
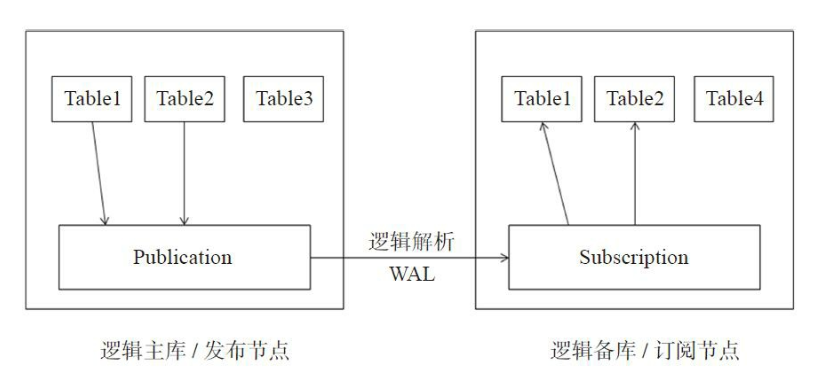
 图片来源于《PostgreSQL实战》逻辑复制是基于逻辑解析,其核心原理是逻辑主库将Publication中表的WAL日志解析成一定格式并发送给逻辑备库,逻辑备库Subscription接收到解析后的WAL日志后进行重做,从而实现表数据同步。
图片来源于《PostgreSQL实战》逻辑复制是基于逻辑解析,其核心原理是逻辑主库将Publication中表的WAL日志解析成一定格式并发送给逻辑备库,逻辑备库Subscription接收到解析后的WAL日志后进行重做,从而实现表数据同步。wal_level = logical
max_wal_senders = 10
max_replication_slots = 8wal_level = logical
max_replication_slots = 8
max_logical_replication_workers = 8postgres=# CREATE USER logical_repl REPLICATION LOGIN CONNECTION LIMIT 8 ENCRYPTED PASSWORD 'logical_repl';
CREATE ROLE/** 创建用于逻辑复制的主库 */
[postgres@PG32 data]$ createdb sourcedb
[postgres@PG32 data]$ psql -d sourcedb
psql (11.4)
Type "help" for help.
sourcedb=# create table logical_tb1(id int primary key,name varchar(20));/** 在逻辑从库上创建不同的库 */
[postgres@PG33 data]$ createdb desdb
[postgres@PG33 data]$ psql -d desdb
psql (11.4)
Type "help" for help.
desdb=# create table logical_tb1(id int primary key,name varchar(20));
CREATE TABLE
desdb=#/** 在发布主库上创建发布pub1,注意实在sourcedb库下执行 */
sourcedb=# CREATE PUBLICATION pub1 FOR TABLE logical_tb1;
CREATE PUBLICATIONsourcedb=# SELECT * FROM pg_publication;
pubname | pubowner | puballtables | pubinsert | pubupdate | pubdelete | pubtruncate
---------+----------+--------------+-----------+-----------+-----------+-------------
pub1 | 10 | f | t | t | t | t
(1 row)desdb=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.56.32 port=5432 user=logical_repl dbname=sourcedb password=logical_repl' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONsourcedb=# SELECT slot_name,plugin,slot_type,database,active,restart_lsn FROM pg_replication_slots where slot_name='sub1';
slot_name | plugin | slot_type | database | active | restart_lsn
-----------+----------+-----------+----------+--------+-------------
sub1 | pgoutput | logical | sourcedb | t | 0/6022D30
(1 row)desdb=# SELECT * FROM pg_subscription;
subdbid | subname | subowner | subenabled | subconninfo | subslotname | subsynccommit | subpublications
---------+---------+----------+------------+---------------------------------------------------------------------------------------+-------------+---------------+-----------------
24995 | sub1 | 10 | t | host=192.168.56.32 port=5432 user=logical_repl dbname=sourcedb password=logical_repl | sub1 | off | {pub1}
(1 row)2019-10-10 15:57:21.847 CST [27443] ERROR: could not start initial contents copy for table "public.logical_tb1": ERROR: permission denied for table logical_tb1
2019-10-10 15:57:21.848 CST [24722] LOG: background worker "logical replication worker" (PID 27443) exited with exit code 1sourcedb=# GRANT USAGE ON SCHEMA public TO logical_repl;
GRANT
sourcedb=# GRANT SELECT ON logical_tb1 TO logical_repl;
GRANT2019-10-10 16:00:25.959 CST [28204] LOG: logical replication table synchronization worker for subscription "sub1", table "logical_tb1" has started
2019-10-10 16:00:25.967 CST [28204] LOG: logical replication table synchronization worker for subscription "sub1", table "logical_tb1" has finished/** 在主库插入数据 */
sourcedb=# insert into logical_tb1(id,name) values(1,'a'),(2,'bca');
INSERT 0 2/** 查看数据是否同步完成 */
desdb=# select * from logical_tb1;
id | name
----+------
1 | a
2 | bca
(2 rows)/** 主库上创建表结构 */
sourcedb=# create table logical_tb2(id int primary key ,addr varchar(100));
CREATE TABLE
sourcedb=#
/** 从库上创建表结构 */
desdb=# create table logical_tb2(id int primary key ,addr varchar(100));
CREATE TABLE
/** 在主库上给逻辑复制账号授权 */
sourcedb=# GRANT SELECT ON logical_tb2 TO logical_repl;
GRANT
/** 添加新表至发布列表 */
sourcedb=# ALTER PUBLICATION pub1 ADD TABLE logical_tb2;
ALTER PUBLICATION
/** 在主库查看发布列表中的表名 */
sourcedb=# SELECT * FROM pg_publication_tables;
pubname | schemaname | tablename
---------+------------+-------------
pub1 | public | logical_tb1
pub1 | public | logical_tb2
(2 rows)/** 主库插入一条记录 */
sourcedb=# insert into logical_tb2(id,addr) values(1,'beijing');
INSERT 0 1
/** 此时在逻辑从库查看,结果却没有数据 */
desdb=# select * from logical_tb2;
id | addr
----+------
(0 rows)/** 此时在从库刷新订阅 */
desdb=# ALTER SUBSCRIPTION sub1 REFRESH PUBLICATION;
/** 刷新完成后再查数据已经有数据了 */
ALTER SUBSCRIPTION
desdb=# select * from logical_tb2;
id | addr
----+---------
1 | beijing
(1 row)我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
我已经找到了几个使用datamapper的示例,并且能够让它们正常工作。不过,所有这些示例都是针对sqlite数据库的。我正在尝试将数据映射器与postgresql一起使用。我将datamapper中的调用从sqlite3更改为postgres,并且我已经安装了dm-postgres-adapter。但它仍然不起作用。我还需要做什么? 最佳答案 与SQLite不同,PostgreSQL不将数据库存储在单个文件中。在你拥有createdyourdatabase之后,尝试这样的事情:DataMapper.setup:default,{:
我想编写一个ruby脚本来递归复制目录结构,但排除某些文件类型。因此,给定以下目录结构:folder1folder2file1.txtfile2.txtfile3.csfile4.htmlfolder2folder3file4.dll我想复制这个结构,但不包含.txt和.cs文件。因此,生成的目录结构应如下所示:folder1folder2file4.htmlfolder2folder3file4.dll 最佳答案 您可以使用查找模块。这是一个代码片段:require"find"ignored_extensions=[".cs"
我找到了这样的东西:Rails:Howtolistdatabasetables/objectsusingtheRailsconsole?这一行没问题:ActiveRecord::Base.connection.tables并返回所有表但是ActiveRecord::Base.connection.table_structure("users")产生错误:ActiveRecord::Base.connection.table_structure("projects")我认为table_structure不是Postgres方法。如何列出Postgres数据库的Rails控制台中表中的所有
之前有人问过这个问题,我发现了以下clip关于如何一次设置一个类对象的所有属性,但由于批量分配保护,这在Rails中是不可能的。(例如,您不能Object.attributes={})有没有一种很好的方法可以将一个类的属性合并到另一个类中?object1.attributes=object2.attributes.inject({}){|h,(k,v)|h[k]=vifObjectModel.column_names.include?(k);h}谢谢。 最佳答案 利用assign_attributes使用:without_prote
我想使用PostgreSQL中的point类型。我已经完成了:railsgmodelTestpoint:point最终的迁移是:classCreateTests当我运行时:rakedb:migrate结果是:==CreateTests:migrating====================================================--create_table(:tests)rakeaborted!Anerrorhasoccurred,thisandalllatermigrationscanceled:undefinedmethod`point'for#/hom
我正在使用带有单个“帐户”表的STI模型来保存用户和技术人员的信息(即用户...8)错误:test_the_truth(用户测试):ActiveRecord::StatementInvalid:PGError:ERROR:关系“技术人员”不存在:从“技术人员”中删除...从本质上讲,标准框架不承认Technicians和Users表(或PostgreSQL称它们为“关系”)不存在,事实上,应该别名为Accounts。有什么想法吗?我对RoR比较陌生,不知道如何解决这个问题而又不完全删除STI。 最佳答案 原来问题是由于存在:./te
我正在使用PostgreSQL9.1.3(x86_64-pc-linux-gnu上的PostgreSQL9.1.3,由gcc-4.6.real(Ubuntu/Linaro4.6.1-9ubuntu3)4.6.1,64位编译)和在ubuntu11.10上运行3.2.2或3.2.1。现在,我可以使用以下命令连接PostgreSQLsupostgres输入密码我可以看到postgres=#我将以下详细信息放在我的config/database.yml中并执行“railsdb”,它工作正常。开发:adapter:postgresqlencoding:utf8reconnect:falsedat
(跟进我之前的问题,Ruby:howcanIcopyavariablewithoutpointingtothesameobject?)我正在编写一个简单的Ruby程序来在.svg文件中进行一些替换。第一步是从文件中提取信息并将其放入数组中。为了避免每次调用此函数时都从磁盘读取文件,我尝试使用memoize设计模式-在第一次调用后的每次调用中都使用缓存结果。为此,我使用了一个在函数之前定义的全局变量。但是,即使我在返回局部变量之前将该变量.dup为局部变量,调用该变量的函数仍在修改全局变量。这是我的实际代码:#memoizetokeepfromhavingtoreadoriginalfi
文章目录一基础定义二创建逻辑卷2-1准备物理设备2-2创建物理卷2-3创建卷组2-4创建逻辑卷2-5创建文件系统并挂载文件三扩展卷组和缩减卷组3-1准备物理设备3-2创建物理卷3-3扩展卷组3-4查看卷组的详细信息以验证3-5缩减卷组四扩展逻辑卷4-1检查卷组是否有可用的空间4-2扩展逻辑卷4-3扩展文件系统五删除逻辑卷5-1备份数据5-2卸载文件系统5-3删除逻辑卷5-4删除卷组5-5删除物理卷六LVM逻辑卷缩容6-1缩容注意事项6-2标准缩容步骤一基础定义LVM,LogicalVolumeManger,逻辑卷管理,Linux磁盘分区管理的一种机制,建立在硬盘和分区上的一个逻辑层,提高磁盘分