目录
本片博客主要介绍Linux进程控制相关的内容,主要从进程创建、进程终止、进程等待、进程程序替换这四个方面介绍,在我们学习了上述相关的进程控制操作后,我们最后会尝试运用上述内容实现一个我们自己的shell,感觉对自己有帮助的话记得给个三连哦。
该部分主要介绍fork函数相关的内容
在Linux中fork函数是非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
pid_t fork(void);返回值介绍:
子进程中返回0,父进程返回子进程pid,出错返回-1。
进程调用fork,当控制转移到内核中的fork代码后,内核做:
分配新的内存块和内核数据结构给子进程
将父进程部分数据结构内容拷贝至子进程
添加子进程到系统进程列表当中
fork返回,开始调度器调度

fork之后,父子进程的代码共享,从fork后的位置开始一起运行。
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <assert.h>
int main()
{
printf("Before: pid:%d\n",getpid());
pid_t id = fork();
assert(id != -1); //检测是否创建成功
printf("Now:pid:%d , id:%d\n",getpid(),id);
return 0;
}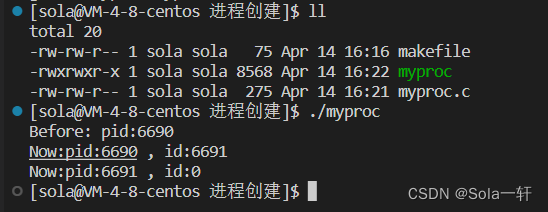
打印结果显示,子进程只执行了fork之后的语句。
注意点:
fork之前父进程独立执行,fork之后,父子两个执行流分别执行。fork之后,谁先执行完全由调度器决定。
通常,父子代码共享,父子再不写入时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式,各自一份副本。
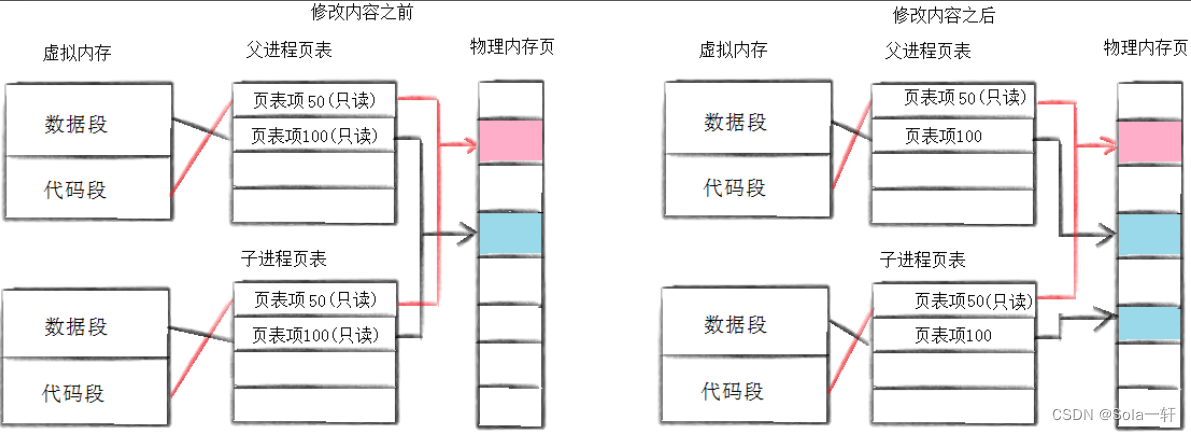
为什么要采用写时拷贝的方案?
简单用法模板:
pid_t id = fork(); //通过对id的判断让父子进程做不同的事情
if(id<0) //出错返回-1
{
//打印错误信息或者终止当前进程
}
else if(id == 0) //子进程fork返回值为0
{
//子进程做什么
}
else //父进程fork返回值是子进程id > 0
{
//父进程干啥
}fork常用场景:
创建子进程后,在子进程内通过进程程序替换执行另一个程序。
一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求。
fork函数创建子进程也可能会失败,有以下两种情况:
系统中有太多的进程,内存空间不足,子进程创建失败。
实际用户的进程数超过了限制,子进程创建失败。
该部分主要介绍退出码,exit和_exit
进程退出时,无非以下三种场景:
代码运行完毕,结果正确
代码运行完毕,结果不正确
代码异常终止
当程序正常终止时,我们可以通过 echo $? 查看进程退出码。
如运行以下程序后:
#include <stdio.h>
int main()
{
return 0;
}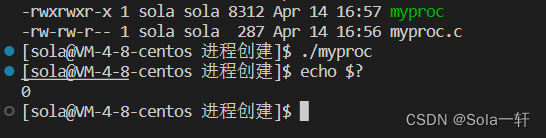
显示出的就是return的值。
我们平时使用的指令也有退出码
很明显,我们平时使用的指令也是一个个写好了的c程序。

通常,我们以0表示正常退出,非0表示异常退出。
C语言当中,我们可以调用strerror函数,其可以通过错误码,获取该错误码在C语言当中对应的错误信息。
#include <stdio.h>
#include <string.h>
int main()
{
for(int i = 1;i<128;++i)
{
printf("%d: %s\n",i,strerror(i));
}
return 0;
}
退出码的含义是人为规定的,C语言的错误信息只是一种参考,不同环境下相同的退出码的对应含义可能不同。
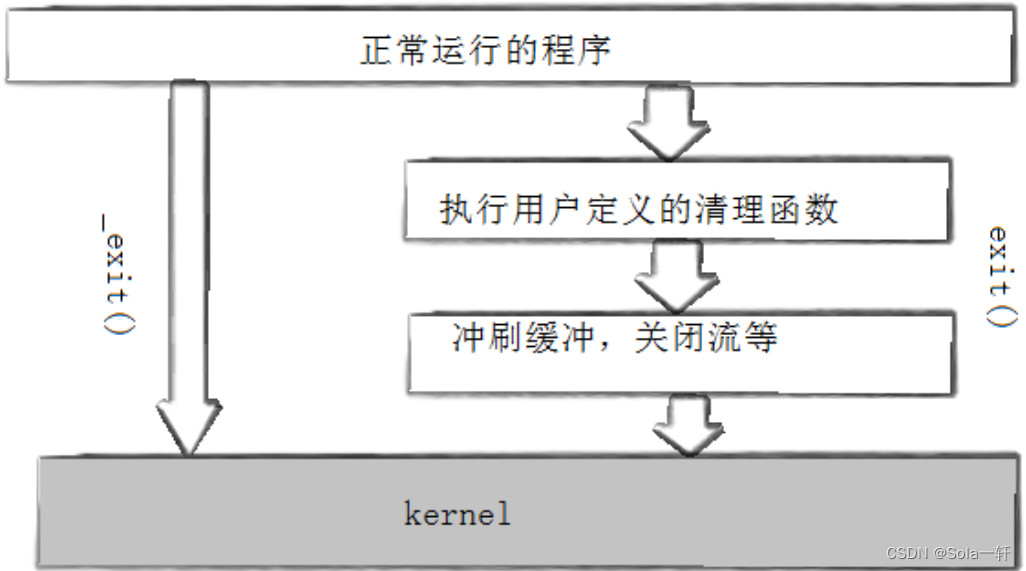
正常终止:
从main返回
调用exit
_exit
异常终止:
ctrl+c ,通过信号来终止
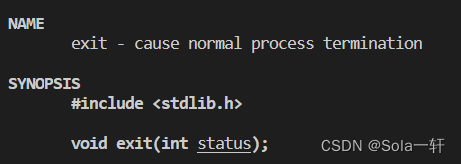
使用exit函数时,我们需要带stdlib.h的头文件,很明显,这是库中的函数。
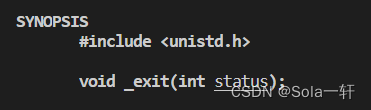
而_exit函数是一个系统调用,显然,exit函数是对 _exit系统调用进行了封装。
exit最后也会调用_exit, 但在调用_exit之前,还做了其他工作:
执行用户通过 atexit或on_exit定义的清理函数。
关闭所有打开的流,所有的缓存数据均被写入
调用_exit
演示:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
printf("hello test "); //没加\n ,不让缓冲区刷新
//exit(1);
_exit(1);
}exit时

结果在程序结束后打印出来了。
_exit时
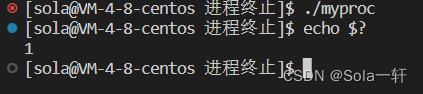
程序运行结束后也没打印。
return是一种更常见的退出进程方法。执行return n等同于执行exit(n),因为调用main的运行时函数会将main的返回值当做 exit的参数。
该部分主要介绍wait和waitpid
子进程退出,父进程如果不管不顾,就可能造成‘僵尸进程’的问题,进而造成内存泄漏。
进程一旦变成僵尸状态,就难以杀掉,即使发送9号信号也无能为力,因为谁也没有办法杀死一个已经死去的进程。
父进程派给子进程的任务完成的如何,我们需要知道。如,子进程运行完成,结果对还是不对,或者是否正常退出。
父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息
pid_t wait(int*status);返回值:
成功返回被等待进程pid,失败返回-1。
参数:
输出型参数,获取子进程退出状态,不关心则可以设置成为NULL。
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <assert.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id<0) //创建子进程失败
{
exit(1);
}
else if(id == 0) //子进程
{
printf("子进程运行,我的pid:%d\n",getpid());
exit(0);
}
//父进程等待子进程
sleep(5);
int status;
wait(&status);
sleep(5);
return 0;
}我们创建了一个子进程,打印完后子进程退出,父进程5秒后才等待子进程,此时子进程应该处于僵尸状态,5秒后回收子进程,子进程消失,父进程再运行5秒后退出。
通过以下监控脚本观察情况是否如我们预料的一样:
//监控脚本
while :; do ps axj | head -1 && ps axj | grep myprocess | grep -v grep ; sleep 1 ; done;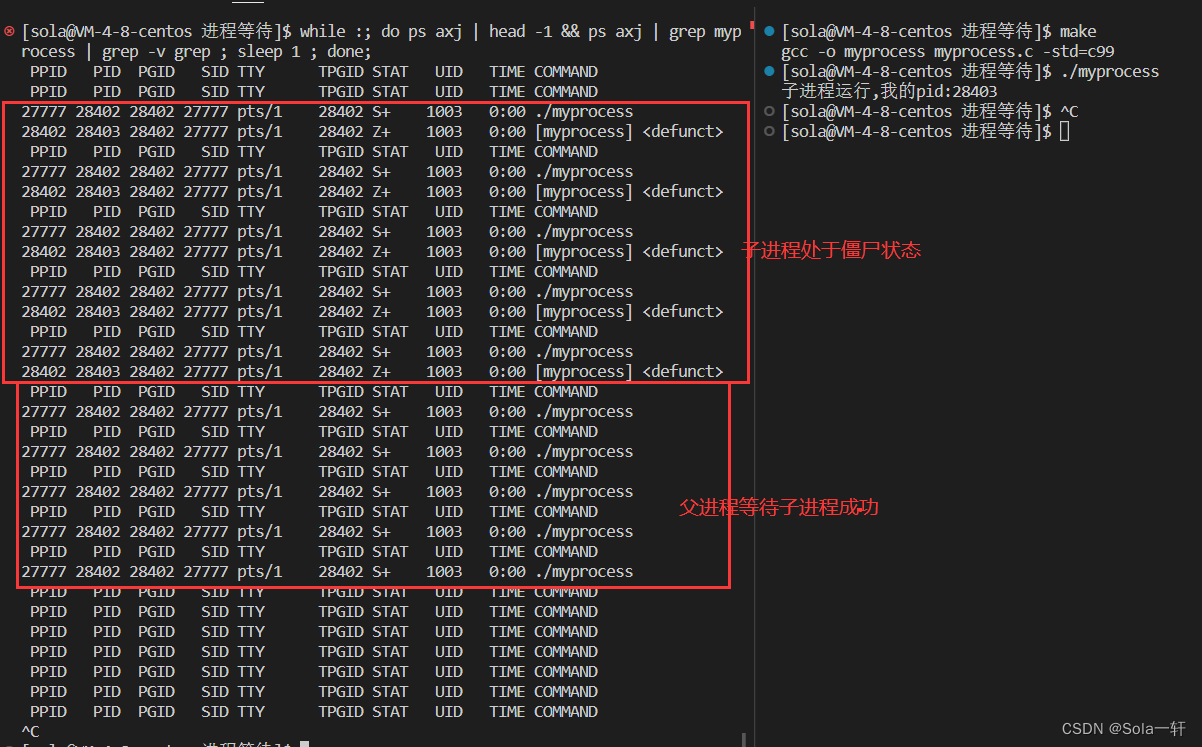
pid_ t waitpid(pid_t pid, int *status, int options);返回值:
当正常返回的时候waitpid返回收集到的子进程的进程ID;
如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
参数讲解:
pid:
Pid=-1,等待任一个子进程。与wait等效。
Pid>0.等待其进程ID与pid相等的子进程。
status(输出型参数,获取子进程退出状态,不关心则可以设置成为NULL):
WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出)
WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码)
options:
WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该子进程的ID。
注意点:
status中 WIFEXITED和WEXITSTATUS是定义好的宏函数。
options用于区分我们是进行阻塞等待还是非阻塞等待,阻塞等待直接填0即可,非阻塞等待就填WNOHANG。(后面会用代码进行演示非阻塞等待)
wait和waitpid,都有一个status参数,该参数是一个输出型参数,由操作系统填充。
如果传递NULL,表示不关心子进程的退出状态信息。
操作系统会根据该参数,将子进程的退出信息反馈给父进程。
status不能简单的当作整形来看待,可以当作位图来看待,具体细节如下图(只用了低16比特位):

通过位运算取出退出状态和终止信号:
ExitCode = ((status>>8) & 0xFF); //退出状态
Signal = (status & 0x7F); //信号#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <assert.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id<0) //创建子进程失败
{
exit(1);
}
else if(id == 0) //子进程
{
while(1)
{
printf("子进程pid: %d\n",getpid());
sleep(1);
}
}
//父进程等待子进程
int status;
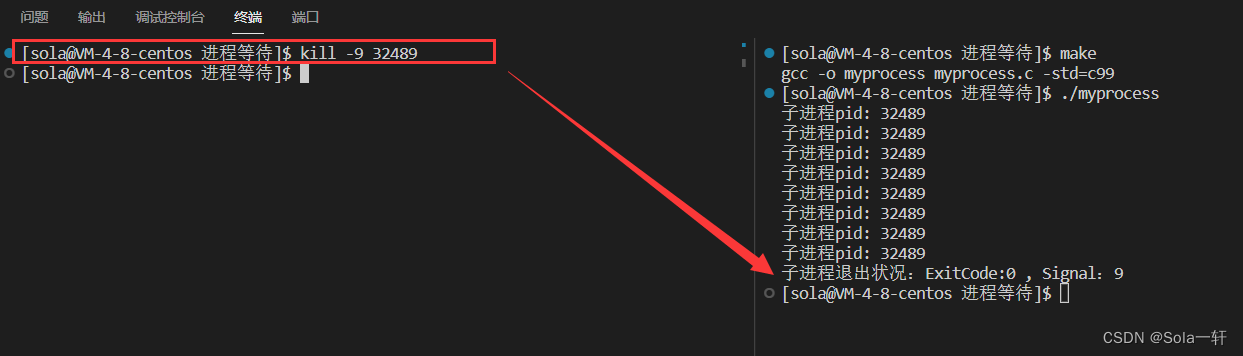
waitpid(id,&status,0);
int ExitCode = ((status>>8) & 0xFF); //退出状态
int Signal = (status & 0x7F); //信号
printf("子进程退出状况:ExitCode:%d , Signal:%d\n",ExitCode,Signal);
sleep(5);
return 0;
}
什么是非阻塞等待?
首先,父进程阻塞等待子进程时,父进程什么都干不了,只能等子进程结束后才能干其他事情。而非阻塞等待,就是我们通过轮询的方式,执行等待函数时,如果子进程还没有结束,父进程就先继续执行自己的事情,等下次再来等待。
如何实现非阻塞等待?
pid_ t waitpid(pid_t pid, int *status, int options);第三个参数options设置为WNOHANG即可.
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <assert.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id<0) //创建子进程失败
{
exit(1);
}
else if(id == 0) //子进程
{
int count = 5;
while(count--)
{
sleep(1);
}
exit(1);
}
//父进程等待子进程
int status;
pid_t ret = 0;
do
{
ret = waitpid(id,&status,WNOHANG);
//父进程做自己的事情
printf("子进程正在运行中\n");
sleep(1);
} while (ret == 0);
// int ExitCode = ((status>>8) & 0xFF); //退出状态
// int Signal = (status & 0x7F); //信号
//使用一下宏函数
if(WIFEXITED(status))
{
printf("子进程退出码为%d\n",WEXITSTATUS(status));
}
else
{
printf("等待失败\n");
}
sleep(5);
return 0;
}
可以看到,在等待的同时,父进程也能打印,干自己的事情。
两种等待方式并没有优劣之分,看情况使用即可。
该部分主要讲解替换的原理和六个exec函数
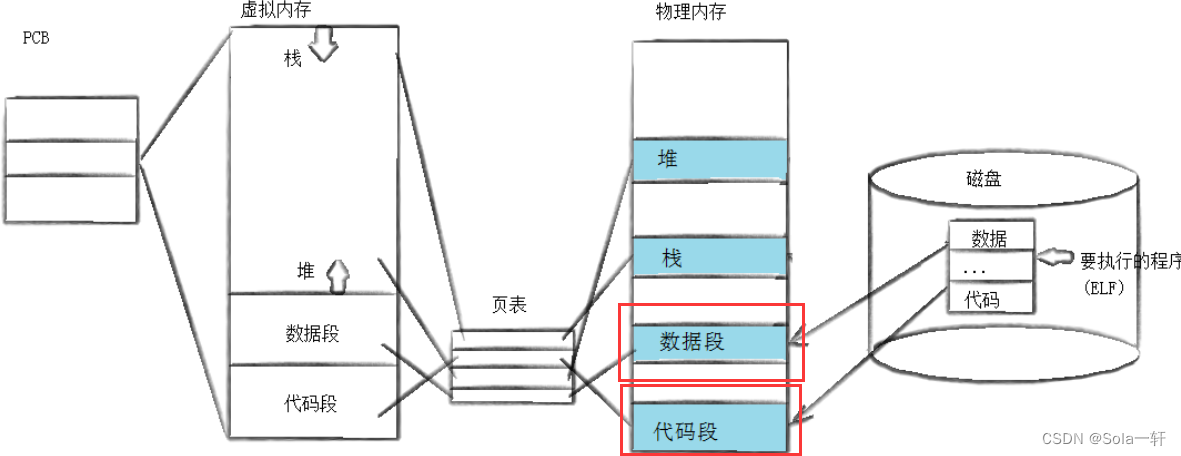
用fork创建子进程后执行的是和父进程相同的程序(但有可能执行不同的代码分支),子进程往往要调用一种exec函数以执行另一个程序。当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。调用exec并不创建新进程,所以调用exec前后该进程的id并未改变(还是用原来的PCB、页表等)。
int execl(const char *path, const char *arg, ...);参数:
path表示要执行的程序所在的路径
可变参数列表,最后以NULL进行结尾
返回值:
失败返回-1,并设置相应的错误码
使用:以ls命令为例
execl("/usr/bin/ls","ls","-a","-l".NULL);int execlp(const char *file, const char *arg, ...);参数:
file表示要运行的程序名,系统会自动在环境变量PATH对应的路径下寻找
可变参数列表,最后以NULL进行结尾
返回值:
失败返回-1,并设置相应的错误码
使用:以ls命令为例
execlp("ls","ls","-a","-l".NULL);int execle(const char *path, const char *arg, ...,char *const envp[]);参数:
path表示要执行的程序所在的路径
可变参数列表,最后以NULL进行结尾
envp数组中,每个位置都指向一个自己设定的环境变量
与execl的使用相比,进程程序替换后使用的环境变量需要我们自己来进行设置
//myprocess
#include <stdio.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <assert.h>
#include <unistd.h>
#include <stdlib.h>
int main()
{
pid_t id = fork();
if(id<0) //创建子进程失败
{
exit(1);
}
else if(id == 0) //子进程
{
char* env[]= { "MYVALUE=1234"};
execle("./test",NULL,env);
exit(1);
}
//父进程等待子进程
int status;
waitpid(id,&status,0);
int ExitCode = ((status>>8) & 0xFF); //退出状态
int Signal = (status & 0x7F); //信号
printf("ExitCode:%d , Signal:%d\n",ExitCode,Signal);
sleep(5);
return 0;
}//test
#include <stdio.h>
#include <stdlib.h>
int main()
{
char*s = getenv("PATH");
char*p = getenv("MYVALUE");
printf("S:%s\n",s);
printf("P:%s\n",p);
return 0;
}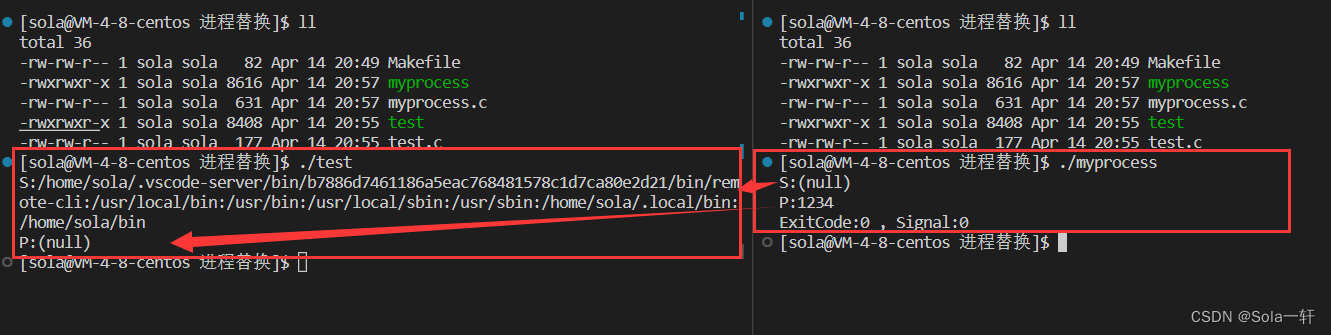
可以看到,我们通过进程程序替换函数execle执行的程序只认识我们自己设置的环境变量。
int execv(const char *path, char *const argv[]);与execl的区别就在于将后面的可变参数列表换成了指针数组。
以ls指令为例:
char*const argv[] = {"ls","-a","-l",NULL};
execv("/usr/bin/ls",argv);
int execvp(const char *file, char *const argv[]);与execvl的区别就在于将路径改为程序名,就不多赘述了。
int execve(const char *path, char *const argv[], char *const envp[]);参考上面execle的用法即可
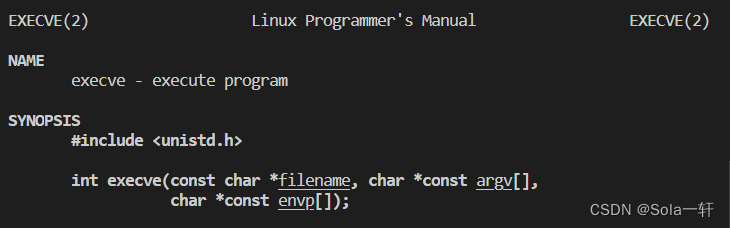
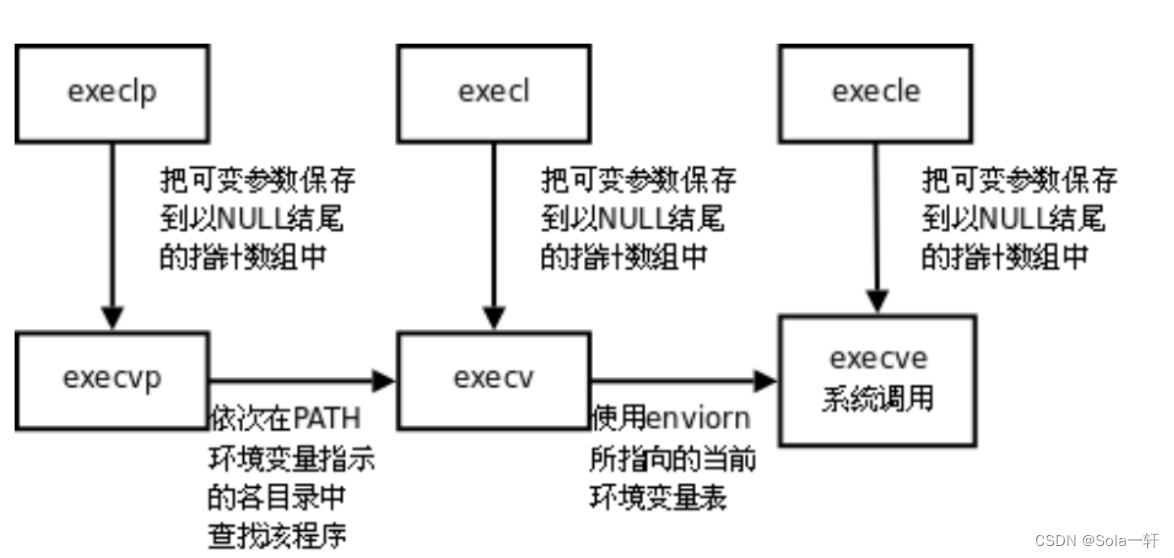
事实上,只有execve是真正的系统调用,其它五个函数最终都调用 execve,所以execve在man手册 第2节,其它函数在man手册第3节。这些函数之间的关系如下图所示:
这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回。
如果调用出错则返回-1。
所以exec函数只有出错的返回值而没有成功的返回值。
这些函数原型看起来很容易混,但只要掌握了规律就很好记。
l(list) : 表示参数采用列表
v(vector) : 参数用数组
p(path) : 有p自动搜索环境变量PATH
e(env) : 表示自己维护环境变量

用下图的时间轴来表示事件的发生次序。其中时间从左向右。shell由标识为sh的方块代表,它随着时间的流逝从左向右移动。shell从用户读入字符串"ls"。shell建立一个新的进程,然后在那个进程中运行ls程序并等待那个进程结束。
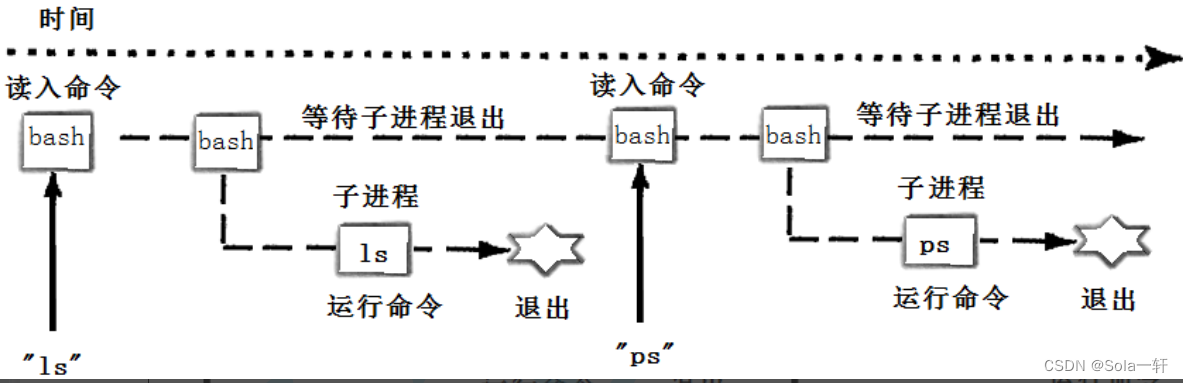
然后shell读取新的一行输入,建立一个新的进程,在这个进程中运行程序 并等待这个进程结束。所以要写一个shell,需要循环以下过程:
获取命令行
解析命令行
建立一个子进程(fork)
替换子进程(execvp)
父进程等待子进程退出(wait)
根据这些思路,和我们前面的学的技术,就可以自己来实现一个shell了。
实现如下:
#include <stdio.h>
#include <string.h>
#include <stdbool.h>
#include <unistd.h>
#include <assert.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <stdlib.h>
#define SIZE 1024
char CommandLine[SIZE]; //存放输入的指令
#define OPT_NUM 64
char* Myargv[OPT_NUM]; //存放分割后的程序指令
//保存上次运行时的退出码和退出信号
int lastCode;
int lastSignal;
int main( )
{
while(true)
{
//1.打印提示符
printf("[用户名@主机名 当前路径]#");
fflush(stdout); //刷新缓冲区
//获取用户输入
char* s = fgets(CommandLine,sizeof(CommandLine)-1,stdin);
assert(s != NULL); //检查释放获取成功
(void)s;
CommandLine[strlen(CommandLine)-1] = 0; //消除掉输入时带的换行符
//字符串分割,拿出指令
Myargv[0] = strtok(CommandLine," ");
int i = 1;
//给ls命令增加配色方案
if(Myargv[0]!=NULL && strcmp(Myargv[0],"ls")==0)
{
Myargv[i++] = (char*)"--color=auto";
}
while( Myargv[i++] = strtok(NULL," ")); //无法分割时返回空指针。 命令行参数最后刚好需要以NULL结尾
//内建命令,内置命令不需要创建子进程来执行
//cd 命令需要改变当前进程的工作目录
if(Myargv[0]!=NULL && strcmp(Myargv[0],"cd")==0)
{
if(Myargv[1]!=NULL)
chdir(Myargv[1]);
continue;
}
//echo命令获取上次程序的退出码
if(Myargv[0]!=NULL && Myargv[1]!=NULL && strcmp(Myargv[0],"echo")==0)
{
if(strcmp(Myargv[1],"$?")==0)
{
printf("lastcode:%d , lastSignal:%d\n",lastCode,lastSignal);
}
else
{
printf("%s\n",Myargv[1]);
}
continue;
}
//条件编译来测试 编译时带上 -DDEBUG即可运行测试
#ifdef DEBUG
for(int i=0; Myargv[i] ;++i)
printf("%s\n",Myargv[i]);
#endif
//创建子进程执行相关指令
pid_t id = fork();
assert(id != -1); //检测子进程是否创建失败
if(id == 0) //子进程进程切换 执行对应的指令
{
execvp(Myargv[0],Myargv);
exit(1); //异常时才从这退出
}
int status; //拿到子程序的退出码
waitpid(id,&status,0);
lastCode = ((status>>8) & 0xFF);
lastSignal = (status & 0x7F);
}
return 0;
}演示:
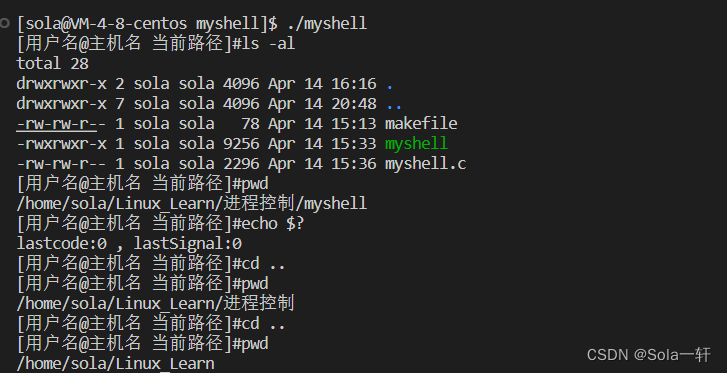
注意点:
内建/内置命令不需要创建子进程来执行,如cd命令等。
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我正在编写一个gem,我必须在其中fork两个启动两个webrick服务器的进程。我想通过基类的类方法启动这个服务器,因为应该只有这两个服务器在运行,而不是多个。在运行时,我想调用这两个服务器上的一些方法来更改变量。我的问题是,我无法通过基类的类方法访问fork的实例变量。此外,我不能在我的基类中使用线程,因为在幕后我正在使用另一个不是线程安全的库。所以我必须将每个服务器派生到它自己的进程。我用类变量试过了,比如@@server。但是当我试图通过基类访问这个变量时,它是nil。我读到在Ruby中不可能在分支之间共享类变量,对吗?那么,还有其他解决办法吗?我考虑过使用单例,但我不确定这是
当我在Rails控制台中按向上或向左箭头时,出现此错误:irb(main):001:0>/Users/me/.rvm/gems/ruby-2.0.0-p247/gems/rb-readline-0.4.2/lib/rbreadline.rb:4269:in`blockin_rl_dispatch_subseq':invalidbytesequenceinUTF-8(ArgumentError)我使用rvm来管理我的ruby安装。我正在使用=>ruby-2.0.0-p247[x86_64]我使用bundle来管理我的gem,并且我有rb-readline(0.4.2)(人们推荐的最少
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
这可能是个愚蠢的问题。但是,我是一个新手......你怎么能在交互式rubyshell中有多行代码?好像你只能有一条长线。按回车键运行代码。无论如何我可以在不运行代码的情况下跳到下一行吗?再次抱歉,如果这是一个愚蠢的问题。谢谢。 最佳答案 这是一个例子:2.1.2:053>a=1=>12.1.2:054>b=2=>22.1.2:055>a+b=>32.1.2:056>ifa>b#Thecode‘if..."startsthedefinitionoftheconditionalstatement.2.1.2:057?>puts"f