 一般情况下Kubernetes可以通过ReplicaSet以一个Pod模板创建多个Pod副本,但是它们都是无状态的,任何时候它们都可以被一个全新的Pod替换。然而有状态的Pod需要另外的方案确保当一个有状态的Pod挂掉后,这个Pod实例需要在别的节点上重建,但是新的实例必须与被替换的实例拥有相同的名称、网络标识和状态。这就是StatefulSet管理Pod的手段。
对于容器集群,有状态服务的挑战在于,通常集群中的任何节点都并非100%可靠的,服务所需的资源也会动态地更新改变。当节点由于故障或服务由于需要更多的资源而无法继续运行在原有节点上时,集群管理系统会为该服务重新分配一个新的运行位置,从而确保从整体上看,集群对外的服务不会中断。
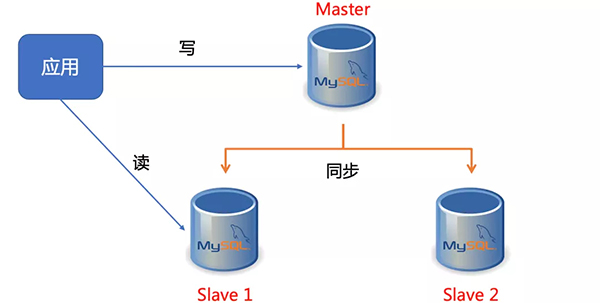
若采用本地存储,当服务漂移后数据并不会随着服务转移到新的节点,重启服务就会出现数据丢失的困境。本文目的是通过一个MySQL的主从集群搭建,深入了解Kubernetes的StatfulSet管理。为了降低实验的外部依赖,存储层面上,我采用的是本地存储,当然生产上不建议这样做,生产环境的存储推荐官方介绍到的的GCE、NFS、Ceph等存储方案,因为这些方案支持动态供给的特性,允许开发人员通过PVC的定义,快速实现数据有效存储,所以你绝不应该把一个宿主机上的目录当作PV使用,只是本文用于实验需要,采用Local Persistent Volume的手段,目的只是为了验证StatefulSet的状态管理功能。
一般情况下Kubernetes可以通过ReplicaSet以一个Pod模板创建多个Pod副本,但是它们都是无状态的,任何时候它们都可以被一个全新的Pod替换。然而有状态的Pod需要另外的方案确保当一个有状态的Pod挂掉后,这个Pod实例需要在别的节点上重建,但是新的实例必须与被替换的实例拥有相同的名称、网络标识和状态。这就是StatefulSet管理Pod的手段。
对于容器集群,有状态服务的挑战在于,通常集群中的任何节点都并非100%可靠的,服务所需的资源也会动态地更新改变。当节点由于故障或服务由于需要更多的资源而无法继续运行在原有节点上时,集群管理系统会为该服务重新分配一个新的运行位置,从而确保从整体上看,集群对外的服务不会中断。
若采用本地存储,当服务漂移后数据并不会随着服务转移到新的节点,重启服务就会出现数据丢失的困境。本文目的是通过一个MySQL的主从集群搭建,深入了解Kubernetes的StatfulSet管理。为了降低实验的外部依赖,存储层面上,我采用的是本地存储,当然生产上不建议这样做,生产环境的存储推荐官方介绍到的的GCE、NFS、Ceph等存储方案,因为这些方案支持动态供给的特性,允许开发人员通过PVC的定义,快速实现数据有效存储,所以你绝不应该把一个宿主机上的目录当作PV使用,只是本文用于实验需要,采用Local Persistent Volume的手段,目的只是为了验证StatefulSet的状态管理功能。

kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumerssh root@node1
mkdir -pv /data/svr/projects/{mysql,mysql2,mysql3}apiVersion: v1
kind: PersistentVolume
metadata:
name: example-mysql-pv
spec:
capacity:
storage: 15Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /data/svr/projects/mysql
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1apiVersion: v1
kind: PersistentVolume
metadata:
name: example-mysql-pv-2
spec:
capacity:
storage: 15Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /data/svr/projects/mysql2
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1apiVersion: v1
kind: PersistentVolume
metadata:
name: example-mysql-pv-3
spec:
capacity:
storage: 15Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /data/svr/projects/mysql3
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1kubectl apply -f 01-persistentVolume-{1..3}.yaml
persistentvolume/example-mysql-pv1 created
persistentvolume/example-mysql-pv2 created
persistentvolume/example-mysql-pv3 created
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumerkubectl apply -f 02-storageclass.yaml
storageclass.storage.k8s.io/local-storage created
apiVersion: v1
kind: Namespace
metadata:
name: mysql
labels:
app: mysql 执行创建:
执行创建:kubectl apply -f 03-mysql-namespace.yaml
namespace/mysql createdapiVersion: v1
kind: ConfigMap
metadata:
name: mysql
namespace: mysql
labels:
app: mysql
data:
master.cnf: |
# Master配置
[mysqld]
log-bin=mysqllog
skip-name-resolve
slave.cnf: |
# Slave配置
[mysqld]
super-read-only
skip-name-resolve
log-bin=mysql-bin
replicate-ignore-db=mysqlkubectl apply -f 04-mysql-configmap.yaml
configmap/mysql created
apiVersion: v1
kind: Secret
metadata:
name: mysql-secret
namespace: mysql
labels:
app: mysql
type: Opaque
data:
password: MTIzNDU2 # echo -n "123456" | base64kubectl apply -f 05-mysql-secret.yaml
secret/mysql-secret createdapiVersion: v1
kind: Service
metadata:
name: mysql
namespace: mysql
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
apiVersion: v1
kind: Service
metadata:
name: mysql-read
namespace: mysql
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysqlkubectl apply -f 06-mysql-services.yaml
$ kubectl get svc -n mysql
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mysql ClusterIP None <none> 3306/TCP 20s
mysql-read ClusterIP 10.0.0.63 <none> 3306/TCP 20s
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
namespace: mysql
labels:
app: mysql
spec:
selector:
matchLabels:
app: mysql
serviceName: mysql
replicas: 2
template:
metadata:
labels:
app: mysql
spec:
initContainers:
- name: init-mysql
image: mysql:5.7
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: password
command:
- bash
- "-c"
- |
set -ex
# 从Pod的序号,生成server-id
[[ $(hostname) =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# 由于server-id不能为0,因此给ID加100来避开它
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# 如果Pod的序号为0,说明它是Master节点,从ConfigMap里把Master的配置文件拷贝到/mnt/conf.d目录下
# 否则,拷贝ConfigMap里的Slave的配置文件
if [[ ${ordinal} -eq 0 ]]; then
cp /mnt/config-map/master.cnf /mnt/conf.d
else
cp /mnt/config-map/slave.cnf /mnt/conf.d
fi
volumeMounts:
- name: conf
mountPath: /mnt/conf.d
- name: config-map
mountPath: /mnt/config-map
- name: clone-mysql
image: gcr.io/google-samples/xtrabackup:1.0
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: password
command:
- bash
- "-c"
- |
set -ex
# 拷贝操作只需要在第一次启动时进行,所以数据已经存在则跳过
[[ -d /var/lib/mysql/mysql ]] && exit 0
# Master 节点(序号为 0)不需要这个操作
[[ $(hostname) =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal == 0 ]] && exit 0
# 使用ncat指令,远程地从前一个节点拷贝数据到本地
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# 执行 --prepare,这样拷贝来的数据就可以用作恢复了
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
containers:
- name: mysql
image: mysql:5.7
env:
# - name: MYSQL_ALLOW_EMPTY_PASSWORD
# value: "1"
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: password
ports:
- name: mysql
containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
resources:
requests:
cpu: 500m
memory: 1Gi
livenessProbe:
exec:
command: ["mysqladmin", "ping", "-uroot", "-p${MYSQL_ROOT_PASSWORD}"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
command: ["mysqladmin", "ping", "-uroot", "-p${MYSQL_ROOT_PASSWORD}"]
initialDelaySeconds: 5
periodSeconds: 2
timeoutSeconds: 1
- name: xtrabackup
image: gcr.io/google-samples/xtrabackup:1.0
ports:
- name: xtrabackup
containerPort: 3307
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: password
command:
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# 从备份信息文件里读取MASTER_LOG_FILE和MASTER_LOG_POS这2个字段的值,用来拼装集群初始化SQL
if [[ -f xtrabackup_slave_info ]]; then
# 如果xtrabackup_slave_info文件存在,说明这个备份数据来自于另一个Slave节点
# 这种情况下,XtraBackup工具在备份的时候,就已经在这个文件里自动生成了“CHANGE MASTER TO”SQL语句
# 所以,只需要把这个文件重命名为change_master_to.sql.in,后面直接使用即可
mv xtrabackup_slave_info change_master_to.sql.in
# 所以,也就用不着xtrabackup_binlog_info了
rm -f xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# 如果只是存在xtrabackup_binlog_info文件,说明备份来自于Master节点,就需要解析这个备份信息文件,读取所需的两个字段的值
[[ $(cat xtrabackup_binlog_info) =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm xtrabackup_binlog_info
# 把两个字段的值拼装成SQL,写入change_master_to.sql.in文件
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# 如果存在change_master_to.sql.in,就意味着需要做集群初始化工作
if [[ -f change_master_to.sql.in ]]; then
# 但一定要先等MySQL容器启动之后才能进行下一步连接MySQL的操作
echo "Waiting for mysqld to be ready(accepting connections)"
until mysql -h 127.0.0.1 -uroot -p${MYSQL_ROOT_PASSWORD} -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
# 将文件change_master_to.sql.in改个名字
# 防止这个Container重启的时候,因为又找到了change_master_to.sql.in,从而重复执行一遍初始化流程
mv change_master_to.sql.in change_master_to.sql.orig
# 使用change_master_to.sql.orig的内容,也就是前面拼装的SQL,组成一个完整的初始化和启动Slave的SQL语句
mysql -h 127.0.0.1 -uroot -p${MYSQL_ROOT_PASSWORD} << EOF
$(< change_master_to.sql.orig),
MASTER_HOST='mysql-0.mysql.mysql',
MASTER_USER='root',
MASTER_PASSWORD='${MYSQL_ROOT_PASSWORD}',
MASTER_CONNECT_RETRY=10;
START SLAVE;
EOF
fi
# 使用ncat监听3307端口。
# 它的作用是,在收到传输请求的时候,直接执行xtrabackup --backup命令,备份MySQL的数据并发送给请求者
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root --password=${MYSQL_ROOT_PASSWORD}"
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mysql
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- "ReadWriteOnce"
storageClassName: local-storage
resources:
requests:
storage: 3Gikubectl apply -f 07-mysql-statefulset.yaml 最后,容器检查pod的运行状态
最后,容器检查pod的运行状态

kubectl -n mysql exec mysql-1 -c mysql -- bash -c "mysql -uroot -p123456 -e 'show slave status \G'"
mysql: [Warning] Using a password on the command line interface can be insecure.
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: mysql-0.mysql.mysql
Master_User: root
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: mysqllog.000003
Read_Master_Log_Pos: 154
Relay_Log_File: mysql-1-relay-bin.000002
Relay_Log_Pos: 319
Relay_Master_Log_File: mysqllog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB: mysql
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 154
Relay_Log_Space: 528
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 100
Master_UUID: 1bad4d64-6290-11ea-8376-0242ac113802
Master_Info_File: /var/lib/mysql/master.info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:kubectl -n mysql exec mysql-0 -c mysql -- bash -c "mysql -uroot -p123456 -e 'create database test’"
kubectl -n mysql exec mysql-0 -c mysql -- bash -c "mysql -uroot -p123456 -e 'use test;create table counter(c int);’"
kubectl -n mysql exec mysql-0 -c mysql -- bash -c "mysql -uroot -p123456 -e 'use test;insert into counter values(123)’"kubectl -n mysql exec mysql-1 -c mysql -- bash -c "mysql -uroot -p123456 -e 'use test;select * from counter’"
c
123kubectl -n mysql scale statefulset mysql -—replicas=3
$ kubectl get po -n mysql
NAME READY STATUS RESTARTS AGE
mysql-0 2/2 Running 0 22m
mysql-1 2/2 Running 0 22m
mysql-2 2/2 Running 0 20skubectl -n mysql exec mysql-2 -c mysql -- bash -c "mysql -uroot -p123456 -e 'use test;select * from counter’"
c
123总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r