title: 二叉搜索树的插入删除修剪
题目链接:701. 二叉搜索树中的插入操作

递归法:
明确BST插入可以不用改变树的结构,所以找到对应的子节点插入即可;
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if (root == nullptr) {
return new TreeNode(val);
}
if (val > root->val) root->right = insertIntoBST(root->right, val);
if (val < root->val) root->left = insertIntoBST(root->left, val);
return root;
}
};
迭代法:
找到叶子节点,但是是迭代的,无法像递归一样利用函数调用的栈,但是可以采用pre 来记录上一个的节点!
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
TreeNode* cur = root;
TreeNode* pre = nullptr;
while (cur) {
pre = cur;
if (cur->val > val) {
cur = cur->left;
}
else if (cur->val < val) {
cur = cur->right;
}
}
if (pre && pre->val > val) pre->left = new TreeNode(val);
else if (pre && pre->val < val) pre->right = new TreeNode(val);
else root = new TreeNode(val);
return root;
}
};
题目链接:450. 删除二叉搜索树中的节点

找到删除节点要观察:
情况一:要删除的节点是叶子节点,直接删除即可;
情况二:要删除的节点是只存有一边子树,直接删除用子树的第一个节点替上来就可;
情况三:要删除的节点存在左右两边子树,那么删除可以有多种选择方案,这里提两种
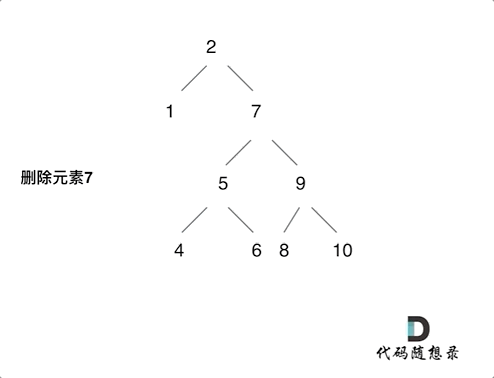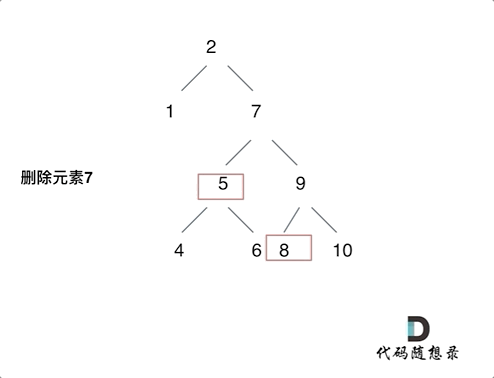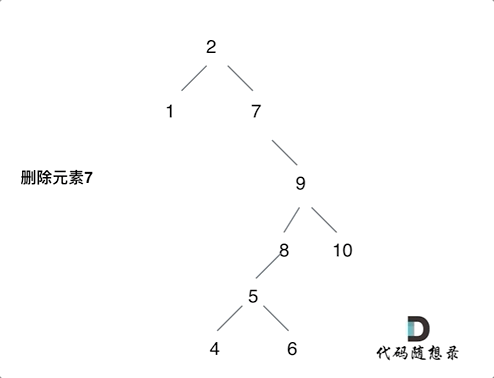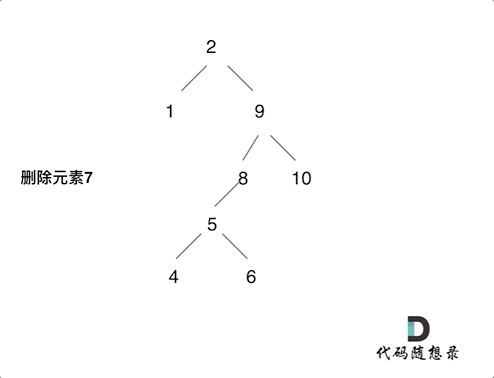
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if (root == nullptr) return nullptr; // 处理找不到的情况;
if (root->val == key) {
// 处理情况一、二
if (root->left == nullptr) {
TreeNode* cur = root->right;
delete root;
return cur;
}
if (root->right == nullptr) {
TreeNode* cur = root->left;
delete root;
return cur;
}
// 情况三
if (root->left && root->right) {
TreeNode* node = root->right;
while (node->left) node = node->left; // 拿到右子树最小的值;
// 方案①:将右子节点替上去;
node->left = root->left;
TreeNode* cur = root->right;
delete root;
return cur;
//方案②:将右子树中的最小值替上去;
node = new TreeNode(node->val);
root->right = deleteNode(root->right, node->val);
node->left = root->left; node->right = root->right;
delete root;
return node;
}
}
// 找左右子树
if (root->val > key) root->left = deleteNode(root->left, key);
if (root->val < key) root->right = deleteNode(root->right, key);
return root;
}
};
迭代法:
class Solution {
public:
TreeNode* deleteoOne(TreeNode* root) {
// 情况一、二
if (root->right == nullptr) return root->left;
if (root->left == nullptr) return root->right;
// 情况三,采用方案①
TreeNode* cur = root->right;
while (cur->left) cur = cur->left;
cur->left = root->left;
return root->right;
}
TreeNode* deleteNode(TreeNode* root, int key) {
if (root == nullptr) return nullptr;
TreeNode* pre = nullptr;
TreeNode* cur = root;
while (cur) {
if (cur->val == key) break;
pre = cur;
if (cur->val > key) cur = cur->left;
else cur =cur->right;
}
// 如果要删除的是头节点
if (pre == nullptr) return deleteoOne(cur);
// 如果要删除的是pre左孩子节点
if (pre->left && pre->left == cur) pre->left = deleteoOne(cur);
// 如果要删除的是pre右孩子节点
if (pre->right && pre->right == cur) pre->right = deleteoOne(cur);
return root;
}
};
题目链接:669. 修剪二叉搜索树


解法一:递归
利用BST树的性质,要明确当下节点可能 不再[low, high]区间内,但是其左子树或者右子树是存在这样的节点的;
自底而上不断改变树的结构,剔除不再[low,high]的节点,有:
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if (root == nullptr) return nullptr;
// 自底向上改变
root->left = trimBST(root->left, low, high);
root->right = trimBST(root->right, low, high);
if (root->val > high) return root->left;
else if (root->val < low) return root->right;
else return root;
}
};
解法二:迭代
看代码注释即可,思考应该返回什么?怎么修剪左右子树?
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
// 找到第一个符合[low, high] 的节点(当返回值);
while (root && (root->val < low || root->val > high)) {
if (root->val < low) root = root->right; // 当前值 < low
else root = root->left; // 当前值 > low
}
// 修剪左子树
TreeNode* cur =root;
while (cur != nullptr) {
while (cur->left && cur->left->val < low) { //找到符合[low, high]的节点 接入left
cur->left = cur->left->right;
}
cur = cur->left;
}
// 修剪右子树
cur = root;
while (cur != nullptr) {
while (cur->right && cur->right->val > high) { //找到符合[low, high]的节点 接入right
cur->right = cur->right->left;
}
cur = cur->right;
}
return root;
}
};
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
在Ruby中是否有Gem或安全删除文件的方法?我想避免系统上可能不存在的外部程序。“安全删除”指的是覆盖文件内容。 最佳答案 如果您使用的是*nix,一个很好的方法是使用exec/open3/open4调用shred:`shred-fxuz#{filename}`http://www.gnu.org/s/coreutils/manual/html_node/shred-invocation.html检查这个类似的帖子:Writingafileshredderinpythonorruby?
我正在尝试找到一种方法来规范化字符串以将其作为文件名传递。到目前为止我有这个:my_string.mb_chars.normalize(:kd).gsub(/[^\x00-\x7F]/n,'').downcase.gsub(/[^a-z]/,'_')但第一个问题:-字符。我猜这个方法还有更多问题。我不控制名称,名称字符串可以有重音符、空格和特殊字符。我想删除所有这些,用相应的字母('é'=>'e')替换重音符号,并将其余的替换为'_'字符。名字是这样的:“Prélèvements-常规”“健康证”...我希望它们像一个没有空格/特殊字符的文件名:“prelevements_routin
我去了这个website查看Rails5.0.0和Rails5.1.1之间的区别为什么5.1.1不再包含:config/initializers/session_store.rb?谢谢 最佳答案 这是删除它的提交:Setupdefaultsessionstoreinternally,nolongerthroughanapplicationinitializer总而言之,新应用没有该初始化器,session存储默认设置为cookie存储。即与在该初始值设定项的生成版本中指定的值相同。 关于
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
啊,正则表达式有点困惑。我正在尝试删除字符串末尾所有可能的标点符号:ifstr[str.length-1]=='?'||str[str.length-1]=='.'||str[str.length-1]=='!'orstr[str.length-1]==','||str[str.length-1]==';'str.chomp!end我相信有更好的方法来做到这一点。有什么指点吗? 最佳答案 str.sub!(/[?.!,;]?$/,'')[?.!,;]-字符类。匹配这5个字符中的任何一个(注意,。在字符类中并不特殊)?-前一个字符或组
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p