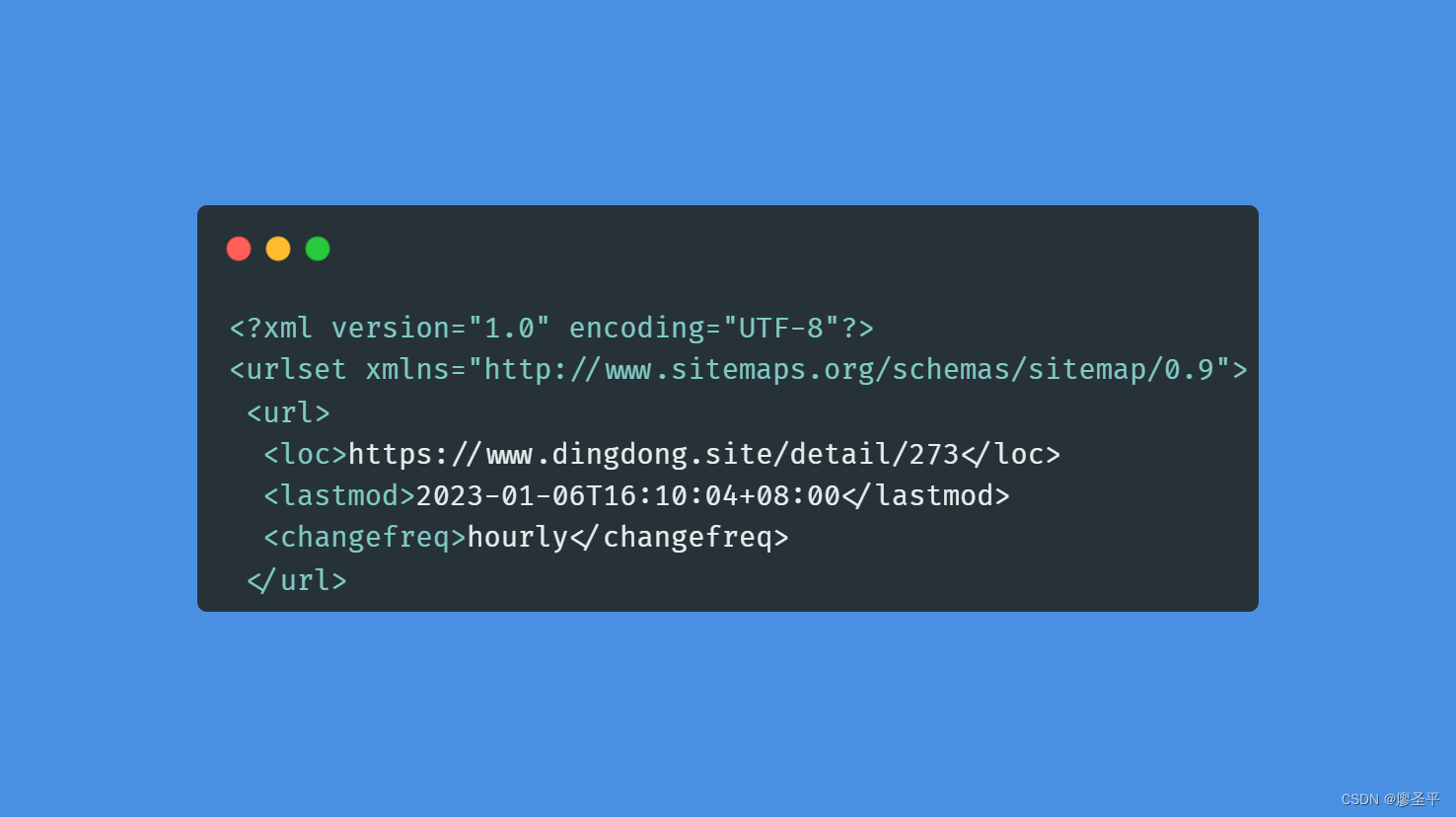
Sitemap 可方便网站管理员通知搜索引擎他们网站上有哪些可供抓取的网页。最简单的 Sitemap 形式,就是XML 文件,在其中列出网站中的网址以及关于每个网址的其他元数据(上次更新的时间、更改的频率以及相对于网站上其他网址的重要程度为何等),以便搜索引擎可以更加智能地抓取网站。
laravel /php
搜索引擎肯定是希望把开发者提供的服务器直接给他,所以需要有一个统一的格式给搜索引擎的蜘蛛。这样搜索引擎就可以直接读取这个xml文件,不需要爬整个网站的数据。
下面用代码实现:
用一个来自俄罗斯的开发者:Maintainers,应该很多老铁认识他,yii的维护者

composer require samdark/sitemap
按照这边的例子,很方便的实现网站地图的生成
use samdark\sitemap\Sitemap;
use samdark\sitemap\Index;
// create sitemap
$sitemap = new Sitemap(__DIR__ . '/sitemap.xml');
// add some URLs
$sitemap->addItem('http://example.com/mylink1');
$sitemap->addItem('http://example.com/mylink2', time());
$sitemap->addItem('http://example.com/mylink3', time(), Sitemap::HOURLY);
$sitemap->addItem('http://example.com/mylink4', time(), Sitemap::DAILY, 0.3);
// set sitemap stylesheet (see example-sitemap-stylesheet.xsl)
$sitemap->setStylesheet('http://example.com/css/sitemap.xsl');
// write it
$sitemap->write();
我的网站是一个纸尿裤分析的网站,所以我只需要把所有的纸尿裤的详情页给蜘蛛了
$sitemap = new \samdark\sitemap\Sitemap(public_path('/sitemap.xml'));
$data = GoodsSku::query()
->whereNotNull('image_url')
->where('unit_amount','>',0)
->get();
foreach ($data as $item){
/**
* @var GoodsSku $item
*/
$sitemap->addItem('https://www.dingdong.site/detail/'.$item->id,strtotime($item->updated_at),\samdark\sitemap\Sitemap::HOURLY);
}
$sitemap->setStylesheet('https://www.dingdong.site/sitemap.xml');
$sitemap->write();
将生生成好的xml文件放在根目录中,定时任务可以每天触发这个程序生成sitemap文件。
这边addItem中几个参数说一下:
第一个: 网站的具体路径
第二个: 是数据更新的时间戳
第三个:说明下网站数据更新的频率
第四个:该数据在网站中的权重(比如我的纸尿裤,帮宝适卖得最好,那就可以把这个权重设高一点)
这时访问 https://www.dingdong.site/sitemap.xml 蜘蛛就能检索到这个文件了,具体能不能爬到呢?这个我也不懂,过几个月再过来看看吧。
我正在研究使用EventMachine支持的twitter-streamrubygem来跟踪和捕获推文。我对整个事件编程有点陌生。我如何判断我在事件循环中所做的任何处理是否导致我落后?有没有简单的检查方法? 最佳答案 您可以通过使用周期性计时器并打印出耗时来确定延迟。如果您使用的是1秒的计时器,您应该已经过了大约1秒,如果它更长,您就知道您正在减慢react器的速度。@last=Time.now.to_fEM.add_periodic_timer(1)doputs"LATENCY:#{Time.now.to_f-@last}"@
这里还有一个新手问题:require'tasks/rails'我在每个Rails项目的根路径中的Rakefile中看到了这一行。我猜这行用于要求vendor/rails/railties/lib/tasks/rails.rb加载所有rake任务:$VERBOSE=nil#LoadRailsrakefileextensionsDir["#{File.dirname(__FILE__)}/*.rake"].each{|ext|loadext}#LoadanycustomrakefileextensionsDir["#{RAILS_ROOT}/lib/tasks/**/*.rake"].so
我正在尝试使用Rails站点map_generatorgem为一个包含8,000,00个页面的站点生成站点地图。gem可以在这里找到:https://github.com/kjvarga/sitemap_generator这是我在sitemap.rb中的代码:require'rubygems'require'sitemap_generator'#SetthehostnameforURLcreationSitemapGenerator::Sitemap.default_host="http://www.mysite.com"SitemapGenerator::Sitemap.create
3月26日,映宇宙(HK:03700,即“映客”)发布截至2022年12月31日的2022年度业绩财务报告。财报显示,映宇宙2022年的总营收为63.19亿元,较2021年同期的91.76亿元下降31.1%。2022年,映宇宙的经营亏损为4698.7万元,2021年同期则为净利润4.57亿元;期内亏损(净亏损)为1.68亿元,2021年同期的净利润为4.33亿元;非国际财务报告准则经调整净利润为3.88亿元,2021年同期为4.82亿元,同比下降19.6%。 映宇宙在财报中表示,收入减少主要是由于行业竞争加剧,该集团对旗下产品采取更为谨慎的运营策略以应对市场变化。不过,映宇宙的毛利率则有所提升
我希望Ruby的解析器会进行这种微不足道的优化,但似乎并没有(谈到YARV实现,Ruby1.9.x、2.0.0):require'benchmark'deffib1a,b=0,1whileb由于这两种方法除了在第二种方法中使用预定义常量而不是常量表达式外是相同的,因此Ruby解释器似乎在每个循环中一次又一次地计算幂常数。是否有一些Material说明为什么Ruby根本不进行这种基本优化或只在某些特定情况下进行? 最佳答案 很抱歉给出了另一个答案,但我不想删除或编辑我之前的答案,因为它下面有有趣的讨论。正如JörgWMittag所说,
我正在尝试从数据库中读取大量单元格(超过100.000个)并将它们写入VPSUbuntu服务器上的csv文件。碰巧服务器没有足够的内存。我正在考虑一次读取5000行并将它们写入文件,然后再读取5000行,等等。我应该如何重构我当前的代码以使内存不会被完全消耗?这是我的代码:defwrite_rows(emails)File.open(file_path,"w+")do|f|f该函数由sidekiqworker调用:write_rows(user.emails)感谢您的帮助! 最佳答案 这里的问题是,当您调用emails.each时,
下面的代码通过ftp上传文件并且它有效。require'net/ftp'ftp=Net::FTP.newftp.passive=trueftp.connect("***")ftp.login("***","***")ftp.chdir"claimsecure-xml-files"ftp.putbinaryfile("file.xls",File.basename("file.xls"))ftp.quit但是如何确定上传是否成功呢? 最佳答案 之后ftp.putbinaryfile("file.xls",File.basename("
文章目录前言约束硬约束的轨迹优化Corridor-BasedTrajectoryOptimizationBezierCurveOptimizationOtherOptions软约束的轨迹优化Distance-BasedTrajectoryOptimization优化方法前言可以看看我的这几篇Blog1,Blog2,Blog3。上次基于MinimumSnap的轨迹生成,有许多优点,比如:轨迹让机器人可以在某个时间点抵达某个航点。任何一个时刻,都能数学上求出期望的机器人的位置、速度、加速度、导数。MinimumSnap可以把问题转换为凸优化问题。缺点:MnimumSnap可以控制轨迹一定经过中间的
我对为我的RubyonRails3.1.3应用优化我的Unicorn设置的方法很感兴趣。我目前正在高CPU超大实例上生成14个工作进程,因为我的应用程序在负载测试期间似乎受CPU限制。在模拟负载测试中,每秒大约20个请求重放请求,我的实例上的所有8个内核都达到峰值,盒子负载飙升至7-8个。每个unicorn实例使用大约56-60%的CPU。我很好奇可以通过哪些方式对其进行优化?我希望能够每秒将更多请求汇集到这种大小的实例上。内存和所有其他I/O一样完全正常。在我的测试过程中,CPU越来越低。 最佳答案 如果您受CPU限制,您希望使用
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此