更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
相信大家都对大名鼎鼎的ClickHouse有一定的了解了,它强大的数据分析性能让人印象深刻。但在字节大量生产使用中,发现了ClickHouse依然存在了一定的限制。本篇将详细介绍我们是如何为ClickHouse增强高可用能力的。
随着字节业务的快速发展,产品快速扩张,承载业务的ClickHouse集群节点数也快速增加。另一方面,按照天进行的数据分区也快速增加,一个集群管理的库表特别多,开始出现元数据不一致的情况。两方面结合,导致集群的可用性极速下降,以至于到了业务难以接受的程度。直观的问题有三类:
1、故障变多
典型的例子如硬件故障,几乎每天都会出现。另外,当集群达到一定的规模,Zookeeper会成为瓶颈,增加故障发生频率。
2、故障恢复时间长
因为数据分区变多,导致一旦发生故障,恢复时间经常会需要1个小时以上,这是业务方完全不能接受的。
3、运维复杂度提升
以往只需要一个人负责运维的集群,由于节点增加和分区变多,运维复杂度和难度成倍的增加,目前运维人数增加了几人也依然拙荆见肘,依然难保证集群的稳定运行。
可用性问题已经成为制约业务发展的重要问题,因此我们决定将影响高可用的问题一一拆解,并逐个解决。
问题所在:
原生ClickHouse 使用 ReplicatedMergeTree 引擎来实现数据同步。原理上,ReplicatedMergeTree 基于 ZooKeeper 完成多副本的选主、数据同步、故障恢复等功能。由于 ReplicatedMergeTree 对 ZooKeeper 的使用比较重,除了每组副本一些表级别的元信息,还存储了逻辑日志、part 信息等潜在数量级较大的信息。Zookeeper并不是一个能做到良好线性扩展的系统,当ZooKeeper 在相对较高的负载情况下运行时,往往性能表现并不佳,甚至会出现副本无法写入,数据也无法同步的情况。在字节内部实际使用和运维 ClickHouse 的过程中,ZooKeeper 也是非常容易成为一个瓶颈的组件。
改造思路:
ReplicatedMergeTree 支持 insert_quorum,insert_quorum 是指如果副本数为3,insert_quorum=2,要成功写入至少两个副本才会返回写入成功。
新分区在副本之间复制的流程如下:
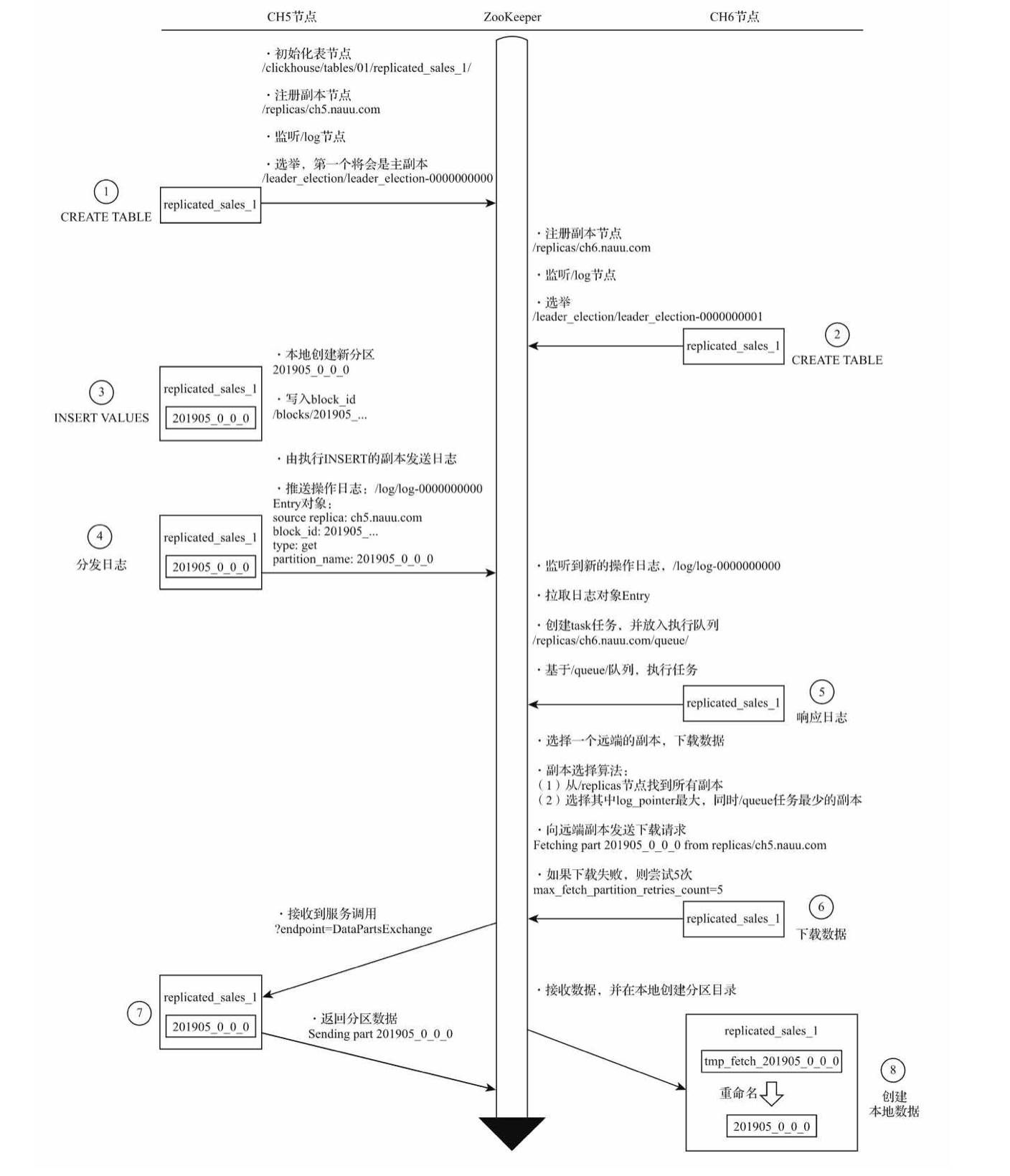
可以看到,反复在 zookeeper 中进行分发日志、数据交换等步骤,这正是引起瓶颈的原因之一。
为了降低对 ZooKeeper 的负载,在ByteHouse中重新实现了一套 HaMergeTree 引擎。通过HaMergeTree降低对 ZooKeeper 的请求次数,减少在 ZooKeeper 上存储的数据量,新的 HaMergeTree 同步引擎:
1)保留ZooKeeper上表级别的元信息;
2)简化逻辑日志的分配;
3)将 part 信息从 ZooKeeper 日志移除。
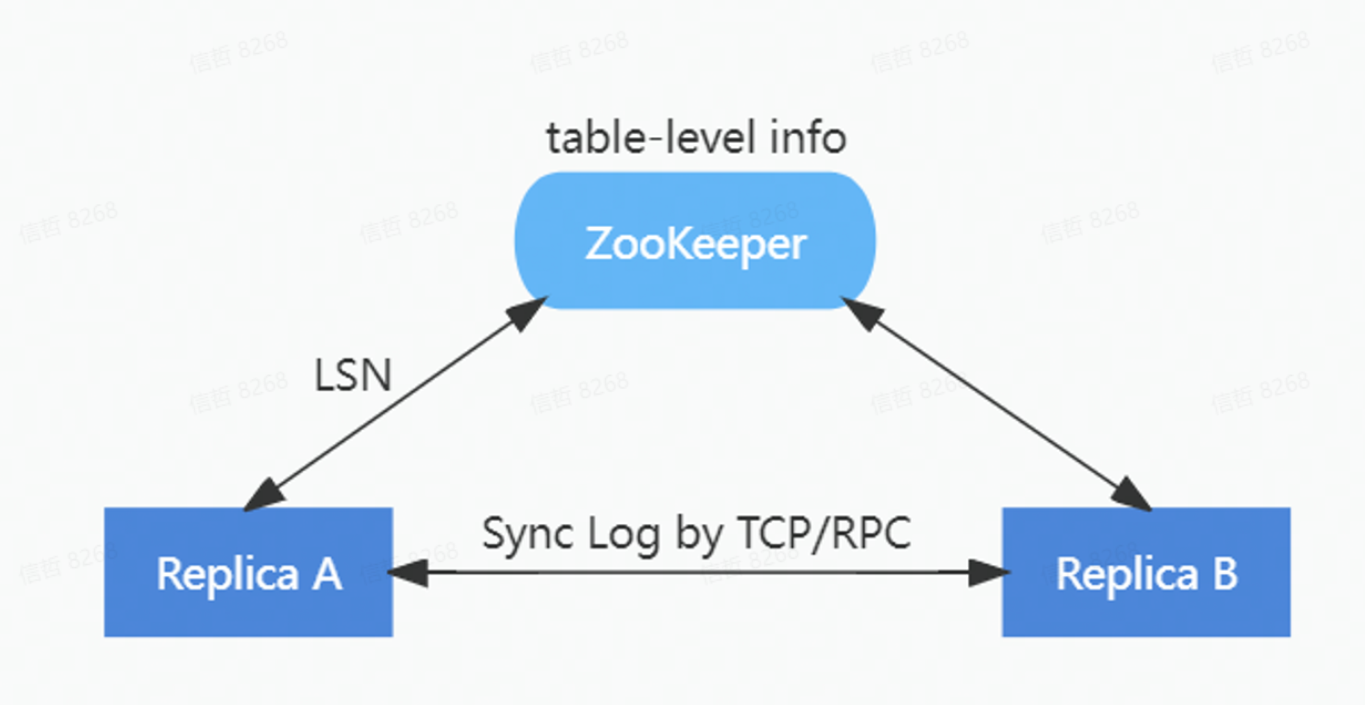
HaMergeTree 减少了操作日志等信息在zookeeper里面的存放,来减少zookeeper的负载,zookeeper里面只是存放log LSN, 具体日志在副本之间通过gossip协议同步回放。
在保持和ReplicatedMergeTree完全兼容的前提下,新的 HaMergeTree 极大减轻了对 ZooKeeper 的负载,实现了 ZooKeeper 集群的压力与数据量不相关。上线后,因Zookeeper导致的异常大量减少。无论是单集群几百甚至上千节点,还是单节点上万张表,都能保障良好的稳定性。
问题所在:
虽然所有数据从业者都在做各种努力,想要保证线上生产环境不出故障,但是现实中还是难以避免会遇到各式各样的问题。主要是由下面这几种因素引起的:
软件缺陷:软件设计本身的Bug引起的系统非正常终止,或依赖的组件兼容引发的问题。
硬件故障:常见的有磁盘损坏、内容故障、CPU故障等,当集群规模扩大后发生的频率也线性增加。
内存溢出导致进程被停止:在OLAP数据库中经常发生。
意外因素:如断电、误操作等引发的问题。
由于原生ClickHouse希望达到极致性能的初衷,所以在ClickHouse系统中元数据常驻于内存中,这导致了ClickHouse server重启时间非常长。因而当故障发生后,恢复的时间也很长,动辄一到两个小时,相当于业务也要中断一到两个小时。当故障频繁出现,造成的业务损失是无法估量的。
改造思路:
为了解决上述问题,在ByteHouse中采用了元数据持久化的方案,将元数据持久化到RocksDB, Server启动时直接从RocksDB加载元数据,内存中也仅仅存放必要的Part信息。因此可以减少元数据对内存的占用,以及加速集群的启动以及故障恢复时间。
如下图所示,元数据持久化整体上采用了RocksDB+Meta in Memory的方式,每个Table都会对应一个RocksDB数据库存放该表所有Part的元信息。Table首次启动时,从文件系统中加载的Part元数据将被持久化到RocksDB中;之后重启时就可以直接从RocksDB中加载Part。每个表从RocksDB或者文件系统加载的Part将只在内存中存放必要的Part信息。在实际使用Part时,将通过内存中存放的Part元信息去RocksDB中读取并加载对应Part。
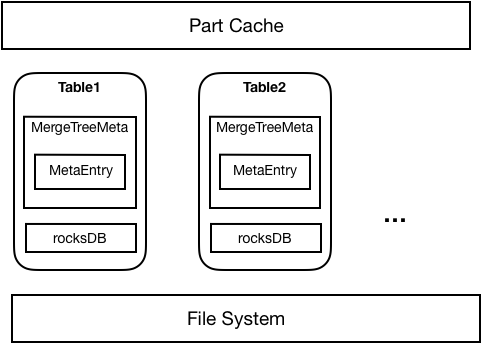
完成元数据持久化后,在性能基本无损失的情况下,单机支持的part不再受内存容量的限制,可以达到100万以上。最重要的是,故障恢复的时间显著缩短,只需要此前的几十分之一的时间就可以完成。例如在原生ClickHouse中需要一到两个小时的恢复时间,在ByteHouse中只需要3分钟,大大提高的系统的高可用能力,为业务提供了坚实保障。
除了以上两点,在ByteHouse中在其他很多方面都为高可用能力做了增强,如通过HaKafka引擎提升了数据写入的高可用性,提升实时数据写入的容错率,可自动切换主备写入;增加了监控运维平台,实现对关键指标的监控、告警;增加多种问题诊断工具,能实现故障的快速定位。
对于数据分析平台来说,稳定性是重中之重。我们对ByteHouse的高可用能力的提升是不会停止的,在极致性能的背后,力图为用户提供最强有力的稳定性保障。
立即跳转火山引擎ByteHouse官网了解详情
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我正在使用Ruby,我正在与一个网络端点通信,该端点在发送消息本身之前需要格式化“header”。header中的第一个字段必须是消息长度,它被定义为网络字节顺序中的2二进制字节消息长度。比如我的消息长度是1024。如何将1024表示为二进制双字节? 最佳答案 Ruby(以及Perl和Python等)中字节整理的标准工具是pack和unpack。ruby的packisinArray.您的长度应该是两个字节长,并且按网络字节顺序排列,这听起来像是n格式说明符的工作:n|Integer|16-bitunsigned,network(bi
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我的rails3.1.6应用程序中有一个自定义访问器方法,它为一个属性分配一个值,即使该值不存在。my_attr属性是一个序列化的哈希,除非为空白,否则应与给定值合并指定了值,在这种情况下,它将当前值设置为空值。(添加了检查以确保值是它们应该的值,但为简洁起见被删除,因为它们不是我的问题的一部分。)我的setter定义为:defmy_attr=(new_val)cur_val=read_attribute(:my_attr)#storecurrentvalue#makesureweareworkingwithahash,andresetvalueifablankvalueisgiven
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源