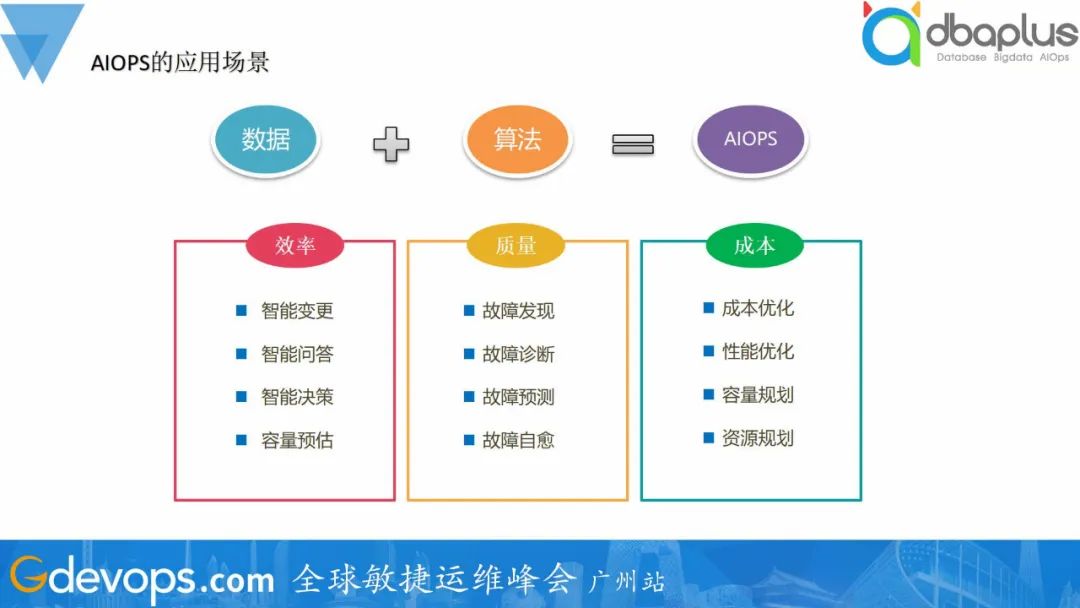
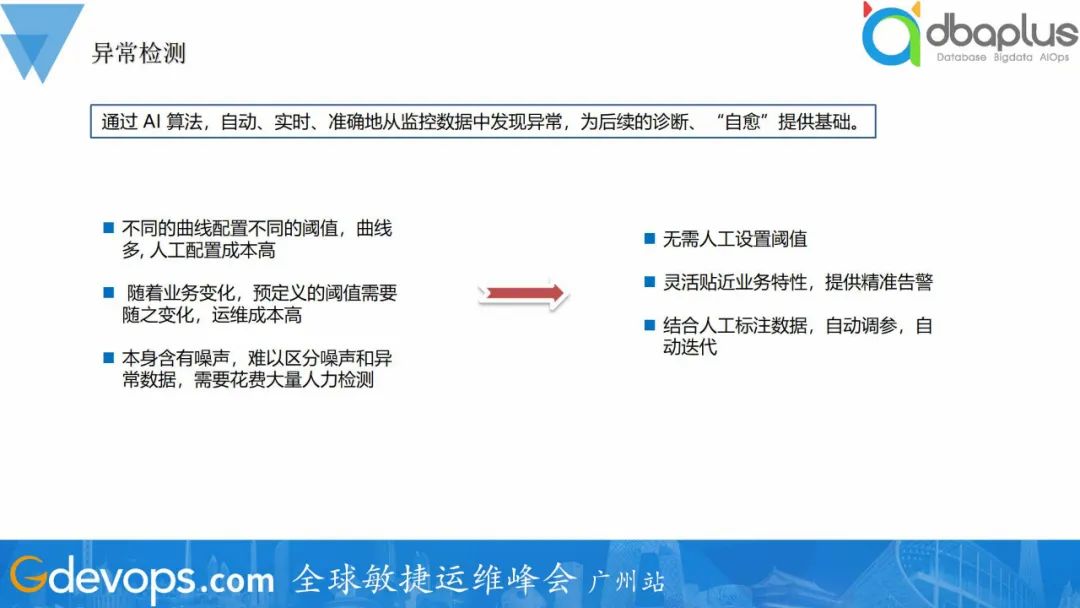
 对于异常检测,其实网上很多文档或者书籍都给出了一些算法或者工具,但在实际运用的过程中,会发现效果往往不是很好,究其原因是这些算法只能有效地针对一些特定的场景、以及需要做很多的优化来适配实际的场景。为了更好地在实际场景中落地,我们对算法做了一些调整优化,并结合业务需求对指标进行划分,达到更好的检测效果。我们将异常检测根据指标类型划分成了三种场景----业务黄金指标(如游戏在线人数)、性能指标(如cpu使用率)、文本数据(如日志),采用不同的检测算法。
对于异常检测,其实网上很多文档或者书籍都给出了一些算法或者工具,但在实际运用的过程中,会发现效果往往不是很好,究其原因是这些算法只能有效地针对一些特定的场景、以及需要做很多的优化来适配实际的场景。为了更好地在实际场景中落地,我们对算法做了一些调整优化,并结合业务需求对指标进行划分,达到更好的检测效果。我们将异常检测根据指标类型划分成了三种场景----业务黄金指标(如游戏在线人数)、性能指标(如cpu使用率)、文本数据(如日志),采用不同的检测算法。
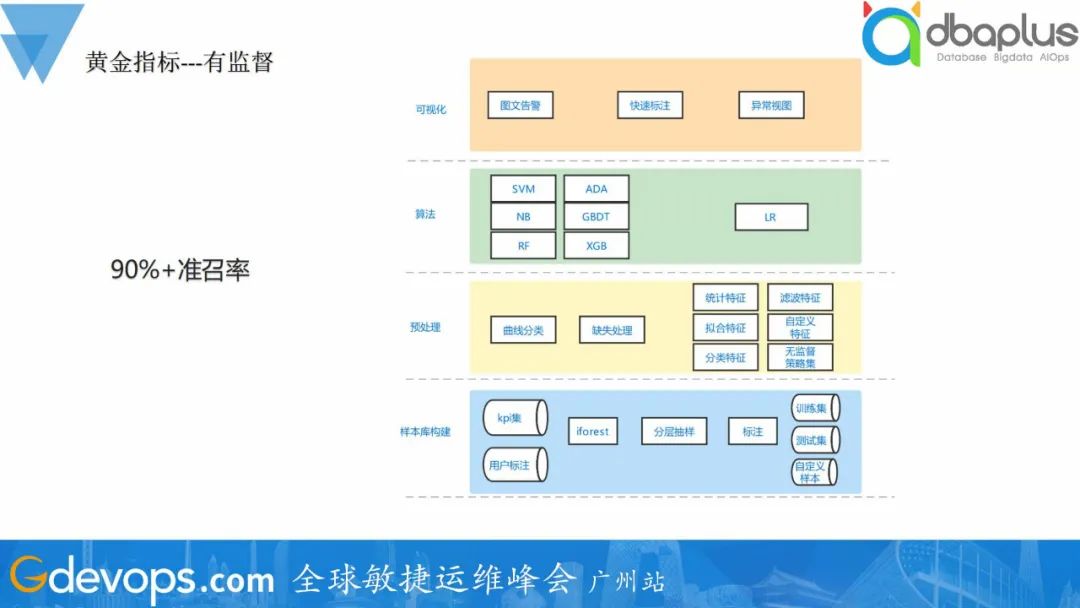 通过有监督模型的方式可达到高准召率的检测效果,线上检测效果可达到90%+,可满足用户的需求。
通过有监督模型的方式可达到高准召率的检测效果,线上检测效果可达到90%+,可满足用户的需求。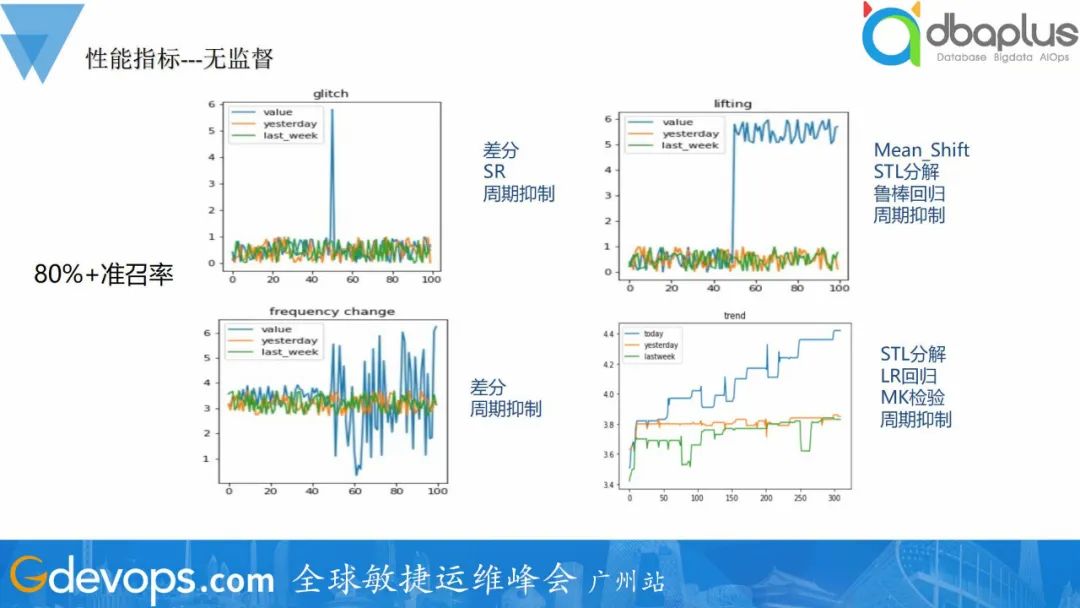 无监督的检测模型,准召率可达到80%+,基本可达到用户预期。通过图文告警的方式告警,帮助用户快速确认报警的正确性。
无监督的检测模型,准召率可达到80%+,基本可达到用户预期。通过图文告警的方式告警,帮助用户快速确认报警的正确性。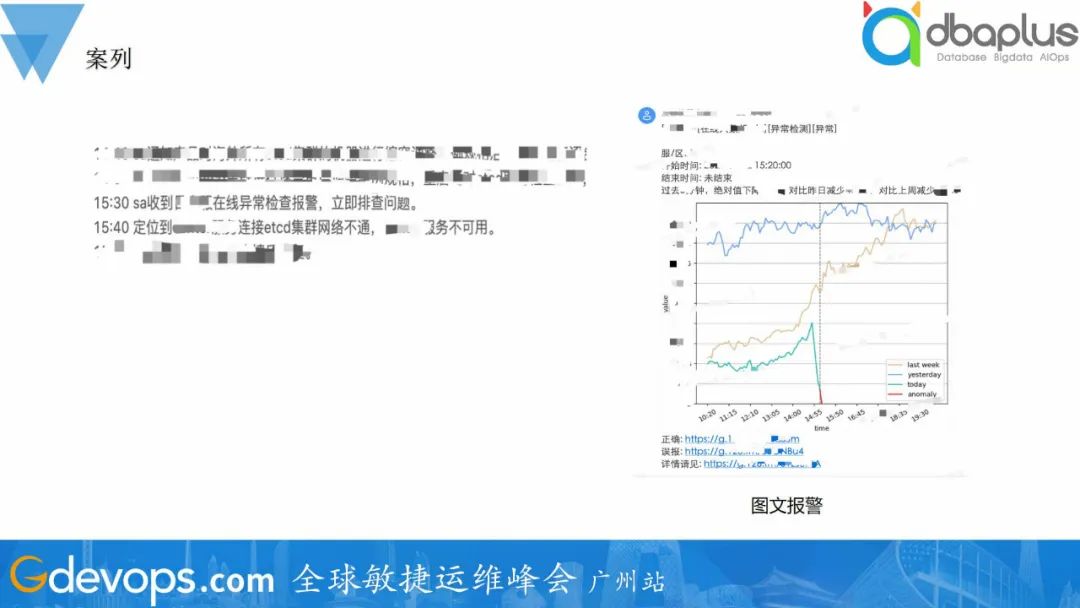
 目前业界日志分类的算法相对成熟,有很多的算法都可以达到不错的效果。一次分类我们采用drain算法,然后Spell进行二次分类,解决一次分类长度不同日志分在不同模板的问题。
目前业界日志分类的算法相对成熟,有很多的算法都可以达到不错的效果。一次分类我们采用drain算法,然后Spell进行二次分类,解决一次分类长度不同日志分在不同模板的问题。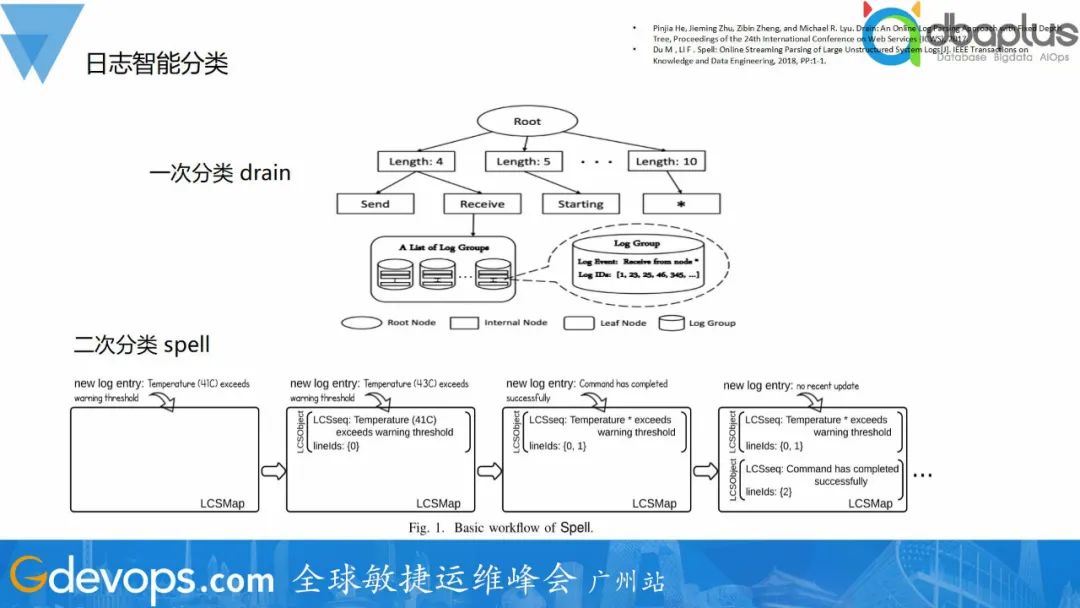 得到日志模板后,可以基于日志模板数量进行异常检测。智能异常检测会对比不同时间段的分类日志数量,利用机器学习模型自动识别突变或者和历史趋势不一致的日志类型,并发出告警信息:
得到日志模板后,可以基于日志模板数量进行异常检测。智能异常检测会对比不同时间段的分类日志数量,利用机器学习模型自动识别突变或者和历史趋势不一致的日志类型,并发出告警信息: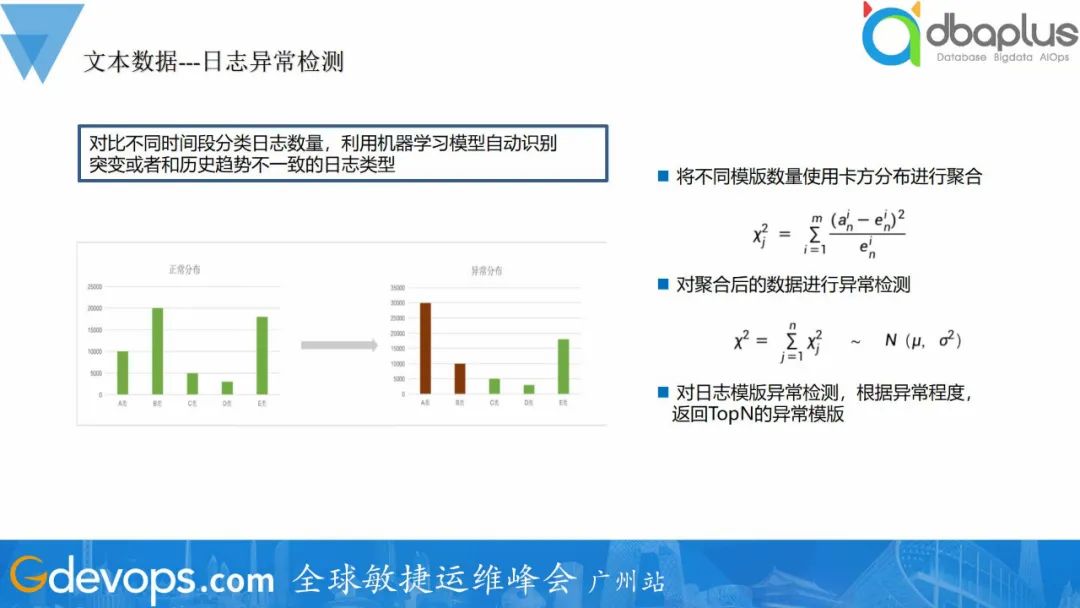 与指标异常检测不同,日志异常检测可以检测到代码类型异常,对程序排障有重大帮助。此外,日志分类可以对日志治理也要很大的帮助,新项目/服务上线时候通过审查日志模板,可以根据需求整理、删除无效日志。
与指标异常检测不同,日志异常检测可以检测到代码类型异常,对程序排障有重大帮助。此外,日志分类可以对日志治理也要很大的帮助,新项目/服务上线时候通过审查日志模板,可以根据需求整理、删除无效日志。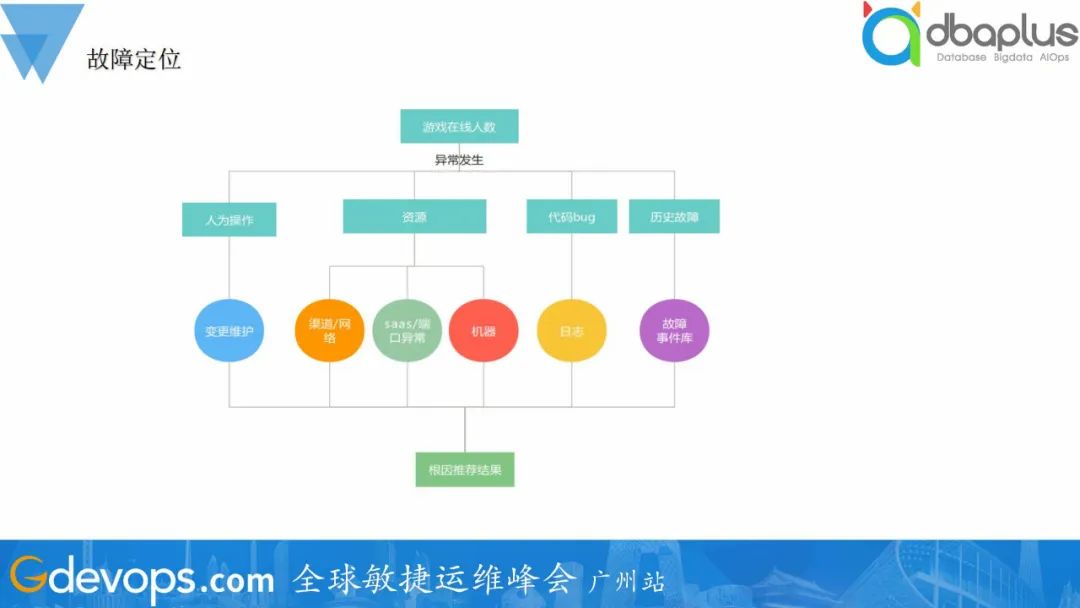
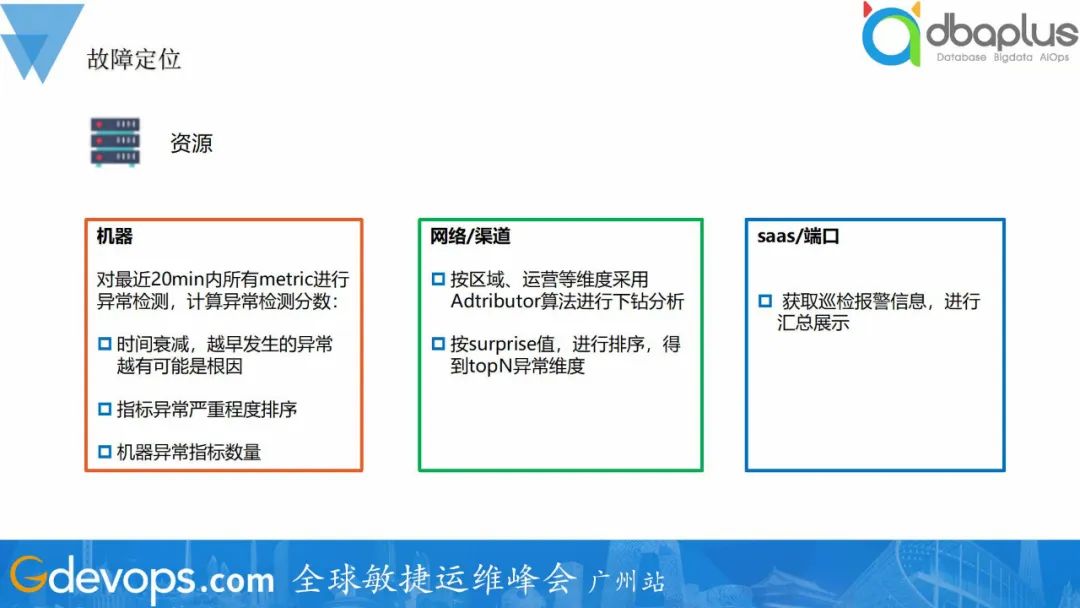
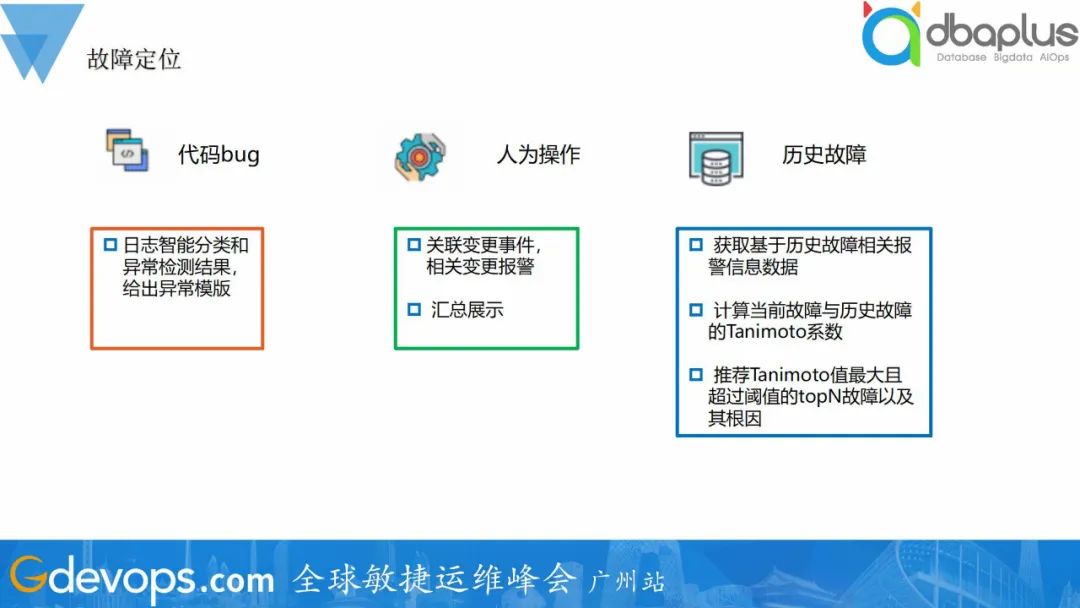 整体的故障定位流程,检测到故障的发生,基于拓扑资源、代码、人为因素、历史故障这几个角度出发,采用不同的方式进行根因分析。如检测到游戏在线人数下降,出发故障定位流程,检测到机器A 网络连接异常,告警出网络问题,人工进行排查出公网故障导致。
整体的故障定位流程,检测到故障的发生,基于拓扑资源、代码、人为因素、历史故障这几个角度出发,采用不同的方式进行根因分析。如检测到游戏在线人数下降,出发故障定位流程,检测到机器A 网络连接异常,告警出网络问题,人工进行排查出公网故障导致。我正在学习Rails,并阅读了关于乐观锁的内容。我已将类型为integer的lock_version列添加到我的articles表中。但现在每当我第一次尝试更新记录时,我都会收到StaleObjectError异常。这是我的迁移:classAddLockVersionToArticle当我尝试通过Rails控制台更新文章时:article=Article.first=>#我这样做:article.title="newtitle"article.save我明白了:(0.3ms)begintransaction(0.3ms)UPDATE"articles"SET"title"='dwdwd
在Cooper的书BeginningRuby中,第166页有一个我无法重现的示例。classSongincludeComparableattr_accessor:lengthdef(other)@lengthother.lengthenddefinitialize(song_name,length)@song_name=song_name@length=lengthendenda=Song.new('Rockaroundtheclock',143)b=Song.new('BohemianRhapsody',544)c=Song.new('MinuteWaltz',60)a.betwee
我早就知道Ruby中的“常量”(即大写的变量名)不是真正常量。与其他编程语言一样,对对象的引用是唯一存储在变量/常量中的东西。(侧边栏:Ruby确实具有“卡住”引用对象不被修改的功能,据我所知,许多其他语言都没有提供这种功能。)所以这是我的问题:当您将一个值重新分配给常量时,您会收到如下警告:>>FOO='bar'=>"bar">>FOO='baz'(irb):2:warning:alreadyinitializedconstantFOO=>"baz"有没有办法强制Ruby抛出异常而不是打印警告?很难弄清楚为什么有时会发生重新分配。 最佳答案
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
修改(澄清问题)我已经花了几天时间试图弄清楚如何从Facebook游戏中抓取特定信息;但是,我遇到了一堵又一堵砖墙。据我所知,主要问题如下。我可以使用Chrome的检查元素工具手动查找我需要的html-它似乎位于iframe中。但是,当我尝试抓取该iframe时,它是空的(属性除外):如果我使用浏览器的“查看页面源代码”工具,这与我看到的输出相同。我不明白为什么我看不到iframe中的数据。答案不是它是由AJAX之后添加的。(我知道这既是因为“查看页面源代码”可以读取Ajax添加的数据,也是因为我有b/c我一直等到我可以看到数据页面之后才抓取它,但它仍然不存在)。发生这种情况是因为
我们如何捕获或/和处理ruby中所有未处理的异常?例如,这样做的动机可能是将某种异常记录到不同的文件或发送电子邮件给系统管理。在Java中我们会做Thread.setDefaultUncaughtExceptionHandler(UncaughtExceptionHandlerex);在Node.js中process.on('uncaughtException',function(error){/*code*/});在PHP中register_shutdown_function('errorHandler');functionerrorHandler(){$error=error_
如何在出现异常时指定全局救援,如果您将Sinatra用于API或应用程序,您将如何处理日志记录? 最佳答案 404可以在not_found方法的帮助下处理,例如:not_founddo'Sitedoesnotexist.'end500s可以通过调用带有block的错误方法来处理,例如:errordo"Applicationerror.Plstrylater."end错误的详细信息可以通过request.env中的sinatra.error访问,如下所示:errordo'Anerroroccured:'+request.env['si
我构建了一个简单的银行应用程序,它能够执行通常的操作;充值、提现等我的Controller方法执行这些操作并拯救由帐户或其他实体引发的异常。以下是Controller代码中使用的一些方法:defopen(type,with:)account=createtype,(holders.findwith)addaccountinit_yearly_interest_foraccountboundary.renderAccountSuccessMessage.new(account)rescueItemExistError=>messageboundary.rendermessageendde
我查看了Stripedocumentationonerrors,但我仍然无法正确处理/重定向这些错误。基本上无论发生什么,我都希望他们返回到edit操作(通过edit_profile_path)并向他们显示一条消息(无论成功与否)。我在edit操作上有一个表单,它可以POST到update操作。使用有效的信用卡可以正常工作(费用在Stripe仪表板中)。我正在使用Stripe.js。classExtrasController5000,#amountincents:currency=>"usd",:card=>token,:description=>current_user.email)
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion是否有适用于这些的3d游戏引擎?