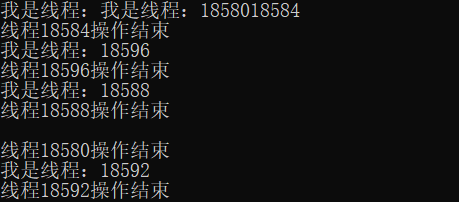
首先,我们看看多线程的执行顺序:
void TextThread() {
cout << "我是线程:" << this_thread::get_id() << endl;
//线程内操作代码
cout << "线程" << this_thread::get_id() << "操作结束" << endl;
}
int main()
{
vector<thread> threadVec;
for (int i = 0; i < 5; ++i) {
threadVec.push_back(thread(TextThread));
}
for (int i = 0; i < 5; ++i) {
threadVec[i].join();
}
return 0;
}
然而上述的线程中并没有涉及到线程之间的通信问题,如果涉及多个线程操作同一堆数据,会怎么样呢?(学过操作系统都知道,这就是数据共享问题)
头文件包含#include <mutex>
最基础用法
①lock()、unlock()
步骤:1.lock(); 2.操作共享数据;3.unlock();
lock()和unlock()要成对使用,注意这种情况:
//拿取数据的函数
bool outMsgPro(int& command) {
myMutex.lock();
if (!msgRecvQueue.empty()) {//非空就进行操作
int command = msgRecvQueue.front();
msgRecvQueue.pop();
//因为进入这里也会return了,一定要unlock();
myMutex.unlock();
return true;
}
myMutex.unlock();
//其他操作代码
return false;
}
高级一点的写法
②lock_guard类模板
lock_guard<mutex> myGuard(myMutex)直接取代了myMutex.lock()和myMutex.unlock();{},约束lock_guard的作用域;//拿取数据的函数
bool outMsgPro(int& command) {
{
std::lock_guard<std::mutex> myGuard(myMutex);
if (!msgRecvQueue.empty()) {//非空就进行操作
int command = msgRecvQueue.front();
msgRecvQueue.pop();
return true;
}
}
//其他操作代码
return false;
}
产生死锁的条件:至少有两个互斥量,多个线程同时需要这两个互斥量,最终形成闭环。比如:
只要保证多个互斥量上锁的顺序一样就不会造成死锁!
std::lock(mutex1,mutex2……):一次锁定多个互斥量(一般这种情况很少),用于处理多个互斥量。但是锁要单独解开mutex1.unlock(),mutex2.unlock()都要自己写std::lock(mutex1,mutex2);
lock_guard<mutex> myGuard1(mutex1, adopt_lock);
lock_guard<mutex> myGuard2(mutex2, adopt_lock);
用lock_guard构造mutex1、mutex2锁的对象,加入adopt_lock后,在调用lock_guard的构造函数时,不再进行lock(); 但是在出了对象的作用域后,还是会调用unlock()释放锁! 解决了lock多个锁后需要自己每个释放的问题。
std::adopt_lock为结构体对象,起一个标记作用,表示这个互斥量已经lock(),不需要再lock()操作。
整个示例代码:
class A
{
public:
//拿取数据的函数
bool outMsgPro(int& command) {
lock(mutex1, mutex2);
lock_guard<mutex> myGuard1(mutex1, adopt_lock);
lock_guard<mutex> myGuard2(mutex2, adopt_lock);
//②lock_guard<mutex> myGuard1(mutex1); lock_guard<mutex> myGuard2(mutex2);
//①mutex1.lock(); mutex2.lock();
if (!msgRecvQueue.empty()) {//非空就进行操作
command = msgRecvQueue.front();
msgRecvQueue.pop();
//因为进入这里也会return了,一定要unlock();
//mutex1.unlock(); mutex2.unlock();
return true;
}
//mutex1.unlock(); mutex2.unlock();
return false; //return自动释放锁
}
//写入数据函数;
void inMsgPro() {
for (int i = 0; i < 100; ++i) {
cout << "inMsgPro()执行,插入元素" << i << endl;
lock(mutex1, mutex2);
lock_guard<mutex> myGuard1(mutex1, adopt_lock);
lock_guard<mutex> myGuard2(mutex2, adopt_lock);
//②lock_guard<mutex> myGuard1(mutex1); lock_guard<mutex> myGuard2(mutex2);
//①mutex1.lock(); mutex2.lock();
msgRecvQueue.push(i);
//mutex1.unlock(); mutex2.unlock();
}
}
//测试拿出数据函数
void Test() {
int data;
for (int i = 0; i < 100; ++i) {
if (outMsgPro(data)) cout << data << " ";
else cout << "没有数据" << " ";
}
}
private:
queue<int> msgRecvQueue;
mutex mutex1;
mutex mutex2;
};
int main() {
A a;
thread myInMsgObj(&A::inMsgPro, &a);//必须要传入地址,说明是同一个元素
thread myOutMsgObj(&A::Test, &a);
myInMsgObj.join();
myOutMsgObj.join();
return 0;
}
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我正在尝试使用ruby编写一个双线程客户端,一个线程从套接字读取数据并将其打印出来,另一个线程读取本地数据并将其发送到远程服务器。我发现的问题是Ruby似乎无法捕获线程内的错误,这是一个示例:#!/usr/bin/rubyThread.new{loop{$stdout.puts"hi"abc.putsefsleep1}}loop{sleep1}显然,如果我在线程外键入abc.putsef,代码将永远不会运行,因为Ruby将报告“undefinedvariableabc”。但是,如果它在一个线程内,则没有错误报告。我的问题是,如何让Ruby捕获这样的错误?或者至少,报告线程中的错误?
我是ruby的新手,我认为重新构建一个我用C#编写的简单聊天程序是个好主意。我正在使用Ruby2.0.0MRI(Matz的Ruby实现)。问题是我想在服务器运行时为简单的服务器命令提供I/O。这是从示例中获取的服务器。我添加了使用gets()获取输入的命令方法。我希望此方法在后台作为线程运行,但该线程正在阻塞另一个线程。require'socket'#Getsocketsfromstdlibserver=TCPServer.open(2000)#Sockettolistenonport2000defcommandsx=1whilex==1exitProgram=gets.chomp
我有一个使用PDFKit呈现网页的pdf版本的Rails应用程序。我使用Thin作为开发服务器。问题是当我处于开发模式时。当我使用“bundleexecrailss”启动我的服务器并尝试呈现任何PDF时,整个过程会陷入僵局,因为当您呈现PDF时,会向服务器请求一些额外的资源,如图像和css,看起来只有一个线程.如何配置Rails开发服务器以运行多个工作线程?非常感谢。 最佳答案 我找到的最简单的解决方案是unicorn.geminstallunicorn创建一个unicorn.conf:worker_processes3然后使用它:
我试图在Ubuntu14.04中使用Curl安装RVM。我运行了以下命令:\curl-sSLhttps://get.rvm.io|bash-sstable出现如下错误:curl:(7)Failedtoconnecttoget.rvm.ioport80:Networkisunreachable非常感谢解决此问题的任何帮助。谢谢 最佳答案 在执行curl之前尝试这个:echoipv4>>~/.curlrc 关于ruby-在Ubuntu14.04中使用Curl安装RVM时出错,我们在Stack
所以,Ruby1.9.1现在是declaredstable.Rails应该与它一起工作,并且正在慢慢地将gem移植到它。它具有native线程和全局解释器锁(GIL)。自从GIL到位后,原生线程是否比1.9.1中的绿色线程有任何优势? 最佳答案 1.9中的线程是原生的,但它们被“放慢了速度”,一次只允许一个线程运行。这是因为如果线程真的并行运行,它会混淆现有代码。优点:IO现在在线程中是异步的。如果一个线程阻塞在IO上,那么另一个线程将继续执行直到IO完成。C扩展可以使用真正的线程。缺点:任何非线程安全的C扩展都可能存在使用Thre
假设我的Rails项目中有一个设置实例变量的Ruby类。classSomethingdefself.objects@objects||=begin#somelogicthatbuildsanarray,whichisultimatelystoredin@objectsendendend是否可以多次设置@objects?是否有可能在一个请求期间,在上面的begin/end之间执行代码时,可以在第二个请求期间调用此方法?我想这实际上归结为Rails服务器实例如何fork的问题。我应该改用Mutex还是线程同步?例如:classSomethingdefself.objectsreturn@o
我在一个ruby文件中有一个函数可以像这样写入一个文件File.open("myfile",'a'){|f|f.puts("#{sometext}")}这个函数在不同的线程中被调用,使得像上面这样的文件写入不是线程安全的。有谁知道如何以最简单的方式使这个文件写入线程安全?更多信息:如果重要的话,我正在使用rspec框架。 最佳答案 您可以通过File#flock给锁File.open("myfile",'a'){|f|f.flock(File::LOCK_EX)f.puts("#{sometext}")}
安装Rails时,一切都很好,但后来,我写道:rails-v和输出:/home/toshiba/.rvm/rubies/ruby-2.2.1/lib/ruby/site_ruby/2.2.0/rubygems/core_ext/kernel_require.rb:54:in`require':cannotloadsuchfile--rails/cli(LoadError)from/home/toshiba/.rvm/rubies/ruby-2.2.1/lib/ruby/site_ruby/2.2.0/rubygems/core_ext/kernel_require.rb:54:in`r