目录
说明:本篇文章主要借鉴于抖音恩培大佬的代码,大佬的github地址为:enpeizhao (enpei) (github.com)
感兴趣的朋友也可以关注大佬的抖音号!
脸部姿态估计识别与检测
帧率检测
目标物体三个角度x、y、z估计
家庭应用:检测孩子是否在看电视,看了多久,距离多远,保护孩子用眼安全
驾驶监督应用:检测司机是否有疲劳驾驶风险(可以从脸部姿态做进一步估计)
自动驾驶:利用单目RGB图像进行深度距离估计,避免了使用激光雷达等高成本的距离估计
人脸识别:轻量化的人脸识别应用,后期可以将此功能引用于嵌入式设备,实现轻量化应用
画面展示:
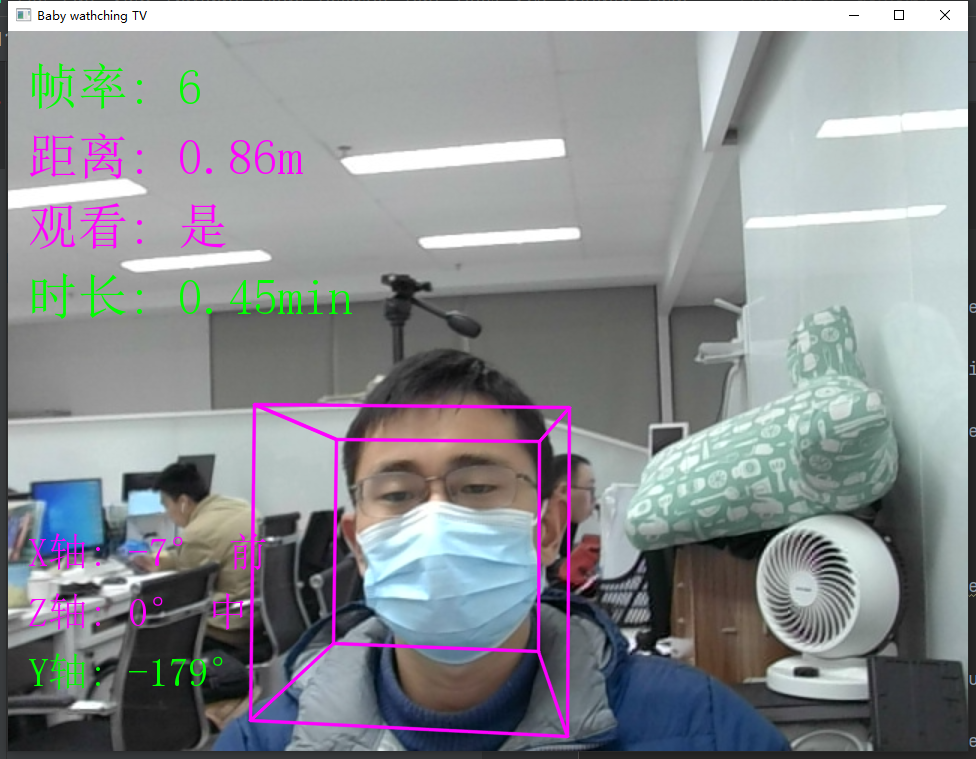
硬件准备:
win10系统, RGB摄像头
软件准备:
python3.7, Pycham(vs code或其他编译器)
conda create -n tv python=3.7tv表示要创建环境的名字,我这里用“tv”来代替环境名字
conda activate tvconda install dlib
pip install opencv-contrib-pythonhttps://github.com/enpeizhao/CVprojects/releases/tag/Models
(恩培大佬github下载地址)
全部指令代码参数配置如下:
python demo.py --命令=参数 -h, --help 显示帮助
--mode MODE 运行模式:collect,train,distance,run对应:采集、训练、评估距离、主程序
--label_id LABEL_ID 采集照片标签id.
--img_count IMG_COUNT
采集照片数量
--img_interval IMG_INTERVAL
采集照片间隔时间
--display DISPLAY 显示模式,取值1-5
--w W 画面宽度
--h H 画面高度这个小项目里边使用的是较为简单的opencv内置人脸识别算法,缺点就是精度可能有限,整体过程需要执行下面三个步骤:
python demo.py --mode='collect' --label_id=1 --img_count=2 --img_interval=2
python demo.py --mode='collect' --label_id={人脸ID} --img_count={该ID采集照片数量,一般1-3张即可} --img_interval={照片采集间隔(秒)};
在目录./face_mode/label.txt下的label文件,里边的每行代表一个人,如1,**表示label_id=1的人脸叫**;
执行python demo.py --mode='train'训练人脸识别模型,模型是对应的./face_model/model.yml权值文件!
python demo.py --mode='run' --w={宽度} --{高度} --display={显示模式},display取值对应:
1:人脸框(人脸检测,识别label中有的人脸)
2:68个人脸关键点(关键点检测)
3:人脸梯形框框(三维深度估计)
4:人脸方向指针(主要就是利用角度的识别)
5:人脸三维坐标系(三维坐标系)
"""
借鉴恩培大佬源码!
主要功能:检测孩子是否在看电视,看了多久,距离多远
使用技术点:人脸检测、人脸识别(采集照片、训练、识别)、姿态估计
"""
import cv2, time
from pose_estimator import PoseEstimator
import numpy as np
import dlib
from utils import Utils
import os
from argparse import ArgumentParser
class MonitorBabay:
def __init__(self):
# 人脸检测
self.face_detector = dlib.get_frontal_face_detector()
# 人脸识别模型:pip uninstall opencv-python,pip install opencv-contrib-python
self.face_model = cv2.face.LBPHFaceRecognizer_create()
# 人脸68个关键点
self.landmark_predictor = dlib.shape_predictor("./assets/shape_predictor_68_face_landmarks.dat")
# 站在1.5M远处,左眼最左边距离右眼最右边的像素距离(请使用getEyePixelDist方法校准,然后修改这里的值)
self.eyeBaseDistance = 65
# pose_estimator.show_3d_model()
self.utils = Utils()
# 采集照片用于训练
# 参数
# label_index: label的索引
# save_interval:隔几秒存储照片
# save_num:存储总量
def collectFacesFromCamera(self,label_index,save_interval,save_num):
cap = cv2.VideoCapture(0)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
fpsTime = time.time()
last_save_time = fpsTime
saved_num = 0
while True:
_, frame = cap.read()
frame = cv2.flip(frame,1)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = self.face_detector(gray)
for face in faces:
if saved_num < save_num:
if (time.time() - last_save_time) > save_interval:
self.utils.save_face(face,frame,label_index)
saved_num +=1
last_save_time = time.time()
print('label_index:{index},成功采集第{num}张照片'.format(index = label_index,num = saved_num))
else:
print('照片采集完毕!')
exit()
self.utils.draw_face_box(face,frame,'','','')
cTime = time.time()
fps_text = 1/(cTime-fpsTime)
fpsTime = cTime
frame = self.utils.cv2AddChineseText(frame, "帧率: " + str(int(fps_text)), (10, 30), textColor=(0, 255, 0), textSize=50)
frame = cv2.resize(frame, (int(width)//2, int(height)//2) )
cv2.imshow('Collect data', frame)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
# 训练人脸模型
def train(self):
print('训练开始!')
label_list,img_list = self.utils.getFacesLabels()
self.face_model.train(img_list, label_list)
self.face_model.save("./face_model/model.yml")
print('训练完毕!')
# 获取两个眼角像素距离
def getEyePixelDist(self):
cap = cv2.VideoCapture(0)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH)
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
# 姿态估计
self.pose_estimator = PoseEstimator(img_size=(height, width))
fpsTime = time.time()
while True:
_, frame = cap.read()
frame = cv2.flip(frame,1)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = self.face_detector(gray)
pixel_dist = 0
for face in faces:
# 关键点
landmarks = self.landmark_predictor(gray, face)
image_points = self.pose_estimator.get_image_points(landmarks)
left_x = int(image_points[36][0])
left_y = int(image_points[36][1])
right_x = int(image_points[45][0])
right_y = int(image_points[45][1])
pixel_dist = abs(right_x-left_x)
cv2.circle(frame, (left_x, left_y), 8, (255, 0, 255), -1)
cv2.circle(frame, (right_x, right_y), 8, (255, 0, 255), -1)
# 人脸框
frame = self.utils.draw_face_box(face,frame,'','','')
cTime = time.time()
fps_text = 1/(cTime-fpsTime)
fpsTime = cTime
frame = self.utils.cv2AddChineseText(frame, "帧率: " + str(int(fps_text)), (20, 30), textColor=(0, 255, 0), textSize=50)
frame = self.utils.cv2AddChineseText(frame, "像素距离: " + str(int(pixel_dist)), (20, 100), textColor=(0, 255, 0), textSize=50)
# frame = cv2.resize(frame, (int(width)//2, int(height)//2) )
cv2.imshow('Baby wathching TV', frame)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
# 运行主程序
def run(self,w,h,display):
model_path = "./face_model/model.yml"
if not os.path.exists(model_path):
print('人脸识别模型文件不存在,请先采集训练')
exit()
label_zh = self.utils.loadLablZh()
self.face_model.read(model_path)
cap = cv2.VideoCapture(0)
width = w
height = h
print(width,height)
# 姿态估计
self.pose_estimator = PoseEstimator(img_size=(height, width))
fpsTime = time.time()
zh_name = ''
x_label = ''
z_label = ''
is_watch = ''
angles = [0, 0, 0]
person_distance = 0
watch_start_time = fpsTime
watch_duration = 0
# fps = 12
# videoWriter = cv2.VideoWriter('./record_video/out'+str(time.time())+'.mp4', cv2.VideoWriter_fourcc(*'H264'), fps, (width,height))
while True:
_, frame = cap.read()
frame = cv2.resize(frame,(width,height))
frame = cv2.flip(frame,1)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = self.face_detector(gray)
for face in faces:
x1,y1,x2,y2 = self.utils.getFaceXY(face)
face_img = gray[y1:y2,x1:x2]
try:
# 人脸识别
idx, confidence = self.face_model.predict(face_img)
zh_name = label_zh[str(idx)]
except cv2.error:
print('cv2.error')
# 关键点
landmarks = self.landmark_predictor(gray, face)
# 计算旋转矢量
rotation_vector, translation_vector = self.pose_estimator.solve_pose_by_68_points(landmarks)
# 计算距离
person_distance = round(self.pose_estimator.get_distance(self.eyeBaseDistance),2)
# 计算角度
rmat, jac = cv2.Rodrigues(rotation_vector)
angles, mtxR, mtxQ, Qx, Qy, Qz = cv2.RQDecomp3x3(rmat)
if angles[1] < -15:
x_label = '左'
elif angles[1] > 15:
x_label = '右'
else:
x_label = '前'
if angles[0] < -15:
z_label = "下"
elif angles[0] > 15:
z_label = "上"
else:
z_label = "中"
is_watch = '是' if( x_label =='前' and z_label == '中') else '否'
if is_watch == '是':
now = time.time()
watch_duration += ( now - watch_start_time)
watch_start_time= time.time()
if display == 1:
# 人脸框
frame = self.utils.draw_face_box(face,frame,zh_name,is_watch,person_distance)
if display == 2:
# 68个关键点
self.utils.draw_face_points(landmarks,frame)
if display == 3:
# 梯形方向
self.pose_estimator.draw_annotation_box(
frame, rotation_vector, translation_vector,is_watch)
if display == 4:
# 指针
self.pose_estimator.draw_pointer(frame, rotation_vector, translation_vector)
if display == 5:
# 三维坐标系
self.pose_estimator.draw_axes(frame, rotation_vector, translation_vector)
# 仅测试单人
break
cTime = time.time()
fps_text = 1/(cTime-fpsTime)
fpsTime = cTime
frame = self.utils.cv2AddChineseText(frame, "帧率: " + str(int(fps_text)), (20, 30), textColor=(0, 255, 0), textSize=50)
color = (255, 0, 255) if person_distance <=1 else (0, 255, 0)
frame = self.utils.cv2AddChineseText(frame, "距离: " + str(person_distance ) +"m", (20, 100), textColor=color, textSize=50)
color = (255, 0, 255) if is_watch =='是' else (0, 255, 0)
frame = self.utils.cv2AddChineseText(frame, "观看: " + str(is_watch ), (20, 170), textColor=color, textSize=50)
#
duration_str = str(round((watch_duration/60),2)) +"min"
frame = self.utils.cv2AddChineseText(frame, "时长: " + duration_str, (20, 240), textColor= (0, 255, 0), textSize=50)
color = (255, 0, 255) if x_label =='前' else (0, 255, 0)
frame = self.utils.cv2AddChineseText(frame, "X轴: {degree}° {x_label} ".format(x_label=str(x_label ),degree = str(int(angles[1]))) , (20, height-220), textColor=color, textSize=40)
color = (255, 0, 255) if z_label =='中' else (0, 255, 0)
frame = self.utils.cv2AddChineseText(frame, "Z轴: {degree}° {z_label}".format(z_label=str(z_label ),degree = str(int(angles[0]))) , (20, height-160), textColor=color, textSize=40)
frame = self.utils.cv2AddChineseText(frame, "Y轴: {degree}°".format(degree = str(int(angles[2]) )),(20, height-100), textColor=(0, 255, 0), textSize=40)
# videoWriter.write(frame)
# frame = cv2.resize(frame, (int(width)//2, int(height)//2) )
cv2.imshow('Baby wathching TV', frame)
if cv2.waitKey(5) & 0xFF == 27:
break
cap.release()
m = MonitorBabay()
# 参数设置
parser = ArgumentParser()
parser.add_argument("--mode", type=str, default='run',
help="运行模式:collect,train,distance,run对应:采集、训练、评估距离、主程序")
parser.add_argument("--label_id", type=int, default=1,
help="采集照片标签id.")
parser.add_argument("--img_count", type=int, default=3,
help="采集照片数量")
parser.add_argument("--img_interval", type=int, default=3,
help="采集照片间隔时间")
parser.add_argument("--display", type=int, default=1,
help="显示模式,取值1-5")
parser.add_argument("--w", type=int, default=960,
help="画面宽度")
parser.add_argument("--h", type=int, default=720,
help="画面高度")
args = parser.parse_args()
mode = args.mode
if mode == 'collect':
print("即将采集照片.")
if args.label_id and args.img_count and args.img_interval:
m.collectFacesFromCamera(args.label_id,args.img_interval,args.img_count)
if mode == 'train':
m.train()
if mode == 'distance':
m.getEyePixelDist()
if mode == 'run':
m.run(args.w,args.h,args.display)END~
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我正在编写一个方法,它将在一个类中定义一个实例方法;类似于attr_accessor:classFoocustom_method(:foo)end我通过将custom_method函数添加到Module模块并使用define_method定义方法来实现它,效果很好。但我无法弄清楚如何考虑类(class)的可见性属性。例如,在下面的类中classFoocustom_method(:foo)privatecustom_method(:bar)end第一个生成的方法(foo)必须是公共(public)的,第二个(bar)必须是私有(private)的。我怎么做?或者,如何找到调用我的cust
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO