
对于试图完善其 API 策略的团队来说,良好的 API 设计是一个经常出现的话题。
API 设计的重要性相信不需要赘述,精心设计的 API 的好处包括:更好开发人员体验、更快的文档编制以及更高的 API 使用率。
那么好的API设计到底是什么?这篇文章将详细介绍一些设计 RESTful API 的最佳实践。
| 精心设计的 API 的特征
一般来说,一个有效的 API 设计将具有以下特点:
*** 易于阅读和使用。**一个设计良好的 API 通常都易于使用,并且它的资源和相关操作可以被不断使用它的开发人员快速记住。
*** 难以滥用。**实现和集成具有良好设计的 API 是一个直截了当的过程,出现代码编写不正确的可能性会更小。它具有信息性反馈,并且不会强迫 API 的最终使用者遵守严格的规范。
*** 完整而简洁。**最后,完整的 API 能让开发人员针对公开的数据制作成熟的应用程序。大多数 API 设计人员和开发人员会在现有 API 的基础上逐步构建,使应用程序的完整性随时间推移而提高。这是每个拥有 API 的工程师或公司在努力实现的目标。
接下来的部分会以照片共享应用程序为例,说明一些概念。该应用程序允许用户上传照片,用这些照片的拍摄地点和描述与之相关的情绪的主题标签来表述。
| 集合、资源及其 URL
了解资源和集合
资源是 REST 概念的基础,它是一个非常重要的对象,可以被自身引用。资源具有数据、与其他资源的关系以及对其进行操作以允许访问和操作相关信息的方法。
一组资源称为一个集合。集合和资源的内容取决于组织机构和使用者的要求。例如,如果某组织认为自身某产品用户群的基本信息可以为组织带来利益,就可以尝试将其作为集合或资源公开,比如像qq在内的各种快捷登录。
统一资源定位符 (URL) 标识资源的在线位置。此 URL 指向 API 资源所在的位置。base URL 是此位置的一部分。
在照片共享应用程序中,我们可以通过适当的 URL 访问的集合和资源公开有关使用该应用程序的用户的数据。

名词可以更好地描述 URL
base URL 应该整洁、优雅且简单,以便使用该产品的开发人员可以轻松地在他们的 Web 应用程序中使用它们。一个又长又难读的基本 URL 不仅不好看,而且在尝试重新编码时也容易出错。以名词命名 URL 应该始终被作为最优解。
我们在设计时,通常没有关于保持资源名词单数或复数的规范,但建议保持集合复数。在所有资源和集合中分别使用相同的复数是一种很好的做法,可以保持描述的一致性。
保持这种命名方式,有助于开发人员理解URL所描述的资源类型,方便他们快速使用这些 API。
说回照片共享应用程序,假设它有一个公共 API,其中包含 /users 和 /photos 作为集合。一目了然,这些都是复数的名词。由此我们可以推断出 /users 和 /photos 分别提供有关产品注册用户群和共享照片的信息。
使用 HTTP 方法描述资源功能
所有资源都有一组可以针对它们进行操作的请求方法,用以处理 API 公开的数据。
RESTful API 主要由 HTTP 请求方法组成,这些请求方法对任何资源具有明确定义的独特操作。以下是常用 HTTP 请求的列表,这些请求定义了 RESTful API 中任何资源或集合的 CRUD 操作。

将动词排除在 URL 之外是一个好主意。GET、PUT、POST 和 DELETE 操作已用于对 URL 描述的资源进行操作,因此在 URL 中使用动词而不是名词会使处理资源变得混乱。
在照片共享应用程序中,以 /users 和 /photos 作为端点,API 的最终使用者可以使用上述 RESTful CRUD 操作轻松直观地使用它们。
| 响应
提供反馈以帮助开发人员取得成功
在开发人员使用产品时,提供的良好的反馈响应,对提高使用率和留存率大帮助极大。每个客户端请求和服务器端响应都是一条消息,在理想的 RESTful 生态系统中,这些消息必须是自描述的。
好的反馈包括对正确实现的自动验证,以及对不正确实现的详细报错。这可以帮助用户调试和纠正他们使用产品的方式。
调整错误可以使用标准 HTTP 代码。对于报错,客户端调用应该有对应的 400 类型的错误代码与之关联;如果存在任何服务器端错误,则必须将对应的 500 响应与它们相关联。使用资源的成功请求方法,应返回 200 类型的响应。
一般而言,使用 API 时会出现三种可能的结果:
*** 客户端应用程序运行错误(客户端错误 – 4xx 响应代码)。**
*** API 行为错误(服务器错误 – 5xx 响应代码)。**
*** 客户端和 API 工作(成功 - 2xx 响应代码)。**
当使用者在使用 API 遇到障碍时,引导他们成功完成,这将大大有助于改善开发人员体验和防止 API 滥用。而很好地描述这些错误响应,需要保持简单和整洁。除了这些,还需要在错误代码中为最终使用者提供足够的信息,才能帮助他们开始修改调整,如果觉得简单描述不够,那可以再提供指向其他文档的链接。
举例说明所有的 GET 响应
一个设计良好的 API 应当有对应的例子,对一个URL获得成功的响应。此示例响应应该简单、明了且易于理解。一个好的经验法则是帮助开发人员在五秒内准确了解成功的响应会给他们带来什么。
回到我们的照片共享应用程序,我们定义了一个 /users 和一个 /photos URL。/users 集合将在数组中提供所有已注册应用程序的用户的用户名和加入日期。
可以使用像 Eolink 这样的 API设计开发工具,在 OpenAPI 规范中定义 API,如下所示:
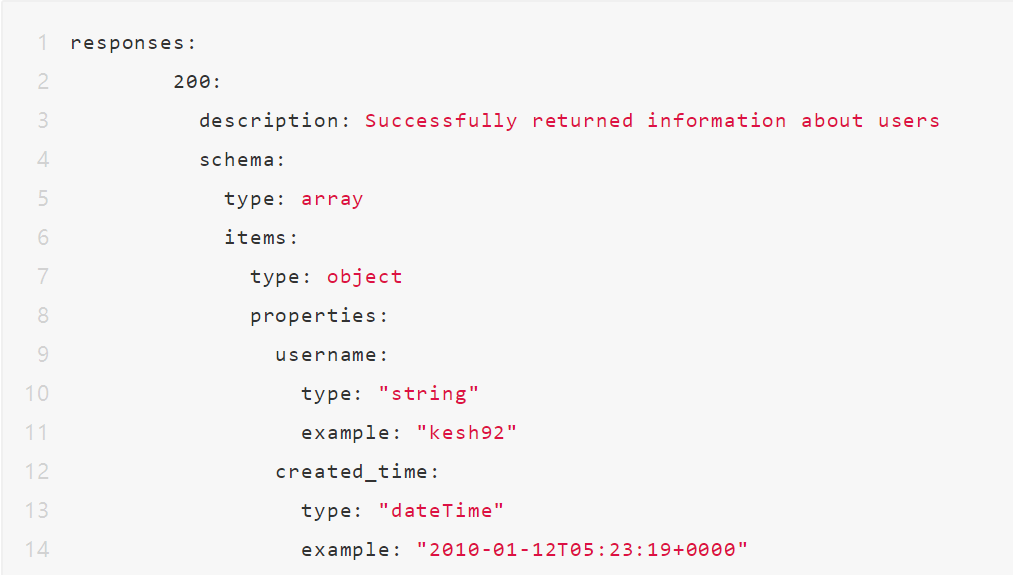
请注意终端用户可以从成功的 GET 调用中获得的每个响应项中描述的数据类型和示例。终端用户将接收JSON 格式的成功响应如下所示。

如果终端用户使用 GET 方法成功调用终端点,那么用户应获取上述数据以及 200 响应代码来验证此为正确用法。同样,不正确的调用,应反馈对应的 400 或 500 响应代码以及相关信息,以帮助用户更好地对集合进行操作。
| 请求
优雅地处理复杂的问题
尝试公开的数据可以通过许多属性来展示,这些属性可能对使用该 API 的最终消费者有益。这些属性描述了基本资源并隔离了可以使用适当方法操作的特定信息资产。
API 应尽量保证完整度,并提供所有必需的信息、数据和资源,以帮助开发人员以无缝方式与它们集成。
但是,完成度意味着要考虑 API 的常见用例。可能有无数的情景关联和属性,去定义它们中的每一个资源并不是一个好的做法。
还应考虑资源公开的数据量。如果试图加载出来很多数据,可能会对服务器产生负面影响,尤其是在负载和性能方面。
上述情况和关系是 API 设计中的重要考虑因素,可以使用适当的参数进行处理。可以扫描属性并限制查询参数中“?”后面的响应,或者使用路径参数隔离客户端正在使用的数据的特定组件。
让我们以我们的照片共享应用程序为例。
开发人员可以使用它来获取有关在特定位置和特定主题标签共享的所有照片的信息。我们还希望将每个 API 调用的结果数限制为 10,以防止服务器负载。如果最终用户想要在波士顿找到带有 #winter 标签的所有照片,调用将是:

请注意,复杂的问题现在已被简化为与查询参数的简单关联。如果您想根据客户的请求提供有关特定用户的信息,则调用将是:

其中 kesh92 是 users 集合中特定用户的用户名,将返回 kesh92 的位置和加入日期。
以上是一些可以设计参数以实现 API,完成并帮助开发人员直观地使用 API 的一些方法。
最后,如果对特定资源或集合的功能有第二个想法,请将其留待下一次迭代。开发和维护 API 是一个持续的过程,等待合适用户的反馈有助于构建强大的 API,使用户能够以创造性的方式集成和开发应用程序。
图中所使用的的接口管理工具是eolink,感兴趣可以自行使用:www.eolink.com
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
它不等于主线程的binding,这个toplevel作用域是什么?此作用域与主线程中的binding有何不同?>ruby-e'putsTOPLEVEL_BINDING===binding'false 最佳答案 事实是,TOPLEVEL_BINDING始终引用Binding的预定义全局实例,而Kernel#binding创建的新实例>Binding每次封装当前执行上下文。在顶层,它们都包含相同的绑定(bind),但它们不是同一个对象,您无法使用==或===测试它们的绑定(bind)相等性。putsTOPLEVEL_BINDINGput
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数