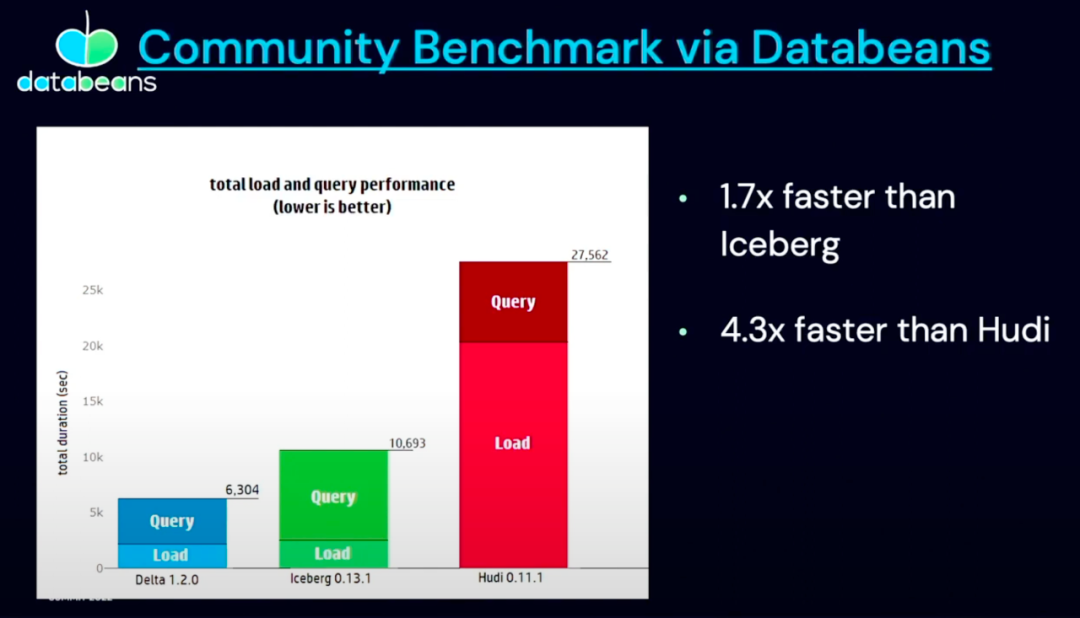
 虽然 Databricks 的工程师反复强调性能测试来自第三方 Databeans,并且他们没有主动要求 Databeans做这项测试,但如果全程看完 delta2.0 发布会,会发现在 delta2.0 即将开放的 key feature 中,特别列出了 Iceberg 到 Delta 的转换功能,并且官方着重讲到了 Adobe 从 Iceberg 迁移到 Delta2.0 的实践,这就难免让人浮想联翩了。
虽然 Databricks 的工程师反复强调性能测试来自第三方 Databeans,并且他们没有主动要求 Databeans做这项测试,但如果全程看完 delta2.0 发布会,会发现在 delta2.0 即将开放的 key feature 中,特别列出了 Iceberg 到 Delta 的转换功能,并且官方着重讲到了 Adobe 从 Iceberg 迁移到 Delta2.0 的实践,这就难免让人浮想联翩了。
 按照 Databricks 的构想,delta1.0 作为 lakehouse 解决方案,可以让数据湖更多,更快地作用于实时和 AI 场景,databricks 提出 delta 架构帮助用户从 lambda 架构中解放出来,核心思想是数据湖既可以跑批,也可以跑流,流计算和批计算的流程和代码可以复用,这样用户没有了维护 lambda 架构的负担,当然计算引擎必须是 spark。遗憾的是 spark streaming 和 struct streaming 在国内用户体量很小,绝大部分用户对 delta1.0 是望梅止渴,对 spark 的深度绑定也一定程度上限制了 delta 社区的发展,给 iceberg 的崛起预埋了伏笔,截止 2022 Q1 社区活跃度的一个对比如下:
按照 Databricks 的构想,delta1.0 作为 lakehouse 解决方案,可以让数据湖更多,更快地作用于实时和 AI 场景,databricks 提出 delta 架构帮助用户从 lambda 架构中解放出来,核心思想是数据湖既可以跑批,也可以跑流,流计算和批计算的流程和代码可以复用,这样用户没有了维护 lambda 架构的负担,当然计算引擎必须是 spark。遗憾的是 spark streaming 和 struct streaming 在国内用户体量很小,绝大部分用户对 delta1.0 是望梅止渴,对 spark 的深度绑定也一定程度上限制了 delta 社区的发展,给 iceberg 的崛起预埋了伏笔,截止 2022 Q1 社区活跃度的一个对比如下: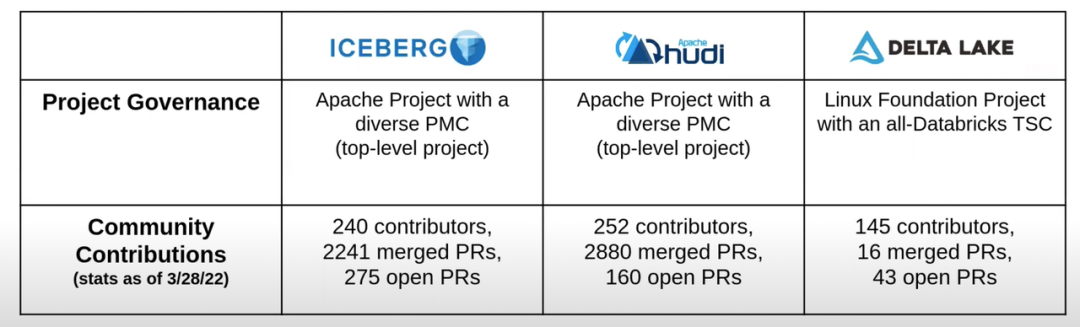 但另一方面,我们也绝不能忽略 Databricks 作为一家运营多年的商业公司,已有相当体量的付费用户,再加上对 spark 社区的主导权,成熟的营销和渠道能力,也许很容易重新建立开源上的优势。Delta 是 Lakehouse 的解决方案,Databricks 也被当做 lakehouse 的代表,但是 delta 这个项目自身的定义却经历了一些变化,我关注到去年某个时间点之前, delta 定义为 open format,引擎中可以直接用 delta 替换 parquet。
但另一方面,我们也绝不能忽略 Databricks 作为一家运营多年的商业公司,已有相当体量的付费用户,再加上对 spark 社区的主导权,成熟的营销和渠道能力,也许很容易重新建立开源上的优势。Delta 是 Lakehouse 的解决方案,Databricks 也被当做 lakehouse 的代表,但是 delta 这个项目自身的定义却经历了一些变化,我关注到去年某个时间点之前, delta 定义为 open format,引擎中可以直接用 delta 替换 parquet。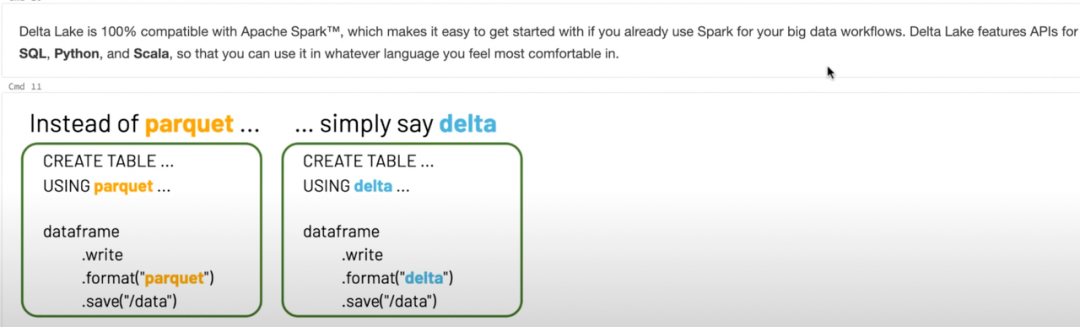 Format 的定义与 iceberg 的 table format 的定义非常相似,但在目前官网中,以及各种相关的分享和博客中,再也见不到此类描述,目前 delta 被官方定义为 lakehouse storage framework,当然,无论 format 还是 framework,汤还是那个汤,只是菜谱更加丰满了。1.2 Iceberg Iceberg 是由 Netflix 团队研发并开源的数据湖 table format,创始人 Ryan Blue 是 spark,parquet,avro 的 PMC,在数据分析领域有非常丰富的经验和人脉,co-fonder 中还有一位来自 Cloudera 的资深工程师,从时间线上看,iceberg 2018年进入 apache 孵化,2020 年毕业,考虑到项目本身的研发周期,很难评判它和 delta 的时间先后,再加上创始人本身是活跃的 spark 贡献者,两个项目从一开始就高度相似。从功能上看,套用知乎上的一句话:不能说非常相似,只能说一模一样。从发展上看,iceberg 更加符合一个开源项目的气质,早期这个项目更多是为了应对 Netflix 对大体量数据分析的需求,重点强调了以下的特性:ACID 和 MVCC 的特性,读数据时不会读到写入的不一致状态
Format 的定义与 iceberg 的 table format 的定义非常相似,但在目前官网中,以及各种相关的分享和博客中,再也见不到此类描述,目前 delta 被官方定义为 lakehouse storage framework,当然,无论 format 还是 framework,汤还是那个汤,只是菜谱更加丰满了。1.2 Iceberg Iceberg 是由 Netflix 团队研发并开源的数据湖 table format,创始人 Ryan Blue 是 spark,parquet,avro 的 PMC,在数据分析领域有非常丰富的经验和人脉,co-fonder 中还有一位来自 Cloudera 的资深工程师,从时间线上看,iceberg 2018年进入 apache 孵化,2020 年毕业,考虑到项目本身的研发周期,很难评判它和 delta 的时间先后,再加上创始人本身是活跃的 spark 贡献者,两个项目从一开始就高度相似。从功能上看,套用知乎上的一句话:不能说非常相似,只能说一模一样。从发展上看,iceberg 更加符合一个开源项目的气质,早期这个项目更多是为了应对 Netflix 对大体量数据分析的需求,重点强调了以下的特性:ACID 和 MVCC 的特性,读数据时不会读到写入的不一致状态可以看出 hudi 想干很多事,并且给自己建立了像数据库一样的目标,这个目标的达成有很长的路要走。Hudi 在三个项目中最早提供 stream upsert 能力 ,如果不做二次开发,hudi 是开箱即用的数据湖 upsert 方案,并且 hudi 社区对开发者非常开放,和 iceberg 专注又谨慎的调性可谓两个极端,但 hudi 大版本之间的变化很大,这个方面先压下不表,有机会专门开个文章聊聊。最早的时候 hudi 只有 spark 下的实现,为了支持 flink 在重构方面社区下了很大的功夫(delta类似),这也是 2020 年没有选择 hudi 的最重要原因,在 hudi 的核心团队创业成立 Onehouse 之后,hudi 的定位明显和其他两家产生了较大的分化,databricks 作为一家商业公司,delta 是他吸引流量的重要手段,商业化上再通过上层的数据开发,治理和 AI platform 变现,同理从公开信息看, Ryan Blue 成立的 Tabular 也是在 iceberg 之上构建 platform,和 table format 泾渭分明。而 hudi 自身已经将自己拔到 platform 的高度,虽然功能上还距离很远,但可以预见长期的 roadmap 会产生较大不同。出于竞争的考虑,delta 和 iceberg 有的,hudi 可能都会跟进,所以 hudi 也可以作为 table format 来使用。当我们为企业做技术选型时,需要考虑是选择一个纯净的 table format 整合到自己的 platform 中,还是选择一个新的 platform 或者将 platform 融合。2、Iceberg 背刺与 delta2.0 的反击现在下判断,为时尚早。如果一定要对比,我更加喜欢对比 delta 和 iceberg,因为 hudi 的愿景和前两个有较大的不同,换句话说,就 table format 而言,delta 和 iceberg 可能更懂要做什么,就懂的层面两讲,iceberg 我认为更胜一筹。拿最近 delta 2.0 发布的内容来看,有兴趣的同学可以去看下 Databricks 官方举办的 Data + AI summit 2022 的 相关分享。发布会重点提及的功能总结如下:
Hudi is a rich platform to build streaming data lakes with incremental data pipelines on a self-managing database layer while being optimized for lake engines and regular batch processing.
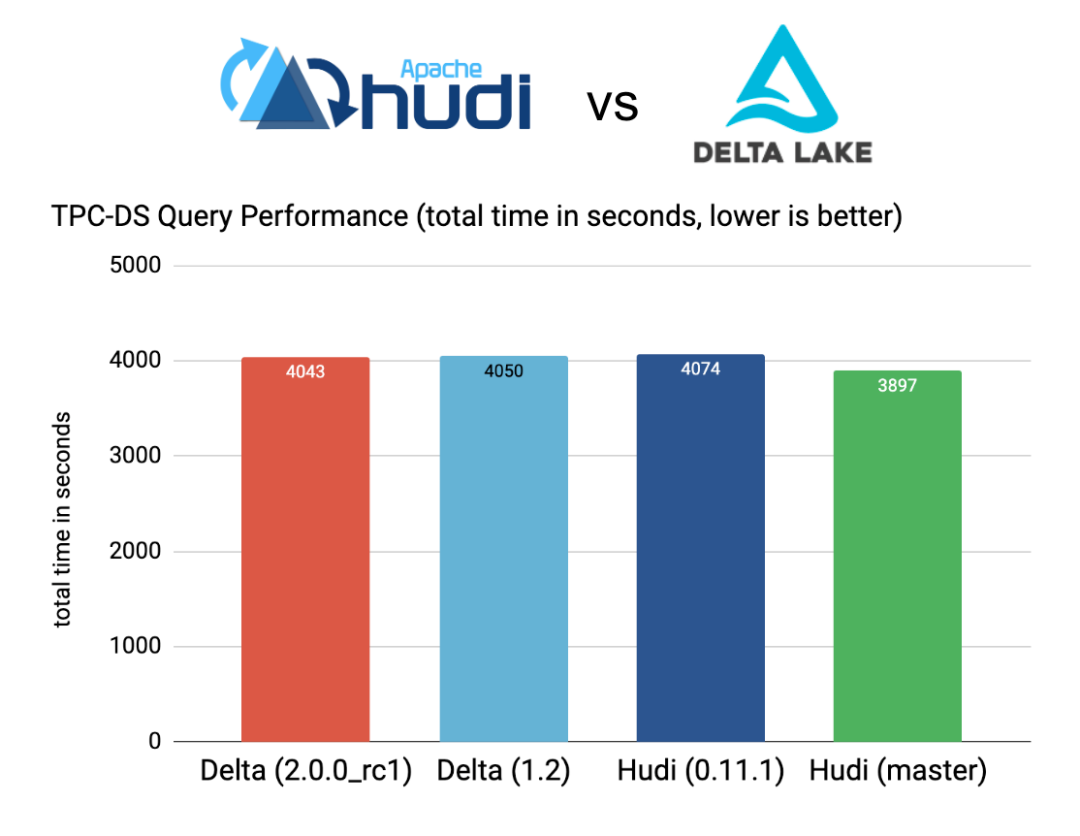 作为一名相关从业者,Delta2.0 的完全开源是一件振奋人心的事,几乎可以下结论,delta2.0 和 iceberg 重叠的功能,会成为数据湖 table format 的事实标准,在这个方向上提前投资的产品和开发者有可能更快地收获果实。至于谁更优秀?iceberg 的开放,专注和执行力让人叹服,delta 的影响力,商业资源和成熟度不可忽略。从功能和外围生态看,iceberg 依然有至少 1-2 年的先发优势,但是生长在 iceberg 上原汁原味的 Tablur 还没影,delta 的平台背书本就超强,再向其他引擎开放了 connector 和 API 之后,相信开源的贡献者和影响力也会同步跟进,期待 delta 社区在活跃度上可以迎头赶上。3、新技术推广的困局作为一名基础软件工程师,自底向上倒逼需求是非常艰难的,想要业务团队切换基础软件可能同时需要天时地利人和,而研究数据湖的同学相信在过去两年推动业务时多少会遇到力不从心的局面,这里我来分享一些我的理解。我们将目前数据湖 Format 已经形成的标准能力做一个小结:
作为一名相关从业者,Delta2.0 的完全开源是一件振奋人心的事,几乎可以下结论,delta2.0 和 iceberg 重叠的功能,会成为数据湖 table format 的事实标准,在这个方向上提前投资的产品和开发者有可能更快地收获果实。至于谁更优秀?iceberg 的开放,专注和执行力让人叹服,delta 的影响力,商业资源和成熟度不可忽略。从功能和外围生态看,iceberg 依然有至少 1-2 年的先发优势,但是生长在 iceberg 上原汁原味的 Tablur 还没影,delta 的平台背书本就超强,再向其他引擎开放了 connector 和 API 之后,相信开源的贡献者和影响力也会同步跟进,期待 delta 社区在活跃度上可以迎头赶上。3、新技术推广的困局作为一名基础软件工程师,自底向上倒逼需求是非常艰难的,想要业务团队切换基础软件可能同时需要天时地利人和,而研究数据湖的同学相信在过去两年推动业务时多少会遇到力不从心的局面,这里我来分享一些我的理解。我们将目前数据湖 Format 已经形成的标准能力做一个小结: 那么这套方法论适用于其他企业吗?我认为答案是肯定的,但是要稍作修改,首先 Databricks 公司做这个项目比较早,并且是作为一个战略型项目来做,它的产品,上层建筑一定是同步跟进的,这也让他的整套 platform 受益于 Lakehouse 非常简洁,而大部分企业用户历史负担要重很多,产品适配牵一发动全身。另一方面,国内基本上实时计算用 Flink,这里不评价 Flink 和 Spark 哪个更好,现实是绝大多数企业不会绑定一个计算引擎,这也是为什么引擎平权对数据湖极为重要,重要到 Delta 也不得不妥协,不同引擎的应用可以吸收各家优势,但会带来产品割裂的问题,主流大数据平台的供应商大多把实时计算作为一个单独的产品入口,当然这背后的原因不光是引擎的问题 ,最重要的依然是存储方案的不统一。产品割裂在大数据方法论的迭代中被更加放大,比如在数据中台中,指标系统,数据模型,数据质量,数据资产这一套中台模块基本是围绕离线场景打造,而在强调 CICD 的 Dataops 中,流计算的需求和场景因为存储和计算的不统一更加难以被纳入考量。这个状况的直接结果是实时数仓,流计算对应的场景和需求在大数据平台的方法论迭代中被边缘化,用户无法在实时场景下体验到数据安全,数据质量,数据治理带来的收益,变本加厉的是,很多既需要实时也需要离线的场景下,用户需要维护流表和批表两套模型,两套代码,并且时刻警惕语义和模型的二义性。了解了 Lakehouse 意义,立足于现实,以网易数帆为例,新的数据湖技术应当帮助 dataops 拓展边界,让数据开发和运维,数据治理的整套体系囊括实时和 AI 的场景,流批一体的数据湖肩负着为业务实现去 lambda 的架构,产品的交互和体验应当更加简洁和高效,让算法分析师,数据科学家,对时效性更加敏感的风控等场景也能按照 Dataops 的标准和规范快速上手,可以用数据治理的方法论优化成本。聊到这里,可能会觉得越来越抽象,我们来举一个数据分析的 lambda 架构:
那么这套方法论适用于其他企业吗?我认为答案是肯定的,但是要稍作修改,首先 Databricks 公司做这个项目比较早,并且是作为一个战略型项目来做,它的产品,上层建筑一定是同步跟进的,这也让他的整套 platform 受益于 Lakehouse 非常简洁,而大部分企业用户历史负担要重很多,产品适配牵一发动全身。另一方面,国内基本上实时计算用 Flink,这里不评价 Flink 和 Spark 哪个更好,现实是绝大多数企业不会绑定一个计算引擎,这也是为什么引擎平权对数据湖极为重要,重要到 Delta 也不得不妥协,不同引擎的应用可以吸收各家优势,但会带来产品割裂的问题,主流大数据平台的供应商大多把实时计算作为一个单独的产品入口,当然这背后的原因不光是引擎的问题 ,最重要的依然是存储方案的不统一。产品割裂在大数据方法论的迭代中被更加放大,比如在数据中台中,指标系统,数据模型,数据质量,数据资产这一套中台模块基本是围绕离线场景打造,而在强调 CICD 的 Dataops 中,流计算的需求和场景因为存储和计算的不统一更加难以被纳入考量。这个状况的直接结果是实时数仓,流计算对应的场景和需求在大数据平台的方法论迭代中被边缘化,用户无法在实时场景下体验到数据安全,数据质量,数据治理带来的收益,变本加厉的是,很多既需要实时也需要离线的场景下,用户需要维护流表和批表两套模型,两套代码,并且时刻警惕语义和模型的二义性。了解了 Lakehouse 意义,立足于现实,以网易数帆为例,新的数据湖技术应当帮助 dataops 拓展边界,让数据开发和运维,数据治理的整套体系囊括实时和 AI 的场景,流批一体的数据湖肩负着为业务实现去 lambda 的架构,产品的交互和体验应当更加简洁和高效,让算法分析师,数据科学家,对时效性更加敏感的风控等场景也能按照 Dataops 的标准和规范快速上手,可以用数据治理的方法论优化成本。聊到这里,可能会觉得越来越抽象,我们来举一个数据分析的 lambda 架构: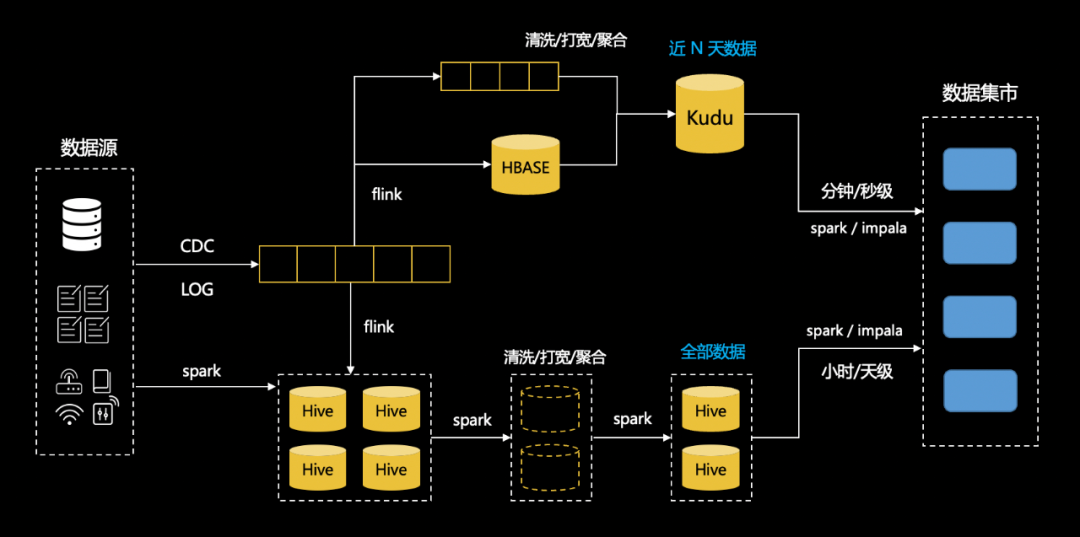 场景中用 Hive 做批表,kafka 做流表,整个离线遵循数据中台和 Dataops 的方法论,实时场景下需要用户构建同步到 hbase 的流计算任务,需要用户实现 join hbase 维表的流计算任务,把数据写到支持实时更新的 kudu 中,最后由业务根据实时和离线的需要选择查询 kudu 表还是 hive 表,在此之前,用户需要分别在数据模型中建表,使用 kudu 的工具建表,并且自己处理两个系统的差异。在这个架构中,用户遭受了割裂的体验,并且需要在上层做很多工作。企业需要的数据湖,应当能够帮助业务解决割裂的问题,用数据湖实现 ETL 、data pipeline 以及 olap 全流程,实现下面的效果:
场景中用 Hive 做批表,kafka 做流表,整个离线遵循数据中台和 Dataops 的方法论,实时场景下需要用户构建同步到 hbase 的流计算任务,需要用户实现 join hbase 维表的流计算任务,把数据写到支持实时更新的 kudu 中,最后由业务根据实时和离线的需要选择查询 kudu 表还是 hive 表,在此之前,用户需要分别在数据模型中建表,使用 kudu 的工具建表,并且自己处理两个系统的差异。在这个架构中,用户遭受了割裂的体验,并且需要在上层做很多工作。企业需要的数据湖,应当能够帮助业务解决割裂的问题,用数据湖实现 ETL 、data pipeline 以及 olap 全流程,实现下面的效果: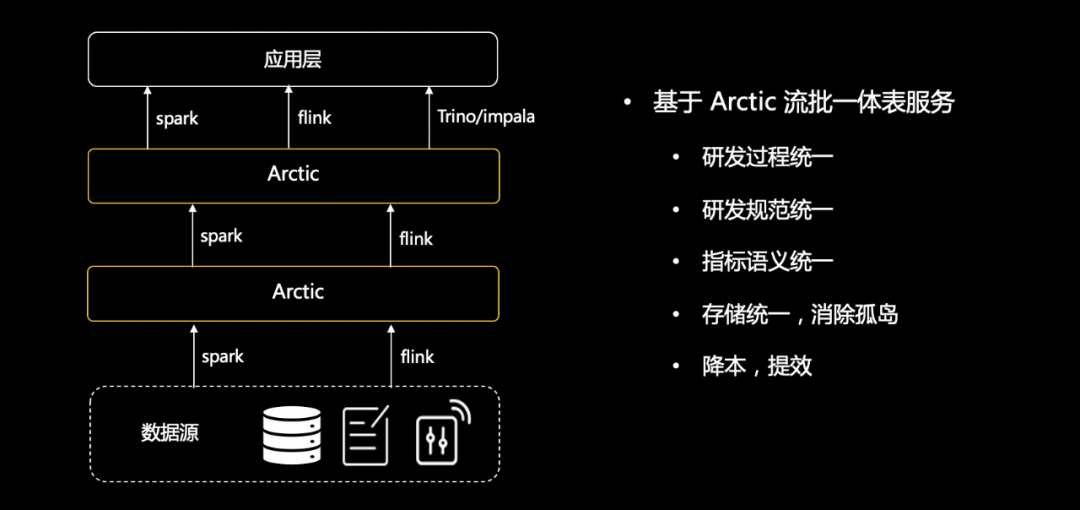 因为实时和离线使用了一套模型,在理论上已经可以将中台和 dataops 的很多能力应用到实时场景中,比如数据质量,当然这个过程中还需要在细节上做出更多的创新。核心的一点,数据湖技术的应用和推广不应当立足在某个或某些特定功能之上,应当结合数据平台的方法论全局来看,让数据分析、AI、流计算各个场景各个环节都能从中受益。5、我们的工作在这样的目标驱动下,过去两年我们团队开发了 Arctic 这个项目,并且在 7 月底默默开源了。首先,我们的工作不是另起炉灶,做一个跟 delta/iceberg 竞争的产品,这不符合企业的需求,Arctic 是立足于开源数据湖 Format 之上的服务,如前文所说,目前我们基于 iceberg。其次,我们的目标要将 Dataops 的边界拓展到流计算,所以 Arctic 会为用户提供更加优化的流的能力,包括 stream upsert,CDC,生产可用的读时合并技术,提供分钟级别新鲜度的数据分析能力,用一句话概括,Arctic 是适配多引擎的流式湖仓服务:
因为实时和离线使用了一套模型,在理论上已经可以将中台和 dataops 的很多能力应用到实时场景中,比如数据质量,当然这个过程中还需要在细节上做出更多的创新。核心的一点,数据湖技术的应用和推广不应当立足在某个或某些特定功能之上,应当结合数据平台的方法论全局来看,让数据分析、AI、流计算各个场景各个环节都能从中受益。5、我们的工作在这样的目标驱动下,过去两年我们团队开发了 Arctic 这个项目,并且在 7 月底默默开源了。首先,我们的工作不是另起炉灶,做一个跟 delta/iceberg 竞争的产品,这不符合企业的需求,Arctic 是立足于开源数据湖 Format 之上的服务,如前文所说,目前我们基于 iceberg。其次,我们的目标要将 Dataops 的边界拓展到流计算,所以 Arctic 会为用户提供更加优化的流的能力,包括 stream upsert,CDC,生产可用的读时合并技术,提供分钟级别新鲜度的数据分析能力,用一句话概括,Arctic 是适配多引擎的流式湖仓服务: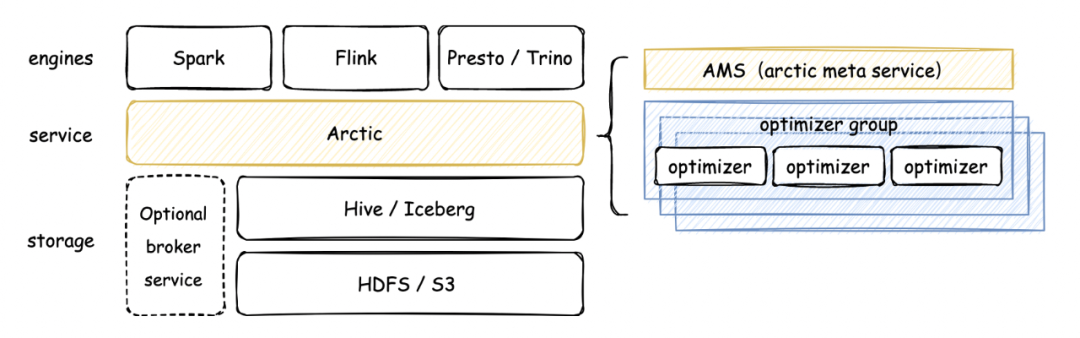
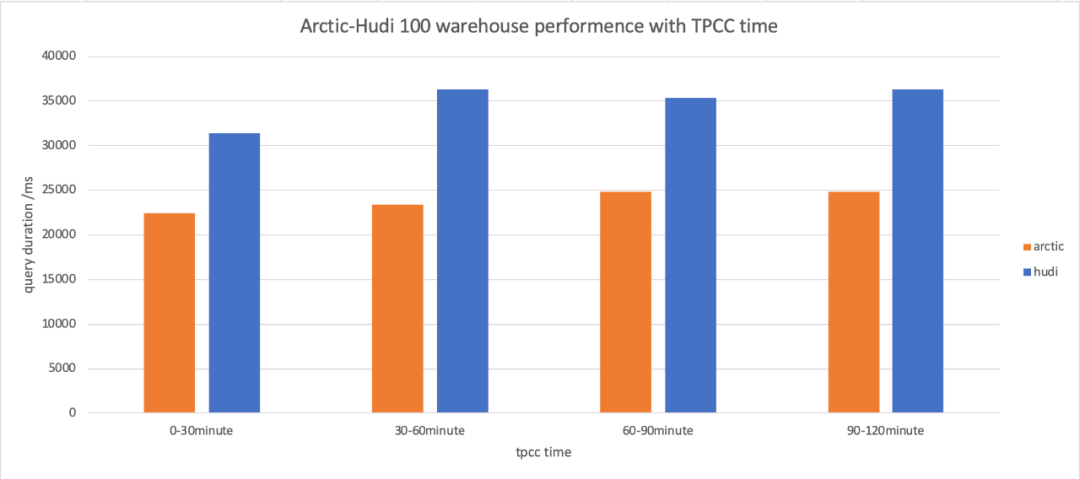 测试方案、环境和配置会在 Arctic 的官网中公开,同时我们将在8月11号的分享中公布更多benchmark 的细节,感兴趣的同学,或者对测试结果有疑问,欢迎参加我们的发布会了解更多信息。虽然我们在 table format 之上,引擎之下做了很多优化工作,但 Arctic 不会魔改 format 的内部实现, Arctic 依赖的都是社区发布的 release 包,未来 Arctic 也将坚持这一点,并通过 format 兼容的特性为用户带来最佳的方案。我们即将在 2022 年 8 月 11 日在线上举办一个简单的发布会,我会花 30 分钟左右的时间来讲讲 Arctic 的目标、特性、规划,以及可以给开源用户带来的价值。从调性上看,Arctic 作为基础软件会是一个完全开源的项目,相关商业化(如果有)会由另外的团队推进,未来条件允许的情况下我们也会积极推动项目向基金会的孵化,从这篇文章中可以看到网易数帆领导层对开源的态度。如果你对 Arctic 的定位、功能,或者任何与他相关的部分感兴趣,欢迎观看我们的直播或录播,或者通过下面的链接了解 arctic:
测试方案、环境和配置会在 Arctic 的官网中公开,同时我们将在8月11号的分享中公布更多benchmark 的细节,感兴趣的同学,或者对测试结果有疑问,欢迎参加我们的发布会了解更多信息。虽然我们在 table format 之上,引擎之下做了很多优化工作,但 Arctic 不会魔改 format 的内部实现, Arctic 依赖的都是社区发布的 release 包,未来 Arctic 也将坚持这一点,并通过 format 兼容的特性为用户带来最佳的方案。我们即将在 2022 年 8 月 11 日在线上举办一个简单的发布会,我会花 30 分钟左右的时间来讲讲 Arctic 的目标、特性、规划,以及可以给开源用户带来的价值。从调性上看,Arctic 作为基础软件会是一个完全开源的项目,相关商业化(如果有)会由另外的团队推进,未来条件允许的情况下我们也会积极推动项目向基金会的孵化,从这篇文章中可以看到网易数帆领导层对开源的态度。如果你对 Arctic 的定位、功能,或者任何与他相关的部分感兴趣,欢迎观看我们的直播或录播,或者通过下面的链接了解 arctic: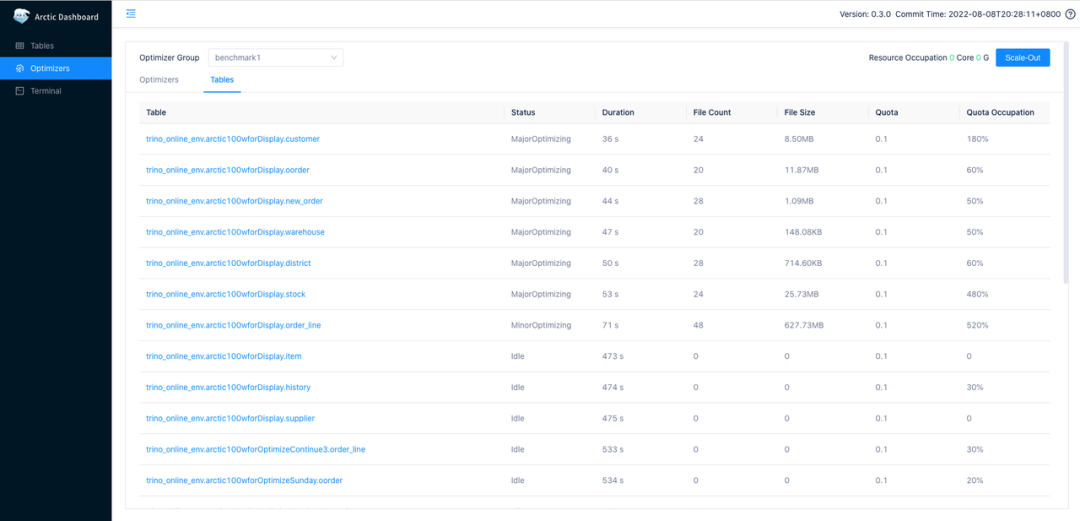 Arctic 为管理员和开发者提供了持续优化的度量和管理工具,以帮助用户实现时效性,存储和计算成本的测量,标定和规划。进一步说,在以数据湖构建的离线场景中,成本和性能呈非常线性的关系,当性能或容量不足时,SRE 只需要考虑加多少机器。而当我们将数据湖的能力拓展到实时场景,成本,性能和数据新鲜度的关系将呈现更为复杂和微妙的状态,Arcitic 的服务和管理功能,将为用户和上层平台理清这一层三角关系:
Arctic 为管理员和开发者提供了持续优化的度量和管理工具,以帮助用户实现时效性,存储和计算成本的测量,标定和规划。进一步说,在以数据湖构建的离线场景中,成本和性能呈非常线性的关系,当性能或容量不足时,SRE 只需要考虑加多少机器。而当我们将数据湖的能力拓展到实时场景,成本,性能和数据新鲜度的关系将呈现更为复杂和微妙的状态,Arcitic 的服务和管理功能,将为用户和上层平台理清这一层三角关系:
当我使用Bundler时,是否需要在我的Gemfile中将其列为依赖项?毕竟,我的代码中有些地方需要它。例如,当我进行Bundler设置时:require"bundler/setup" 最佳答案 没有。您可以尝试,但首先您必须用鞋带将自己抬离地面。 关于ruby-我需要将Bundler本身添加到Gemfile中吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/4758609/
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
如果我使用ruby版本2.5.1和Rails版本2.3.18会怎样?我有基于rails2.3.18和ruby1.9.2p320构建的rails应用程序,我只想升级ruby的版本,而不是rails,这可能吗?我必须面对哪些挑战? 最佳答案 GitHub维护apublicfork它有针对旧Rails版本的分支,有各种变化,它们一直在运行。有一段时间,他们在较新的Ruby版本上运行较旧的Rails版本,而不是最初支持的版本,因此您可能会发现一些关于需要向后移植的有用提示。不过,他们现在已经有几年没有使用2.3了,所以充其量只能让更
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Rubysyntaxquestion:Rational(a,b)andRational.new!(a,b)我正在阅读ruby镐书,我对创建有理数的语法感到困惑。Rational(3,4)*Rational(1,2)产生=>3/8为什么Rational不需要new方法(我还注意到例如我可以在没有new方法的情况下创建字符串)?
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
其实做自媒体的成本并不高,入门只需要一部手机即可!在手机上找视频素材、使用手机剪辑视频、最后使用手机发布视频作品获得收益!方法并不难,今天这期内容就来给粉丝们分享一种小方法,每天稳定收益100-300,抓紧点赞收藏!1、找素材(1)使用手机拍摄自己喜欢的经典段落,使用程序把文案内容提取出来(2)也可以在豆瓣、知乎、微博等网站中找一些自己需要的文案素材(3)把文案进行润色修改,可以加入一些自己的观点(4)视频素材可以使用软件中自带的素材,也可以在素材网站中下载完整版的素材2、文案配音(1)把复制好的文案直接导入小程序中(2)调整音色、音调后一键合成音频即可(3)可以选择自己朗读配音,需要花一点时