Hive分区的概念与传统关系型数据库分区不一样。
传统数据库的分区方式:就oracle而言,分区独立存在于段里,里面存储真实的数据,在数据进行插入的时候自动分配分区。
Hive的分区方式:因为Hive实际是存储在HDFS上的抽象,Hive的一个分区名对应一个目录名,子分区名就是子目录名,并非一个实际字段。
因此能够这样理解,当在插入数据的时候指定分区,其实就是新建一个目录或者子目录,或者在原有的目录上添加数据文件。
目录

Hive分区是在建立表的时候用Partitioned by 关键字定义的,但要注意,Partitioned by子句中定义的列是表中正式的列,可是Hive下的数据文件中并不包含这些列,由于它们是目录名。
建立一张静态分区表par_tab,单个分区
create table par_tab (name string,nation string) partitioned by (sex string) row format delimited fields terminated by ',';这时候经过desc查看的表结构以下性能
hive> desc par_tab;
OK
name string
nation string
sex string
# Partition Information
# col_name data_type comment
sex string
Time taken: 0.038 seconds, Fetched: 8 row(s)准备本地数据文件par_tab.txt,内容 “名字/国籍”,将以性别(sex)做为分区
jan,china
mary,america
lilei,china
heyong,china
yiku,japan
emoji,japan把数据插入到表(其实load操做至关于把文件移动到HDFS的Hive目录下)
load data local inpath '/home/hadoop/files/par_tab.txt' into table par_tab partition (sex='man');这时候在hive下查询par_tab表,变成了3列
hive> select * from par_tab;
OK
jan china man
mary america man
lilei china man
heyong china man
yiku japan man
emoji japan man
Time taken: 0.076 seconds, Fetched: 6 row(s)查看par_tab目录结构
[hadoop@hadoop001 files]$ hadoop dfs -lsr /user/hive/warehouse/par_tab drwxr-xr-x - hadoop supergroup 0 2017-03-29 08:25 /user/hive/warehouse/par_tab/sex=man -rwxr-xr-x 1 hadoop supergroup 71 2017-03-29 08:25 /user/hive/warehouse/par_tab/sex=man/par_tab.txt
能够看到,在新建分区表的时候,系统会在hive数据仓库默认路径/user/hive/warehouse/下建立一个目录(表名),再建立目录的子目录sex=man(分区名),最后在分区名下存放实际的数据文件。
若是再插入另外一个数据文件数据:
lily,china
nancy,china
hanmeimei,america插入数据
load data local inpath '/home/hadoop/files/par_tab_wm.txt' into table par_tab partition (sex='woman');查看par_tab表目录结构
[hadoop@hadoop001 files]$ hadoop dfs -lsr /user/hive/warehouse/par_tab drwxr-xr-x - hadoop supergroup 0 2017-03-29 08:25 /user/hive/warehouse/par_tab/sex=man -rwxr-xr-x 1 hadoop supergroup 71 2017-03-29 08:25 /user/hive/warehouse/par_tab/sex=man/par_tab.txt drwxr-xr-x - hadoop supergroup 0 2017-03-29 08:35 /user/hive/warehouse/par_tab/sex=woman -rwxr-xr-x 1 hadoop supergroup 41 2017-03-29 08:35 /user/hive/warehouse/par_tab/sex=woman/par_tab_wm.txt
最后查看两次插入的结果,包含了man和woman
hive> select * from par_tab;
OK
jan china man
mary america man
lilei china man
heyong china man
yiku japan man
emoji japan man
lily china woman
nancy china woman
hanmeimei america woman
Time taken: 0.136 seconds, Fetched: 9 row(s)由于分区列是表实际定义的列,因此查询分区数据时
hive> select * from par_tab where sex='woman';
OK
lily china woman
nancy china woman
hanmeimei america woman
Time taken: 0.515 seconds, Fetched: 3 row(s)下面建立一张静态分区表par_tab_muilt,多个分区(性别+日期)
hive> create table par_tab_muilt (name string, nation string) partitioned by (sex string,dt string) row format delimited fields terminated by ',' ;
hive> load data local inpath '/home/hadoop/files/par_tab.txt' into table par_tab_muilt partition (sex='man',dt='2017-03-29'); [hadoop@hadoop001 files]$ hadoop dfs -lsr /user/hive/warehouse/par_tab_muilt drwxr-xr-x - hadoop supergroup 0 2017-03-29 08:45 /user/hive/warehouse/par_tab_muilt/sex=man drwxr-xr-x - hadoop supergroup 0 2017-03-29 08:45 /user/hive/warehouse/par_tab_muilt/sex=man/dt=2017-03-29 -rwxr-xr-x 1 hadoop supergroup 71 2017-03-29 08:45 /user/hive/warehouse/par_tab_muilt/sex=man/dt=2017-03-29/par_tab.txt
可见,新建表的时候定义的分区顺序,决定了文件目录顺序(谁是父目录谁是子目录),正由于有了这个层级关系,当查询全部man的时候,man如下的全部日期下的数据都会被查出来。若是只查询日期分区,但父目录sex=man和sex=woman都有该日期的数据,那么Hive会对输入路径进行修剪,从而只扫描日期分区,性别分区不做过滤(即查询结果包含了全部性别)。
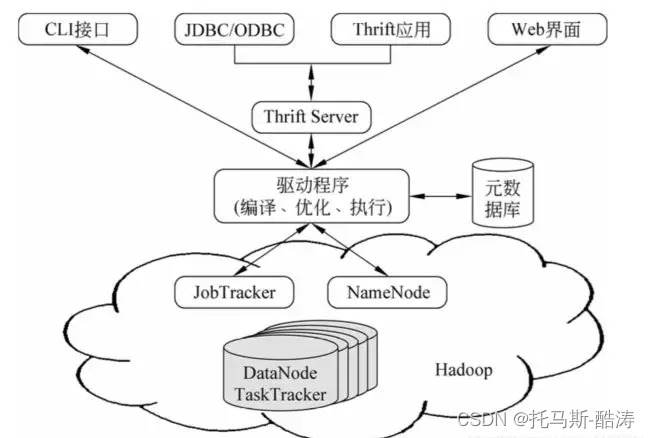
若是用上述的静态分区,插入的时候必须首先要知道有什么分区类型,并且每一个分区写一个load data,比较麻烦。使用动态分区可解决以上问题,其能够根据查询获得的数据动态分配到分区里。其实动态分区与静态分区区别就是不指定分区目录,由系统本身选择。
首先,启动动态分区功能
hive> set hive.exec.dynamic.partition=true;假设已有一张表par_tab,前两列是名称name和国籍nation,后两列是分区列,性别sex和日期dt,数据以下
hive> select * from par_tab;
OK
lily china man 2013-03-28
nancy china man 2013-03-28
hanmeimei america man 2013-03-28
jan china man 2013-03-29
mary america man 2013-03-29
lilei china man 2013-03-29
heyong china man 2013-03-29
yiku japan man 2013-03-29
emoji japan man 2013-03-29
Time taken: 1.141 seconds, Fetched: 9 row(s)我把这张表的内容直接插入到另外一张表par_dnm中,并实现sex为静态分区,dt动态分区(不指定究竟是哪日,让系统本身分配决定)
hive> insert overwrite table par_dnm partition(sex='man',dt)
> select name, nation, dt from par_tab;插入后看下目录结构
drwxr-xr-x - hadoop supergroup 0 2017-03-29 10:32 /user/hive/warehouse/par_dnm/sex=man drwxr-xr-x - hadoop supergroup 0 2017-03-29 10:32 /user/hive/warehouse/par_dnm/sex=man/dt=2013-03-28 -rwxr-xr-x 1 hadoop supergroup 41 2017-03-29 10:32 /user/hive/warehouse/par_dnm/sex=man/dt=2013-03-28/000000_0 drwxr-xr-x - hadoop supergroup 0 2017-03-29 10:32 /user/hive/warehouse/par_dnm/sex=man/dt=2013-03-29 -rwxr-xr-x 1 hadoop supergroup 71 2017-03-29 10:32 /user/hive/warehouse/par_dnm/sex=man/dt=2013-03-29/000000_0
再查看分区数
hive> show partitions par_dnm;
OK
sex=man/dt=2013-03-28
sex=man/dt=2013-03-29
Time taken: 0.065 seconds, Fetched: 2 row(s)证实动态分区成功。
注意,动态分区不容许主分区采用动态列而副分区采用静态列,这样将致使全部的主分区都要建立副分区静态列所定义的分区。
动态分区能够容许全部的分区列都是动态分区列,可是要首先设置一个参数hive.exec.dynamic.partition.mode :
hive> set hive.exec.dynamic.partition.mode;
hive.exec.dynamic.partition.mode=strict它的默认值是strict,即不容许分区列所有是动态的,这是为了防止用户有可能原意是只在子分区内进行动态建分区,可是因为疏忽忘记为主分区列指定值了,这将致使一个dml语句在短期内建立大量的新的分区(对应大量新的文件夹),对系统性能带来影响。 因此要设置:
hive> set hive.exec.dynamic.partition.mode=nostrict;
rpartition和partition有什么区别?我已经阅读了文档,但我认为它们是一样的。只是那些出现在后来的ruby版本中吗? 最佳答案 以下示例将有助于识别差异:"abccba".partition("b")#=>["a","b","ccba"]"abccba".rpartition("b")#=>["abcc","b","a"]所以区别在于rpartition搜索最右边的匹配项,而不是最左边的匹配项。 关于Rubyrpartition与分区?,我们在StackOverflow
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
有没有办法在Ruby中动态创建数组?例如,假设我想遍历用户输入的书籍数组:books=gets.chomp用户输入:"TheGreatGatsby,CrimeandPunishment,Dracula,Fahrenheit451,PrideandPrejudice,SenseandSensibility,Slaughterhouse-Five,TheAdventuresofHuckleberryFinn"我把它变成一个数组:books_array=books.split(",")现在,对于用户输入的每一本书,我想用Ruby创建一个数组。伪代码来做到这一点:x=0books_array.
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
我正在尝试动态构建一个多维数组。我想要的基本上是这样的(为简单起见写出来):b=0test=[[]]test[b]这给了我错误:NoMethodError:undefinedmethod`test=[[],[],[]]而且它工作正常,但在我的实际使用中,我不会事先知道需要多少个数组。有一个更好的方法吗?谢谢 最佳答案 不需要像您正在使用的索引变量。只需将每个数组附加到您的test数组:irb>test=[]=>[]irb>test[["a","b","c"]]irb>test[["a","b","c"],["d","e","f"]]
如何只加载map边界内的标记gmaps4rails?当然,在平移和/或缩放后加载新的。与此直接相关的是,如何获取map的当前边界和缩放级别? 最佳答案 我是这样做的,我只在用户完成平移或缩放后替换标记,如果您需要不同的行为,请使用不同的事件监听器:在你看来(index.html.erb):{"zoom"=>15,"auto_adjust"=>false,"detect_location"=>true,"center_on_user"=>true}},false,true)%>在View的底部添加:functiongmaps4rail
如何在对象上调用方法名称的嵌套哈希?例如,给定以下哈希:hash={:a=>{:b=>{:c=>:d}}}我想创建一个方法,给定上面的散列,执行以下操作:object.send(:a).send(:b).send(:c).send(:d)我的想法是我需要从一个未知的关联中获取一个特定的属性(这个方法不知道,但程序员知道)。我希望能够指定一个方法链来以嵌套哈希的形式检索该属性。例如:hash={:manufacturer=>{:addresses=>{:first=>:postal_code}}}car.execute_method_hash(hash)=>90210
我有一个ruby程序,我想接受用户创建的方法,并使用该名称创建一个新方法。我试过这个:defmethod_missing(meth,*args,&block)name=meth.to_sclass我收到以下错误:`define_method':interningemptystring(ArgumentError)in'method_missing'有什么想法吗?谢谢。编辑:我以不同的方式让它工作,但我仍然很好奇如何以这种方式做到这一点。这是我的代码:defmethod_missing(meth,*args,&block)Adder.class_evaldodefine_method
假设我们有A、B、C类。Adefself.inherited(sub)#metaprogramminggoeshere#takeclassthathasjustinheritedclassA#andforfooclassesinjectprepare_foo()as#firstlineofmethodthenrunrestofthecodeenddefprepare_foo#=>prepare_foo()neededhere#somecodeendendBprepare_foo()neededhere#somecodeendend如您所见,我正在尝试将foo_prepare()调用注入