本小节介绍应用程序的 ApplicationMaster 在 NodeManager 成功启动并向 ResourceManager 注册后,向 ResourceManager 请求资源(Container)到获取到资源的整个过程,以及 ResourceManager 内部涉及的主要工作流程。
整个过程可看做以下两个阶段的送代循环:
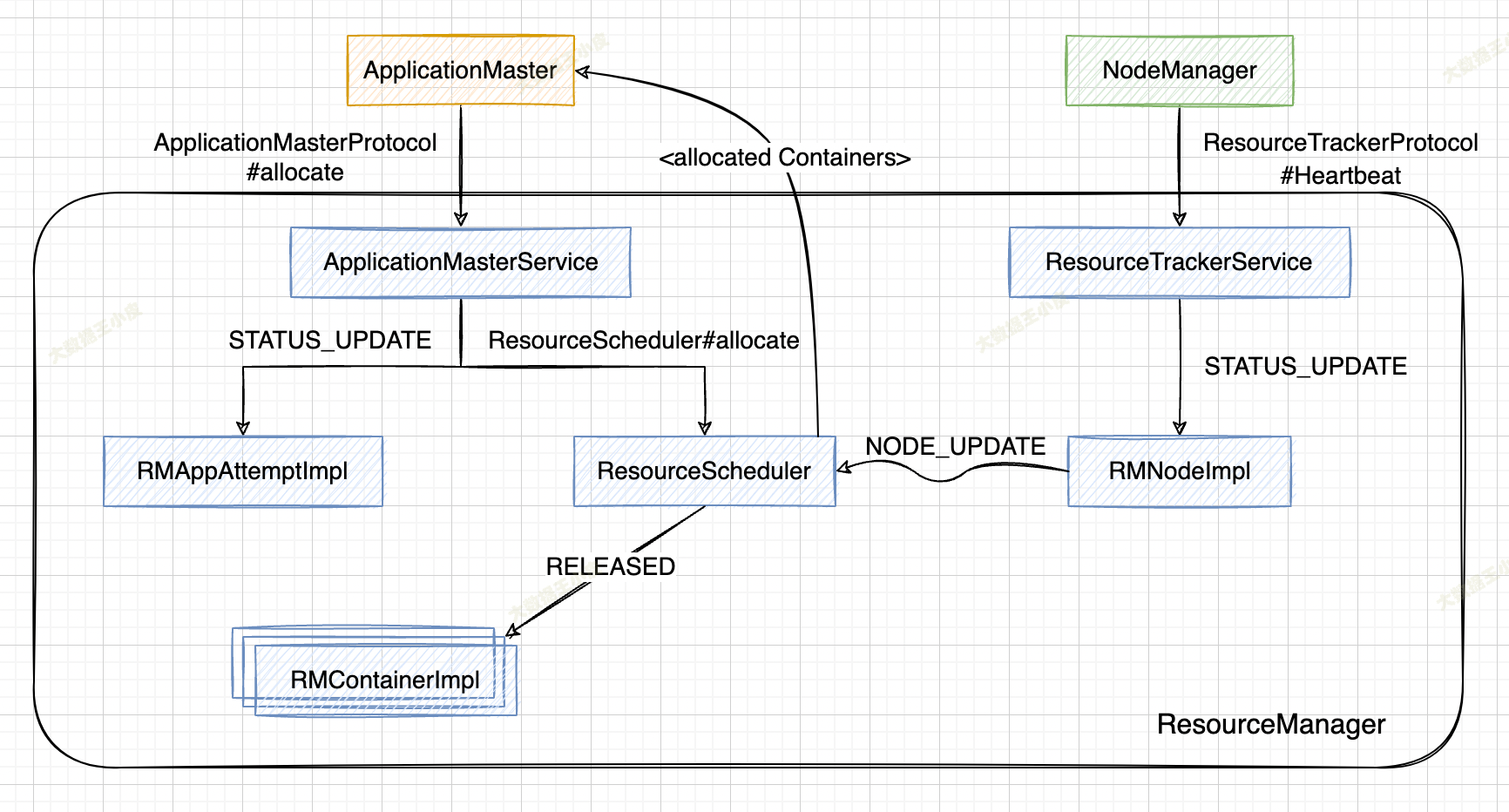
1、ApplicationMaster 通过 RPC 函数 ApplicationMasterProtocol#allocate 向 ResourceManager 汇报资源需求(由于该函数被周期性调用,我们通常也称之为“心跳”),包括新的资源需求描述、待释放的 Container 列表、请求加入黑名单的节点列表、请求移除黑名单的节点列表等。
public AllocateResponse allocate(AllocateRequest request) {
// Send the status update to the appAttempt.
// 发送 RMAppAttemptEventType.STATUS_UPDATE 事件
this.rmContext.getDispatcher().getEventHandler().handle(
new RMAppAttemptStatusupdateEvent(appAttemptId, request.getProgress()));
// 从 am 心跳 AllocateRequest 中取出新的资源需求描述、待释放的 Container 列表、黑名单列表
List<ResourceRequest> ask = request.getAskList();
List<ContainerId> release = request.getReleaseList();
ResourceBlacklistRequest blacklistRequest = request.getResourceBlacklistRequest();
// 接下来会做一些检查(资源申请量、label、blacklist 等)
// 将资源申请分割(动态调整 container 资源量)
// Split Update Resource Requests into increase and decrease.
// No Exceptions are thrown here. All update errors are aggregated
// and returned to the AM.
List<UpdateContainerRequest> increaseResourceReqs = new ArrayList<>();
List<UpdateContainerRequest> decreaseResourceReqs = new ArrayList<>();
List<UpdateContainerError> updateContainerErrors =
RMServerUtils.validateAndSplitUpdateResourceRequests(rmContext,
request, maximumCapacity, increaseResourceReqs,
decreaseResourceReqs);
// 调用 ResourceScheduler#allocate 函数,将该 AM 资源需求汇报给 ResourceScheduler
// (实际是 Capacity、Fair、Fifo 等实际指定的 Scheduler 处理)
allocation =
this.rScheduler.allocate(appAttemptId, ask, release,
blacklistAdditions, blacklistRemovals,
increaseResourceReqs, decreaseResourceReqs);
}
2、ResourceManager 中的 ApplicationMasterService#allocate 负责处理来自 AM 的心跳请求,收到该请求后,会发送一个 RMAppAttemptEventType.STATUS_UPDATE 事件,RMAppAttemptImpl 收到该事件后,将更新应用程序执行进度和 AMLivenessMonitor 中记录的应用程序最近更新时间。
3、调用 ResourceScheduler#allocate 函数,将该 AM 资源需求汇报给 ResourceScheduler,实际是 Capacity、Fair、Fifo 等实际指定的 Scheduler 处理。
以 CapacityScheduler#allocate 实现为例:
// CapacityScheduler#allocate
public Allocation allocate(ApplicationAttemptId applicationAttemptId,
List<ResourceRequest> ask, List<ContainerId> release,
List<String> blacklistAdditions, List<String> blacklistRemovals,
List<UpdateContainerRequest> increaseRequests,
List<UpdateContainerRequest> decreaseRequests) {
// Release containers
// 发送 RMContainerEventType.RELEASED
releaseContainers(release, application);
// update increase requests
LeafQueue updateDemandForQueue =
updateIncreaseRequests(increaseRequests, application);
// Decrease containers
decreaseContainers(decreaseRequests, application);
// Sanity check for new allocation requests
// 会将资源请求进行规范化,限制到最小和最大区间内,并且规范到最小增长量上
SchedulerUtils.normalizeRequests(
ask, getResourceCalculator(), getClusterResource(),
getMinimumResourceCapability(), getMaximumResourceCapability());
// Update application requests
// 将新的资源需求更新到对应的数据结构中
if (application.updateResourceRequests(ask)
&& (updateDemandForQueue == null)) {
updateDemandForQueue = (LeafQueue) application.getQueue();
}
// 获取已经为该应用程序分配的资源
allocation = application.getAllocation(getResourceCalculator(),
clusterResource, getMinimumResourceCapability());
return allocation;
}
4、ResourceScheduler 首先读取待释放 Container 列表,向对应的 RMContainerImpl 发送 RMContainerEventType.RELEASED 类型事件,杀死正在运行的 Container;然后将新的资源需求更新到对应的数据结构中,之后获取已经为该应用程序分配的资源,并返回给 ApplicationMasterService。
1、NodeManager 将当前节点各种信息(container 状况、节点利用率、健康情况等)封装到 nodeStatus 中,再将标识节点的信息一起封装到 request 中,之后通过RPC 函数 ResourceTracker#nodeHeartbeat 向 ResourceManager 汇报这些状态。
// NodeStatusUpdaterImpl#startStatusUpdater
protected void startStatusUpdater() {
statusUpdaterRunnable = new Runnable() {
@Override
@SuppressWarnings("unchecked")
public void run() {
// ...
Set<NodeLabel> nodeLabelsForHeartbeat =
nodeLabelsHandler.getNodeLabelsForHeartbeat();
NodeStatus nodeStatus = getNodeStatus(lastHeartbeatID);
NodeHeartbeatRequest request =
NodeHeartbeatRequest.newInstance(nodeStatus,
NodeStatusUpdaterImpl.this.context
.getContainerTokenSecretManager().getCurrentKey(),
NodeStatusUpdaterImpl.this.context
.getNMTokenSecretManager().getCurrentKey(),
nodeLabelsForHeartbeat);
// 发送 nm 的心跳
response = resourceTracker.nodeHeartbeat(request);
2、ResourceManager 中的 ResourceTrackerService 负责处理来自 NodeManager 的请 求,一旦收到该请求,会向 RMNodeImpl 发送一个 RMNodeEventType.STATUS_UPDATE 类型事件,而 RMNodelmpl 收到该事件后,将更新各个 Container 的运行状态,并进一步向 ResoutceScheduler 发送一个 SchedulerEventType.NODE_UPDATE 类型事件。
// ResourceTrackerService#nodeHeartbeat
public NodeHeartbeatResponse nodeHeartbeat(NodeHeartbeatRequest request)
throws YarnException, IOException {
NodeStatus remoteNodeStatus = request.getNodeStatus();
/**
* Here is the node heartbeat sequence...
* 1. Check if it's a valid (i.e. not excluded) node
* 2. Check if it's a registered node
* 3. Check if it's a 'fresh' heartbeat i.e. not duplicate heartbeat
* 4. Send healthStatus to RMNode
* 5. Update node's labels if distributed Node Labels configuration is enabled
*/
// 前 3 步都是各种检查,后面才是重点的逻辑
// Heartbeat response
NodeHeartbeatResponse nodeHeartBeatResponse =
YarnServerBuilderUtils.newNodeHeartbeatResponse(
getNextResponseId(lastNodeHeartbeatResponse.getResponseId()),
NodeAction.NORMAL, null, null, null, null, nextHeartBeatInterval);
// 这里会 set 待释放的 container、application 列表
// 思考:为何只有待释放的列表呢?分配的资源不返回么? - 分配的资源是和 AM 进行交互的
rmNode.setAndUpdateNodeHeartbeatResponse(nodeHeartBeatResponse);
populateKeys(request, nodeHeartBeatResponse);
ConcurrentMap<ApplicationId, ByteBuffer> systemCredentials =
rmContext.getSystemCredentialsForApps();
if (!systemCredentials.isEmpty()) {
nodeHeartBeatResponse.setSystemCredentialsForApps(systemCredentials);
}
// 4. Send status to RMNode, saving the latest response.
// 发送 RMNodeEventType.STATUS_UPDATE 事件
RMNodeStatusEvent nodeStatusEvent =
new RMNodeStatusEvent(nodeId, remoteNodeStatus);
if (request.getLogAggregationReportsForApps() != null
&& !request.getLogAggregationReportsForApps().isEmpty()) {
nodeStatusEvent.setLogAggregationReportsForApps(request
.getLogAggregationReportsForApps());
}
this.rmContext.getDispatcher().getEventHandler().handle(nodeStatusEvent);
3、ResourceScheduler 收到事件后,如果该节点上有可分配的空闲资源,则会将这些资源分配给各个应用程序,而分配后的资源仅是记录到对应的数据结构中,等待 ApplicationMaster 下次通过心跳机制来领取。(资源分配的具体逻辑,将在后面介绍 Scheduler 的文章中详细讲解)。
本篇分析了申请与分配 Container 的流程,主要分为两个阶段。
第一阶段由 AM 发起,通过心跳向 RM 发起资源请求。
第二阶段由 NM 发起,通过心跳向 RM 汇报资源使用情况。
之后就是,RM 根据 AM 资源请求以及 NM 剩余资源进行一次资源分配(具体分配逻辑将在后续文章中介绍),并将分配的资源通过下一次 AM 心跳返回给 AM。
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我是一名决定学习Ruby和RubyonRails的ASP.NETMVC开发人员。我已经有所了解并在RoR上创建了一个网站。在ASP.NETMVC上开发,我一直使用三层架构:数据层、业务层和UI(或表示)层。尝试在RubyonRails应用程序中使用这种方法,我发现没有关于它的信息(或者也许我只是找不到它?)。也许有人可以建议我如何在RubyonRails上创建或使用三层架构?附言我使用ruby1.9.3和RubyonRails3.2.3。 最佳答案 我建议在制作RoR应用程序时遵循RubyonRails(RoR)风格。Rails
我目前有一个reddit克隆类型的网站。我正在尝试根据我的用户之前喜欢的帖子推荐帖子。看起来K最近邻或k均值是执行此操作的最佳方法。我似乎无法理解如何实际实现它。我看过一些数学公式(例如k表示维基百科页面),但它们对我来说并没有真正意义。有人可以推荐一些伪代码,或者可以查看的地方,以便我更好地了解如何执行此操作吗? 最佳答案 K最近邻(又名KNN)是一种分类算法。基本上,您采用包含N个项目的训练组并对它们进行分类。如何对它们进行分类完全取决于您的数据,以及您认为该数据的重要分类特征是什么。在您的示例中,这可能是帖子类别、谁发布了该项