文章目录
| 软件 | 版本 |
|---|---|
| Hadoop | 3.3.2 |
| Hive | 3.1.2 |
| Spark | 3.3.1 |
| Flink | 1.14.5 |
cd /home/software
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hudi/0.12.0/hudi-0.12.0.src.tgz --no-check-certificate
tar -xvf hudi-0.12.0.src.tgz -C /home
cd /home/software
wget https://mirrors.tuna.tsinghua.edu.cn/apache/maven/maven-3/3.8.6/binaries/apache-maven-3.8.6-bin.tar.gz --no-check-certificate
tar -xvf apache-maven-3.8.6-bin.tar.gz -C /home
vi /etc/profile
#MAVEN_HOME
export MAVEN_HOME=/home/apache-maven-3.8.6
export PATH=$PATH:$MAVEN_HOME/bin
vi /home/apache-maven-3.8.6/conf/settings.xml
<!-- 添加阿里云镜像-->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
vim /home/hudi-0.12.0/pom.xml
新增repository加速依赖下载
<repository>
<id>nexus-aliyun</id>
<name>nexus-aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
修改依赖的组件版本
<hadoop.version>3.3.2</hadoop.version>
<hive.version>3.1.2</hive.version>
Hudi默认依赖的hadoop2,要兼容hadoop3,除了修改版本,还需要修改如下代码:
vim /home/hudi-0.12.0/hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java
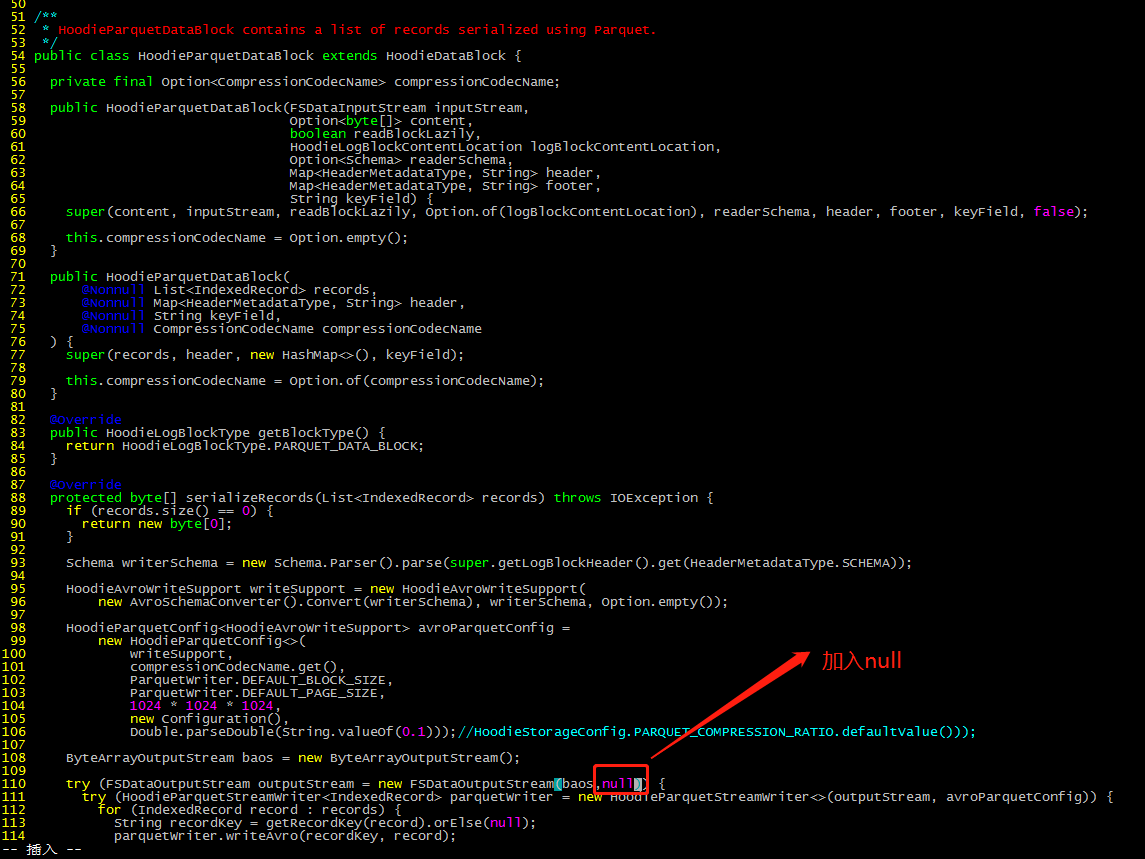
通过网址下载:http://packages.confluent.io/archive/5.3/confluent-5.3.4-2.12.zip
解压后找到以下jar包,上传服务器hp5
common-config-5.3.4.jar
common-utils-5.3.4.jar
kafka-avro-serializer-5.3.4.jar
kafka-schema-registry-client-5.3.4.jar
install到maven本地仓库
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-config -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-config-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-utils -Dversion=5.3.4 -Dpackaging=jar -Dfile=./common-utils-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-avro-serializer -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-avro-serializer-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=5.3.4 -Dpackaging=jar -Dfile=./kafka-schema-registry-client-5.3.4.jar
修改了Hive版本为3.1.2,其携带的jetty是0.9.3,hudi本身用的0.9.4,存在依赖冲突。
排除低版本jetty,添加hudi指定版本的jetty:
cp /home/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml /home/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml.bak
vim /home/hudi-0.12.0/packaging/hudi-spark-bundle/pom.xml
Hive依赖(382行):
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>

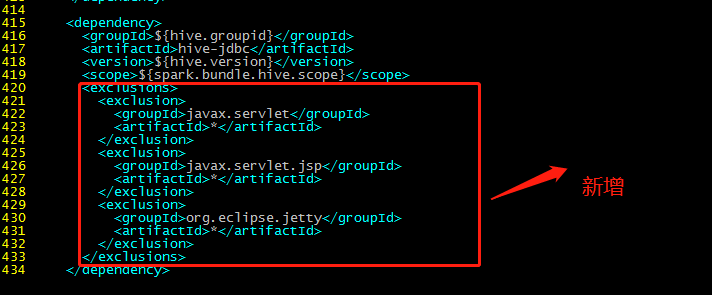
415行:
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
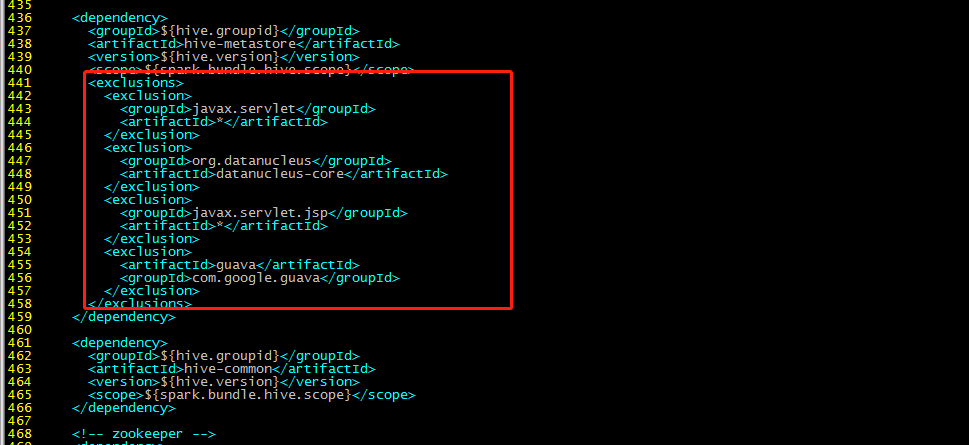
436行:
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
461行:
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
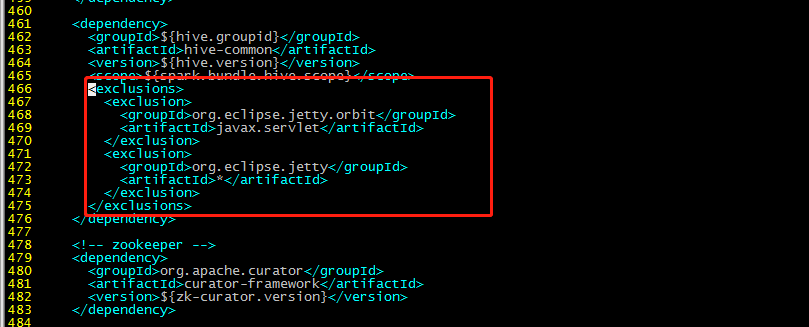
增加hudi配置版本的jetty:
<!-- 增加hudi配置版本的jetty -->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>
排除低版本jetty,添加hudi指定版本的jetty:
vim /home/hudi-0.12.0/packaging/hudi-utilities-bundle/pom.xml
345行部分:
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
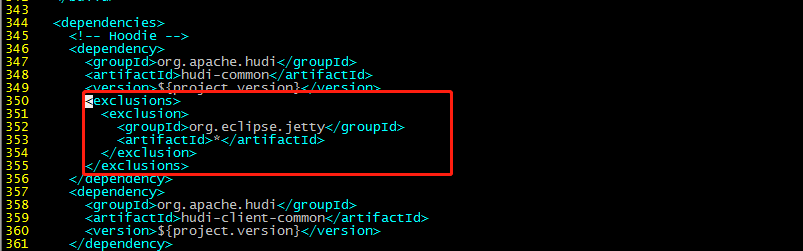
357行:
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
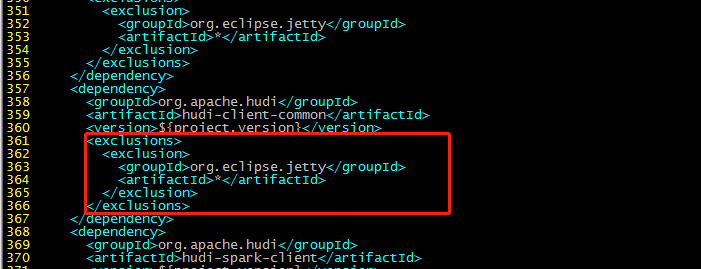
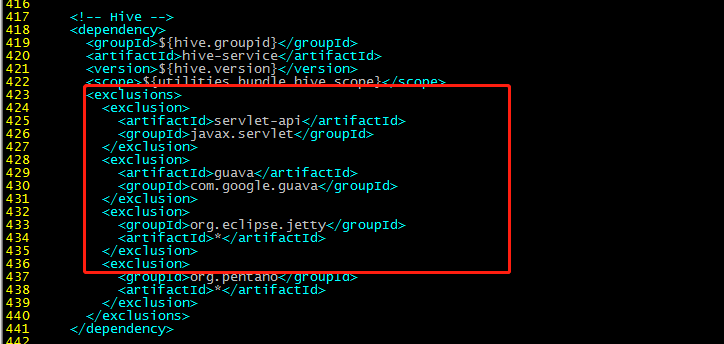
417行部分:
<exclusions>
<exclusion>
<artifactId>servlet-api</artifactId>
<groupId>javax.servlet</groupId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.pentaho</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
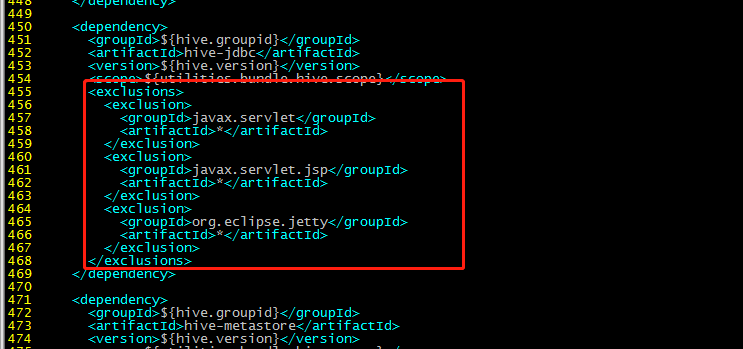
450:
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
471行:
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
</exclusion>
<exclusion>
<groupId>javax.servlet.jsp</groupId>
<artifactId>*</artifactId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
</exclusions>
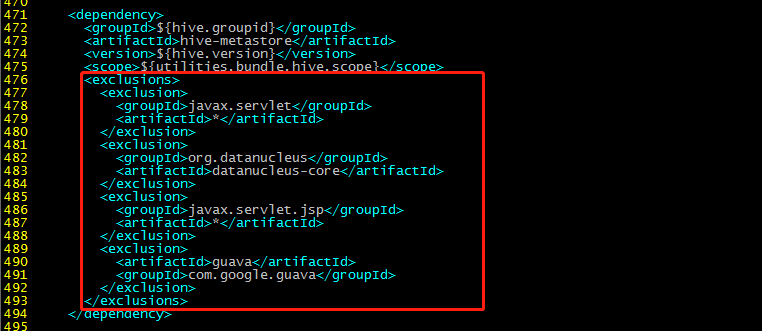
496行:
<exclusions>
<exclusion>
<groupId>org.eclipse.jetty.orbit</groupId>
<artifactId>javax.servlet</artifactId>
</exclusion>
<exclusion>
<groupId>org.eclipse.jetty</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
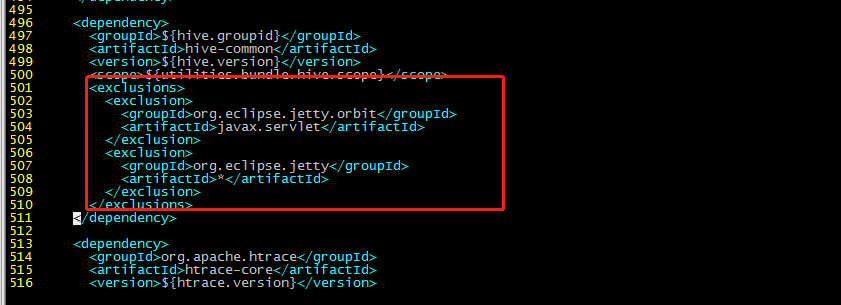
增加:
<!-- 增加hudi配置版本的jetty -->
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-server</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-util</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-webapp</artifactId>
<version>${jetty.version}</version>
</dependency>
<dependency>
<groupId>org.eclipse.jetty</groupId>
<artifactId>jetty-http</artifactId>
<version>${jetty.version}</version>
</dependency>
cd /home/hudi-0.12.0
mvn clean package -DskipTests -Dspark3.3 -Dflink1.14 -Dscala-2.12 -Dhadoop.version=3.3.2 -Pflink-bundle-shade-hive3
报错:
这个报错在网上找了好久都没找到解决方案,后来想了下,我使用的是open jdk11,换回JDK8版本,此问题解决。
安装apache的各个组件,还是继续使用JDK8版本吧,别使用open jdk了,坑太多了。
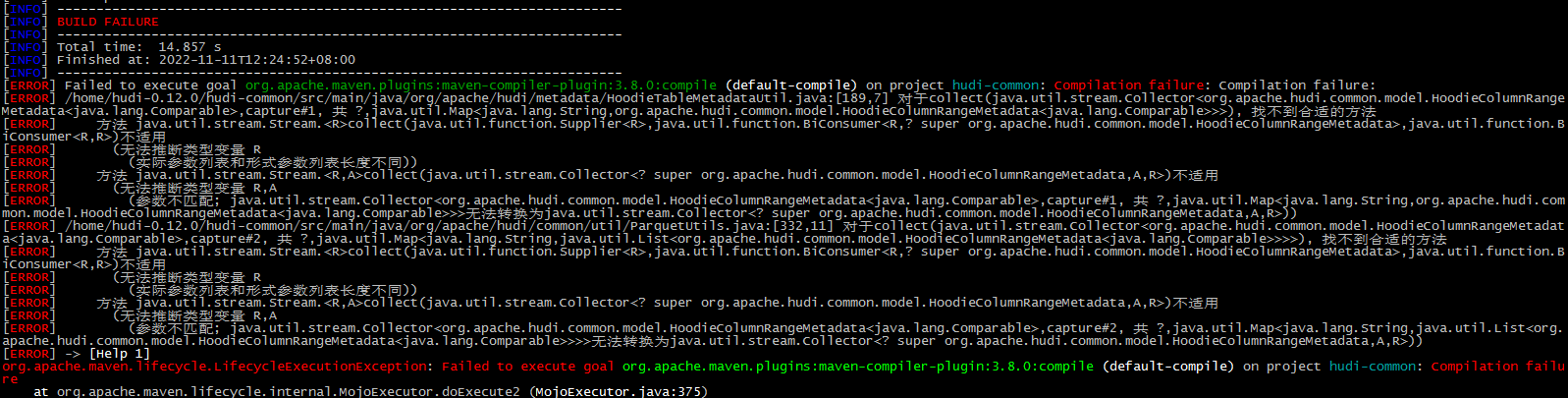
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:3.8.0:compile (default-compile) on project hudi-common: Compilation failure: Compilation failure:
[ERROR] /home/hudi-0.12.0/hudi-common/src/main/java/org/apache/hudi/metadata/HoodieTableMetadataUtil.java:[189,7] 对于collect(java.util.stream.Collector<org.apache.hudi.common.model.HoodieColumnRangeMetadata<java.lang.Comparable>,capture#1, 共 ?,java.util.Map<java.lang.String,org.apache.hudi.common.model.HoodieColumnRangeMetadata<java.lang.Comparable>>>), 找不到合适的方法
[ERROR] 方法 java.util.stream.Stream.<R>collect(java.util.function.Supplier<R>,java.util.function.BiConsumer<R,? super org.apache.hudi.common.model.HoodieColumnRangeMetadata>,java.util.function.BiConsumer<R,R>)不适用
[ERROR] (无法推断类型变量 R
[ERROR] (实际参数列表和形式参数列表长度不同))
[ERROR] 方法 java.util.stream.Stream.<R,A>collect(java.util.stream.Collector<? super org.apache.hudi.common.model.HoodieColumnRangeMetadata,A,R>)不适用
[ERROR] (无法推断类型变量 R,A
[ERROR] (参数不匹配; java.util.stream.Collector<org.apache.hudi.common.model.HoodieColumnRangeMetadata<java.lang.Comparable>,capture#1, 共 ?,java.util.Map<java.lang.String,org.apache.hudi.common.model.HoodieColumnRangeMetadata<java.lang.Comparable>>>无法转换为java.util.stream.Collector<? super org.apache.hudi.common.model.HoodieColumnRangeMetadata,A,R>))
[ERROR] /home/hudi-0.12.0/hudi-common/src/main/java/org/apache/hudi/common/util/ParquetUtils.java:[332,11] 对于collect(java.util.stream.Collector<org.apache.hudi.common.model.HoodieColumnRangeMetadata<java.lang.Comparable>,capture#2, 共 ?,java.util.Map<java.lang.String,java.util.List<org.apache.hudi.common.model.HoodieColumnRangeMetadata<java.lang.Comparable>>>>), 找不到合适的方法
[ERROR] 方法 java.util.stream.Stream.<R>collect(java.util.function.Supplier<R>,java.util.function.BiConsumer<R,? super org.apache.hudi.common.model.HoodieColumnRangeMetadata>,java.util.function.BiConsumer<R,R>)不适用
[ERROR] (无法推断类型变量 R
[ERROR] (实际参数列表和形式参数列表长度不同))
[ERROR] 方法 java.util.stream.Stream.<R,A>collect(java.util.stream.Collector<? super org.apache.hudi.common.model.HoodieColumnRangeMetadata,A,R>)不适用
[ERROR] (无法推断类型变量 R,A
[ERROR] (参数不匹配; java.util.stream.Collector<org.apache.hudi.common.model.HoodieColumnRangeMetadata<java.lang.Comparable>,capture#2, 共 ?,java.util.Map<java.lang.String,java.util.List<org.apache.hudi.common.model.HoodieColumnRangeMetadata<java.lang.Comparable>>>>无法转换为java.util.stream.Collector<? super org.apache.hudi.common.model.HoodieColumnRangeMetadata,A,R>))
[ERROR] -> [Help 1]
编译成功:
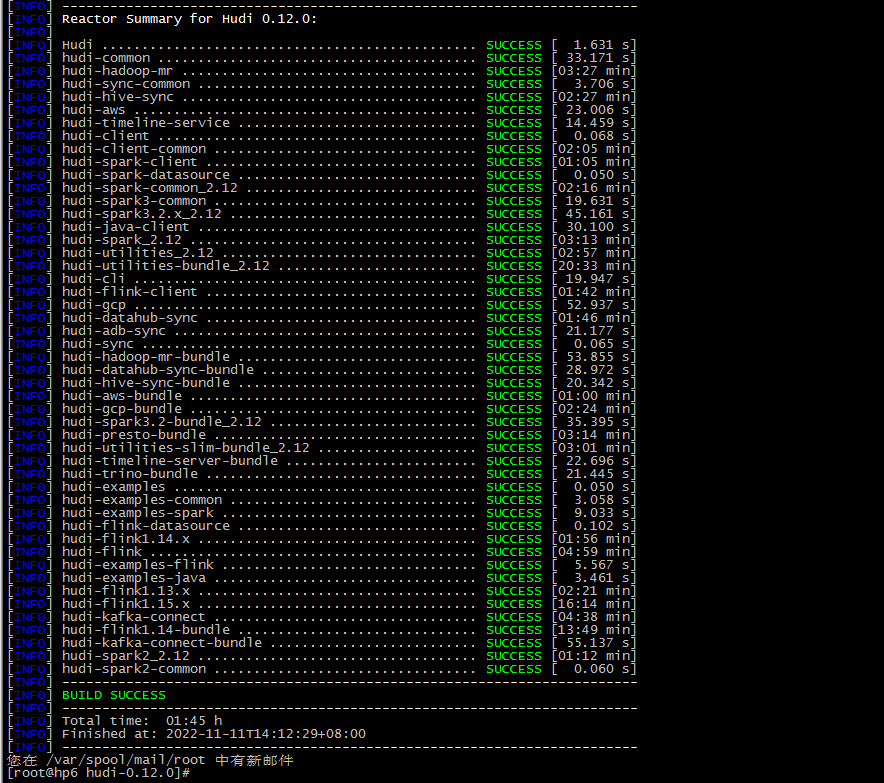
编译成功后,进入hudi-cli说明成功:
cd /home/hudi-0.12.0/hudi-cli
./hudi-cli.sh
相关的jar包:
编译完成后,相关的包在packaging目录的各个模块中:
比如,flink与hudi的包:

关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121