
目录
1.Hive并不是hadoop自带的组件,因此我们需要去下载hive,此次课我们使用hive 1.2.1版本,下载地址为:
2.下载完成之后,安装包默认保存在下载文件夹中,解压安装包apache-hive-1.2.1-bin.tar.gz至路径 /usr/local,命令如下:
3.然后切换至目录 /usr/local,将文件夹名改为hive(为了后续的方便),并且修改文件权限给hadoop账户:
4.配置环境变量:为了方便使用,需把hive命令加入到环境变量中去,使用vim编辑器打开.bashrc文件,命令如下:
6.修改/usr/local/hive/conf下的配置文件,该目录下的文件有:
1.我们采用MySQL数据库保存Hive的元数据,而不是采用Hive自带的derby来存储元数据,因此需要在Ubuntu里安装MySQL 使用以下命令即可进行mysql安装:
2.MySQL安装完成之后,可用以下命令启动和关闭mysql服务器:
3.确认mysql安装成功且可正常启动之后,需下载mysql jdbc的包,地址为: https://downloads.mysql.com/archives/c-j/
6.在mysql shell界面,新建hive数据库(这个hive数据库与hive-site.xml中localhost:3306/hive的hive对应,用来保存hive元数据):
8.至此,hive和mysql都已经安装配置完毕,可以尝试启动hive,注意hive是hadoop之上的,所以要先启动hadoop:
9.启动进入Hive的交互式执行环境以后,会出现如下命令提示符:
http://archive.apache.org/dist/hive/hive-1.2.1/
sudo tar -zxf ~/下载/apache-hive-1.2.1-bin.tar.gz -C /usr/local
cd /usr/local/
sudo mv apache-hive-1.2.1-bin hive
sudo chown -R hadoop:hadoop hive
vim ~/.bashrc在该文件最前面一行添加如下内容:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
export HADOOP_HOME=/usr/local/hadoop 
source ~/.bashrc
首先将hive-default.xml.template重命名为hive-default.xml:
cd /usr/local/hive/conf
mv hive-default.xml.template hive-default.xml 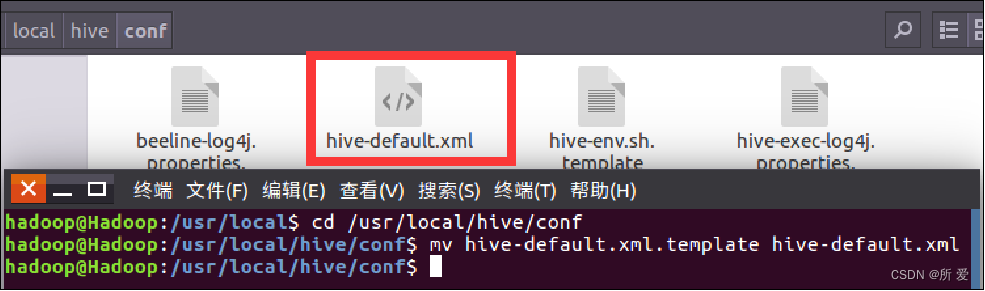
然后,使用vim编辑器新建一个配置文件hive-site.xml,命令如下:
vim hive-site.xml在hive-site.xml中添加如下配置信息:

保存退出,Hive的配置完成
sudo apt-get install mysql-server如果发现安装缓慢或者版本较低,可以先更新一下软件源以获得最新版本:
sudo apt-get update过程中问到 y/n 一律 y:

安装过程会提示设置mysql root用户的密码,还是建议设置个简单的密码,比如我这里使用的还是hadoop,设置完成后等待自动安装即可。
service mysql start
service mysql stop

在启动和关闭mysql的时候,都需要输入我们刚才设置的密码:
可以使用如下命令来确认mysql是否启动成功:
sudo netstat -tap | grep mysqlmysql节点处于LISTEN状态表示启动成功:

tar -zxvf mysql-connector-java-5.1.40.tar.gz
将解压完成之后,mysql-connector-java-5.1.40目录下的 mysql-connector-java-5.1.40-bin.jar 文件拷贝到/usr/local/hive/lib目录下:
cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib
复制完成之后如图:
service mysql start登陆进入mysql shell界面:
mysql -u root -p
mysql> create database hive 
mysql> grant all on *.* to hive@localhost identified by 'hive';
此处表示,将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码, 然后,用如下命令刷新mysql系统权限关系表:
mysql> flush privileges; 
ssh localhost
cd /usr/local/hadoop ./sbin/start-dfs.sh jps
cd /usr/local/hive ./bin/hive 
可以在里面输入SQL语句,如果要退出Hive交互式执行环境,可以输入如下命令:

至此,本次课的操作,hive和mysql的安装配置完成
以上为本文全部内容。
由于我是新手小白,如有错误请斧正。

我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs
我正在尝试在我的centos服务器上安装therubyracer,但遇到了麻烦。$geminstalltherubyracerBuildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingtherubyracer:ERROR:Failedtobuildgemnativeextension./usr/local/rvm/rubies/ruby-1.9.3-p125/bin/rubyextconf.rbcheckingformain()in-lpthread...yescheckingforv8.h...no***e
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm