文章目录
提到数据结构与算法,就一定会伴随着诸多所谓的坚持和抱怨。同时,还有两个词总是出现,一个是内功,是对知识的定位,一个是吃透,是对自己的期待。可是,我们是不是被这两个词束缚太久了,以至于出现了很多的问题:

我个人觉得,其实真正的原因是你没有找到好的学习方法,没有抓住学习的重点。实际上,数据结构和算法的东西并不多,常用的、基础的知识点更是屈指可数。只要掌握了正确的学习方法,学起来并没有看上去那么难,更不需要什么高智商、厚底子。
从广义上讲,数据结构就是指一组数据的存储结构。算法就是操作数据的一组方法。
图书馆储藏书籍你肯定见过吧?为了方便查找,图书管理员一般会将书籍分门别类进行 “存储”。按照一定规律编号,就是书籍这种 “数据” 的存储结构。
那我们如何来查找一本书呢?有很多种办法,你当然可以一本一本地找,也可以先根据书籍类别的编号,是人文,还是科学、计算机,来定位书架,然后再依次查找。笼统地说,这些查找方法都是算法。
从狭义上讲,是指某些著名的数据结构和算法,比如队列、栈、堆、二分查找、动态规划等。这些都是前人智慧的结晶,我们可以直接拿来用。我们要讲的这些经典数据结构和算法,都是前人从很多实际操作场景中抽象出来的,经过非常多的求证和检验,可以高效地帮助我们解决很多实际的开发问题。
那数据结构和算法有什么关系呢?为什么大部分书都把这两个东西放到一块儿来讲呢?
这是因为,数据结构和算法是相辅相成的。数据结构是为算法服务的,算法要作用在特定的数据结构之上。 因此,我们无法孤立数据结构来讲算法,也无法孤立算法来讲数据结构。
比如,因为数组具有随机访问的特点,常用的二分查找算法需要用数组来存储数据。但如果我们选择链表这种数据结构,二分查找算法就无法工作了,因为链表并不支持随机访问。
数据结构是静态的,它只是组织数据的一种方式。如果不在它的基础上操作、构建算法,孤立存在的数据结构就是没用的。
现在你对数据结构与算法是不是有了比较清晰的理解了呢?有了这些储备,下面我们来看看,数据结构与算法的难点在哪儿吧。
第一个问题:都说这部分知识是内功,一定要不断修炼,保证吃透,可是何为内功?何为吃透?
有人把学习数据结构与算法比喻为练内功,但我不赞成这样的说法。程序员真正的内功其实是解决复杂问题的全局把控能力以及细节实现能力,这往往需要十数年甚至数十年的持续修炼才能体会得到。除非你将所有计算机基础知识都称为内功,否则这样的比喻并不恰当。
不可否认的是,数据结构和算法方面的知识是计算机的基础知识之一,但是,这不意味着你一定要给它贴上一个宏大的标签,甚至扛着极大的心理压力和包袱去学习。
数据结构和算法方面的知识博大精深,深入挖掘下去还会用到许多数学知识。因此,我们的首要目标不应该是吃透,而应该是尝一尝,把知识读薄,指向实践,够用即可。后续要在某个非常具体的数据结构或者算法领域取得一定成就,才会需要吃透其中的一些东西。
第二个问题:怎么分配系统学习和刷题的时间呢?
有一句话很重要,做选择之前要明白自己到底想要什么。
刷题,基本都是为了应付面试。如果非要说是为了锻炼解决问题的思维能力,以及快速用合适的数据结构去解决现实中的问题,这个作用当然也有,但却是次要的。对于软件工程师来讲,还有很多比数据结构更重要的知识需要去学会。
如果你确定要去某个大厂应聘某个算法岗,而该算法岗是需要你刷题的,那么你就在系统学习之后,在网上找找相关的试卷或者考题,有目的地到 LeetCode 上去刷。
如果你不去大厂或者并不去应聘一些专门的算法岗职位,那么直接去系统学习一门课就好。把时间节省出来好好学些更重要的知识吧。切记,时间对于软件开发工程师非常非常珍贵,甚至是你最珍贵的资源、最宝贵的财富。千万不要大手大脚的占用大量时间去学习太多没必要的知识。
一言以蔽之,也就是没有孰重孰轻,但 系统的学习是刷题的基础。想象一下,你会在不认识汉字的情况下去读小说吗?
越是大而全,越要删繁就简卸下了包袱,明确了目标,接下来的问题就是怎么学习了。
很多同学感觉到自己的时间有限,数据结构和算法知识体系太过庞大,学了后面忘了前面,很难坚持学完。造成这种情况的原因很多,比如有些资料把简单问题复杂化了,有些资料则非常晦涩,数学知识过多,学术性过强,甚至是表达不清,很难让人有舒适的学习体验。
不论你是否已经具备了一定的基础,接下来,就让我们放平心态,先来梳理下在每个模块的学习目标到底是什么。
为了让大家对数据结构和算法能有个全面的认识,我画了一张图,里面几乎涵盖了所有数据结构和算法书籍中都会讲到的知识点。
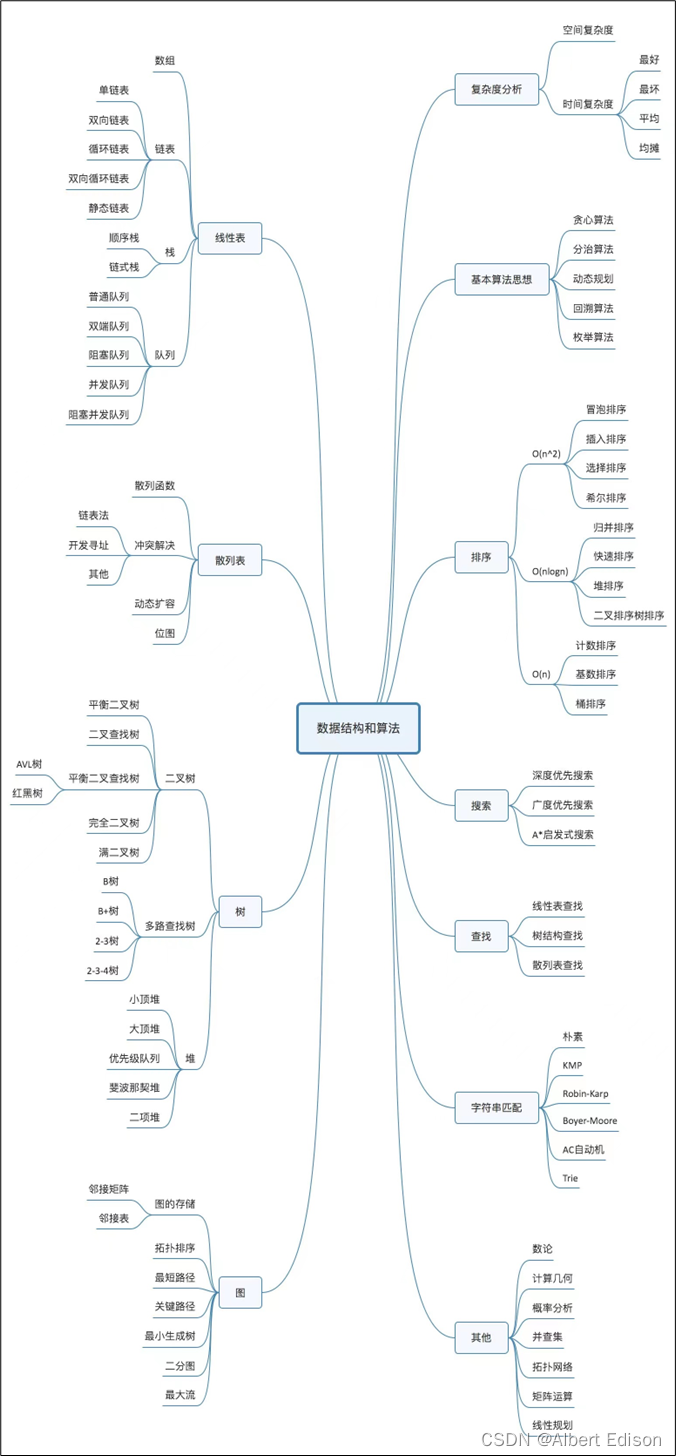
数据结构和算法解决的是如何更省、更快地存储和处理数据的问题,因此,我们就需要一个考量效率和资源消耗的方法,这就是复杂度分析方法。
所以,如果你只掌握了数据结构和算法的特点、用法,但是没有学会复杂度分析,那就相当于只知道操作口诀,而没掌握心法。只有把心法了然于胸,才能做到无招胜有招!
因此,复杂度分析这个内容,一定要花大力气来啃,必须要拿下,并且要搞得非常熟练。否则,后面的数据结构和算法也很难学好。
学习任何知识都要由浅入深,由易到难。线性表会是本专栏讲解的第一个数据结构,和其它结构相比,它更为简单直接,也最好理解,从代码实现上也最容易,是学习其他更复杂数据结构的基础。同样,也一定能让你对之后的学习更有信心。
不过,在一些复杂的领域中,线性表这种简单的数据结构还不足以表达问题,这个时候,树形结构就出现了。
它是算法面试中最常出现的数据结构,也是在实际开发中我们经常会有意无意用到的数据结构,想要写出正确且更高效的程序代码,这部分的内容还是要打好基础的。
图是比树形结构更复杂的数据结构。如果说树形结构的应用往往体现在程序编写中,那么对图的应用往往更接地气,更体现在实际生活中。
比如可以通过图来解决找出两个城市之间如何行走距离最短、最节省时间、花费的金钱最少问题等等,还可以用图来估算一个工程能否按顺序进行以及估算该工程需要的最短时间。
我们知道,数据结构是为算法服务的。所以在讲解完线性表、树形结构、图这三种数据结构后,我们正式进入到算法知识的讲解中。
在各种算法知识中,尤其以排序算法最经典,实用且在面试中最常出现。排序算法有十数种,每种排序算法的适用场合、时间以及空间复杂度、稳定性等各不相同,搞定了这部分的内容,也就可以应付面试了。
这种数据结构非常常见,同时也有着广泛的应用,比如在搜索引擎中搜索的关键词、在文章中需要过滤的敏感词等等,都属于字符串。
其中,最需要解决的问题是子串在整个字符串中的查找问题。主要介绍两种查找子串的算法实现方式。第一种实现方式称为朴素模式匹配算法,容易理解但执行效率相对较低;第二种是 KMP 模式匹配算法,这种算法执行效率很高,但理解起来却颇有难度。
尤其值得注意的是,有些面试官非常喜欢考 KMP 模式匹配算法实现的子串查找,这里的重要程度也就不言而喻了。
跳表与哈希表这两种数据结构都非常实用且有趣味性,可以理解成是属于更高级的数据结构范畴。不过放心,虽然高级,但代码实现上却没有那么复杂。
你可以把跳表看作强化版的线性表,可以极大提升元素查询速度。而哈希表是对数组的扩展,对于查找操作同样有非常良好的性能表现。引入这两个话题,一是为了丰富你的眼界和开发思路,以备在日后的开发中随时采用,二来也是避免不了的老调重弹 —— 为了应付面试的需要。
作为初学者,或者一个非算法工程师来说,你并不需要掌握上图里面的所有知识点。很多高级的数据结构与算法,比如二分图、最大流等,这些在我们平常的开发中很少会用到。所以,你暂时可以不用看。咱们学习要学会找重点。如果不分重点地学习,眉毛胡子一把抓,学起来肯定会比较吃力。
所以,只要集中精力逐一攻克这下面知识点就足够了。
掌握了这些基础的数据结构和算法,再学更加复杂的数据结构和算法,就会非常容易、非常快。
学习数据结构和算法的过程,是非常好的思维训练的过程,所以,千万不要被动地记忆,要多辩证地思考,多问为什么。如果你一直这么坚持做,你会发现,等你学完之后,写代码的时候就会不由自主地考虑到很多性能方面的事情,时间复杂度、空间复杂度非常高的垃圾代码出现的次数就会越来越少。你的编程内功就真正得到了修炼。
前面划了学习的重点,也讲了学习这门课需要具备的基础。现在我就给你分享一下,本专栏 「数据结构」 学习的一些技巧。掌握了这些技巧,可以让你化被动为主动,学起来更加轻松,更加有动力!
在学习的过程中,一定会碰到 拦路虎。如果哪个知识点没有怎么学懂,不要着急,这是正常的。因为,想听一遍、看一遍就把所有知识掌握,这肯定是不可能的。学习知识的过程是反复迭代、不断沉淀的过程。
因此,我特别希望这个专栏 「数据结构」 不仅能帮你抛下身上对于数据结构与算法的沉重包袱,更能潜移默化地为你打开思维,建立数据结构与算法的敏感度,为之后的每一次实战打下坚实的基础。
要记住,数据结构与算法,本来就是一件小事。
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
它不等于主线程的binding,这个toplevel作用域是什么?此作用域与主线程中的binding有何不同?>ruby-e'putsTOPLEVEL_BINDING===binding'false 最佳答案 事实是,TOPLEVEL_BINDING始终引用Binding的预定义全局实例,而Kernel#binding创建的新实例>Binding每次封装当前执行上下文。在顶层,它们都包含相同的绑定(bind),但它们不是同一个对象,您无法使用==或===测试它们的绑定(bind)相等性。putsTOPLEVEL_BINDINGput
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?