文章目录
本项目是参考 muduo 实现的基于 Reactor 模型的多线程网络库。使用 C++ 11 编写去除 muduo 对 boost 的依赖,内部实现了一个小型的 HTTP 服务器,可支持 GET 请求和静态资源的访问,且附有异步日志监控服务端情况。
项目已经实现了 Channel 模块、Poller 模块、事件循环模块、HTTP 模块、定时器模块、异步日志模块、内存池模块、数据库连接池模块。
https://github.com/Shang/A-Tiny-Network-Library
Ubuntu 18.04.6 LTSg++ 7.5.0vscodegitcmake 3.10.2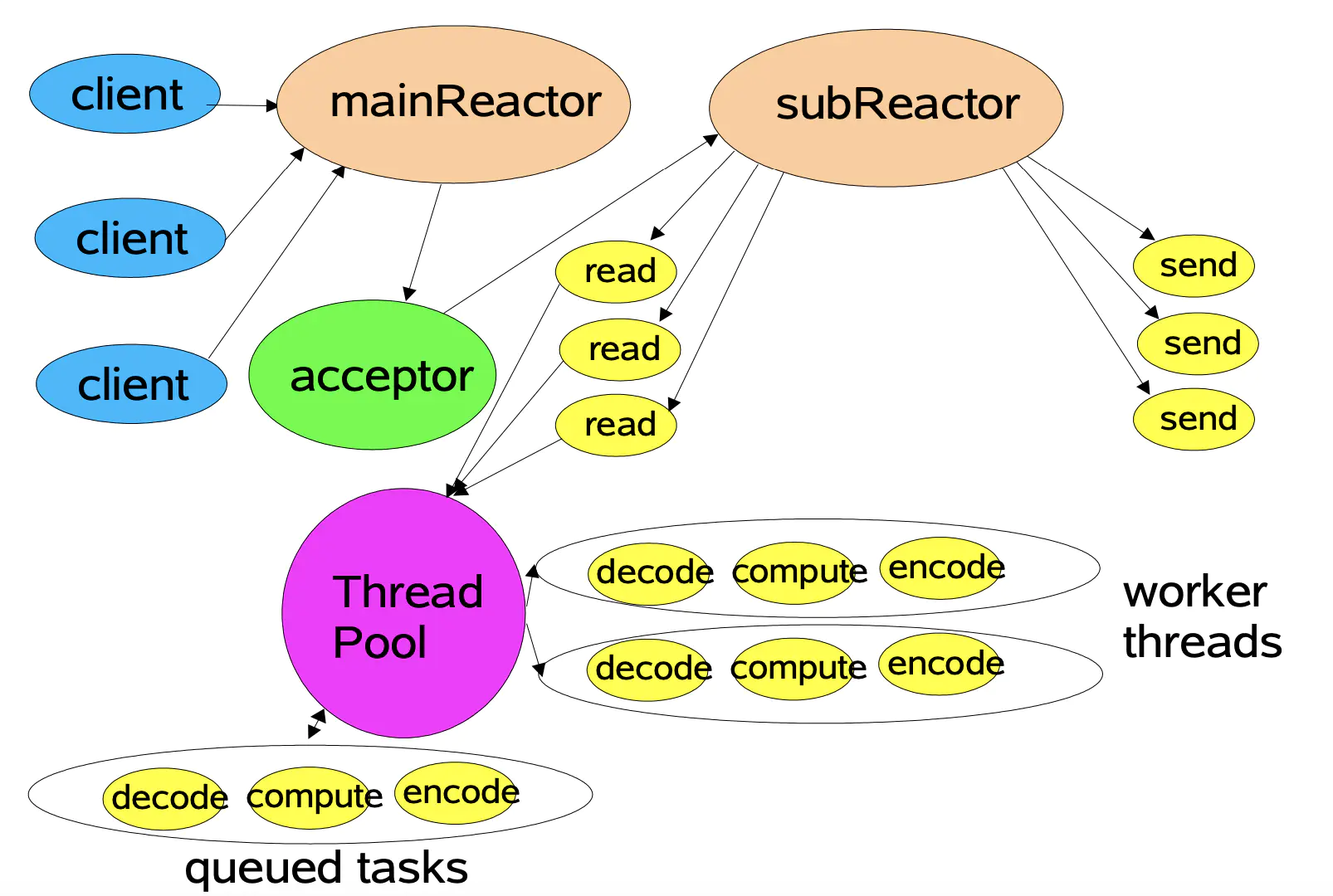
项目采用主从 Reactor 模型,MainReactor 只负责监听派发新连接,在 MainReactor 中通过 Acceptor 接收新连接并轮询派发给 SubReactor,SubReactor 负责此连接的读写事件。
调用 TcpServer 的 start 函数后,会内部创建线程池。每个线程独立的运行一个事件循环,即 SubReactor。MainReactor 从线程池中轮询获取 SubReactor 并派发给它新连接,处理读写事件的 SubReactor 个数一般和 CPU 核心数相等。使用主从 Reactor 模型有诸多优点:
安装Cmake
sudo apt-get update
sudo apt-get install cmake
下载项目
git clone git@github.com:Shangyizhou/tiny-network.git
执行脚本构建项目
cd ./tiny-network && bash build.sh
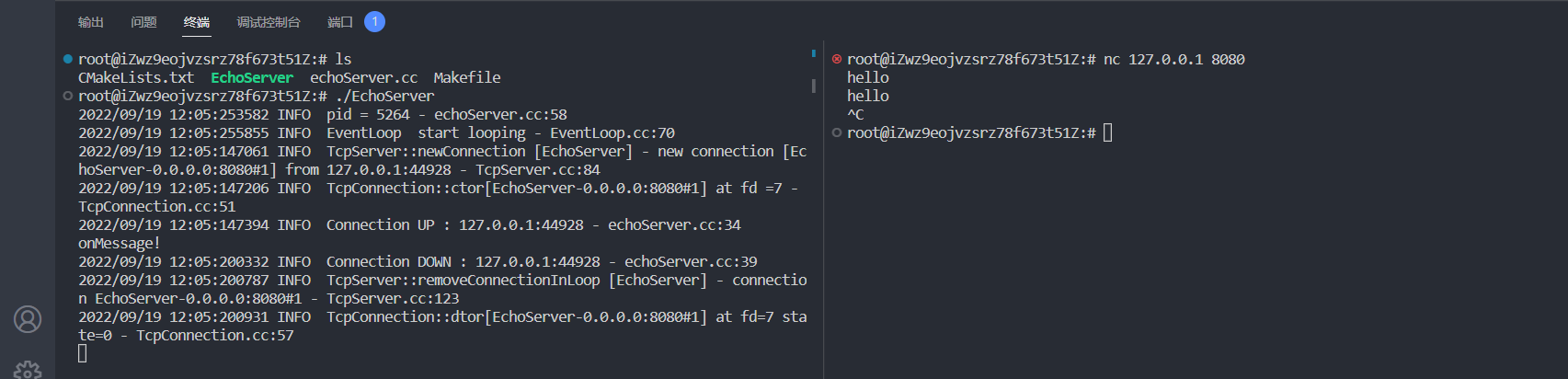
这里以一个简单的回声服务器作为案例,EchoServer默认监听端口为8080。
cd ./example
./EchoServer
执行情况:
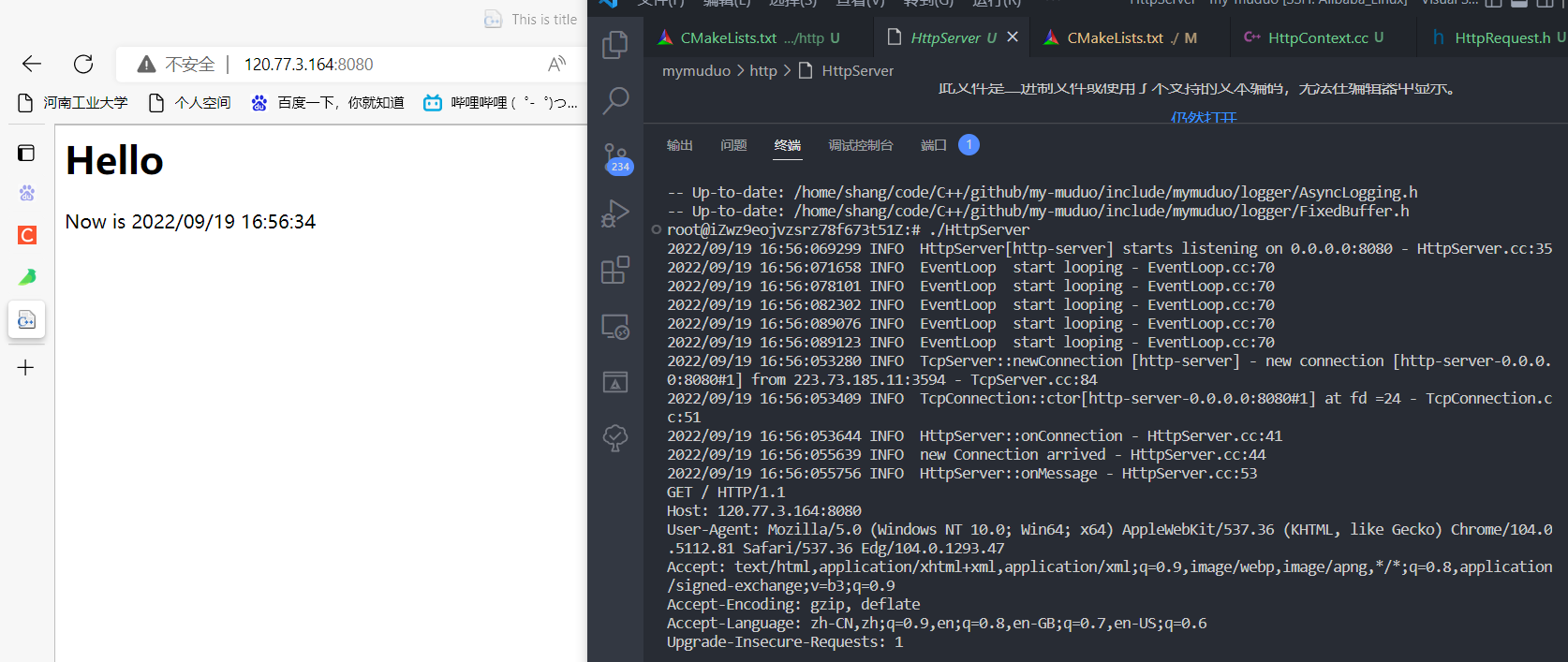
http模块有一个小型的HTTP服务器案例,也可以执行。其默认监听8080:
cd ./src/http && ./HttpServer
这里的某些模块会配置使用 muduo 的源码讲解,有些使用的是本项目的源码,不过实现思路是一致的。这里的源码详解更详细一点,后面只给出部分设计。
Channel 对文件描述符和事件进行了一层封装。平常我们写网络编程相关函数,基本就是创建套接字,绑定地址,转变为可监听状态(这部分我们在 Socket 类中实现过了,交给 Acceptor 调用即可),然后接受连接。
但是得到了一个初始化好的 socket 还不够,我们是需要监听这个 socket 上的事件并且处理事件的。比如我们在 Reactor 模型中使用了 epoll 监听该 socket 上的事件,我们还需将需要被监视的套接字和监视的事件注册到 epoll 对象中。
可以想到文件描述符和事件和 IO 函数全都混在在了一起,极其不好维护。而 muduo 中的 Channel 类将文件描述符和其感兴趣的事件(需要监听的事件)封装到了一起。而事件监听相关的代码放到了 Poller/EPollPoller 类中。
Channel 重要成员
/**
* const int Channel::kNoneEvent = 0;
* const int Channel::kReadEvent = EPOLLIN | EPOLLPRI;
* const int Channel::kWriteEvent = EPOLLOUT;
*/
static const int kNoneEvent;
static const int kReadEvent;
static const int kWriteEvent;
EventLoop *loop_; // 当前Channel属于的EventLoop
const int fd_; // fd, Poller监听对象
int events_; // 注册fd感兴趣的事件
int revents_; // poller返回的具体发生的事件
int index_; // 在Poller上注册的情况
std::weak_ptr<void> tie_; // 弱指针指向TcpConnection(必要时升级为shared_ptr多一份引用计数,避免用户误删)
bool tied_; // 标志此 Channel 是否被调用过 Channel::tie 方法
// 保存着事件到来时的回调函数
ReadEventCallback readCallback_; // 读事件回调函数
EventCallback writeCallback_; // 写事件回调函数
EventCallback closeCallback_; // 连接关闭回调函数
EventCallback errorCallback_; // 错误发生回调函数
我们编写网络编程代码的时候少不了使用IO复用系列函数,而muduo也为我们提供了对此的封装。muduo 有 Poller 和 EPollPoller 类分别对应着epoll和poll。
而我们使用的接口是Poller,muduo 以Poller 为虚基类,派生出 Poller 和 EPollPoller 两个子类,用不同的形式实现 IO 复用。
class Poller : noncopyable
{
public:
// Poller关注的Channel
typedef std::vector<Channel*> ChannelList;
Poller(EventLoop* loop);
virtual ~Poller();
/**
* 需要交给派生类实现的接口
* 用于监听感兴趣的事件和fd(封装成了channel)
* 对于Poller是poll,对于EPollerPoller是epoll_wait
* 最后返回epoll_wait/poll的返回时间
*/
virtual Timestamp poll(int timeoutMs, ChannelList* activeChannels) = 0;
// 需要交给派生类实现的接口(须在EventLoop所在的线程调用)
// 更新事件,channel::update->eventloop::updateChannel->Poller::updateChannel
virtual void updateChannel(Channel* channel) = 0;
// 需要交给派生类实现的接口(须在EventLoop所在的线程调用)
// 当Channel销毁时移除此Channel
virtual void removeChannel(Channel* channel) = 0;
// 需要交给派生类实现的接口
virtual bool hasChannel(Channel* channel) const;
/**
* newDefaultPoller获取一个默认的Poller对象(内部实现可能是epoll或poll)
* 它的实现并不在 Poller.cc 文件中
* 如果要实现则可以预料其会包含EPollPoller PollPoller
* 那么外面就会在基类引用派生类的头文件,这个抽象的设计就不好
* 所以外面会单独创建一个 DefaultPoller.cc 的文件去实现
*/
static Poller* newDefaultPoller(EventLoop* loop);
// 断言是否在创建EventLoop的所在线程
void assertInLoopThread() const
{
ownerLoop_->assertInLoopThread();
}
protected:
// 保存fd => Channel的映射
typedef std::map<int, Channel*> ChannelMap;
ChannelMap channels_;
private:
EventLoop* ownerLoop_;
};
重写方法靠派生类实现,这里我们可以专注一下 newDefaultPoler 方法。其内部返回默认实现的 Poller,可以是 epoll 实现的,也可以是 select 或 poll 实现的。
EventLoop 可以算是 muduo 的核心类了,EventLoop 对应着事件循环,其驱动着 Reactor 模型。我们之前的 Channel 和 Poller 类都需要依靠 EventLoop 类来调用。
Channel 负责封装文件描述符和其感兴趣的事件,里面还保存了事件发生时的回调函数
Poller 负责I/O复用的抽象,其内部调用epoll_wait获取活跃的 Channel
EventLoop 相当于 Channel 和 Poller 之间的桥梁,Channel 和 Poller 之间并不之间沟通,而是借助着 EventLoop 这个类。
这里上代码,我们可以看见 EventLoop 的成员变量就有 Channel 和 Poller。
class EventLoop
{
...
std::unique_ptr<Poller> poller_;
// scratch variables
ChannelList activeChannels_;
Channel* currentActiveChannel_;
};
其实 EventLoop 也就是 Reactor模型的一个实例,其重点在于循环调用 epoll_wait 不断的监听发生的事件,然后调用处理这些对应事件的函数。而这里就设计了线程之间的通信机制了。
最初写socket编程的时候会涉及这一块,调用epoll_wait不断获取发生事件的文件描述符,这其实就是一个事件循环。
while (1)
{
// 返回发生的事件个数
int n = epoll_wait(epfd, ep_events, EPOLL_SIZE, -1);
// 这个循环的所有文件描述符都是发生了事件的,效率得到了提高
for (i = 0; i < n; i++)
{
//客户端请求连接时
if (ep_events[i].data.fd == serv_sock)
{
// 接收新连接的到来
}
else //是客户端套接字时
{
// 负责读写数据
}
}
}
TcpConnection 类负责处理一个新连接的事件,包括从客户端读取数据和向客户端写数据。但是在这之前,需要先设计好缓冲区。
非阻塞网络编程中应用层buffer是必须的:非阻塞IO的核心思想是避免阻塞在read()或write()或其他I/O系统调用上,这样可以最大限度复用thread-of-control,让一个线程能服务于多个socket连接。I/O线程只能阻塞在IO-multiplexing函数上,如select()/poll()/epoll_wait()。这样一来,应用层的缓冲是必须的,每个TCP socket都要有inputBuffer和outputBuffer。
TcpConnection必须有output buffer:使程序在write()操作上不会产生阻塞,当write()操作后,操作系统一次性没有接受完时,网络库把剩余数据则放入outputBuffer中,然后注册POLLOUT事件,一旦socket变得可写,则立刻调用write()进行写入数据。——应用层buffer到操作系统buffer
TcpConnection必须有input buffer:当发送方send数据后,接收方收到数据不一定是整个的数据,网络库在处理socket可读事件的时候,必须一次性把socket里的数据读完,否则会反复触发POLLIN事件,造成busy-loop。所以网路库为了应对数据不完整的情况,收到的数据先放到inputBuffer里。——操作系统buffer到应用层buffer。
muduo 的 Buffer 类作为网络通信的缓冲区,像是 TcpConnection 就拥有 inputBuffer 和 outputBuffer 两个缓冲区成员。而缓冲区的设计特点:
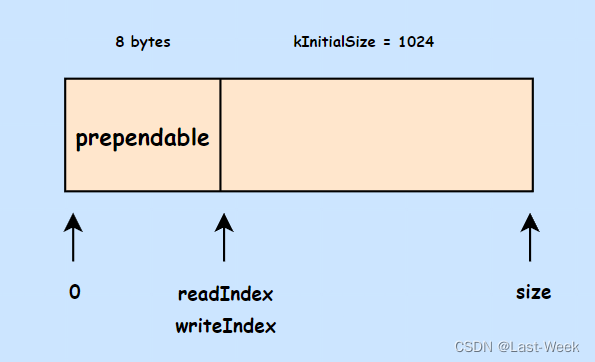
其内部使用std::vector保存数据,并提供许多访问方法。并且std::vector拥有扩容空间的操作,可以适应数据的不断添加。
std::vector内部分为三块,头部预留空间,可读空间,可写空间。内部使用索引标注每个空间的起始位置。每次往里面写入数据,就移动writeIndex;从里面读取数据,就移动readIndex。
class Buffer : public muduo::copyable
{
public:
static const size_t kCheapPrepend = 8; // 头部预留8个字节
static const size_t kInitialSize = 1024; // 缓冲区初始化大小 1KB
explicit Buffer(size_t initialSize = kInitialSize)
: buffer_(kCheapPrepend + initialSize), // buffer分配大小 8 + 1KB
readerIndex_(kCheapPrepend), // 可读索引和可写索引最开始位置都在预留字节后
writerIndex_(kCheapPrepend)
{
assert(readableBytes() == 0);
assert(writableBytes() == initialSize);
assert(prependableBytes() == kCheapPrepend);
}
/*......*/
// 可读空间大小
size_t readableBytes() const
{ return writerIndex_ - readerIndex_; }
// 可写空间大小
size_t writableBytes() const
{ return buffer_.size() - writerIndex_; }
// 预留空间大小
size_t prependableBytes() const
{ return readerIndex_; }
// 返回可读空间地址
const char* peek() const
{ return begin() + readerIndex_; }
/*......*/
private:
std::vector<char> buffer_; // 缓冲区其实就是vector<char>
size_t readerIndex_; // 可读区域开始索引
size_t writerIndex_; // 可写区域开始索引
};
定时器功能相关的类由 Timestamp,Timer,TimerQueue类组成,muduo 库还有一个 Timeld 类方便对定时器进行索引,本项目里没有加上这个类。
一个定时器所需的功能:
class Timer : noncopyable
{
private:
const TimerCallback callback_; // 定时器回调函数
Timestamp expiration_; // 下一次的超时时刻
const double interval_; // 超时时间间隔,如果是一次性定时器,该值为0
const bool repeat_; // 是否重复(false 表示是一次性定时器)
};
使用timerfd实现定时功能
linux2.6.25 版本新增了 timerfd 这个供用户程序使用的定时接口,这个接口基于文件描述符,当超时事件发生时,该文件描述符就变为可读。这种特性可以使我们在写服务器程序时,很方便的便把定时事件变成和其他I/O事件一样的处理方式,当时间到期后,就会触发读事件。我们调用响应的回调函数即可。
int timer_create(int clockid,int flags); // 成功返回0
此函数用于创建timerfd,我们需要指明使用标准事件还是相对事件,并且传入控制标志。
为什么要实现非阻塞的日志
如果是同步日志,那么每次产生日志信息时,就需要将这条日志信息完全写入磁盘后才会执行后续程序。而磁盘 IO 是比较耗时的操作,如果有大批量的日志信息需要写入就会阻塞网络库的工作。
如果是异步日志,那么写日志消息只需要将日志的信息先进行存储,当累计到一定量或者经过一定时间时再将这些日志信息批量写入磁盘。而这个写入过程靠后台线程去执行,不会影响处理事件的其他线程。
经过对比可以得到,异步日志的方式对性能更加友好,而且可以减少磁盘 IO 函数的操作,一次写入更多的数据,提高效率。
muduo日志库的设计
muduo 日志消息的组成:时间戳、线程ID、日志级别、日志正文、源文件名、行号(下面的例子省略了线程 TID)。
2022/11/30 00:57:016530 INFO EventLoop start looping - EventLoop.cc:70
muduo 日志库由前端和后端组成。
前端主要包括:Logger、LogStream、FixedBuffer、SourceFile。
后端主要包括:AsyncLogging、LogFile、AppendFile。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
运行bundleinstall后出现此错误:Gem::Package::FormatError:nometadatafoundin/Users/jeanosorio/.rvm/gems/ruby-1.9.3-p286/cache/libv8-3.11.8.13-x86_64-darwin-12.gemAnerroroccurredwhileinstallinglibv8(3.11.8.13),andBundlercannotcontinue.Makesurethat`geminstalllibv8-v'3.11.8.13'`succeedsbeforebundling.我试试gemin
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我正在尝试创建一个带有项目符号字符的Ruby1.9.3字符串。str="•"+"helloworld"但是,当我输入它时,我收到有关非ASCII字符的语法错误。我该怎么做? 最佳答案 你可以把Unicode字符放在那里。str="\u2022"+"helloworld" 关于ruby-如何在Ruby字符串中插入项目符号字符?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1195
我的Rails站点使用了一个确实不是很好的gem。每次我需要做一些新的事情时,我最终不得不花费与向实际Rails项目添加代码一样多的时间来为gem添加功能。但我不介意,我将我的Gemfile设置为指向我的gem的GitHub分支(我尝试提交PR,但维护者似乎已经下台)。问题是我真的没有找到一种合理的方法来测试我添加到gem的新东西。在railsc中测试它会特别好,但我能想到的唯一方法是a)更改~/.rvm/gems/.../foo。rb,这看起来不对或者b)升级版本,推送到Github,然后运行bundleup,这除了耗时之外显然是一场灾难,因为我不确定我所做的promise是否正