良好的编码风格,有助于代码的阅读、调试和修改。虽然 Verilog 代码可以在保证语法正确的前提下任意编写,但是潦草的编码风格往往是一锤子买卖。有时回看自己编写的代码,既看不出信号的意义,也不了解模块的功能,还得从逻辑上一步步分析,就会消耗大量的时间和精力去消化,严重影响设计进度。
为了不让别人或自己由衷的感叹出:这特喵的是哪个"小傻宝"写的代码!下面对编码风格进行一定意义上的建议。
信号变量、模块等一定要使用有意义的名字,且信号名称在模块间穿梭时也应该保持不变,以便代码自身就具有清晰的说明信息,增强可读性。
当名字单词数量过多时,可以使用首字母大写或下划线"_"进行拼接。个人喜欢后者,比较清晰。
reg DataToDestinationClock ;
reg data_to_destination_clock ; //推荐
建议使用单词缩写的方式对信号进行命名,并懂得取舍,避免过长的信号命名。例如 clock 缩写为 clk, destination 缩写为 dest,source 缩写为 src 等。
reg data_to_destination_clock ; reg des_data ; //推荐巧用数字代表英文字母,例如 2 代表 to, 4 代表 for, 可以省略一丢丢代码空间。
reg clk_for_test, sig_uart_to_spi ; reg clk4test, sig_uart2spi ; //推荐
虽然 Verilog 区分大小写,但是建议一般功能模块的名称、端口、信号变量等全部使用小写,parameter 使用大写,一些电源、pad 等特殊端口使用大写。只为编写代码方便,容易区分常量变量,不用考虑大小写不一样但名字相同的信号变量的差异。
parameter DW = 8 ; //常量 reg [DW-1 : 0] wdata ; //变量
寄存器变量一般加后缀 _r, 延迟打拍的变量加后缀 _r1、_r2等。主要有两大好处。一是 RTL 设计时容易根据变量类型对数据进行操作。二是综合后网表的信号名字经常会改变,加入后缀容易在综合后网表中找到与 RTL 中对应的信号变量。
wire dout_en ; reg dout_en_r ; ... //dout_en_r 的逻辑 assign dout_en = dout_en_r ;
其他尾缀:_d 可以表示延迟后的信号,_t 可以表示暂时存储的信号,_n 可以表示低有效的信号,_s 可以表示 slave 信号,_m 可以表示 master 信号等。
避免使用关键字对信号进行命名,例如 in, out, x, z 均不建议作为变量。
文件名字保持与设计的 module 名字一致,文件内尽量只包含一个设计模块。
每一个设计模块开头,都应该包含文件说明信息,包括版权、模块名字、作者、日期、梗概、修改记录等信息。例如:
/********************************************************** // Copyright 1891.06.02-2017.07.14 // Contact with willrious@sina.com ================ runoob.v ====================== >> Author : willrious >> Date : 1995.09.07 >> Description : Welcome >> note : (1)To >> : (2)My >> V180121 : World. ************************************************************/
注释应该精炼的表达出代码所描述的意义,简短的注释在一行语句代码之后添加,过长的注释提前一行书写。
//输出位宽小于输入位宽,求取缩小的倍数及对应的位数 parameter SHRINK = DWI/DWO ; reg [AWI-1:0] ADDR_WR ; //写地址
注释尽量用英文书写,以保证不同操作系统、不同编辑器下能够正常显示。
端口信号中,除一般的时钟和复位信号,其他信号最好也进行注释。
注释功能非常强大,可以使用注释信息画出时序图,甚至可以使用注释画出数字电路结构图。

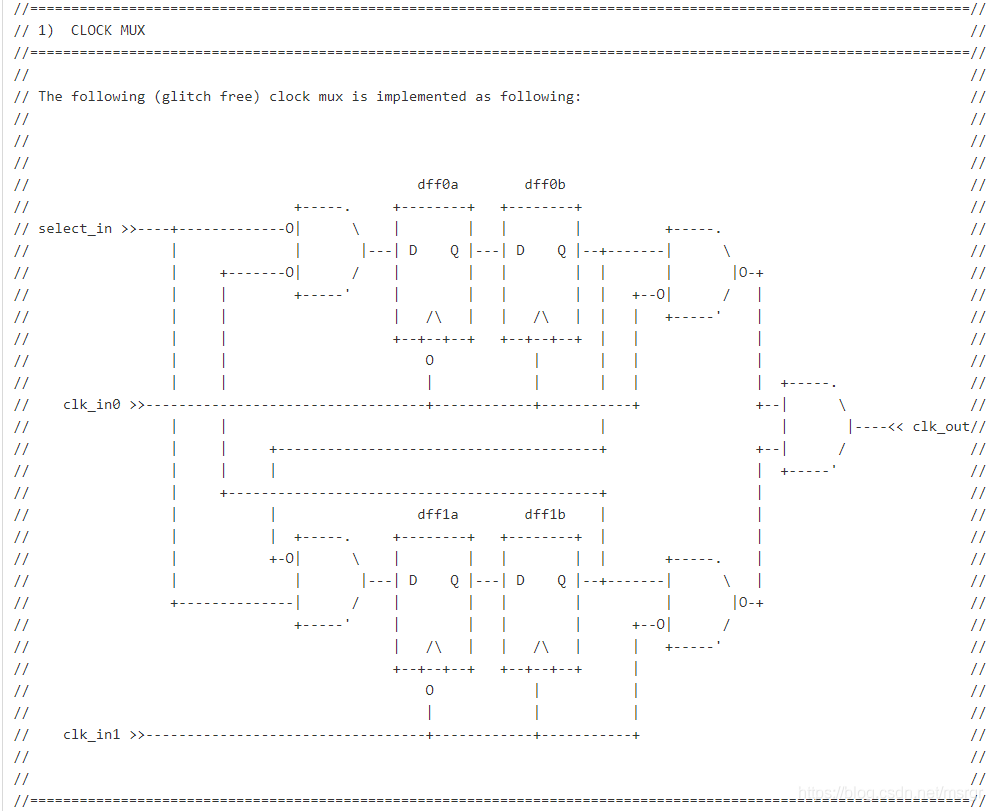
使用圆括号确定程序的优先级或逻辑结构。为避免操作符优先级问题导致设计错误,建议多多使用圆括号。同时,圆括号的巧妙使用有时候也会优化逻辑综合后的结构。例如:
//往往被综合成串行的 3 个加法器
assign F = A + B + C + D ;
//往往被综合成并行的的 2 个加法器和 1 个级联的加法器,时序更加宽松
assign F = (A + B) + (C + D) ;
//不推荐
assign flag = cnt == 4'd2 && mode == 2'b01;
//推荐
assign flag = (cnt == 4'd2) && (mode == 2'b01);
条件语句尽量使用 case 语句代替 if 语句。当同级别的条件判断语句过多时,使用 case 语句综合后的硬件结构,往往比 if 语句消耗更少的资源,拥有更好的时序。
状态机编写时,尽量使用 3 段式,以保证代码具有良好的整洁性和安全性。
系统设计时,尽量采用模块按功能分割、然后进行模块例化的方法。相比成千上万行代码都集成在一个文件中,模块分割有利于团队设计,便于更新维护。
端口信号保证每行一个信号,逗号紧跟在端口声明之后,强迫症患者请保持逗号也对齐。
//不推荐
module even_divisor (input rstn, clk, output clk_div2, clk_div4, clk_div10) ;
//推荐
module even_divisor (
input rstn ,
input clk ,
output clk_div2 ,
output clk_div4 ,
output clk_div10
);
一行代码内容过长时,尽量换行编写,无需使用换行符,例如:
assign rempty = (rover_flag == rq2_wptr_decode[AWI]) &&
(raddr_ex >= rq2_wptr_decode[AWI-1:0]);
尽量使用 begin + end 的方式保证执行语句间的层叠关系。begin 与关键字同行,end 另起一行。例如,always 语句块使用时,或条件语句只有一条执行语句时,都可以省略 begin + end 关键字。但为保证结构的完整性,以及后续代码的调试与修改,还是建议加入此类关键字。
always @(posedge dout_clk or negedge rstn) begin
if (!rstn) begin
dout_en_r <= 1'b0 ;
end
else begin
dout_en_r <= rd_en_wir ;
end
end
尽量使用 tab 键和空格,保证语句按照层级结构对齐,变量、关键字、操作符之间也应该留有空隙,便于逻辑判断。
generate
if (DWO >= DWI) begin
reg [DWI-1:0] mem [(1<<AWI)-1 : 0] ;
always @(posedge CLK_WR) begin
if (WR_EN) begin
mem[ADDR_WR] <= D ;
end
end
end
endgenerate
模块例化时,端口信号尽量与连接信号隔开,并各自对齐。连接信号为向量时指明其位宽,方便阅读、调试。
ram u_ram(
.CLK_WR (clk),
.WR_EN (wren), //写满时禁止写
.ADDR_WR (addr),
.D (wdata[9:0]),
.Q (rdata[31:0])
);
例化多个相同的模块时,尽量使用 generate 语句,避免过长的例化代码描述。
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
我正在尝试在Ruby中复制Convert.ToBase64String()行为。这是我的C#代码:varsha1=newSHA1CryptoServiceProvider();varpasswordBytes=Encoding.UTF8.GetBytes("password");varpasswordHash=sha1.ComputeHash(passwordBytes);returnConvert.ToBase64String(passwordHash);//returns"W6ph5Mm5Pz8GgiULbPgzG37mj9g="当我在Ruby中尝试同样的事情时,我得到了相同sha
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
查看Ruby代码,它具有以下proc_arity:staticVALUEproc_arity(VALUEself){intarity=rb_proc_arity(self);returnINT2FIX(arity);}更多的是C编码风格问题,但为什么staticVALUE在单独的一行而不是像这样的:staticVALUEproc_arity(VALUEself) 最佳答案 它来自UNIX世界,因为它有助于轻松grep函数的定义:$grep-n'^proc_arity'*.c或使用vim:/^proc_arity
我创建了一个由于“在运行时执行的单例元类定义”而无法编码的对象(这段代码的描述是否正确?)。这是通过以下代码执行的:#defineclassXthatmyusesingletonclassmetaprogrammingfeatures#throughcallofmethod:break_marshalling!classXdefbreak_marshalling!meta_class=class我该怎么做才能使对象编码正确?是否可以从对象instance_of_x的classX中“移除”单例组件?我真的需要一个建议,因为我们的一些对象需要通过Marshal.dump序列化机制进行缓存。
我在使用Ruby1.9.2p290更改文本文件的编码时遇到问题。我收到错误消息invalidbytesequenceinUTF-8(ArgumentError)。问题(我认为)在于字符集似乎是未知的。如果我执行以下操作,则从命令行:$filetest.txt我得到:Non-ISOextended-ASCIIEnglishtext,withCRLFlineterminators或者,或者,如果我这样做:$file-itest.txt我得到:test.txt:text/plain;charset=unknown但是,如果我这样做,在Ruby中:data=File.open("test.tx
这是我发现自己偶尔想做的事情。假设我有一个参数列表。在Lisp中,我可以像这样`(imaginary-function,@args)为了调用将数组从一个元素转换为正确数量的参数的函数。Ruby中是否有类似的功能?或者我只是在这里使用了一个完全错误的成语? 最佳答案 是的!它被称为splat运算符。a=[1,44]p(*a) 关于Ruby:如何将数组拼接成Lisp风格的列表?,我们在StackOverflow上找到一个类似的问题: https://stackov