SAP WM高阶之下架策略M(Small Large Quantity)
Part I:功能简述以及主数据设置
在SAP WM模块里,存储类型的下架策略M (Small/Large quantity included)是一个在SAP项目实践中不常用的策略。该策略的核心要义是:物料的库存存放在至少2个存储类型里,零散的小数量库存放在存储类型1里,而整托的大数量库存存放在存储类型2里。当业务人员下架的时候,SAP系统发现下架数量比较小,所以自动建议从存储类型1里下架,否则就从存储类型2里下架。
要想使用该下架策略,有如下三个要点:
1)相关存储类型的下架策略维护成M。
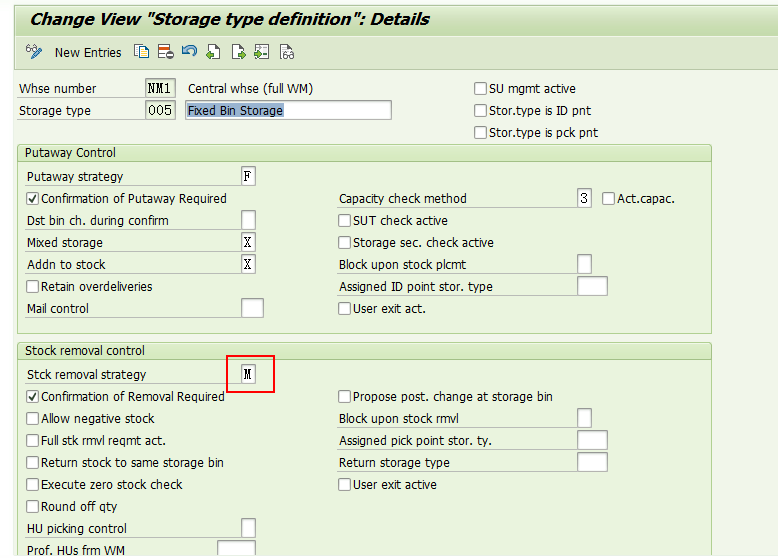

注意:在相关的storage type(005和Z03)的设置里都需要将stock removal strategy(下架策略)维护成M。
2)在Storage type search里,需要将相关存储类型维护进去,并且存放小数量库存的storage type放在前面,存放整托库存的storage type放在后面。
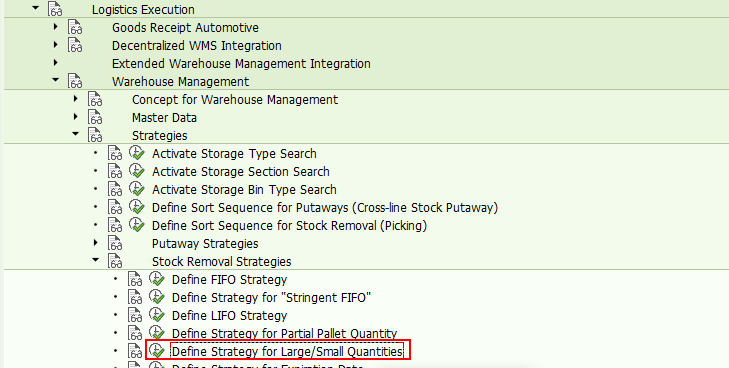
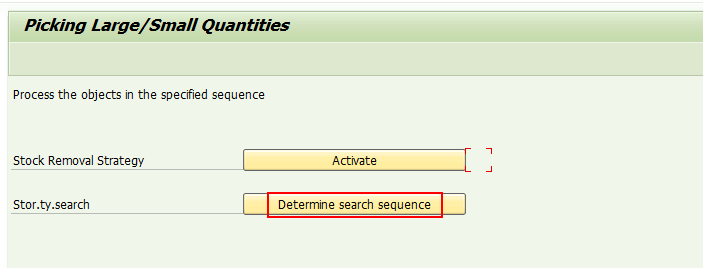

这里我们假定:小数量的库存放在005存储类型里,整托库存放在Z03存储类型里。
3)在物料主数据的WM 2视图里,需要在存放小数量的存储类型下维护Control Quantity字段值。SAP系统会比较此次下架的数量是大于还是小于这个control qty,如果是小于control qty,则系统自动建议从存放小数量库存的storage type下架,否则就会从存放大数量的storage type里下架。
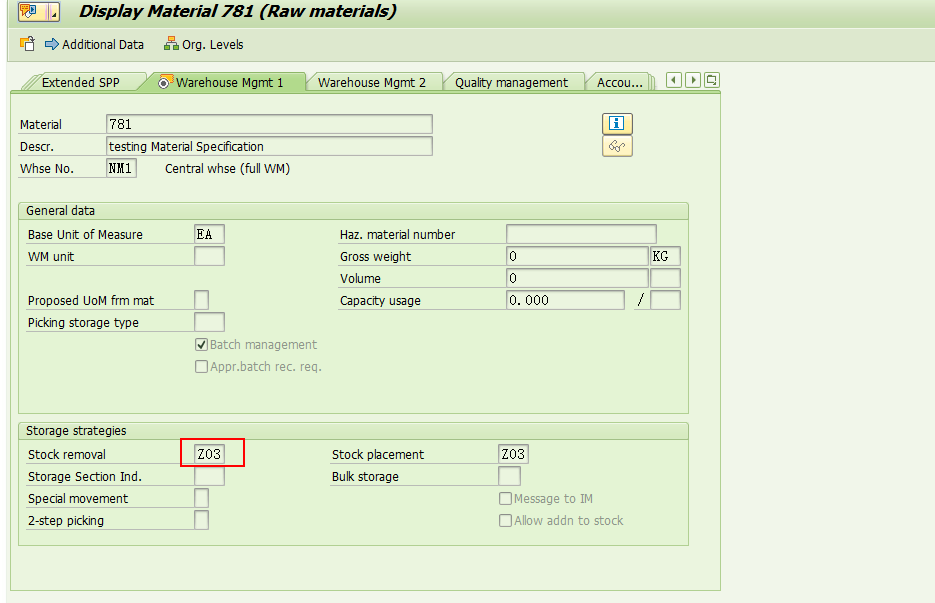
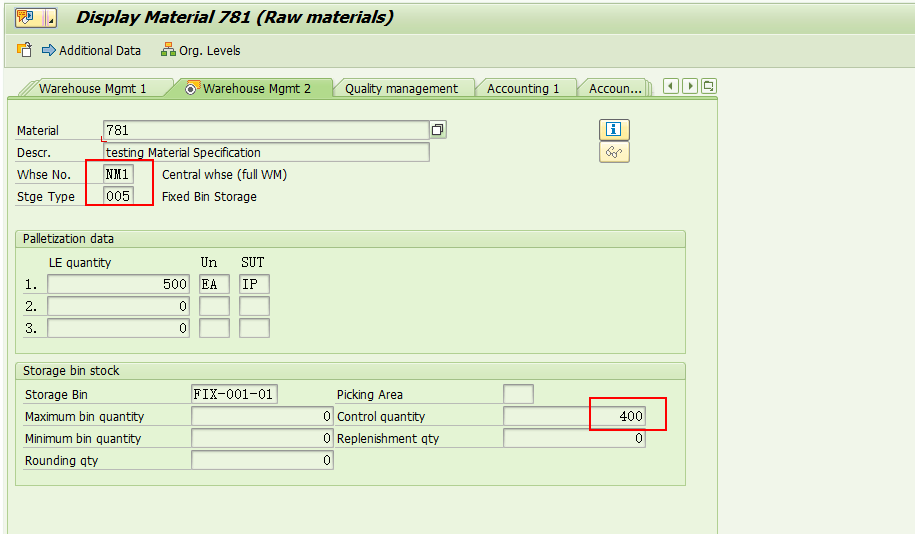
在放置小数量库存的storage type 005里维护Control quantity字段值400EA .
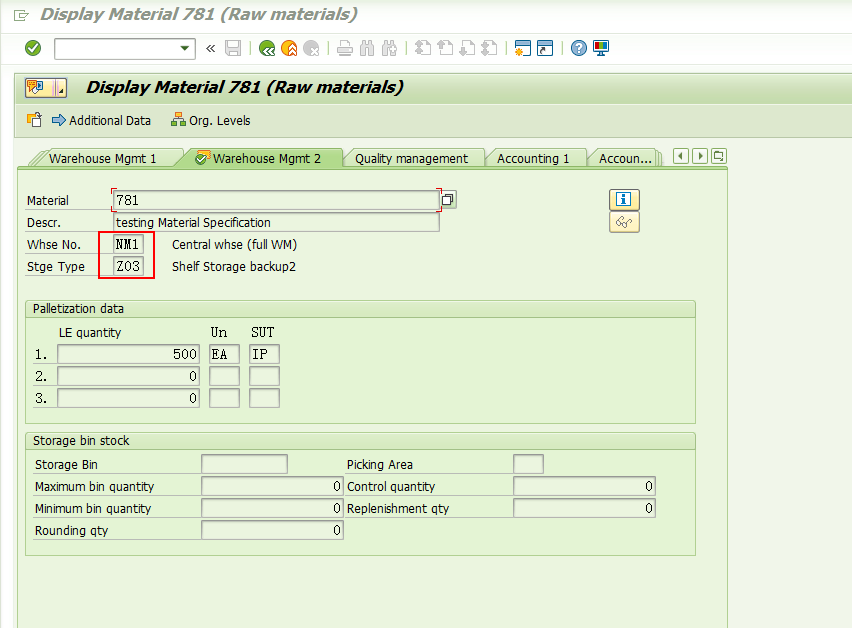
在放置整托库存的存储类型Z03里不用维护control quantity。
Part II:下架策略M的功能展示
1, 现在物料781在存储类型005和Z03的库存数据。
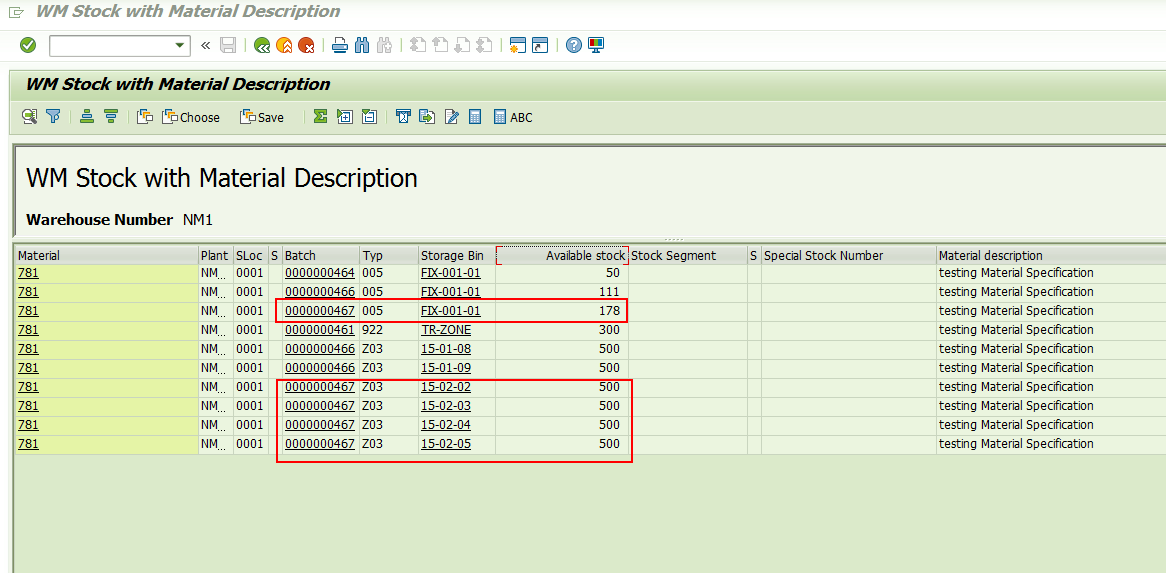
批次号0000000467在005存储地有零散库存,在Z03存储区域有整托库存(500 EA/Pallet).
2, 执行事务代码MIGO做一笔201出库事务,数量小于物料主数据里维护的control quantity字段值。
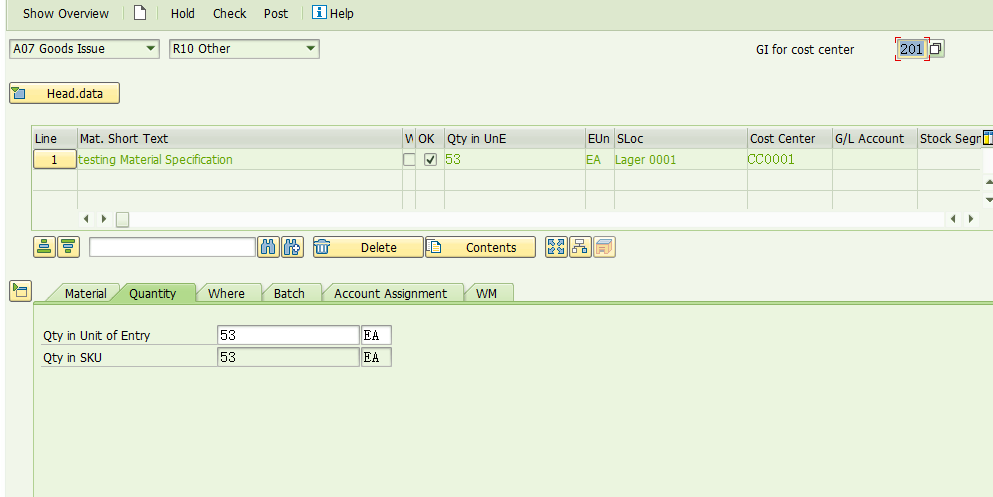
出货数量是53。Batch #0000000467,
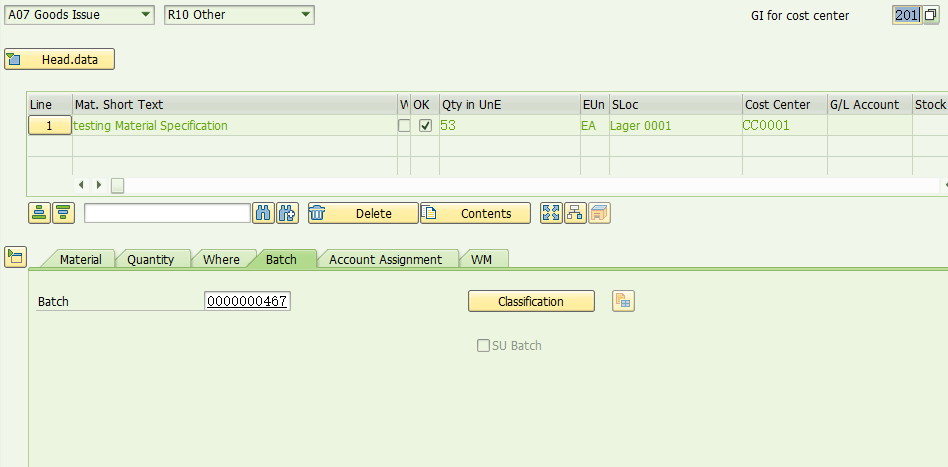
Post,系统转向LT06界面,如下图示:

回车,系统进入如下界面,
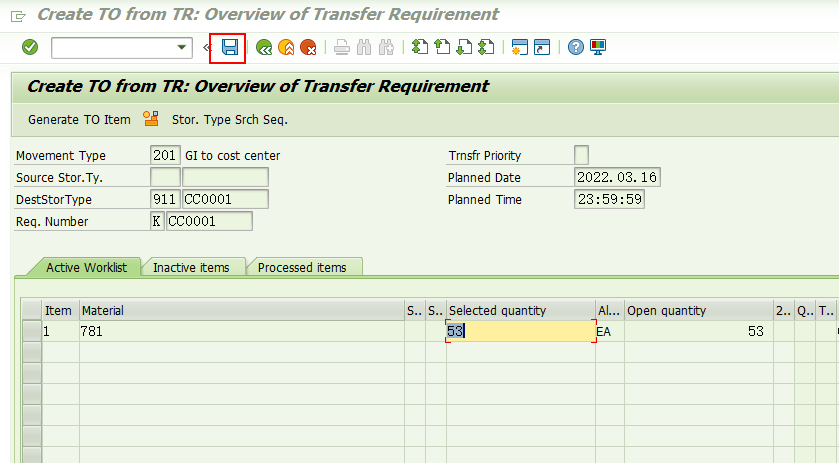
不做人工干预,直接保存,看系统的表现。

TO#82被创建。观察该TO的数据,

因为出库数量53小于control quantity,所以从005存储类型下架。这是符合预期的。
最新的库存数据如下:
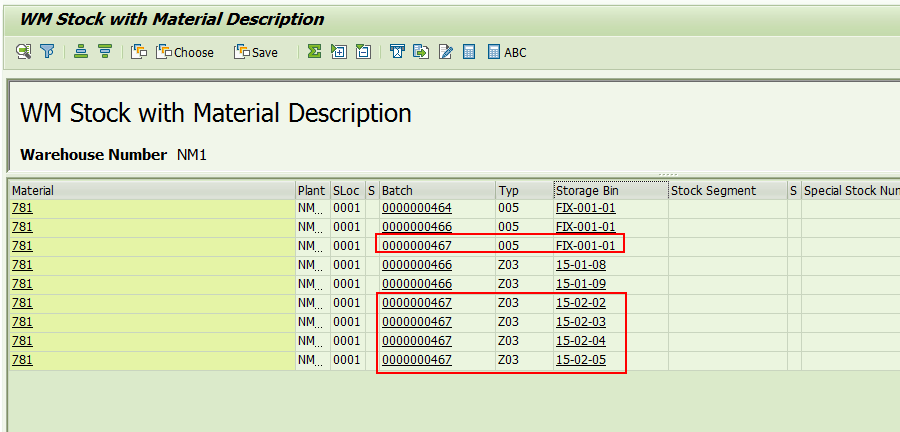
物料781批次号0000000467在存储类型005和Z03都还有库存,如上图示。
3, 再次执行事务代码MIGO做一次201发货,数量是1000,批次号还是0000000467。
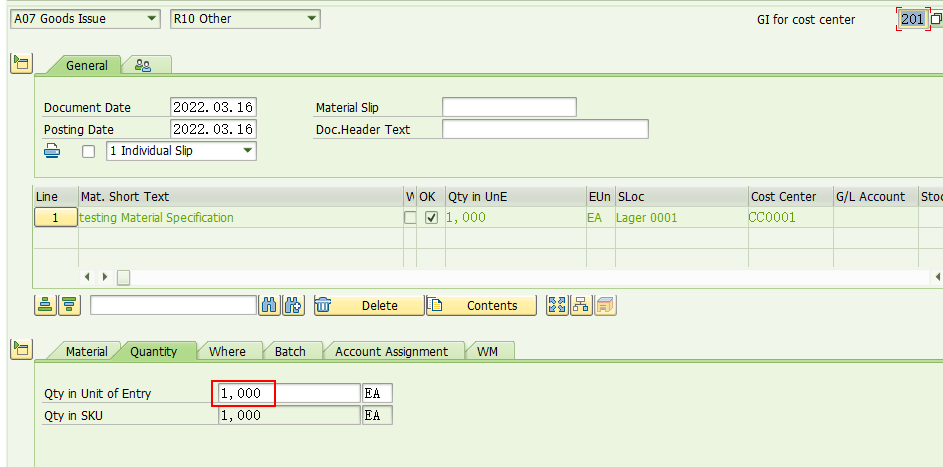
Post,系统转向LT06界面,如下图示:
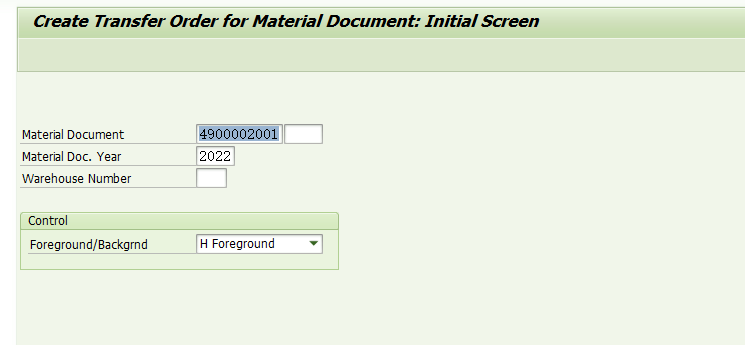
回车,SAP系统进入如下界面,
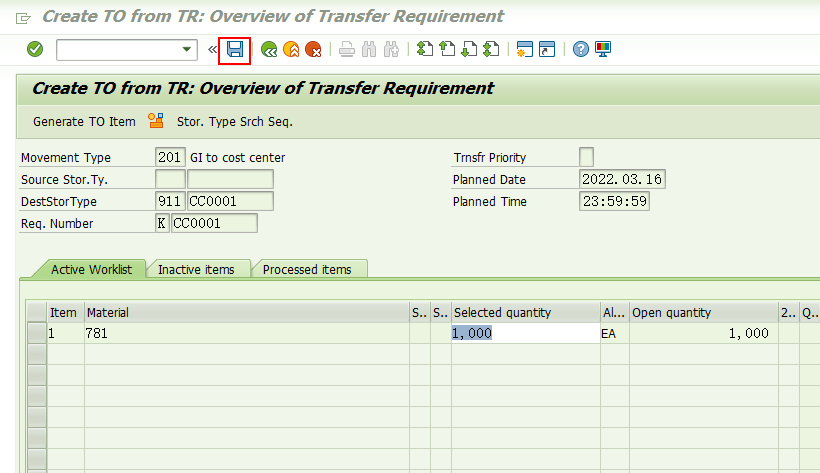
还是不做人工干预,直接保存,系统转入如下界面,

系统能自动建议从Z03 storage type里下架了。输入货架15-02-02,

回车,系统转入如下界面,
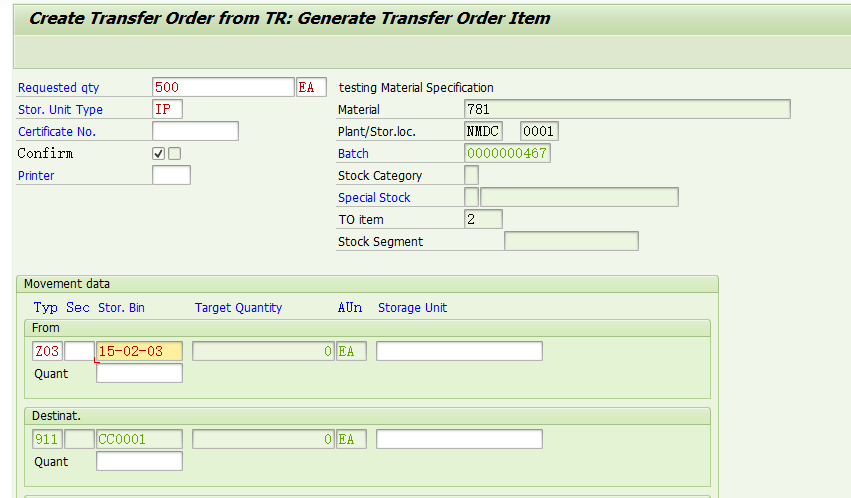
对于余下的数量,继续输入另外一个货架15-02-03, 回车,
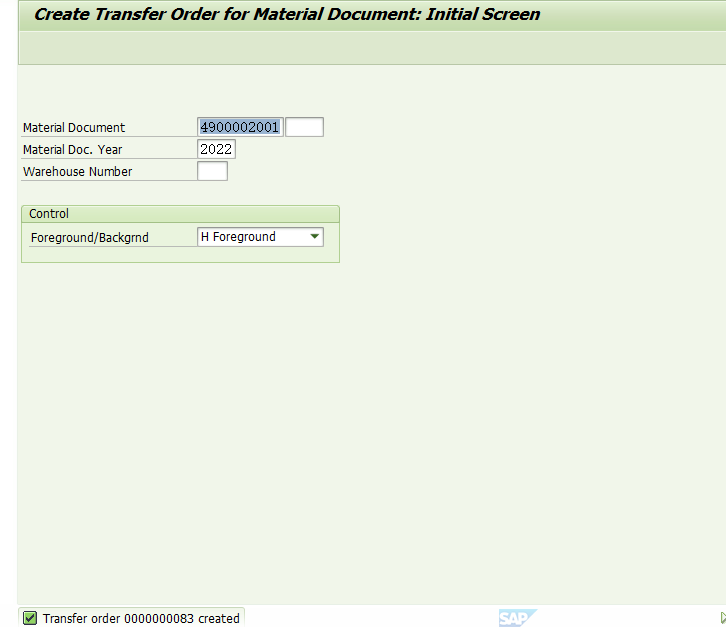
TO#83被创建了。如上图。
观察这个TO#83的数据,
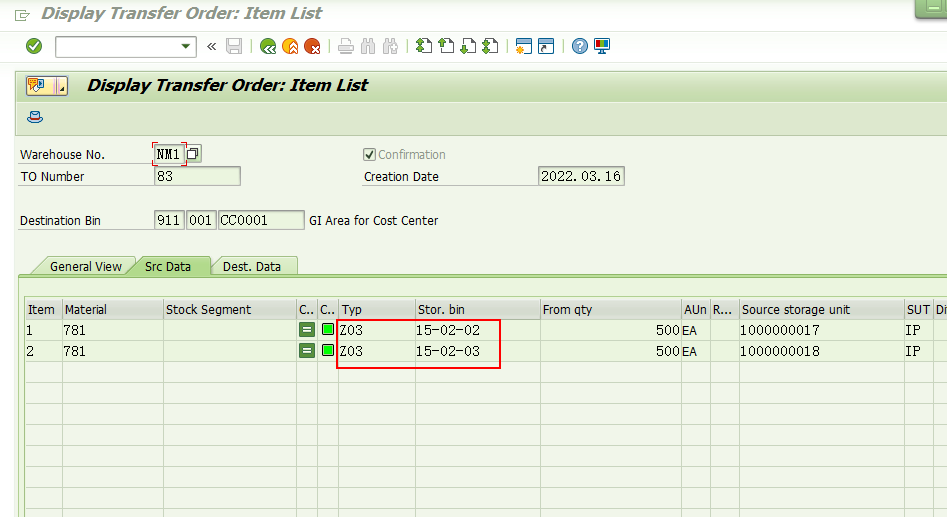
当下架数量为1000的时候,系统自动定位到存放整托库存的storage type Z03,因为下架数量大于在物料主数据里维护的control quantity。这是符合我们的预期的。
这就是下架策略M的控制效果!
注:本文基于SAP S4/HANA 1909系统。
-完-
写于2022-3-16。