背景说明
随着流计算的发展,挑战不再仅限于数据量和计算量,业务变得越来越复杂,开发者可能是资深的大数据从业者、初学 Java 的爱好者,或是不懂代码的数据分析者。如何提高开发者的效率,降低流计算的门槛,对推广实时计算非常重要。
SQL 是数据处理中使用最广泛的语言,它允许用户简明扼要地展示其业务逻辑。Flink 作为流批一体的计算引擎,致力于提供一套 SQL 支持全部应用场景,Flink SQL 的实现也完全遵循 ANSI SQL 标准。之前,用户可能需要编写上百行业务代码,使用 SQL 后,可能只需要几行 SQL 就可以轻松搞定。
本文介绍如何使用华为FusionInsight MRS FlinkServer服务进行界面化的FlinkSQL编辑,从而处理复杂的嵌套Json格式
Json内容
下面以cdl新增数据的json为例
{
"schema":{
"type":"struct",
"fields":[
{
"type":"string",
"optional":false,
"field":"DATA_STORE"
},
{
"type":"string",
"optional":false,
"field":"SEG_OWNER"
},
{
"type":"string",
"optional":false,
"field":"TABLE_NAME"
},
{
"type":"int64",
"optional":false,
"name":"org.apache.kafka.connect.data.Timestamp",
"version":1,
"field":"TIMESTAMP"
},
{
"type":"string",
"optional":false,
"field":"OPERATION"
},
{
"type":"string",
"optional":true,
"field":"LOB_COLUMNS"
},
{
"type":"struct",
"fields":[
{
"type":"array",
"items":{
"type":"struct",
"fields":[
{
"type":"string",
"optional":false,
"field":"name"
},
{
"type":"string",
"optional":true,
"field":"value"
}
],
"optional":false
},
"optional":false,
"field":"properties"
}
],
"optional":false,
"name":"transaction",
"field":"transaction"
},
{
"type":"struct",
"fields":[
{
"type":"int64",
"optional":false,
"field":"uid"
}
],
"optional":true,
"name":"unique",
"field":"unique"
},
{
"type":"struct",
"fields":[
{
"type":"int64",
"optional":false,
"field":"uid"
},
{
"type":"string",
"optional":true,
"default":"",
"field":"uname"
},
{
"type":"int64",
"optional":true,
"field":"age"
},
{
"type":"string",
"optional":true,
"field":"sex"
},
{
"type":"string",
"optional":true,
"field":"mostlike"
},
{
"type":"string",
"optional":true,
"field":"lastview"
},
{
"type":"int64",
"optional":true,
"field":"totalcost"
}
],
"optional":true,
"name":"data",
"field":"data"
},
{
"type":"struct",
"fields":[
],
"optional":true,
"name":"EMPTY",
"field":"before"
},
{
"type":"string",
"optional":true,
"field":"HEARTBEAT_IDENTIFIER"
}
],
"optional":false,
"name":"hudi.hudisource"
},
"payload":{
"DATA_STORE":"MYSQL",
"SEG_OWNER":"hudi",
"TABLE_NAME":"hudisource",
"TIMESTAMP":1631070742000,
"OPERATION":"INSERT",
"LOB_COLUMNS":"",
"transaction":{
"properties":[
{
"name":"file",
"value":"mysql-bin.000005"
},
{
"name":"pos",
"value":"32307"
},
{
"name":"gtid",
"value":""
}
]
},
"unique":{
"uid":11
},
"data":{
"uid":11,
"uname":"蒋语堂",
"age":38,
"sex":"女",
"mostlike":"图",
"lastview":"播放器",
"totalcost":28732
},
"before":null,
"HEARTBEAT_IDENTIFIER":"998d66cc-1405-40e2-bbdc-41f2adf40724"
}
}上面的数据信息为复杂的json嵌套结构,包含了 Map、Array、Row 等类型, 对于这样的复杂格式需要有一种高效的方式进行解析,下面介绍如何实现。
华为FusionInsight MRS Flink WebUI介绍
Flink WebUI提供基于Web的可视化开发平台,用户只需要编写SQL即可开发作业,极大降低作业开发门槛。同时通过作业平台能力开放,支持业务人员自行编写SQL开发作业来快速应对需求,大大减少Flink作业开发工作量。
Flink WebUI主要有以下特点:
下面介绍如何使用Flink WebUI开发FlinkSQL DDL语句解析出有效信息
操作步骤
SQL说明:创建两张kafka流表,起作用为从kafka源端读取cdl对应topic,解析出需要的字段。并将结果写入另外一个kafka topic
schema.fields[1].typetype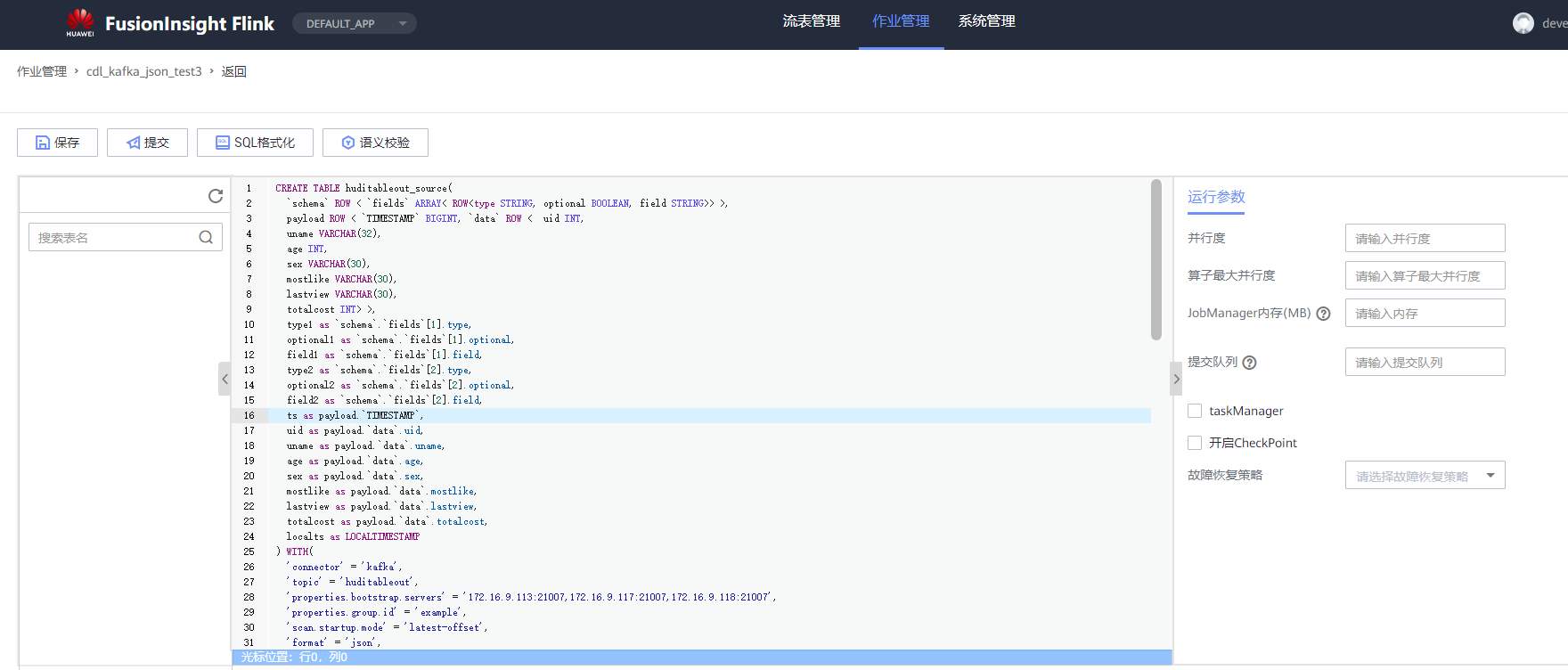
CREATE TABLE huditableout_source(
`schema` ROW < `fields` ARRAY< ROW<type STRING, optional BOOLEAN, field STRING>> >,
payload ROW < `TIMESTAMP` BIGINT, `data` ROW < uid INT,
uname VARCHAR(32),
age INT,
sex VARCHAR(30),
mostlike VARCHAR(30),
lastview VARCHAR(30),
totalcost INT> >,
type1 as `schema`.`fields`[1].type,
optional1 as `schema`.`fields`[1].optional,
field1 as `schema`.`fields`[1].field,
type2 as `schema`.`fields`[2].type,
optional2 as `schema`.`fields`[2].optional,
field2 as `schema`.`fields`[2].field,
ts as payload.`TIMESTAMP`,
uid as payload.`data`.uid,
uname as payload.`data`.uname,
age as payload.`data`.age,
sex as payload.`data`.sex,
mostlike as payload.`data`.mostlike,
lastview as payload.`data`.lastview,
totalcost as payload.`data`.totalcost,
localts as LOCALTIMESTAMP
) WITH(
'connector' = 'kafka',
'topic' = 'huditableout',
'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007',
'properties.group.id' = 'example',
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true',
'properties.sasl.kerberos.service.name' = 'kafka',
'properties.security.protocol' = 'SASL_PLAINTEXT',
'properties.kerberos.domain.name' = 'hadoop.hadoop.com'
);
CREATE TABLE huditableout(
type1 VARCHAR(32),
optional1 BOOLEAN,
field1 VARCHAR(32),
type2 VARCHAR(32),
optional2 BOOLEAN,
field2 VARCHAR(32),
ts BIGINT,
uid INT,
uname VARCHAR(32),
age INT,
sex VARCHAR(30),
mostlike VARCHAR(30),
lastview VARCHAR(30),
totalcost INT,
localts TIMESTAMP
) WITH(
'connector' = 'kafka',
'topic' = 'huditableout2',
'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007',
'properties.group.id' = 'example',
'scan.startup.mode' = 'latest-offset',
'format' = 'json',
'json.fail-on-missing-field' = 'false',
'json.ignore-parse-errors' = 'true',
'properties.sasl.kerberos.service.name' = 'kafka',
'properties.security.protocol' = 'SASL_PLAINTEXT',
'properties.kerberos.domain.name' = 'hadoop.hadoop.com'
);
insert into
huditableout
select
type1,
optional1,
field1,
type2,
optional2,
field2,
ts,
uid,
uname,
age,
sex,
mostlike,
lastview,
totalcost,
localts
from
huditableout_source;
源端kafka 数据  目标端kafka 数据
目标端kafka 数据 
本文由华为云发布。
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我得到了一个包含嵌套链接的表单。编辑时链接字段为空的问题。这是我的表格:Editingkategori{:action=>'update',:id=>@konkurrancer.id})do|f|%>'Trackingurl',:style=>'width:500;'%>'Editkonkurrence'%>|我的konkurrencer模型:has_one:link我的链接模型:classLink我的konkurrancer编辑操作:defedit@konkurrancer=Konkurrancer.find(params[:id])@konkurrancer.link_attrib
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
这道题是thisquestion的逆题.给定一个散列,每个键都有一个数组,例如{[:a,:b,:c]=>1,[:a,:b,:d]=>2,[:a,:e]=>3,[:f]=>4,}将其转换为嵌套哈希的最佳方法是什么{:a=>{:b=>{:c=>1,:d=>2},:e=>3,},:f=>4,} 最佳答案 这是一个迭代的解决方案,递归的解决方案留给读者作为练习:defconvert(h={})ret={}h.eachdo|k,v|node=retk[0..-2].each{|x|node[x]||={};node=node[x]}node[
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
下面例子中的Nested和Child有什么区别?是否只是同一事物的不同语法?classParentclassNested...endendclassChild 最佳答案 不,它们是不同的。嵌套:Computer之外的“Processor”类只能作为Computer::Processor访问。嵌套为内部类(namespace)提供上下文。对于ruby解释器Computer和Computer::Processor只是两个独立的类。classComputerclassProcessor#Tocreateanobjectforthisc
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
我有一个名为posts的模型,它有很多附件。附件模型使用回形针。我制作了一个用于创建附件的独立模型,效果很好,这是此处说明的View(https://github.com/thoughtbot/paperclip):@attachment,:html=>{:multipart=>true}do|form|%>posts中的嵌套表单如下所示:prohibitedthispostfrombeingsaved:@attachment,:html=>{:multipart=>true}do|at_form|%>附件记录已创建,但它是空的。文件未上传。同时,帖子已成功创建...有什么想法吗?