现在静态博客的标配之一就是博客搜索🔍,我也是通过搭建博客发现了它,这篇主要记录一下怎么使用 algolia 完成博客搜索,自己的博客搭建使用的是 docusaurus 。
首先需要去 algolia 官网注册自己的账号,可以直接使用 Github 注册登陆即可。
注册完后,创建数据源 DB:
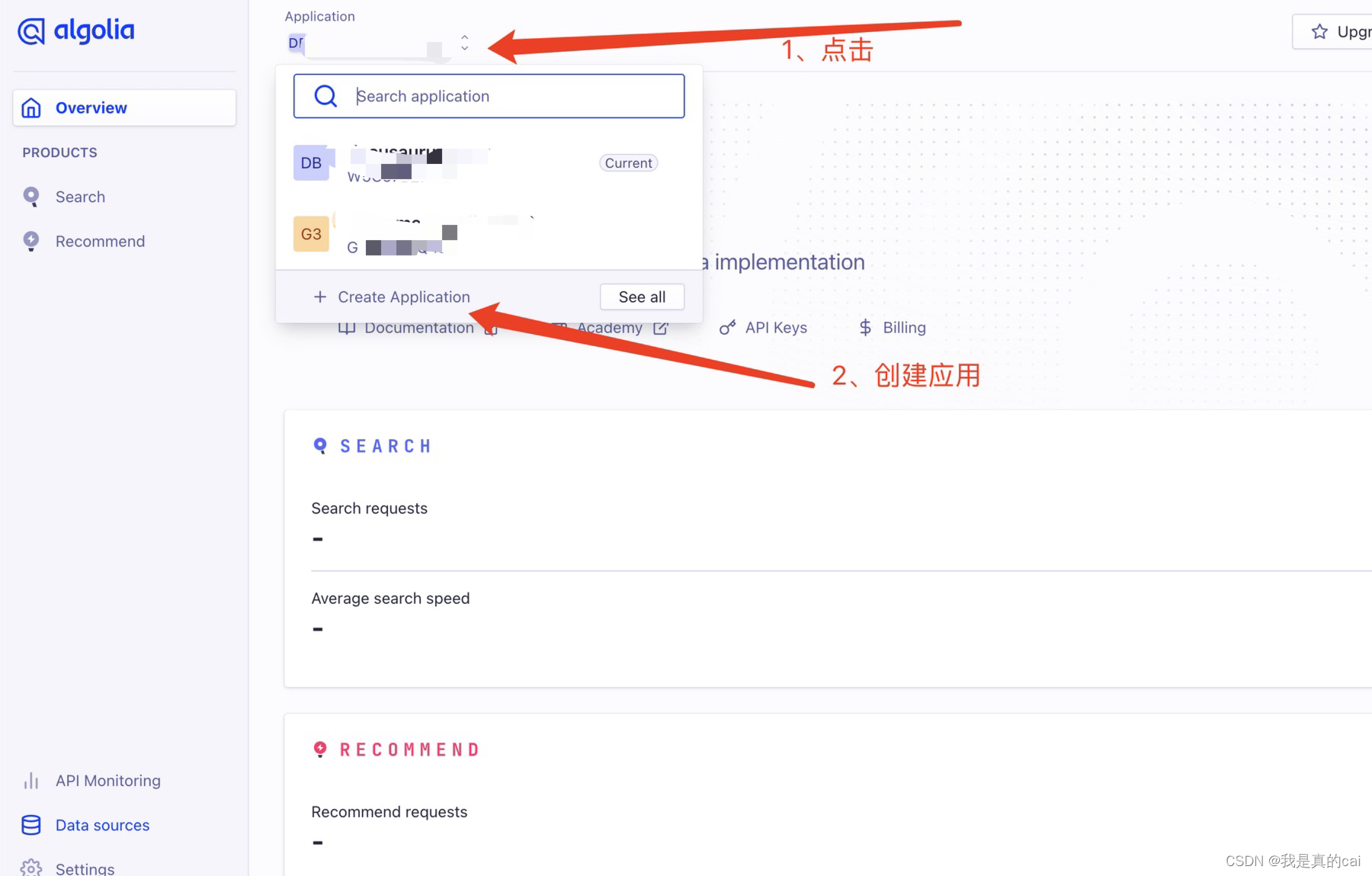
然后就是创建了你自己的应用了:
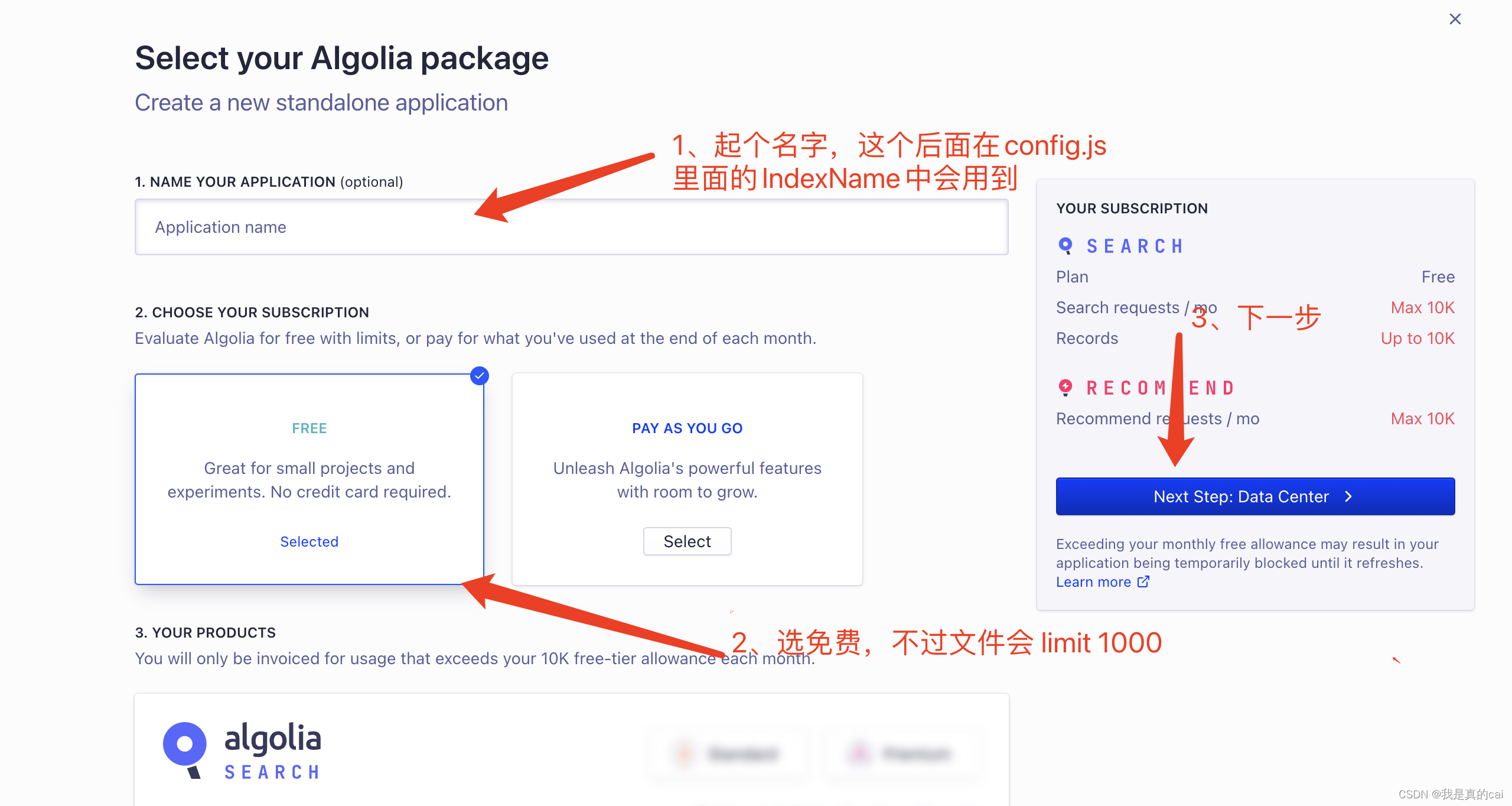
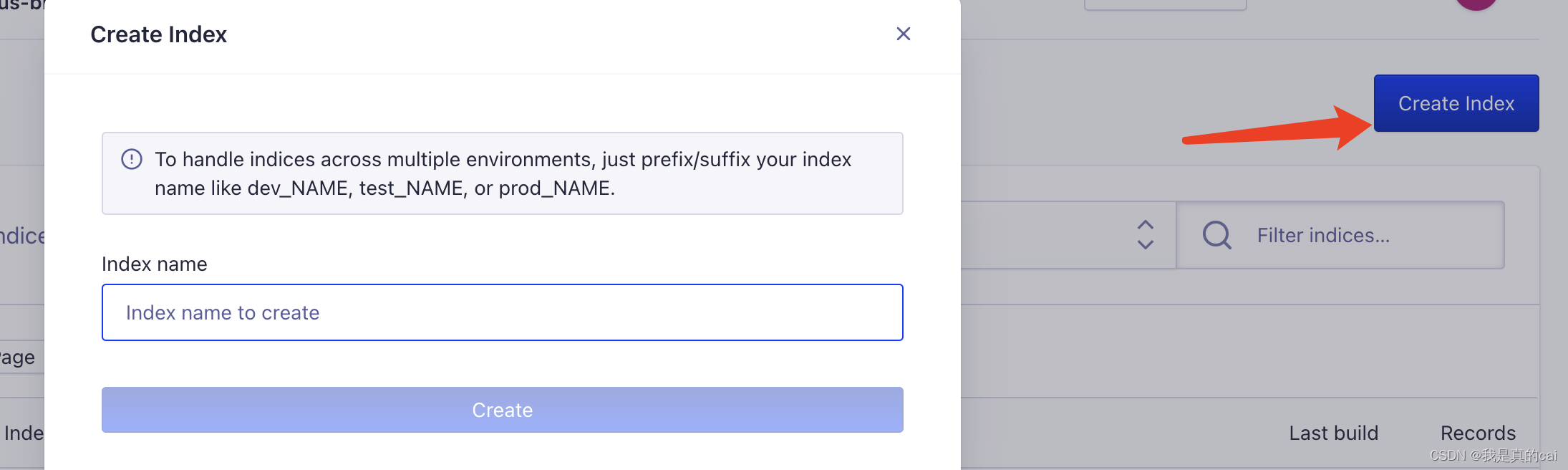
创建完之后,需要创建关键的 index 索引了,它用来存放爬取到的内容数据。点击 Indices
再给索引起个名字:这个名字后面会用到!
Docusaurus 官方已经支持了 algolia 搜索,直接去 docusaurus.config.js 文件配置即可:
themeConfig: {
// ...
algolia: {
apiKey: "Search-Only API Key",
indexName: "刚才创建索引的 name,不是数据源的 name",
appId: "Application ID",
},
}
如果是用其他搭建的比如 Hexo,VuePress/ VitePres,也类似,在对应在 config 文件配置就好。
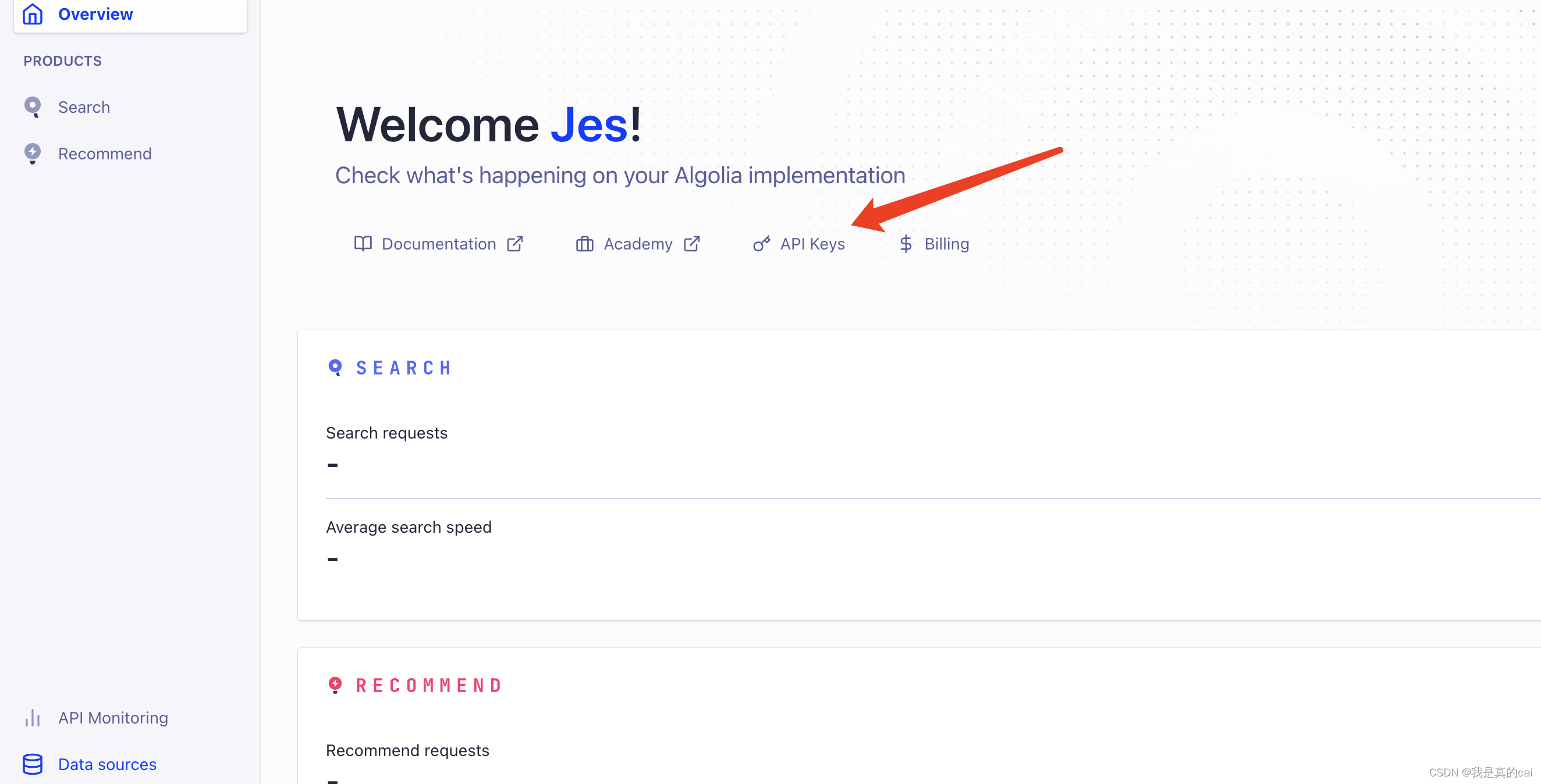
上面 apiKey、appId 可以在 API Keys 里面查看:
运行项目,就可以看到出现搜索功能,这时候还不能用,因为 algolia 还没有爬取自己网站的内容。
由于 Algolia 限制开源项目才可以免费试用爬虫,所以我们要自己推送数据。需要如下环境:
brew install jq)—— 解析 json 文件用爬取环境创建后,完成以下步骤
1、 创建 .env 文件存放环境变量
ALGOLIA_APP_ID=xxx
ALGOLIA_API_KEY=xxx
2、创建一个docsearch.json文件
{
// 修改部分
"index_name": "对应上config文件里面的indexName,也是创建的索引名",
"start_urls": ["https://www.website.com/"], // 自己的域名网站地址
// 更换自己的域名地址,Docusaurus 官方会有配置生成 sitemap.xml 的方式
"sitemap_urls": ["https://www.website.com/sitemap.xml"],
// end
"stop_urls": ["/search"], // 排除不需要爬取页面的路由地址
"selectors": {
"lvl0": {
"selector": "(//ul[contains(@class,'menu__list')]//a[contains(@class, 'menu__link menu__link--sublist menu__link--active')]/text() | //nav[contains(@class, 'navbar')]//a[contains(@class, 'navbar__link--active')]/text())[last()]",
"type": "xpath",
"global": true,
"default_value": "Documentation"
},
"lvl1": "header h1, article h1",
"lvl2": "article h2",
"lvl3": "article h3",
"lvl4": "article h4",
"lvl5": "article h5, article td:first-child",
"lvl6": "article h6",
"text": "article p, article li, article td:last-child"
},
"custom_settings": {
"attributesForFaceting": [
"type",
"lang",
"language",
"version",
"docusaurus_tag"
],
"attributesToRetrieve": [
"hierarchy",
"content",
"anchor",
"url",
"url_without_anchor",
"type"
],
"attributesToHighlight": ["hierarchy", "content"],
"attributesToSnippet": ["content:10"],
"camelCaseAttributes": ["hierarchy", "content"],
"searchableAttributes": [
"unordered(hierarchy.lvl0)",
"unordered(hierarchy.lvl1)",
"unordered(hierarchy.lvl2)",
"unordered(hierarchy.lvl3)",
"unordered(hierarchy.lvl4)",
"unordered(hierarchy.lvl5)",
"unordered(hierarchy.lvl6)",
"content"
],
"distinct": true,
"attributeForDistinct": "url",
"customRanking": [
"desc(weight.pageRank)",
"desc(weight.level)",
"asc(weight.position)"
],
"ranking": [
"words",
"filters",
"typo",
"attribute",
"proximity",
"exact",
"custom"
],
"highlightPreTag": "<span class='algolia-docsearch-suggestion--highlight'>",
"highlightPostTag": "</span>",
"minWordSizefor1Typo": 3,
"minWordSizefor2Typos": 7,
"allowTyposOnNumericTokens": false,
"minProximity": 1,
"ignorePlurals": true,
"advancedSyntax": true,
"attributeCriteriaComputedByMinProximity": true,
"removeWordsIfNoResults": "allOptional",
"separatorsToIndex": "_",
"synonyms": [
["js", "javascript"],
["ts", "typescript"]
]
}
}
控制台执行 docker 爬去推送命令:
docker run -it --env-file=.env -e "CONFIG=$(cat docsearch.json | jq -r tostring)" algolia/docsearch-scraper
需要提前打开下载好的 docker 应用。
接下来就是等待阶段,这里需要点时间download docker 内置的东西。
最后控制台出现:
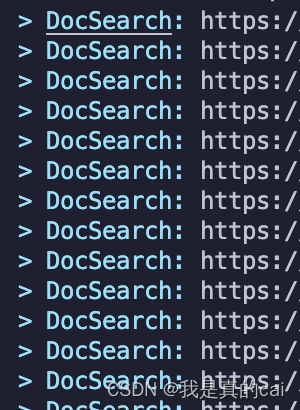
说明就在推送本地爬取的内容到 algolia 了。
可以利用 github 的 Action 帮我们跑这个阶段的内容,这个还是比较方便的。
项目根目录创建 .github/workflows/docsearch.yml 文件
内容:
name: docsearch
on:
push:
branches:
- master
jobs:
algolia:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Get the content of docsearch.json as config
id: algolia_config
run: echo "::set-output name=config::$(cat docsearch.json | jq -r tostring)"
- name: Run algolia/docsearch-scraper image
env:
ALGOLIA_APP_ID: ${{ secrets.ALGOLIA_APP_ID }}
ALGOLIA_API_KEY: ${{ secrets.ALGOLIA_API_KEY }}
CONFIG: ${{ steps.algolia_config.outputs.config }}
run: |
docker run \
--env APPLICATION_ID=${ALGOLIA_APP_ID} \
--env API_KEY=${ALGOLIA_API_KEY} \
--env "CONFIG=${CONFIG}" \
algolia/docsearch-scraper
这里说一下设置 github action 触发的条件
on:
push:
branches:
- master
on: deployment
on:
schedule:
# 约每天早上8点触发(UTC时间0点)
- cron: '0 0 * * *'
on:
workflow_dispatch:
我用的是第一种,提交代码更新文件就触发。
需要注意的是:免费的创建的 algolia 限制文件 records 1000,如果超过的话,Github Action 会跑失败,所以也就是爬取推送不成功。导致搜索用不了。暂时还不知道怎么解决,所以我都是本地用 docker 的。
根据上面步骤就可以完成 algolia 的搜索配置功能。
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复