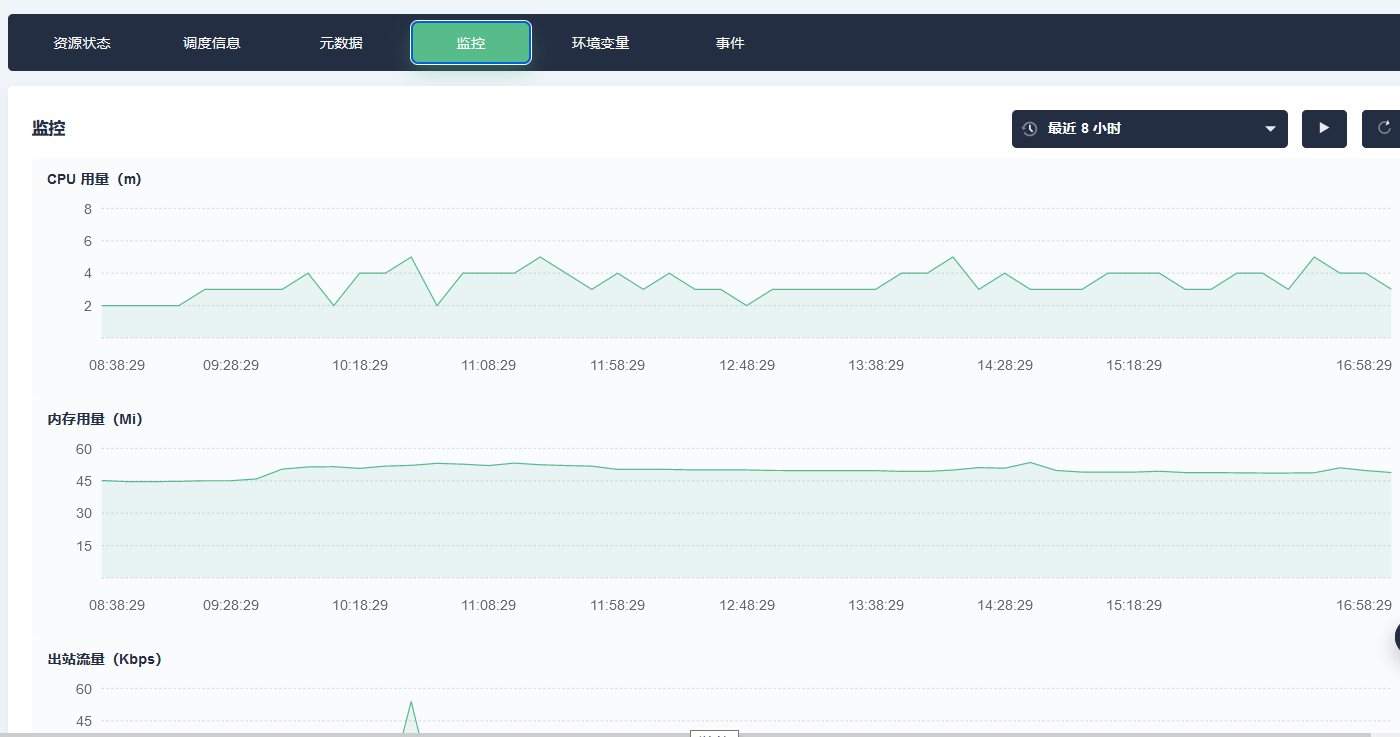
KubeSphere 监控提供了 Prometheus 监控套件,对服务器资源及使用情况能实时监控同时可以查询历史变化,极大方便了系统维护管理,提前发现系统资源瓶颈进行处理,提高稳定性。服务器集群监控如下图所示:
KubeSphere 同时支持对单个服务的性能和资源使用进行监控,这是原先使用 Rancher 没有体验过的,对评估整体服务部署资源性能占用有了很好计算参考和优化方向。服务监控如下图所示:
去年六月底 KubeShere 3.3.0 版本发布后第一时间安装尝鲜,一开始全功能安装 KubeSphere,core,Prometheus,Istio,DevOps,monitor,APP 应用商店等各个组件。发现整个一套部署下去会很重,同时当前阶段有些组件还不太用得上,于是在部署安装配置文件里对一些模块(如 Istio,APP 商店)设置为 false 不安装即可。
PaaS 容器管理监控等基础设施作为企业产品服务的重要底座,稳定性,易用性,可适配性也是我们不断追求的目标,因此计划后续结合 KubeSphere 强大的容器管理平台能力进行自身产品需求服务管理进行融合,几个重要方向如下:
本文由博客一文多发平台 OpenWrite 发布!
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
参见下面的示例,我想最好使用第二种方法,但第一种也可以。哪种方法最好,使用另一种的后果是什么?classTestdefstartp"started"endtest=Test.newtest.startendclassTest2defstartp"started"endendtest2=Test2.newtest2.start 最佳答案 我肯定会说第二种变体更有意义。第一个不会导致错误,但对象实例化完全过时且毫无意义。外部变量在类的范围内不可见:var="string"classAvar=A.newendputsvar#=>strin
如果我构建了一个应用程序来访问来自Gmail、Twitter和Facebook的一些数据,并且我希望用户只需输入一次他们的身份验证信息,并且在几天或几周后重置,那会怎样是在Ruby中动态执行此操作的最佳方法吗?我看到很多人只是拥有他们客户/用户凭证的配置文件,如下所示:gmail_account:username:myClientpassword:myClientsPassword这看起来a)非常不安全,b)如果我想为成千上万的用户存储此类信息,它就无法工作。推荐的方法是什么?我希望能够在这些服务之上构建一个界面,因此每次用户进行交易时都必须输入凭据是不可行的。
目录SpringBootStarter是什么?以前传统的做法使用SpringBootStarter之后starter的理念:starter的实现: 创建SpringBootStarter步骤在idea新建一个starter项目、直接执行下一步即可生成项目。 在xml中加入如下配置文件:创建proterties类来保存配置信息创建业务类:创建AutoConfiguration测试如下:SpringBootStarter是什么? SpringBootStarter是在SpringBoot组件中被提出来的一种概念、简化了很多烦琐的配置、通过引入各种SpringBootStarter包可以快速搭建出一
我正在使用Devise在Rails应用程序中,并希望通过API公开一些模型数据,但应该像应用程序一样限制对API的访问。$curlhttp://myapp.com/api/v1/sales/7.json{"error":"Youneedtosigninorsignupbeforecontinuing."}很明显。在这种情况下是否有访问API的最佳实践?我更喜欢一步验证+获取数据,但这只是为了让客户的工作更轻松。他们将使用JQuery在客户端提取数据。感谢您提供任何信息!凡妮莎 最佳答案 我建议您按照以下帖子中的选项2:使用APIke
我正在开发一个Rails2.3.1网站。在整个网站中,我需要一个用于在各种页面(主页、创建帖子页面、帖子列表页面、评论列表页面等)上创建帖子的表单——只要说这个表单需要在由各种Controller)。这些页面中的每一个都显示在相应的Controller/操作中检索到的各种其他信息。例如,主页列出了最新的10篇文章、从数据库中提取的内容等。因此,我已将帖子创建表单移动到它自己的部分中,并将该部分包含在所有必要的页面中。请注意,部分POST中的表单到/questions(路由到PostsController::create——这是默认的Rails行为)。我遇到的问题是当Posts表单没有正
我正在按照我一直在研究的研讨会实现“服务对象”,我正在构建一个redditAPI应用程序。我需要对象返回一些东西,所以我不能只执行初始化程序中的所有内容。我有这两个选择:选项1:类需要实例化classSubListFromUserdefuser_subscribed_subs(client)@client=client@subreddits=sort_subs_by_name(user_subs_from_reddit)endprivatedefsort_subs_by_name(subreddits)subreddits.sort_by{|sr|sr[:name].downcase}