vivo 互联网前端团队-Yang Kun
在团队中,我们因业务发展,需要用到桌面端技术,如离线可用、调用桌面系统能力。什么是桌面端开发?一句话概括就是:以 Windows 、macOS 和 Linux 为操作系统的软件开发。对此我们做了详细的技术调研,桌面端的开发方式主要有 Native 、 QT 、 Flutter 、 NW 、 Electron 、 Tarui 。其各自优劣势如下表格所示:
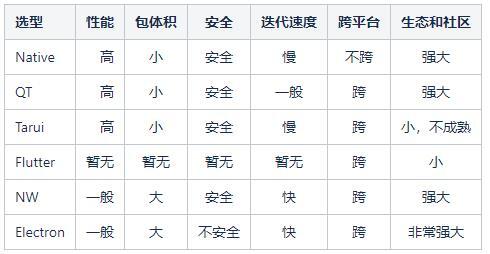
我们最终的桌面端技术选型是 Electron ,Electron 是一个可以使用 Web 技术来开发跨平台桌面应用的开发框架。
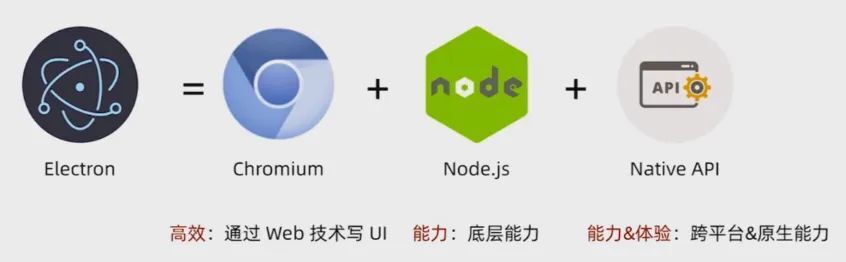
其技术组成如下:
Electron = Chromium + Node.js + Native API
各技术能力如下图所示:
整体架构如下图所示:
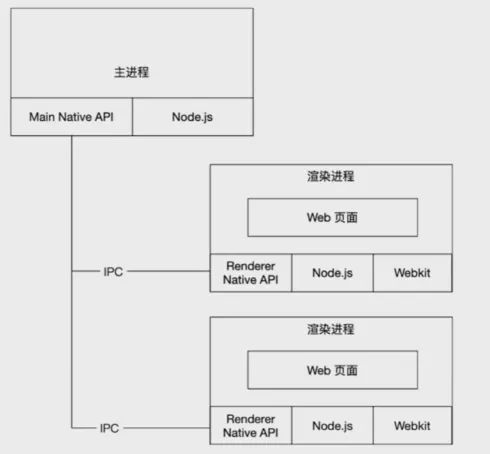
Electron 是多进程架构,架构具有以下特点:
这里说下 Electron 进程间通信技术原理:
electron 使用 IPC (interprocess communication) 在进程之间进行通信,如下图所示:
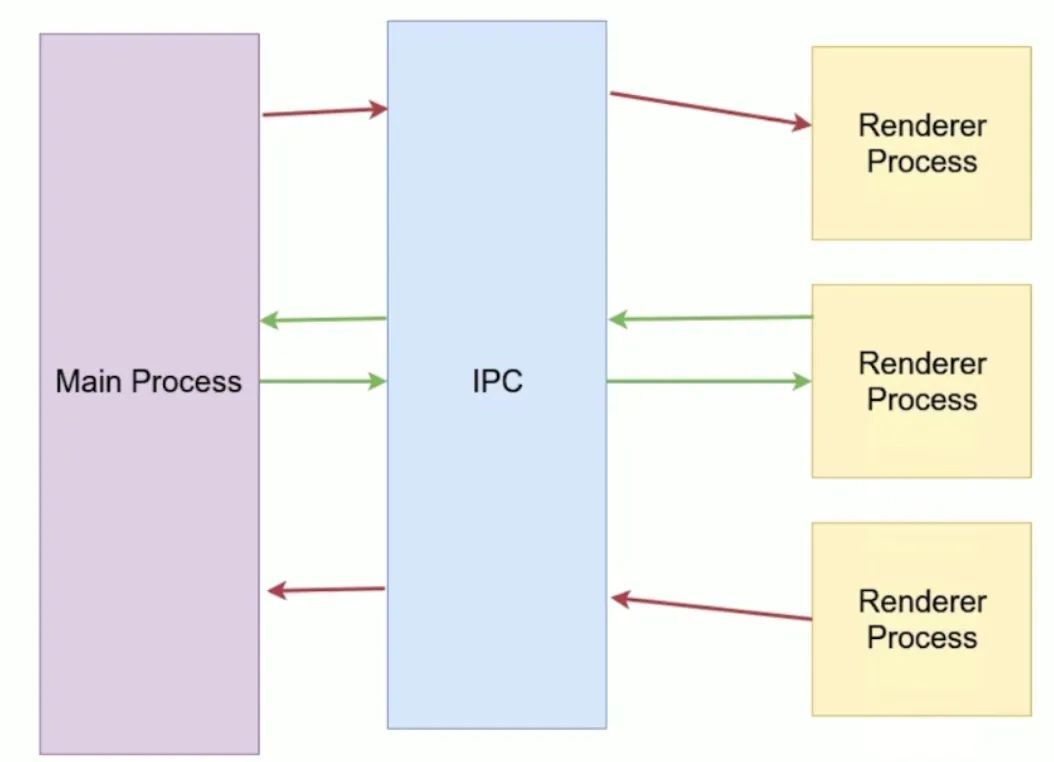
其提供了 IPC 通信模块,主进程的 ipcMain 和渲染进程的 ipcRenderer。
从 electron 源码中可以看出, ipcMain 和 ipcRenderer 都是 EventEmitter 对象,源码如下图所示:
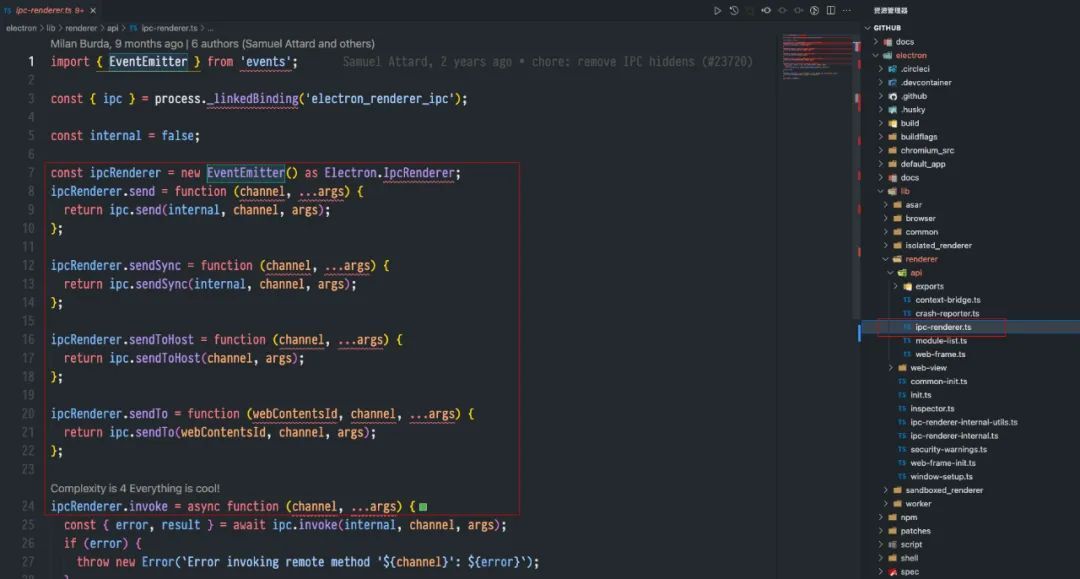
看到源码实现,是不是觉得 IPC 不难理解了。知其本质,方可游刃有余。
看到这,我们回顾上文技术表格,看到 Electron 应用包体积大,那体积大的根本原因是什么呢?
其实这和 chromium 的框架设计有关,其对很多功能都没有宏控制,导致很难把庞大复杂的细节功能去除掉,也造成了基于 chromium 的开发框架,如 electron 、 nwjs 打出的包起步就是 100 多 M 。
综上,electron 具有跨端、基于 Web 、超强生态等优点,是桌面端开发的优秀方案之一。下文将介绍 electron 应用开发实践经验,包括应用技术选型和常用功能。
理由如下:
- Javascript 的超集 - 无缝支持所有的 es2020+ 所有的特性,学习成本小
- 编译生成的 JavaScript 的代码保持很好的可读性
- 可维护性明显增强
- 完整的 OOP 的支持 - extends, interface, private, protect, public等
- 类型即文档
- 类型的约束,更少的单元测试的覆盖
- 更安全的代码
- 更好的重构能力
- 静态分析自动导包
- 代码错误检查
- 代码跳转
- 代码提示补齐
大量的社区的类型定义文件 提升开发效率
理由:简单而又强大,目前 electron 应用最好的构建工具之一。
这里提一下 electron-builder 其和 electron-forge 的介绍和区别,看下图所示:
两者最大的区别在于自由度,两者在能力上基本没什么差异了,从官方组织中的排序看,有意优先推荐 electron-forge 。
我们采用的是 Vue3 ,同时使用 Vite 作为构建工具,具体优点,大家可以查看官网介绍,这套组合是目前主流的 Web 开发方案。
目前的 monorepo 生态百花齐放,正确的实践方法应该是集大成法,也就是取各家之长,目前的趋势也是如此,各开源 monorepo 工具达成默契,专注自己擅长的能力。
如 pnpm 擅长依赖管理, turbo 擅长构建任务编排。遂在 monorepo 技术选型上,我选择了 pnpm 和 turbo 。
pnpm 理由如下:
- 目前最好的包管理工具, pnpm 吸收了 npm 、 yarn 、 lerna 等主流工具的精华,并去其糟粕。
- 生态、社区活跃且强大
- 结合 workspace 可以完成 monorepo 最佳设计和实践
- 在管理多项目的包依赖、代码风格、代码质量、组件库复用等场景下,表现出色
- 在框架、库的开发、调试、维护方面,表现出色
相比于 vue 官网,在使用 pnpm 上,我加了 workspace 。
turbo 理由如下:
- 它是一个高性能构建系统,拥有增量构建、云缓存、并行执行、运行时零开销、任务管道、精简子集等特性
- 具有非常优秀的任务编排能力,可以弥补 pnpm 在任务编排上的短板
electron 应用数据库有非常多的选择如 lowdb 、 sqlite3 、 electron-store 、 pouchdb 、 dedb 、 rxdb 、 dexie 、 ImmortalDB 等。这些数据库都有一个特性,那就是无服务器。
electron 应用数据库技术选型考虑因素主要有以下3点:
- 生态(使用者数量、维护频率、版本稳定度)
- 能力
- 性能
- 其他(和使用者技术匹配度)
我们通过以下渠道进行了相关调研
- github 的 issues、commit、fork、star
- sourcegraph 关键字搜索结果数
- npm 包下载量、版本发布
- 官网和博客
给出四个最优选择,分别是 lowdb 、 sqlite3 、 nedb 、 electron-store , 理由如下:
- lowdb: 生态、能力、性能三方面表现优秀, json 形式的存储结构, 支持 lodash 、 ramda 等 api 操作,利于备份和调用
- sqlite3: 生态、能力、性能三方面表现优秀, Nodejs 关系型数据库第一选择方案
- nedb: 能力、性能三方面表现优秀,缺点是基本不维护了,但底子还在,尤其操作是 MongoDB 的子集,对于熟悉 MongoDB 的使用者来说是绝佳选择。
- electron-store: 生态表现优秀,轻量级持久化方案,简单易用
我们使用的数据库选型是 lowdb 方案。
PS:提一下 pouchdb ,如果需要将本地数据同步到远端数据库,可以使用 pouchdb ,其和 couchdb 可以轻松完成同步。
软件开发过程中,将一些流程和操作通过脚本来完成,可以有效地提高开发效率和幸福度。
依赖 node runtime 的优秀选择就两个:shelljs 和 zx , 选择 zx 的理由如下:
- 自带 fetch 、 chalk 等常用库,使用方便快捷
- 多个子进程方便快捷、执行远端脚本、解析 md 、 xml 文件脚本、支持 ts ,功能丰富且强大
- 谷歌出品,大厂背景,生态非常活跃
至此,技术选型就介绍完了,下面我将介绍electron 应用的常用功能。
此部分主要介绍以下5点内容:
- 应用图标生成
- 二进制文件构建
- 按需构建
- 性能优化
- 跨平台兼容
不同尺寸图标的生成有以下方法:
Windows
MacOS
本章节内容是基于 electron-forge 阐述的,不过原理是一样的。
在开发桌面端应用时,会有场景要用到第三方的二进制程序,比如 ffmpeg 这种。在构建二进制程序时,要关注以下两个注意项:
(1)二进制程序不能打包进 asar 中 可以在构建配置文件(forge.config.js)进行如下设置:
const os = require('os')
const platform = os.platform()
const config = {
packagerConfig: {
// 可以将 ffmpeg 目录打包到 asar 目录外面
extraResource: [`./src/main/ffmpeg/`]
}
}
(2)开发和生产环境,获取二进制程序路径方法是不一样的 可以采用如下代码进行动态获取:
import { app } from 'electron'
import os from 'os'
import path from 'path'
const platform = os.platform()
const dir = app.getAppPath()
let basePath = ''
if(app.isPackaged) basePath = path.join(process.resourcesPath)
else basePath = path.join(dir, 'ffmpeg')
const isWin = platform === 'win32'
// ffmpeg 二进制程序路径
const ffmpegPath = path.join(basePath, `${platform}`, `ffmpeg${isWin ? '.exe' : ''}`)
如何对跨平台二进制文件进行按需构建呢?
比如桌面应用中用到了 ffmpeg , 它需要有 windows 、 mac 和 linux 的下载二进制。在打包的时候,如果不做按需构建,则会将 3 个二进制文件全部打到构建中,这样会让应用体积增加很多。
可以在 forge.config.js 配置文件中进行如下配置,即可完成按需构建,代码如下:
const platform = os.platform()
const config = {
packagerConfig: {
extraResource: [`./src/main/ffmpeg/${platform}`]
},
}
通过 platform 变量来把对应系统的二进制打到构建中,即可完成对二进制文件的按需构建。
主要是构建速度和构建体积优化,构建速度这块不好优化。本文重点说下构建体积优化,这里拿 mac 系统举例说明, 在 electron 应用打包后,查看应用包内容,如下图所示:
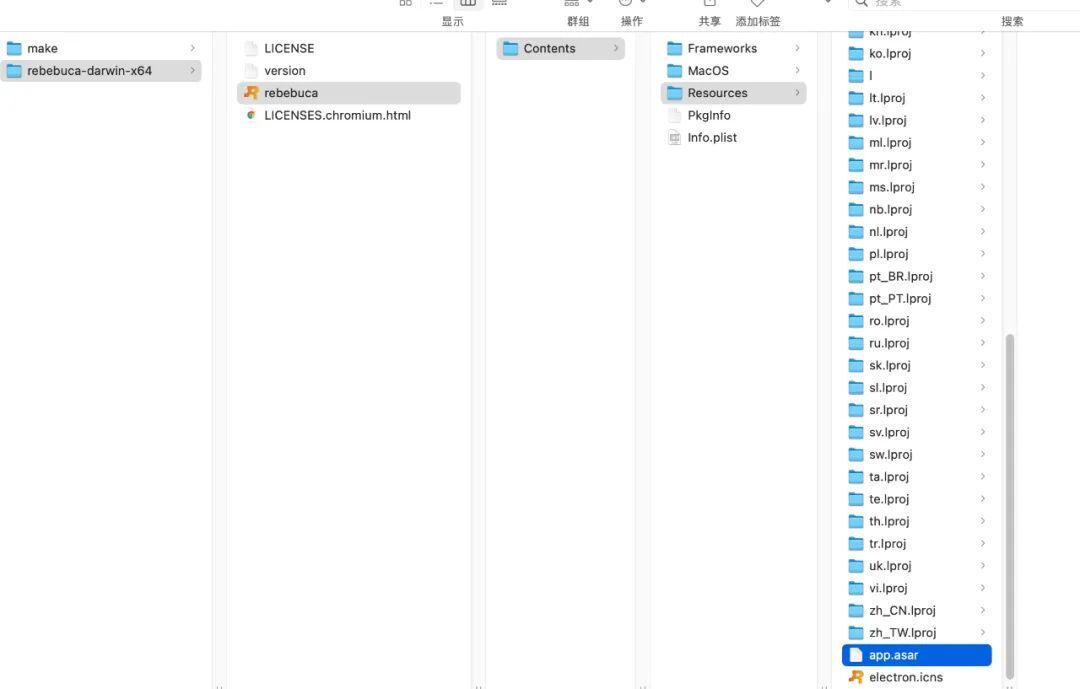
可以看到有一个 app.asar 文件,这个文件用 asar 解压后可以看到有以下内容:

可以看出 asar 中的文件,就是我们构建后的项目代码,从图中可以看到有 node_modules 目录, 这是因为在 electron 构建机制中,会自动把 dependencies 的依赖全部打到 asar 中。
所以结合上述分析,我们的优化措施有以下4点:
这里提下第 4 点,如何对 node_modules 进行清理精简呢?
如果是 yarn 安装的依赖,我们可以在根目录使用下面命令进行精简:
yarn autoclean -I
yarn autoclean -F
如果是 pnpm 安装的依赖,第 4 点应该不起作用了。我在项目中使用 yarn 安装依赖,然后执行上述命令后,发现打包体积减少了 6M , 虽然不多,但也还可以。
至此,构建功能就介绍完了。
本章节主要分为以下两个方面:
下面将依次介绍上述两种更新
通过下载最新的包或者 zip 文件,进行软件更新,需要替换所有的文件。
整体设计流程图如下:
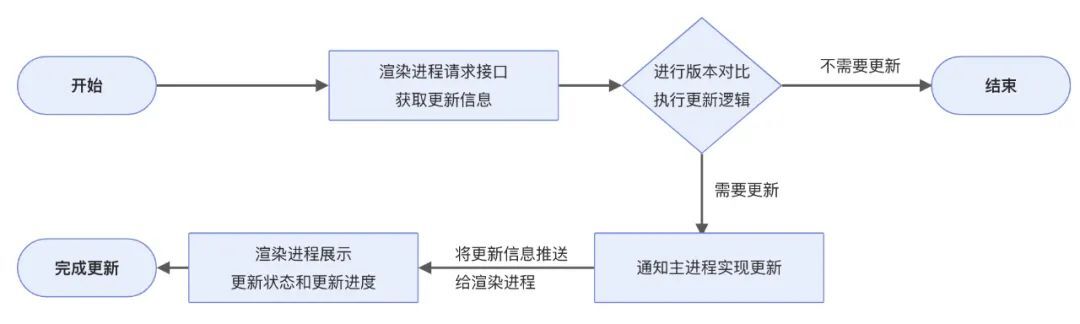
按照流程图去实现,我们需要做以下事情:
- 开发服务端接口,用来返回应用最新版本信息
- 渲染进程使用 axios 等工具请求接口,获取最新版本信息
- 封装更新逻辑,用来对接口返回的版本信息进行综合比较,判断是否更新
- 通过 ipc 通信将更新信息传递给主进程
- 主进程通过 electron-updater 进行全量更新
- 将更新信息通过 ipc 推送给渲染进程
- 渲染进程向用户展示更新信息,若更新成功,则弹出弹窗告诉用户重启应用,完成软件更新
通过拉取最新的渲染层打包文件,覆盖之前的渲染层代码,完成软件更新,此方案只需替换渲染层代码,无需替换所有文件。
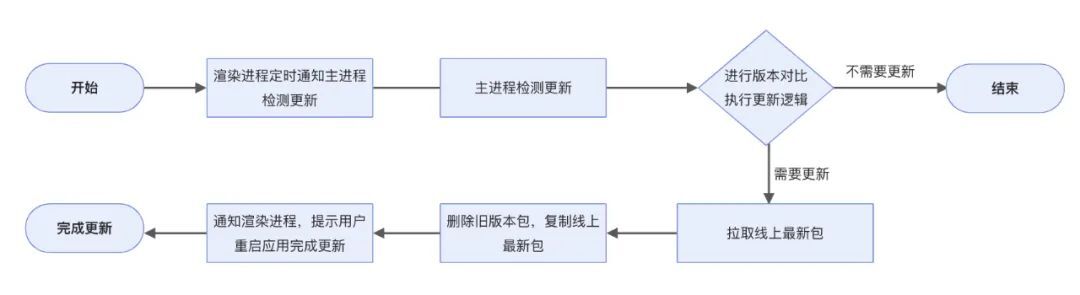
按照流程图去实现,我们需要做以下事情
- 渲染进程定时通知主进程检测更新
- 主进程检测更新
- 需要更新,则拉取线上最新包
- 删除旧版本包,复制线上最新包,完成增量更新
- 通知渲染进程,提示用户重启应用完成更新
全量更新和增量更新各有优势,多数情况下,采用增量更新来提高用户更新体验,同时使用全量更新作为兜底更新方案。
至此,更新功能就介绍完了。
分为以下3个方面:
构建优化在上文内容中,已经详细介绍过了,这里不再介绍,下面将介绍 启动时优化 和 运行时优化。
- 使用 v8-compile-cache 缓存编译代码
- 优先加载核心功能,非核心功能动态加载
- 使用多进程,多线程技术
- 采用 asar 打包:会加快启动速度
- 增加视觉过渡:loading + 骨架屏
使用 V8 缓存数据,为什么要这么做呢?
因为 electorn 使用 V8 引擎运行 js , V8 运行 js 时,需要先进行解析和编译,再执行代码。其中,解析和编译过程消耗时间多,经常导致性能瓶颈。而 V8 缓存功能,可以将编译后的字节码缓存起来,省去下一次解析、编译的时间。
主要使用 v8-compile-cache 来缓存编译的代码,做法很简单:在需要缓存的地方加一行
require('v8-compile-cache')
其他使用方法请查看此链接文档 https://www.npmjs.com/package/v8-compile-cache(opens new window)
伪代码如下:
export function share() {
const kun = require('kun')
kun()
}
用一个思维导图来完整阐述如何进行 Web 性能优化,如下图所示:
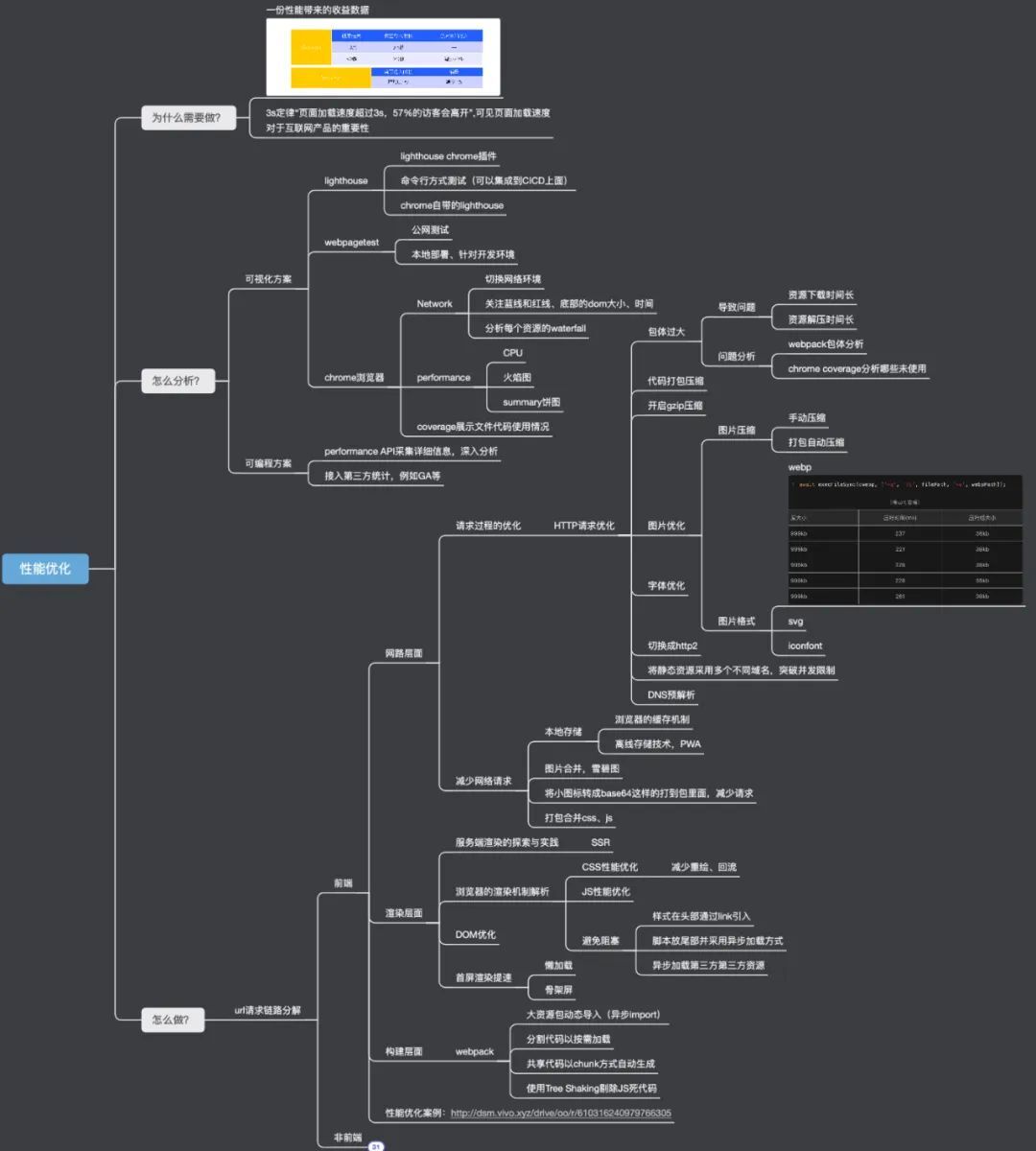
上图基本包含了性能优化的核心关键点和内容,大家可以以此作为参考,去做性能优化。
核心方案就是将运行时耗时、计算量大的功能交给新开的 node 进程去执行处理。
伪代码如下:
const { fork } = require('child_process')
let { app } = require('electron')
function createProcess(socketName) {
process = fork(`xxxx/server.js`, [
'--subprocess',
app.getVersion(),
socketName
])
}
const initApp = async () => {
// 其他初始化代码...
let socket = await findSocket()
createProcess(socket)
}
app.on('ready', initApp)
通过以上代码,将耗时、计算量大的功能,放在 server.js ,然后再 fork 到新开 node 进程中进行处理。
至此,性能优化就介绍完了。
质量保障的全流程措施如下图所示:
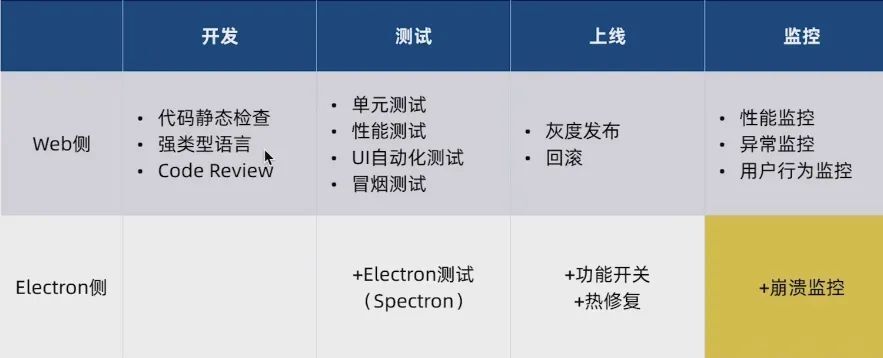
本章节主要介绍以下3个方面:
下面将会依次介绍上述内容。
自动化测试是什么?

上图是做自动化测试一个完整步骤,大家可以看图领会。
自动化测试主要分为 单元测试、集成测试、端到端测试,三者关系如下图所示:

一般情况下,作为软件工程师,我们做到一定的单元测试就可以了。而且从我目前经验来说,如果是写业务性质的项目,基本上不会编写测试相关的代码。自动化测试主要是用来编写库、框架、组件等需要作为单独个体提供给他人使用的。
electron 的测试工具推荐 vitest 、 spectron 。具体用法参考官网文档即可,没什么特别的技巧。
对于 GUI 软件,尤其桌面端软件来说,崩溃率非常重要,因此需要对崩溃进行监控。
崩溃监控原理如下图所示:
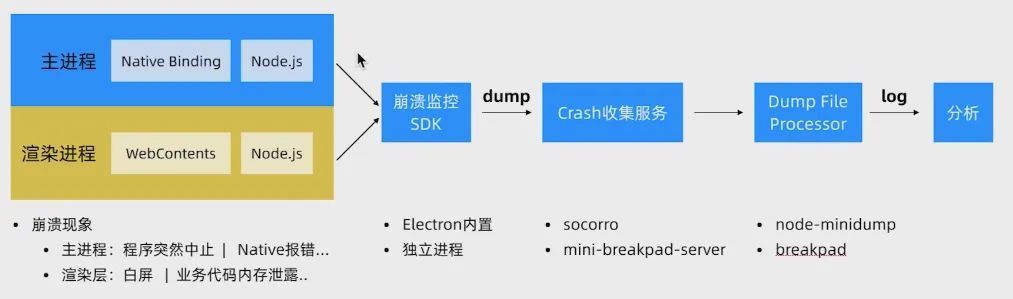
崩溃监控技巧
崩溃监控做好后,如果发生崩溃,该如何治理崩溃呢?
崩溃治理难点:
崩溃治理技巧:
俗话说的好,安全大于天,保证 electron 应用的安全也是一项重要的事情,本章节将安全分为以下 5 个方面:
下面将会依次介绍上述内容。
目前 electron 在源码安全做的不好,官方只用 asar 做了一下很没用的源码保护,到底有多没用呢?
你只需要下载 asar 工具,然后对 asar 文件进行解压就可以得到里面的源码了,如下图所示:
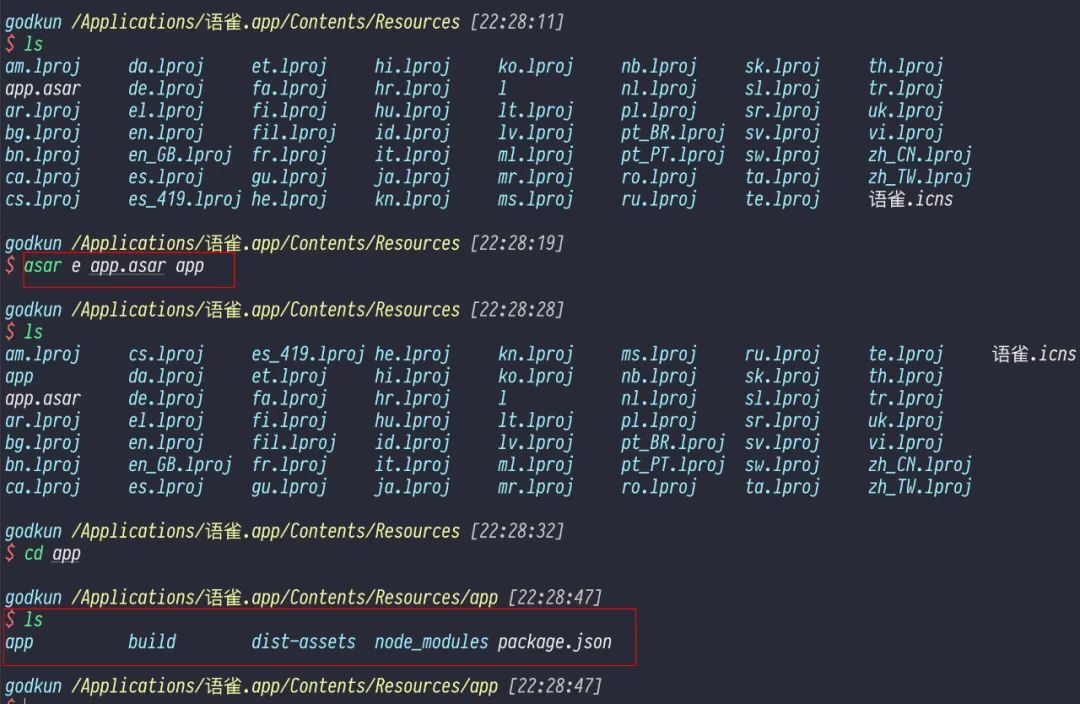
通过图中操作即可看到语雀应用的源码。上面提到的 asar 是什么呢?
asar 是一种将多个文件合并成一个文件的类 tar 风格的归档格式。Electron 可以无需解压整个文件,即可从其中读取任意文件内容。
asar 技术原理:
可以直接看 electron 源码,都是 ts 代码,容易阅读,源码如下图所示:
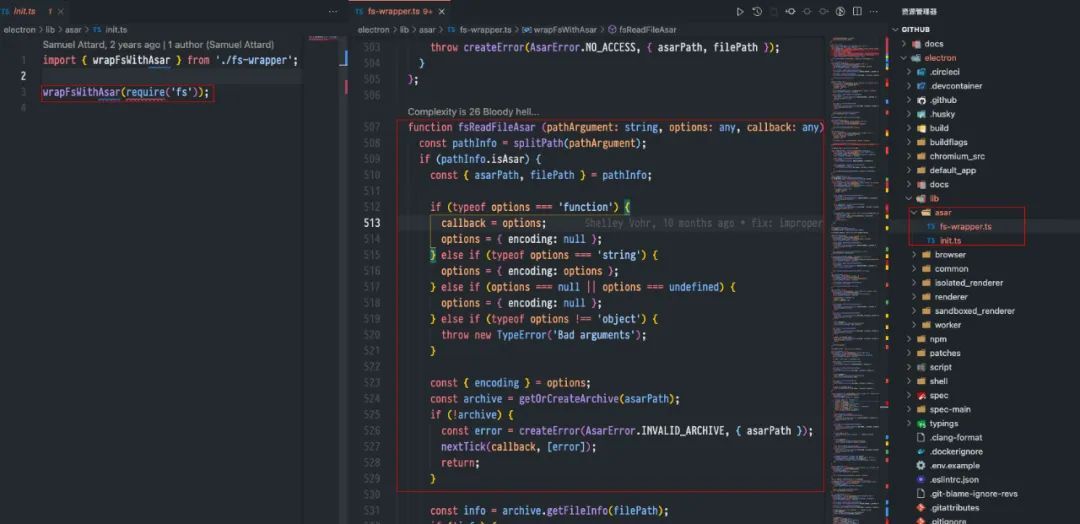
从图中可以看出, asar 的核心实现就是对 nodejs 的 fs 模块进行重写。
避免源码泄漏,按照从低到高的源码安全,可以分为以下程度
其中,Language bindings 是最高的源码安全措施,其实使用 C++ 或 Rust 代码来编写 electron 应用代码,通过将 C++ 或 Rust 代码编译成二进制代码后,破译的难度会变高。这里我说下如何使用 Rust 去编写 electron 应用代码。
方案:使用 napi-rs 作为工具去编写,如下图所示:
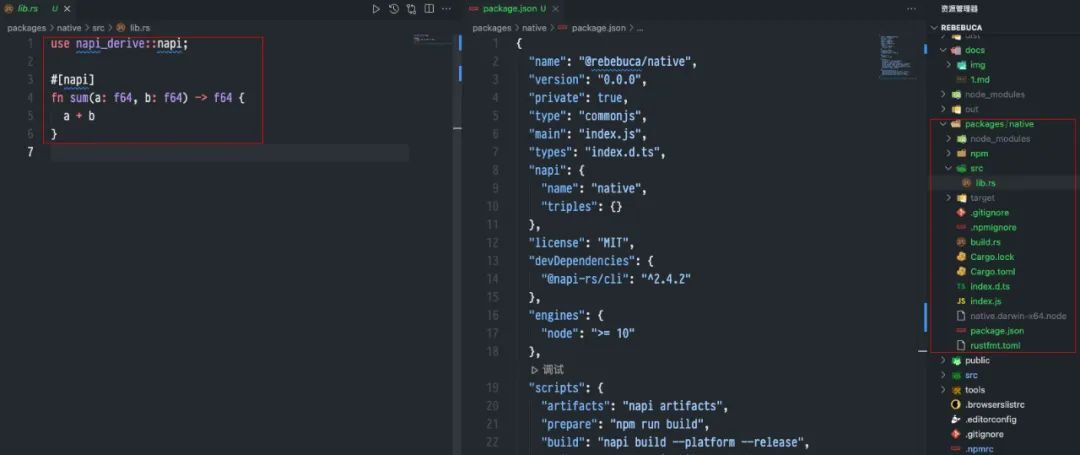
我们采用 pnpm-workspace 去管理 Rust 代码,使用 napi-rs ,比如我们写一个 sum 函数,rs代码如下:
fn sum(a: f64, b: f64) -> f64 {
a + b
}
此时我们加上 napi 装饰代码,如下所示:
use napi_derive::napi;
#[napi]
fn sum(a: f64, b: f64) -> f64 {
a + b
}
在通过 napi-cli 将上述代码编译成 node 可以调用的二进制代码。
编译后,在electron使用上述代码,如下所示:
import { sum as rsSum } from '@rebebuca/native'
// 输出 7
console.log(rsSum(2, 5))
napi-rs 的使用请阅读官方文档,地址是:https://napi.rs/(opens new window)
至此,language bindings 的阐述就完成了。我们通过这种方式,可以完成对重要功能的源码保护。
目前熟知的一个安全问题是克隆攻击,此问题的主流解决方案是将用户认证信息和应用设备指纹进行绑定,整体流程如如下图所示:

应用设备指纹生成:可以用上文阐述的 napi-rs 方案去实现
用户认证信息和设备指纹绑定:使用服务端去实现
主要有以下措施:
以上具体细节不再介绍,自行搜索上述方案。除此之外,还有个官方推荐的最佳安全实践,有空可以看看,地址如下:https://www.electronjs.org/docs/latest/tutorial/security(opens new window)
至此,安全这块就介绍完了。
本文介绍了我们对桌面端技术的调研、确定技术选型,以及用 electron 开发过程中,总结的实践经验,如构建、性能优化、质量保障、安全等。希望对读者在开发桌面应用过程中有所帮助,文章难免有不足和错误的地方,欢迎读者在评论区交流。
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub