前言:
大家好,我是良辰丫,今天我将与大家一起学习文件操作的相关操作,跟随我的步伐,一起往下看!💞💞💞
🧑个人主页:良辰针不戳
📖所属专栏:javaEE初阶
🍎励志语句:生活也许会让我们遍体鳞伤,但最终这些伤口会成为我们一辈子的财富。
💦期待大家三连,关注,点赞,收藏。
💌作者能力有限,可能也会出错,欢迎大家指正。
💞愿与君为伴,共探Java汪洋大海。

目录
文件: 这个概念想必我们并不陌生,电脑上的文件,手机上的文件,一个文件夹,或者一个文本文件,再或者一个word文件等都可以看做一个文件.- 咱们日程谈到的文件,其实是硬盘上的文件.
看到这里,咱们回忆一下
硬盘(外存)与内存的区别
- 速度:内存比硬盘快得多.
- 空间:内存比硬盘小.
- 成本:内存比硬盘贵.
- 持久化:内存断电后数据消失,外存(硬盘)断电后数据还在.
咱们写一个简单的代码,定义一个变量,其实就是在内存上申请空间;但是数据库中数据一般是保存在硬盘上的.
- IO是文件的一种操作,大多数都表示输入输出流在
操作硬盘的一种操作.- 文件输入输出流的概括,为什么叫流呢?大家可以想象一下水流,从一头流向另一头,文件流和水流有点相似,大家可以稍作理解.
咱们之前学过二叉树,文件的结构组织相当于一种 N叉树结构.简单的截图看一下我的一个目录结构.
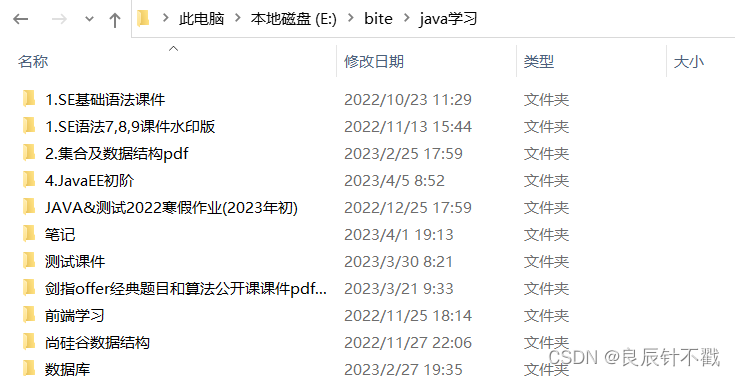
所谓路径: 描述某个文件所在的位置.路径可以说是一个文件的身份标识.windows系统中路径是唯一的,但是在Linux系统中路径可能不同.
绝对路径: 从盘符开始,到某个文件的路径.(下面我们会用代码来描述)
下面是一个绝对路径
E:\bite\java学习\4.JavaEE初阶\4.JavaEE初阶
所谓
相对路径,是相对于某个位置开始,到你要找的那个文件.
下面是一个相对路径,其中点表示当前路径,也就是相对于java学习这个路径
.\4.JavaEE初阶\4.JavaEE初阶.
普通文件也会根据其保存数据的不同,也经常被分为不同的类型,我们一般简单的划分为文本文件和二进制文件,分别指代保存被字符集编码的文本和按照标准格式保存的非被字符集编码过的文件。
- 我们肉眼可以看懂的文件(帮助大家理解,并不能这样说)
- 文本文件存储的是文本,文本文件的内容都是由ASCII字符组成的.
- 其实,计算机只能识别二进制文件,文本文件是计算机进行翻译,帮助我们理解的.

- 计算机进行识别的文件,我们单纯通过肉眼不理解文件内容.
- 我们如何识别文本文件和二进制文件呢?一种简单的办法是用记事本打开某个文件,我们能理解就是文本文件,理解不了的就是二进制文件.
- 二进制就是一个个的字节,记事本尝试把若干个字节的数据往utf8码表里替换,替换出来啥就是啥,替换不出来的就是方块.
- 我们电脑上建立的快捷方式相当于是真实文件的一个引用,和我们java里面的引用很相似.
有File对象,并不代表对象真实存在,File对象是硬盘上的一个文件的抽象表示.
- 文件是存储在硬盘上的,直接通过代码操作硬盘,不太方便.
- 在内存中创建一个对应的对象,操作这个内存中的对象,就可以间接影响到硬盘的文件情况了.
构造File对象的过程中,可以使用绝对路径/相对路径进行初始化,这个路径指向的文件,可以存在,也可以不存在.
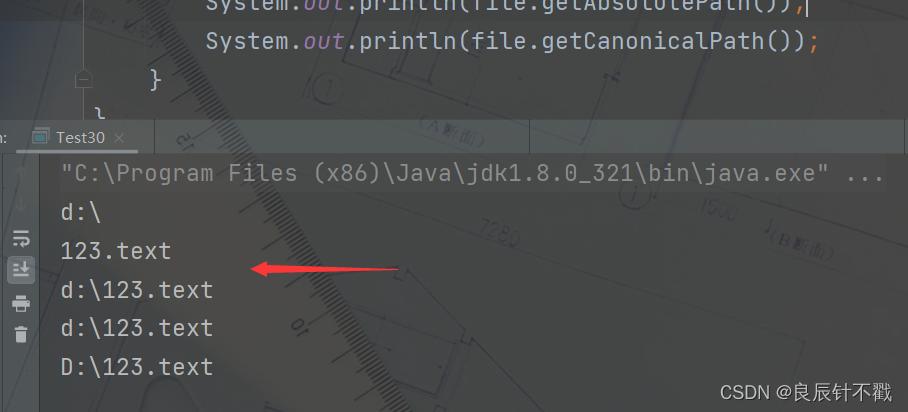
public static void main(String[] args) throws IOException{
//File创建的文件并不一定真实存在
File file = new File("d:/123.text");
//获取父目录
System.out.println(file.getParent());
//获取自己文件名
System.out.println(file.getName());
//获取路径
System.out.println(file.getPath());
//获取绝对路径(下面是两种获取绝对路径的方式,暂时不用区分)
System.out.println(file.getAbsolutePath());
System.out.println(file.getCanonicalPath());
}
public static void main(String[] args) throws IOException {
// 在相对路径中, ./ 通常可以省略
File file = new File("d:/123.txt");
//判断文件是否存在
System.out.println(file.exists());
System.out.println(file.isDirectory());
//判断是否为普通文件
System.out.println(file.isFile());
// 创建文件
file.createNewFile();
System.out.println(file.exists());
System.out.println(file.isDirectory());
System.out.println(file.isFile());
file.delete();
System.out.println("删除文件之后");
System.out.println(file.exists());
}
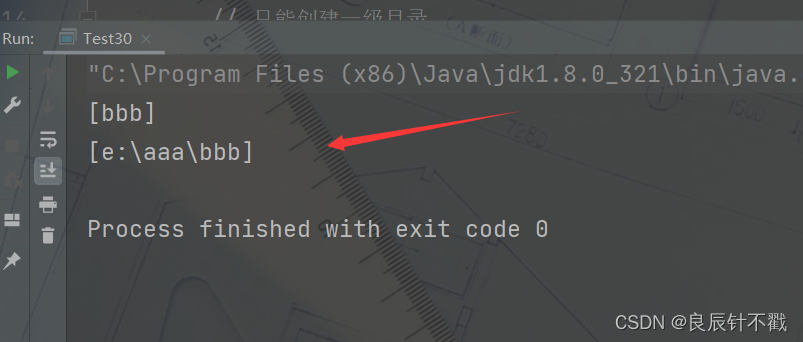
public static void main(String[] args) {
File file = new File("e:/aaa/bbb");
// 只能创建一级目录
// file.mkdir();
// 创建多级目录,注意mkdirs为复数
file.mkdirs();
}
public static void main(String[] args) throws IOException {
File file = new File("e:/aaa");
String[] results = file.list();
System.out.println(Arrays.toString(results));
File[] results2 = file.listFiles();
System.out.println(Arrays.toString(results2));
}
public static void main(String[] args) {
// 重命名
File src = new File("e:/aaa");
File dest = new File("e:/fff");
src.renameTo(dest);
}
下面有许多File方法,咱们没有必要可以去记,只需要记忆一些常见的,然后需要用的时候我们去查就可以了.(常见的我会用代码展示)
| 返回类型 | 方法名 | 说明 |
|---|---|---|
| String | getParent() | 返回 File 对象的父目录文件路径 |
| String | getName() | 返回 FIle 对象的纯文件名称 |
| String | getPath() | 返回 File 对象的文件路径 |
| String | getAbsolutePath() | 返回 File 对象的绝对路径 |
| String | getCanonicalPath() | 返回 File 对象的修饰过的绝对路径 |
| boolean | exists() | 判断 File 对象描述的文件是否真实存在 |
| boolean | isDirectory() | 判断 File 对象代表的文件是否是一个目录 |
| boolean | isFile() | 判断 File 对象代表的文件是否是一个普通文件 |
| boolean | createNewFile() | 根据 File 对象,自动创建一个空文件。成功创建后返会true |
| boolean | delete() | 根据 File 对象,删除该文件。成功删除后返回 true |
| void | deleteOnExit() | 根据File对象标注文件将被删除 |
| String[] | list() | 返回File对象代表的目录下的所有文件名 |
| File[] | listFiles() | 返回File对象代表的目录的所有文件,以File表示 |
| boolean | mkdir() | 创建File对象代表的目录 |
| boolean | mkdirs() | 创建File对象代表的目录,如果必要会创建中间目录 |
| boolean | renameTo(File dest) | 进行文件改名 |
| boolean | canRead | 判断用户是否有可读权限 |
| boolean | canWrite | 判断用户是否有可写权限 |
| void | flush() | 我们知道 I/O 的速度是很慢的,所以,大多的 OutputStream 为了减少设备操作的次数,在写数据的时候都会将数据先暂时写入内存的一个指定区域里,直到该区域满了或者其他指定条件时才真正将数据写入设备中,这个区域一般称为缓冲区。但造成一个结果,就是我们写的数据,很可能会遗留一部分在缓冲区中。需要在最后或者合适的位置,调用 flush(刷新)操作,将数据刷到设备中。 |
- 根据文本文件,提供了一组类,统称为"字符流",典型代表为Reader,Writer,读写的基本单位是字符.
- 二进制文件,提供了一组类,统称为"字节流",典型代表为InputStream,OutputStream,读写的基本单位是字节.
- 流对象又分为输入流和输出流.
InputStream用来进行IO操作,不仅仅可以读写硬盘文件,还可以读写别的(后面的网络编程经常用.)
注意:
文件的关闭操作非常重要
inputStream.close()
那么问题来了,咱们java不是有gc垃圾处理机制嘛?为什么还需要手动释放资源呢?
- java中内存中的文件一般不需要手动释放,但是这里的文件(硬盘)的资源是需要手动释放的,咱们这里的文件主要是文件描述符.
- 进程是使用PCB这样的结构来表示:pid,内存指针,文件描述符.
文件描述符记录了当前进程打开了哪些文件,每次打开一个文件,都会在这个表里,申请一个位置,这个表可以当成一个数组,数组下标就是文件描述符,数组元素就是这个文件在内核中的结构体的表示.但是这个表的长度是有限制的,不能无休止的打开不进行释放,一旦满了,继续打开,就会打开失败,可能会导致文件资源泄露,内存泄露,甚至会有更严重的问题.
下面我写了两种close的方式.
- 注释掉的代码拥有close操作,但是显得代码并不美观.
- 我们需要了解的是==带有资源的try操作,会在代码块结束的时候,自动执行close关闭操作.因为InputStream实现了Closeable类.==这就是我们没有加注释的写法,是不是更加美观了呢?
public static void main(String[] args) throws IOException {
// 这个过程, 相当于 C 中的 fopen , 文件的打开操作~~
// InputStream inputStream = null;
// try {
// inputStream = new FileInputStream("e:/hello.txt");
// } finally {
// inputStream.close();
// }
try (InputStream inputStream = new FileInputStream("e:/hello.txt")) {
// 读文件
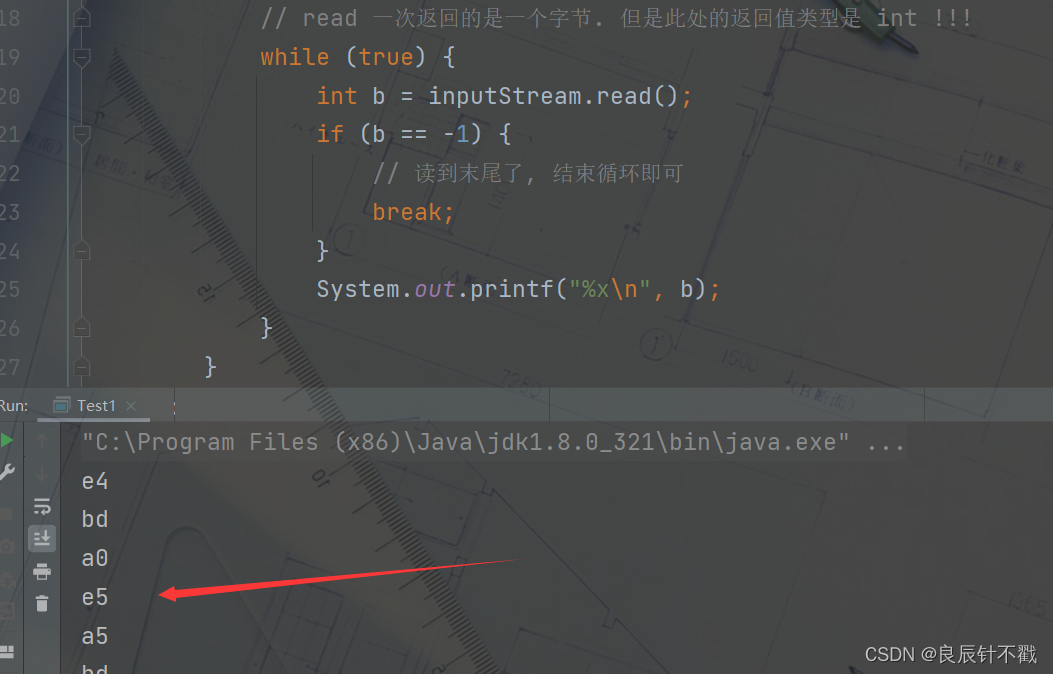
// read 一次返回的是一个字节. 但是此处的返回值类型是 int !!!
while (true) {
int b = inputStream.read();
if (b == -1) {
// 读到末尾了, 结束循环即可
break;
}
System.out.printf("%x\n", b);
}
}
}
- 如果文件读取完毕,read就会返回-1.
- 此处使用的是字节流,每次读取的不是字符,而是字节,读出的这一串数据,就是每个字符的ASCII码.
- read 和 write还可以一次读写多个字节,使用byte[]来表示.
- read会尽可能把byte[]填满,读到末尾,返回-1.
- write会把byte[]所有数据写入文件中.
下面是把字节流数据写入到文件中,但是咱们写入的数据是字节流,也能叫做二进制文件,咱们用肉眼看不懂.
public static void main(String[] args) {
try (OutputStream outputStream = new FileOutputStream("e:/hello.txt")) {
outputStream.write(1);
outputStream.write(2);
outputStream.write(3);
} catch (IOException e) {
e.printStackTrace();
}
}
字符流: 按照字符为单位进行读写文件.
- Reader,FileReader,Writer,FileWriter
- 构造方法打开文件,close进行关闭.
- read方法来读,一次读一个char或者char[].
- write方法来写,一次写一个char或者char[]或者String.
public static void main(String[] args) {
try (Reader reader = new FileReader("e:/hello.txt")) {
while (true) {
int c = reader.read();
if (c == -1) {
break;
}
//int强制类型转换成char
char ch = (char)c;
System.out.print(ch);
}
} catch (IOException e) {
e.printStackTrace();
}
}
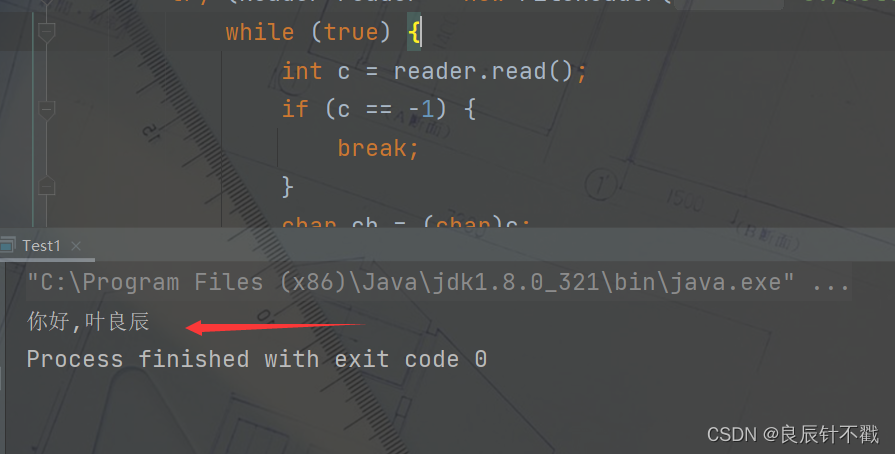
看上面的截图,咱们就可以非常清楚的看到文本内容,因为咱们读取的方式是字符流.字节流与字符流好多用法都相同,咱们就不一一展示了.
接下来咱们完成一个简单的文件操作案例,进行文件内容的查询操作.
- 简单进行递归遍历目录,把所有文件都列出来.
- 每次找到一个文件打开,读取里面的内容.
- 判断是否拥有要查找的关键词,如果存在,列出该文件夹.
咱们的循环采取foreach的方式,foreach不用判断条件,不用管是否越界,而且具有自动遍历的方式,非常好用.
package io;
import java.io.*;
import java.util.*;
public class Test02 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
// 1. 先让用户指定一个要搜索的根目录
System.out.println("请输入要扫描的根目录: ");
//当前目录下文件不存在
File rootDir = new File(scanner.next());
if (!rootDir.isDirectory()) {
System.out.println("输入有误, 您输入的目录不存在!");
return;
}
// 2. 让用户输入一个要查询的词.
System.out.println("请输入要查询的词: ");
String word = scanner.next();
// 3. 递归的进行目录/文件的遍历了
scanDir(rootDir, word);
}
private static void scanDir(File rootDir, String word) {
// 列出当前的 rootDir 中的内容. 没有内容, 直接递归结束
File[] files = rootDir.listFiles();
if (files == null) {
// 当前 rootDir 是一个空的目录, 这里啥都没有.
// 没必要往里递归了
//这是递归的结束条件
return;
}
// 目录里有内容, 就遍历目录中的每个元素
for (File f : files) {
System.out.println("当前搜索到: " + f.getAbsolutePath());
if (f.isFile()) {
// 是普通文件
// 打开文件, 读取内容, 比较看是否包含上述关键词
String content = readFile(f);
if (content.contains(word)) {
System.out.println(f.getAbsolutePath() + " 包含要查找的关键字!");
}
} else if (f.isDirectory()) {
// 是目录
// 进行递归操作
scanDir(f, word);
} else {
// 不是普通文件, 也不是目录文件, 直接跳过
continue;
}
}
}
//下面的方法的作用就是把文件内容遍历一次,然后提取出来.
private static String readFile(File f) {
// 读取文件的整个内容, 返回出来.
// 使用字符流来读取. 由于咱们匹配的是字符串, 此处只能按照字符流处理, 才是有意义的.
StringBuilder stringBuilder = new StringBuilder();
try (Reader reader = new FileReader(f)) {
// 一次读一个字符, 把读到的结果给拼装到 StringBuilder 中. 统一转成 String
while (true) {
int c = reader.read();
if (c == -1) {
break;
}
stringBuilder.append((char)c);
}
} catch (IOException e) {
e.printStackTrace();
}
return stringBuilder.toString();
}
}
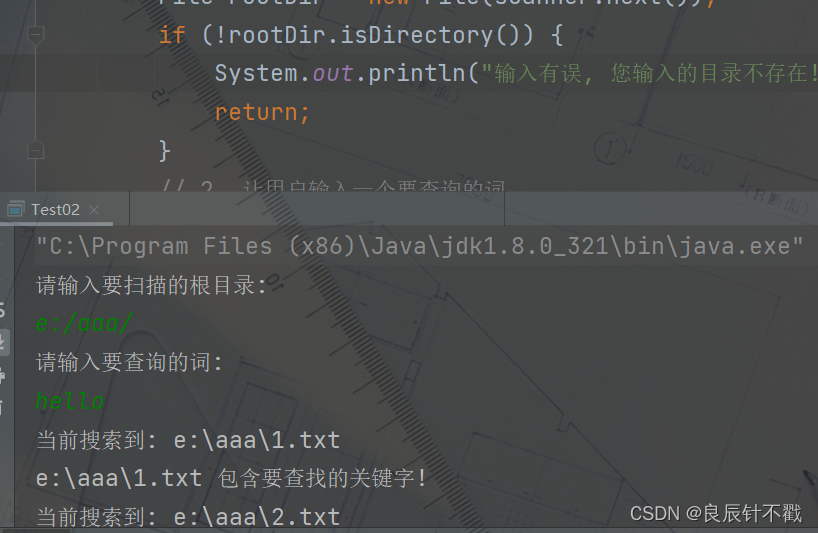
咱们写的只是一个普通的查找文件,当我们的路径范围比较大的时候,就可能查不到我们想要的结果.一般的项目中的查询需要用到一种倒排索引的数据结构,目前咱们不需要了解.
下面的文件删除与文件复制与文件查询的原理基本一样,大家可以去尝试一下.
package io;
import java.io.*;
import java.util.*;
public class Del {
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
System.out.print("请输入要扫描的根目录: ");
String rootDirPath = scanner.next();
File rootDir = new File(rootDirPath);
if (!rootDir.isDirectory()) {
System.out.println("您输入的根目录不存在或者不是目录,退出");
return;
}
System.out.print("请输入要找出的文件名中的字符: ");
String token = scanner.next();
List<File> result = new ArrayList<>();
// 因为文件系统是树形结构,所以我们使用深度优先遍历(递归)完成遍历
scanDir(rootDir, token, result);
System.out.println("共找到了符合条件的文件 " + result.size() + " 个,它们分别 是");
for (File file : result) {
System.out.println(file.getCanonicalPath() + " 请问您是否要删除该文件?y/n");
String in = scanner.next();
if (in.toLowerCase().equals("y")) {
file.delete();
}
}
}
private static void scanDir(File rootDir, String token, List<File> result) {
File[] files = rootDir.listFiles();
if (files == null || files.length == 0) {
return;
}
for (File file : files) {
if (file.isDirectory()) {
scanDir(file, token, result);
} else {
if (file.getName().contains(token)) {
result.add(file.getAbsoluteFile());
}
}
}
}
}
package io;
import java.io.*;
import java.util.*;
public class KaoBei {
public static void main(String[] args) throws IOException {
Scanner scanner = new Scanner(System.in);
System.out.print("请输入要复制的文件(绝对路径 OR 相对路径): ");
String sourcePath = scanner.next();
File sourceFile = new File(sourcePath);
if (!sourceFile.exists()) {
System.out.println("文件不存在,请确认路径是否正确");
return;
}
if (!sourceFile.isFile()) {
System.out.println("文件不是普通文件,请确认路径是否正确");
return;
}
System.out.print("请输入要复制到的目标路径(绝对路径 OR 相对路径): ");
String destPath = scanner.next();
File destFile = new File(destPath);
if (destFile.exists()) {
if (destFile.isDirectory()) {
System.out.println("目标路径已经存在,并且是一个目录,请确认路径是否正 确");
return;
}
if (destFile.isFile()) {
System.out.println("目录路径已经存在,是否要进行覆盖?y/n");
String ans = scanner.next();
if (!ans.toLowerCase().equals("y")) {
System.out.println("停止复制");
return;
}
}
}
try (InputStream is = new FileInputStream(sourceFile)) {
try (OutputStream os = new FileOutputStream(destFile)) {
byte[] buf = new byte[1024];
int len;
while (true) {
len = is.read(buf);
if (len == -1) {
break;
}
os.write(buf, 0, len);
}
os.flush();
}
}
System.out.println("复制已完成");
}
}
后序:
文件操作其实很简单,语法也不复杂,除了学习语法还要深刻了解字节流(可以看做二进制文件)和字符流(可以看做文本文件).学了这么多,大家稍加练习,熟悉一下文件操作的语法吧.
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信