在采用FPGA电路设计中,首先要进行芯片选型。而芯片选型都是根据你的设计需求来找器件。需求可能涉及以下几个方面:
1. 时钟速度(逻辑时钟、IO时钟等),不同Family能达到的速度不同
2. 时钟数量,不同Family的时钟资源不同
3. IO数目和支持的电平标准
4. 板上封装(焊接方式、体积大小)
5. 其他各种硬核功能(PowerPC,MGT,GTP,TEMAC等)
6. 功耗要求,顺便考虑散热空间
7. 非易失性要求,Spartan 3A系列有内置Flash
8. 产品调试和升级扩容空间,比如调试时用较大的器件,完成后改用同样封装较小规模的器件

6系列用ISE开发,7系列用vivado。
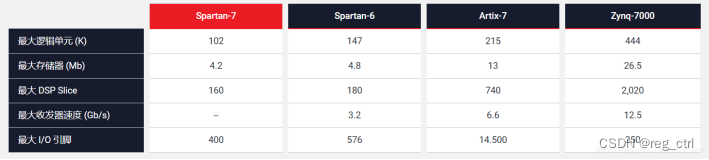
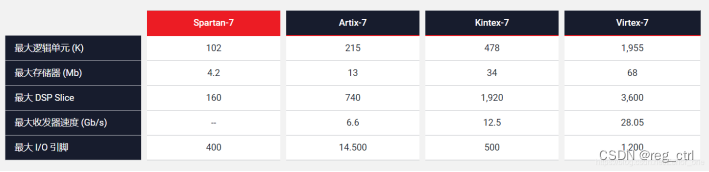
关于各系列的片上资源,可直接参考各系列的芯片选型手册:
Cost-Optimized Portfolio Product Tables and Product Selection Guide
All Programmable 7Series Product Selection Guide
UltraSCALE FPGA Product Tables and Product Selection Guide
Altera 的主流FPGA分为两大类,一种侧重低成本应用,容量中等,性能可以满足一般的逻辑设计要求,如Cyclone,CycloneII;还有一种侧重于高性能应用,容量大,性能能满足各类高端应用,如Startix,StratixII等,用户可以根据自己实际应用要求进行选择。在性能可以满足的情况下,优先选择低成本器件
器件系列 + 器件类型(是否含有高速串行收发器) + LE 逻辑单元数量 + 封装类型 + 高速串行收发器的数量(没有则不写) + 引脚数目 + 器件正常使用的温度范围 + 器件的速度等级 + 后缀举例:
EP4CE10F17C8N 为例
UG-112:Device Package User Guide
UG-116:Device Reliability Report
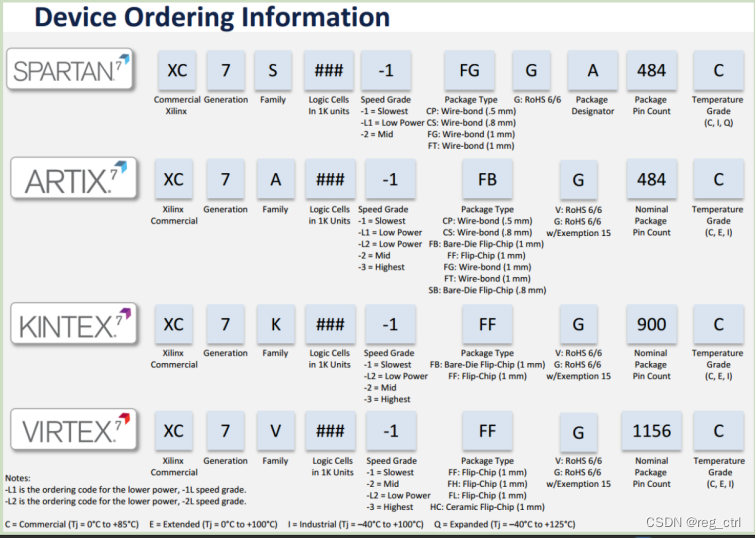
譬如,对于编号为XC4VLX60-1FFG668CS2的FPGA,器件类型是XC4VLX60-10,封装是FFG668CS2。具体而言
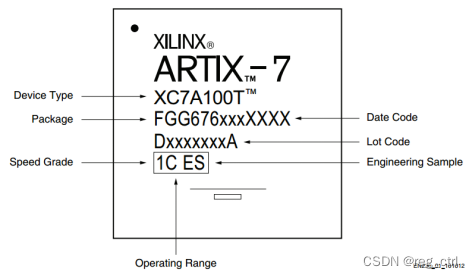
序号越低,速度等级越高 这是Altera FPGA的排序方法,“序号越高,速度等级也越高”这是Xilinx FPGA的排序方法
在芯片生产出来之后,实际测试标定出来的;速度快的芯片在总产量中的比率低,价格也就相应地高。
一般来讲,提高一个速度等级将带来 12%到 15%的性能提升,但是器件的成本却增加了 20%大 30%。如果利用设计结构来将性能提升12%到 15%(通过增加额外的流水线),那么就可以降低速度等级,从而节约20%大 30%的成本;

参考:FPGA开发者看过来:IO是怎么命名的?上电又有什么规律?__凤凰网
命名方式多样,A13,B14,BANK34,BANK12,MIO0,EMIO···。这是FPGA的特点,FPGA可以兼容多种不同的电压标准,也有丰富的IO。
FPGA的IO物理命名规则,也就是我们做管脚约束时候的命名,芯片通常是长方体或者正方体,所以命名通常采用字母+数字组合的方式。
xilinx的命名(xilinx的文档是行业标杆,其它FPGA厂家的资料多多少少会参考xilinx)通常xilinx 的功能命名格式为:IO_LXXY#/IO_XX。其中:
例如:IO_L13P_T2_MRCC_12,这是一个用户IO,支持差分信号,是BANK12的第13对差分的P端口,与此同时它也是全局时钟网络输入管脚(MRCC是全局时钟网络)
除了FPGA的用户IO外,还有很多其他的功能IO,如下载接口,模式选择接口,还有MRCC,最重要的是FPGA的电源引脚。
Zynq有两套独立的供电系统,(PS和PL),因此没有上电时序需求
当我在我的Rails应用程序根目录中运行rakedoc:app时,API文档是使用/doc/README_FOR_APP作为主页生成的。我想向该文件添加.rdoc扩展名,以便它在GitHub上正确呈现。更好的是,我想将它移动到应用程序根目录(/README.rdoc)。有没有办法通过修改包含的rake/rdoctask任务在我的Rakefile中执行此操作?是否有某个地方可以查找可以修改的主页文件的名称?还是我必须编写一个新的Rake任务?额外的问题:Rails应用程序的两个单独文件/README和/doc/README_FOR_APP背后的逻辑是什么?为什么不只有一个?
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
Rails中有没有一种方法可以提取与路由关联的HTTP动词?例如,给定这样的路线:将“users”匹配到:“users#show”,通过:[:get,:post]我能实现这样的目标吗?users_path.respond_to?(:get)(显然#respond_to不是正确的方法)我最接近的是通过执行以下操作,但它似乎并不令人满意。Rails.application.routes.routes.named_routes["users"].constraints[:request_method]#=>/^GET$/对于上下文,我有一个设置cookie然后执行redirect_to:ba
我在尝试使用Nokogiri构建XML文档时遇到了一个小问题。我想将我的元素之一称为“文本”(请参阅下面粘贴代码的最底部)。通常,要创建一个新元素,我会执行类似以下的操作xml.text--但它似乎是.text是Nokogiri已经用来做其他事情的方法。因此,当我写这行时xml.textNokogiri没有创建名为的新元素但只是写了意味着成为元素内容的文本。我怎样才能让Nokogiri实际制作一个名为的元素??builder=Nokogiri::XML::Builder.newdo|xml|xml.TEI("xmlns"=>"http://www.tei-c.org/ns/1.0"
我在一个简单的RailsAPI中有以下Controller代码:classApi::V1::AccountsControllerehead:not_foundendendend问题在于,生成的json具有以下格式:{id:2,name:'Simpleaccount',cash_flows:[{id:1,amount:34.3,description:'simpledescription'},{id:2,amount:1.12,description:'otherdescription'}]}我需要我生成的json是camelCase('cashFlows'而不是'cash_flows'
如果我生成一个名为"product"的脚手架,当我使用它们编写我的应用程序时,它们之间有什么区别?@products,@product,@Product,@Products,产品,Product、product和products(我很确定这些并没有全部用到,但它至少应该让我知道我在做什么'指的是)。对于@/capitalization/plurality的每个组合的含义,我似乎找不到简单的解释。将不胜感激。 最佳答案 你可以阅读Rubystyleguide和Railsstyleguide,您会得到问题的答案。
我有以下代码#coloursarandomcellwithacorrectcolourdefcolour_random!whiletruedocol,row=rand(columns),rand(rows)cell=self[row,col]ifcell.empty?thencell.should_be_filled??cell.colour!(1):cell.colour!(0)breakendendend做什么并不重要,尽管它应该很明显。关键是Rubocop给了我一个警告Neveruse'do'withmulti-line'while为什么我不应该那样做?那我该怎么办呢?
在我的应用程序中我有classUserincludeUser::FooendUser::Foo定义在app/models/user/foo.rb现在我正在使用一个定义了自己的Foo类的库。我收到此错误:warning:toplevelconstantFooreferencedbyUser::FooUser仅引用具有完整路径的Foo,User::Foo,而Foo实际上从来没有指的是Foo。这是怎么回事?更新:才想起我之前遇到过同样的问题,在问题1中看到这里:HowdoIrefertoasubmodule's"fullpath"inruby? 最佳答案
考虑Ruby类Foo::Bar。惯例是将“Foo”命名空间作为一个模块,但它也可以很容易地作为一个类:moduleFoo;classBar;end;end对比:classFoo;classBar;end;end在第二种情况下,Bar不是Foo的内部类,它只是在Foo的单例上定义的另一个常量。在这两种情况下,父类(superclass)都是Object并且它们只包含Kernel模块。它们的祖先链是相同的。因此,除了您可以根据其类使用Foo进行的操作(如果是类则实例化,如果是模块则扩展/包含),命名空间的性质是否对有任何影响酒吧?是否有令人信服的理由选择其中一个名称间距而不是另一个?我看到