文章目录
传统的卷积通常是将大图片卷积成一张小图片,而反卷积就是反过来,将一张小图片变成大图片。
但这有什么用呢?其实有用,例如,在生成网络(GAN)中,我们是给网络一个向量,然后生成一张图片
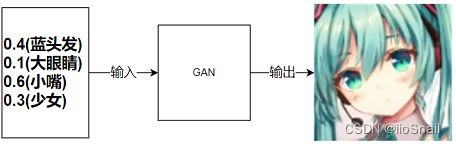
所以我们需要想办法把这个向量一直扩,最终扩到图片的的大小。
在了解反卷积前,先来学习传统卷积的几个padding概念,因为后面反卷积也有相同的概念
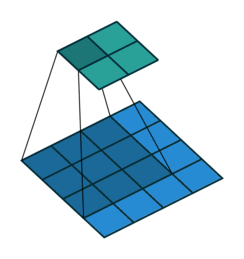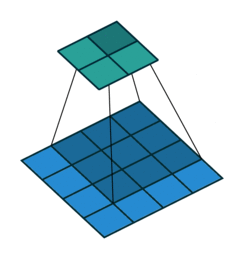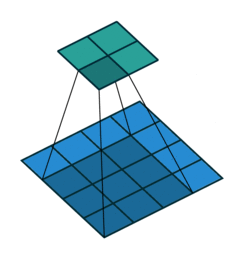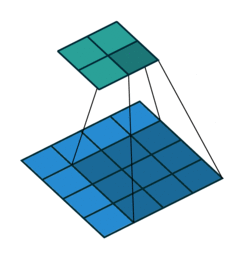
No Padding就是padding为0,这样卷积之后图片尺寸就会缩小,这个大家应该都知道
下面的图片都是 蓝色为输入图片,绿色为输出图片。
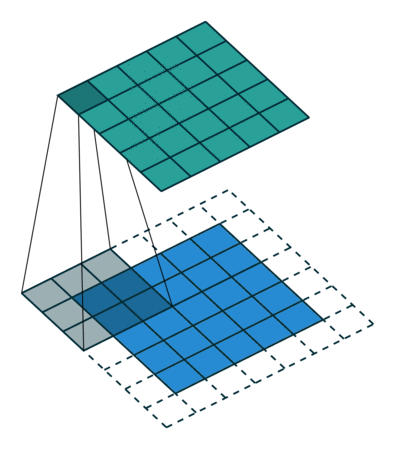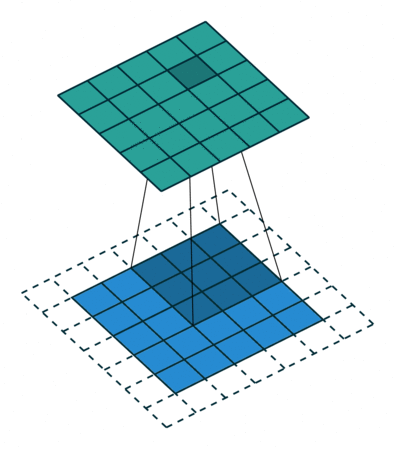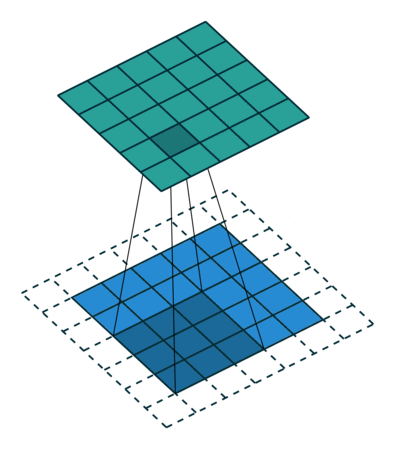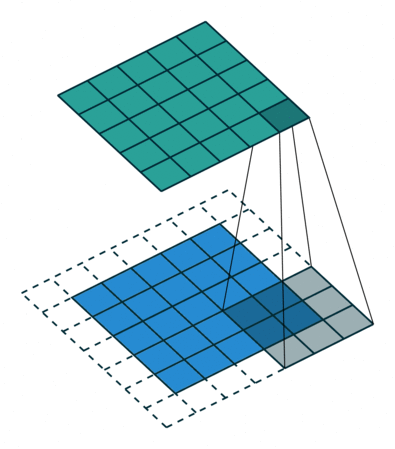
Half Padding也称为Same Padding,先说Same,Same指的就是输出的图片和输入图片的大小一致,而在stride为1的情况下,若想让输入输出尺寸一致,需要指定
p
=
⌊
k
/
2
⌋
p=\lfloor k/2 \rfloor
p=⌊k/2⌋,这就是 Half 的由来,即padding数为kerner_size的一半。
在 pytorch 中支持same padding,例如:
inputs = torch.rand(1, 3, 32, 32)
outputs = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=5, padding='same')(inputs)
outputs.size()
torch.Size([1, 3, 32, 32])
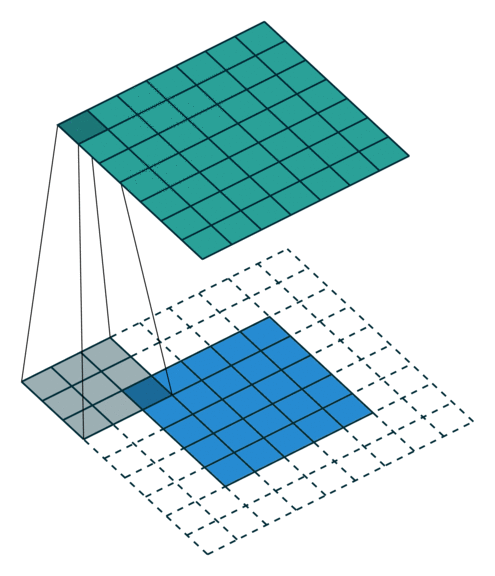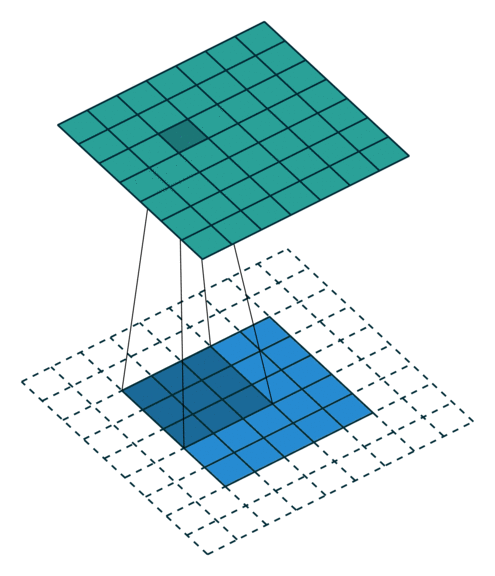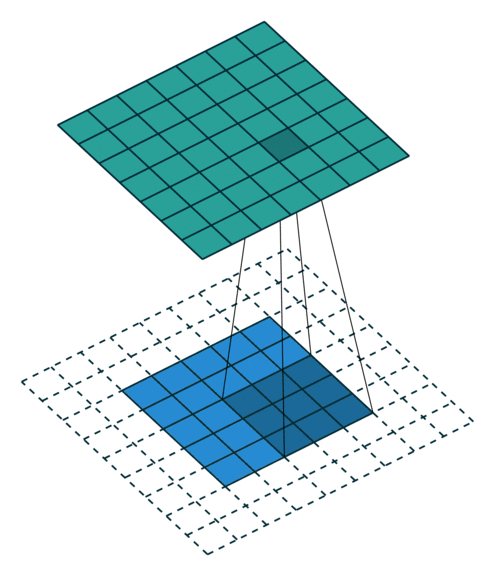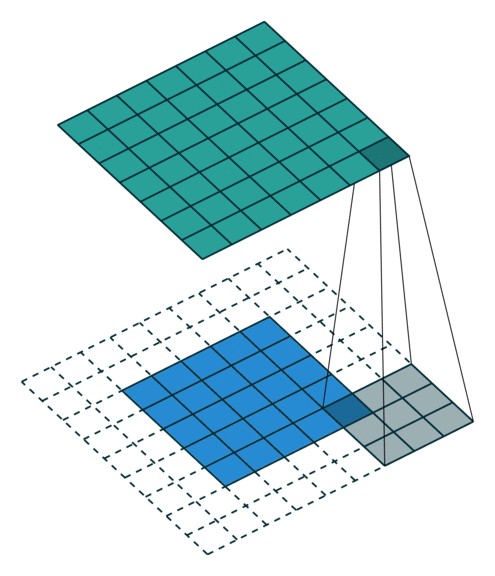
当 p = k − 1 p=k-1 p=k−1 时就达到了 Full Padding。为什么这么说呢?可以观察上图, k = 3 k=3 k=3, p = 2 p=2 p=2,此时在第一格卷积的时候,只有一个输入单位参与了卷积。假设 p = 3 p=3 p=3 了,那么就会存在一些卷积操作根本没有输入单位参与,最终导致值为0,那跟没做一个样。
我们可以用pytorch做个验证,首先我们来一个Full Padding:
inputs = torch.rand(1, 1, 2, 2)
outputs = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=2, bias=False)(inputs)
outputs
tensor([[[[-0.0302, -0.0356, -0.0145, -0.0203],
[-0.0515, -0.2749, -0.0265, -0.1281],
[ 0.0076, -0.1857, -0.1314, -0.0838],
[ 0.0187, 0.2207, 0.1328, -0.2150]]]],
grad_fn=<SlowConv2DBackward0>)
可以看到此时的输出都是正常的,我们将padding再增大,变为3:
inputs = torch.rand(1, 1, 2, 2)
outputs = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=3, bias=False)(inputs)
outputs
tensor([[[[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.1262, 0.2506, 0.1761, 0.3091, 0.0000],
[ 0.0000, 0.3192, 0.6019, 0.5570, 0.3143, 0.0000],
[ 0.0000, 0.1465, 0.0853, -0.1829, -0.1264, 0.0000],
[ 0.0000, -0.0703, -0.2774, -0.3261, -0.1201, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]]],
grad_fn=<SlowConv2DBackward0>)
可以看到最终输出图像周围多了一圈 0,这就是部分卷积没有输入图片参与,导致无效了计算。
反卷积其实和卷积是一样的,只不是参数对应关系有点变化。例如:
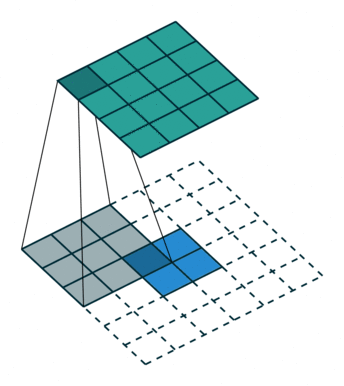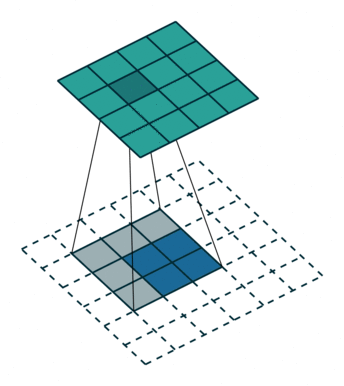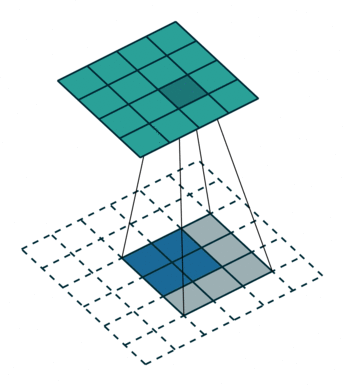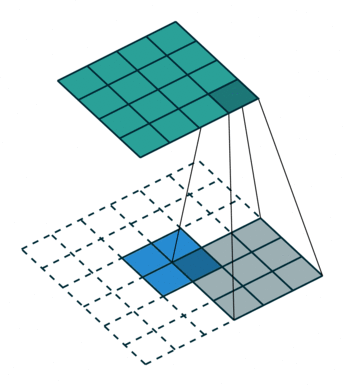
这是一个padding=0的反卷积,这时候你肯定要问了,这padding分明是2嘛,你怎么说是0呢?请看下面
在传统卷积中,我们的 padding 范围为 [ 0 , k − 1 ] [0, k-1] [0,k−1], p = 0 p=0 p=0 被称为 No padding, p = k − 1 p=k-1 p=k−1 被称为 Full Padding。
而在反卷积中的 p ′ p' p′ 刚好相反,也就是 p ′ = k − 1 − p p' = k-1 - p p′=k−1−p 。也就是当我们传 p ′ = 0 p'=0 p′=0 时,相当于在传统卷积中传了 p = k − 1 p=k-1 p=k−1,而传 p ′ = k − 1 p'=k-1 p′=k−1 时,相当于在传统卷积中传了 p = 0 p=0 p=0。
我们可以用如下实验进行验证:
inputs = torch.rand(1, 1, 32, 32)
# 定义反卷积,这里 p'=2, 为反卷积中的Full Padding
transposed_conv = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=3, padding=2, bias=False)
# 定义卷积,这里p=0,为卷积中的No Padding
conv = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=0, bias=False)
# 让反卷积与卷积kernel参数保持一致,这里其实是将卷积核参数的转置赋给了反卷积
transposed_conv.load_state_dict(OrderedDict([('weight', torch.Tensor(np.array(conv.state_dict().get('weight'))[:, :, ::-1, ::-1].copy()))]))
# 进行前向传递
transposed_conv_outputs = transposed_conv(inputs)
conv_outputs = conv(inputs)
# 打印卷积输出和反卷积输出的size
print("transposed_conv_outputs.size", transposed_conv_outputs.size())
print("conv_outputs.size", conv_outputs.size())
# 查看它们输出的值是否一致。
#(因为上面将参数转为numpy,又转了回来,所以其实卷积和反卷积的参数是有误差的,
# 所以不能直接使用==,采用了这种方式,其实等价于==)
(transposed_conv_outputs - conv_outputs) < 0.01
transposed_conv_outputs.size: torch.Size([1, 1, 30, 30])
conv_outputs.size: torch.Size([1, 1, 30, 30])
tensor([[[[True, True, True, True, True, True, True, True, True, True, True,
.... //略
从上面例子可以看出来,反卷积和卷积其实是一样的,区别就几点:
题外话,不感兴趣去可以跳过,在上面第三点我们说了 p ′ p' p′ 的最大值为 k − 1 − p k-1-p k−1−p,但实际你用pytorch实验会发现, p ′ p' p′是可以大于这个值的。而这背后,相当于是对原始图像做了裁剪。
在pytorch的nn.Conv2d中,padding是不能为负数的,会报错,但有时可能你需要让padding为负数(应该没这种需求吧),此时就可以用反卷积来实现,例如:
inputs = torch.ones(1, 1, 3, 3)
transposed_conv = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=1, padding=1, bias=False)
print(transposed_conv.state_dict())
outputs = transposed_conv(inputs)
print(outputs)
OrderedDict([('weight', tensor([[[[0.7700]]]]))])
tensor([[[[0.7700]]]], grad_fn=<SlowConvTranspose2DBackward0>)
上述例子中,我们传给网络的是图片:
[ 1 1 1 1 1 1 1 1 1 ] \begin{bmatrix} 1 & 1 &1 \\ 1 & 1 &1 \\ 1 & 1 &1 \end{bmatrix} ⎣⎡111111111⎦⎤
但是我们传的
p
′
=
1
,
k
=
1
p'=1, k=1
p′=1,k=1,这样在传统卷积中相当于
p
=
k
−
1
−
p
′
=
−
1
p=k-1-p'=-1
p=k−1−p′=−1,相当于 Conv2d(padding=-1),这样在做卷积时,其实是对图片
[
1
]
[1]
[1] 在做卷积(因为把周围裁掉了一圈),所以最后输出的尺寸为
(
1
,
1
,
1
,
1
)
(1,1,1,1)
(1,1,1,1)
这个题外话好像没啥实际用途,就当是更加理解反卷积中的padding参数吧。
反卷积的stride这个名字有些歧义,感觉起的不怎么好,具体什么意思可以看下图:
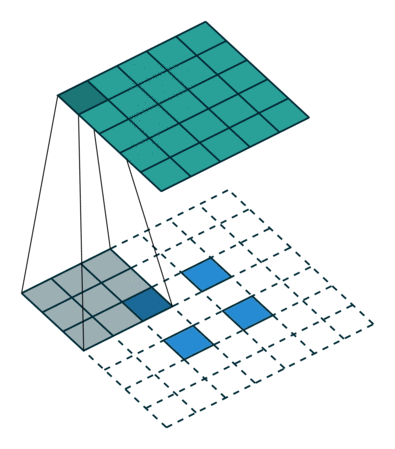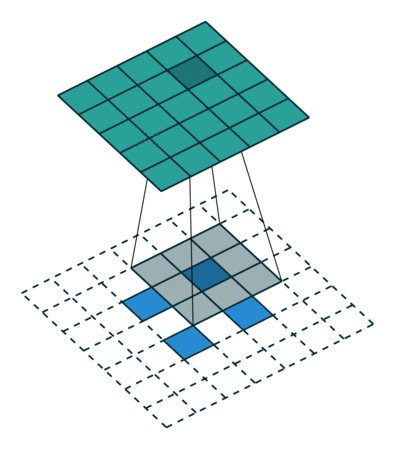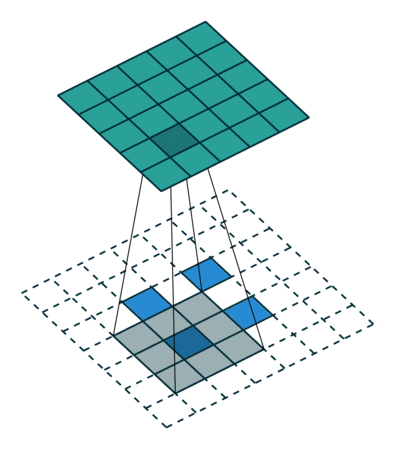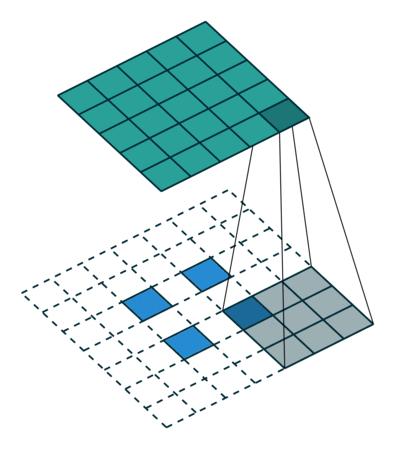
左边是stride=1(称为No Stride)的反卷积,右边是stride=2 的反卷积。可以看到,他们的区别就是在原始图片的像素点中间填充了0。没错,在反卷积中,stride参数就是表示往输入图片每两个像素点中间填充0,而填充的数量就是 stride - 1。
例如,我们对32x32的图片进行反卷积,stride=3,那么它就会在每两个像素点中间填充两个0,原始图片的大小就会变成 32 + 31 × 2 = 94 32+31\times 2=94 32+31×2=94。用代码实验一下:
inputs = torch.ones(1, 1, 32, 32)
transposed_conv = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=3, padding=2, stride=3, bias=False)
outputs = transposed_conv(inputs)
print(outputs.size())
torch.Size([1, 1, 92, 92])
我们来算一下,这里我使用了反卷积的Full Padding(相当于没有对原始图像的边缘进行padding),然后stride传了3,相当于在每两个像素点之间填充两个0,那么原始图像就会变成 94x94 的,然后kernal是3,所以最终的输出图片大小为 94 − 3 + 1 = 92 94-3+1=92 94−3+1=92.
不知道你有没有发现,如果卷积和反卷积的参数一致,卷积会让 A A A 尺寸变为 B B B 尺寸,那么反卷积就会将 B B B 尺寸变为 A A A 尺寸。
举个例子:
inputs = torch.rand(1, 1, 32, 32)
outputs = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=18, padding=3, stride=1)(inputs)
outputs.size()
torch.Size([1, 1, 21, 21])
我们这里将32x32的图片通过卷积变为了 21x21。此时我们将卷积变为反卷积(参数不变),输入图片大小变为 21x21:
inputs = torch.rand(1, 1, 21, 21)
outputs = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=18, padding=3, stride=1)(inputs)
outputs.size()
torch.Size([1, 1, 32, 32])
看,反卷积将 21x21 的图片又变回了 32x32,这也就是为什么要叫反卷积。
但。。,真的是这样嘛,我们再看一个例子:
inputs = torch.rand(1, 1, 7, 7)
outputs = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=0, stride=2)(inputs)
outputs.size()
torch.Size([1, 1, 3, 3])
inputs = torch.rand(1, 1, 8, 8)
outputs = nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=0, stride=2)(inputs)
outputs.size()
torch.Size([1, 1, 3, 3])
inputs = torch.rand(1, 1, 3, 3)
outputs = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=3, padding=0, stride=2)(inputs)
outputs.size()
torch.Size([1, 1, 7, 7])
上面我们对7x7和8x8的图片都使用卷积操作,他们最后结果都是3x3,这样反卷积就会存在歧义,而反卷积默认选择了转换为7x7。原因可以见下图:
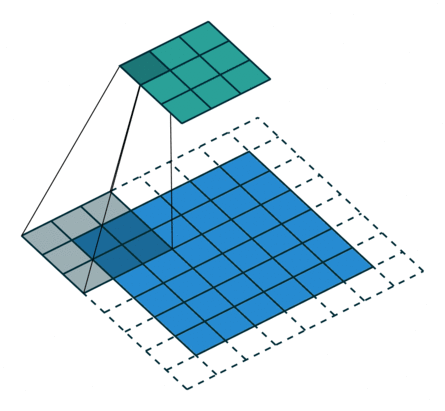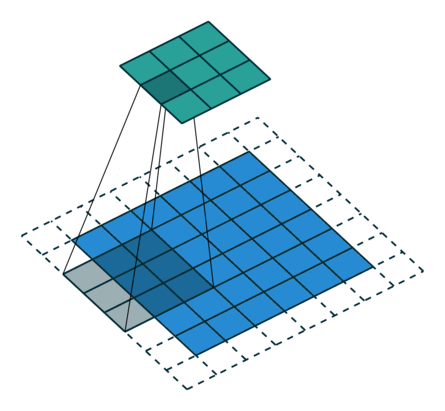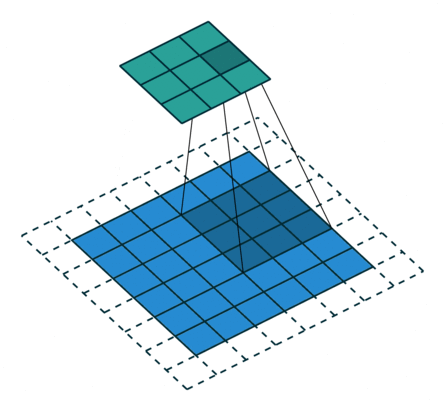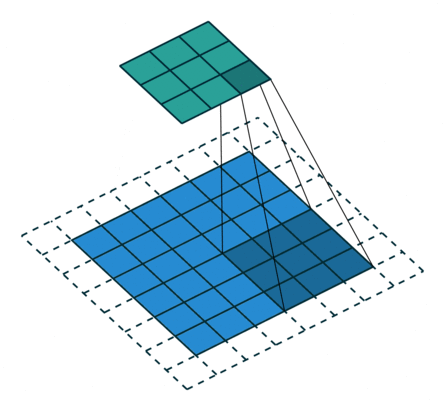
从这张图可以看到,8x8的图片其实最右边和最下边的一行是没有参与卷积运算的,这是因为stride为2,再走2步就超出图片范围了。所以7x7和8x8最终的结果都为3x3。
那么如果我们想让3x3的反卷积得8x8而不是7x7,那么我们就需要在输出图片边缘补充数据,具体补几行就是output_padding指定的。所以output_padding的作用就是:在输出图像右侧和下侧补值,用于弥补stride大于1带来的缺失。其中output_stadding必须小于stride
例如:
inputs = torch.rand(1, 1, 3, 3)
outputs = nn.ConvTranspose2d(in_channels=1, out_channels=1, kernel_size=3, padding=0, stride=2, output_padding=1)(inputs)
outputs
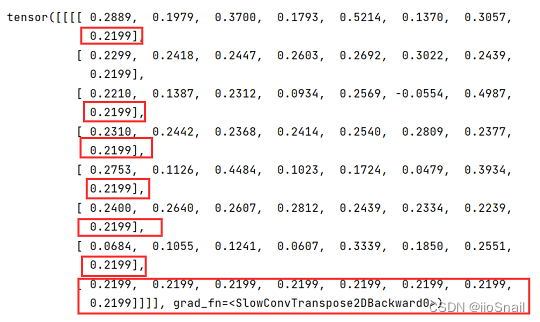
具体这个 0.2199 是什么我也不太清楚,我测试了发现并不是平均值
反卷积的作用是将原始图像进行扩大
反卷积与传统卷积的区别不大,主要区别有:
2.1 padding的对应关系变了,反卷积的padding参数
p
′
=
k
−
1
−
p
p' = k-1-p
p′=k−1−p。其中
k
k
k 是kernel_size, p为传统卷积的padding值;
2.2 stride参数的含义不一样,在反卷积中stride表示在输入图像中间填充0,每两个像素点之间填充的数量为 stride-1
2.3 除了上述的俩参数外,其他参数没啥区别
如果卷积和反卷积的参数一致,卷积会让 AA 尺寸变为 BB 尺寸,那么反卷积就会将 BB 尺寸变为 AA 尺寸
output_padding的作用就是:在输出图像右侧和下侧补值,用于弥补stride大于1带来的缺失。其中output_stadding必须小于stride
Convolution arithmetic: https://github.com/vdumoulin/conv_arithmetic
A guide to convolution arithmetic for deep
learning: https://arxiv.org/pdf/1603.07285.pdf
nn.ConvTranspose2d官方文档: https://pytorch.org/docs/stable/generated/torch.nn.ConvTranspose2d.html
What output_padding does in nn.ConvTranspose2d?:https://stackoverflow.com/questions/67096544/what-output-padding-does-in-nn-convtranspose2d
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use