如今,各行各业都已经意识到了数据的价值,开始沉淀数据资产,挖掘数据价值,但是数据本身其实是很难直观地看到其价值的。数据就是存储在计算机系统的“01”代码,如果你不去用它,能有什么价值?
正如美国哈佛大学教授格林先生所说:数据本身并不等于知识,更不是智慧,只有经过正确分析之后,数据才能凸显它的意义。
在标签体系对外推广实践的过程中,我们也经常会遇到客户提问:辛苦完成标签体系的开发与落库后,该如何使用这些标签,才能发挥其实用价值?
如何把标签所承载的数据信息进行形象化,最直接的方法就是将标签直接拿来使用,进行个体画像分析。向系统提供一个用户ID后,系统会向你展示这个用户的全部标签结果,如下图所示。
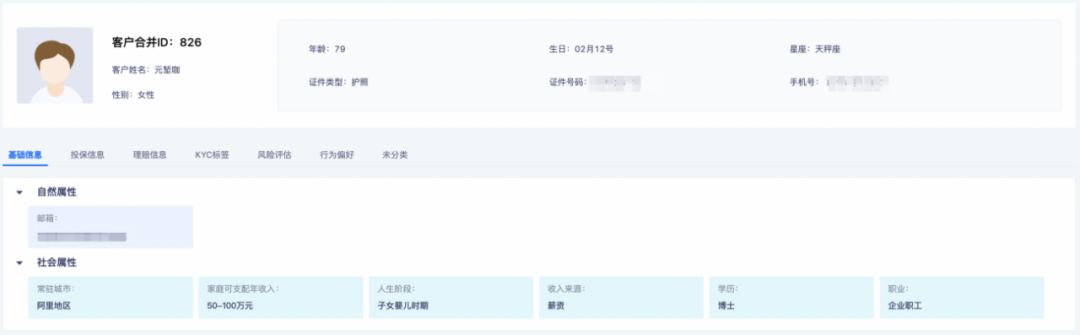
在分析好该用户的特征后,运营就可以根据他的画像特征进行针对性的分析与沟通。例如,该用户当前正处于哺乳期,可以向她推荐一些奶粉产品。
这种针对个体的画像分析通常产生在小数据量的场景下,更多的应用于CRM系统中,如销售人员和客户之间的一对一沟通服务过程。销售人员需要提前介入,根据对用户的初步了解,提前锁定目标问题,给用户带去流畅高效的沟通体验。
然而,在大数据量的场景下,这种一对一沟通方式效率很低。想象一下,用户来到购物平台首页,排队等待服务人员依次进行针对性提问,那用户等不到服务人员对接就已经流失掉了。
面对这种情况不用着急,只需要根据用户特征初步判断其所属人群后,通过用户画像为客户量身制定相关喜好或潜在喜好的推荐,直接将针对该人群的运营策略应用于该客户身上,便能直接切入客户心之所向,大大提升用户体验和服务效率。
这个策略的制定过程通常可以通过以下四步完成:
如确定以提升用户活跃度指标为方向的运营目标。以运营目标为导向才可快速进行用户分析,短时高效地寻找到可以提升整体水平的目标用户。同时,运营目标的制定也可以让运营效果具有可衡量性。
根据运营目标确定筛选条件,筛选出符合要求的用户实现用户圈群。如:需要圈选出使用APP活跃度高且偏好电销渠道和自营APP渠道的用户,则可在「客户数据洞察平台」进行如下配置:
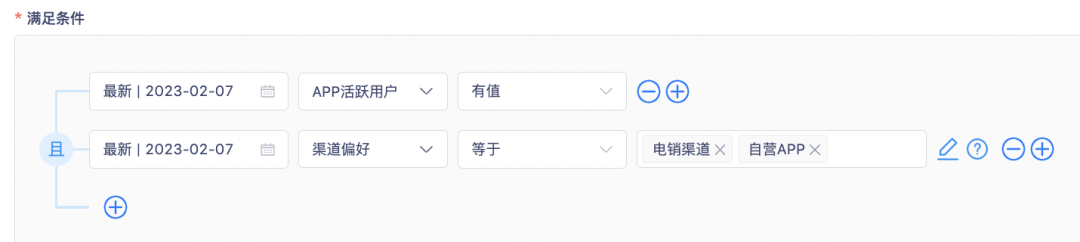
条件的设置主要包含两部分因素:时间和标签结果值。时间可以是绝对时间,也可以是相对时间,如:圈选1月1日注册且过去第1天活跃的用户,这里的1月1日即是绝对时间,过去第1天即是相对时间。
筛选出符合要求的用户后,要对筛选结果进行针对性分析,确定用户群体的整体特征。这里的分析可以有多种方式,典型的分析方法包括群组画像分析、显著性分析、对比分析和群组交并差分析。
● 群组画像分析
针对圈选的用户,系统统计出每个标签的实例数情况,用户根据这个数据结果查看标签分布情况,判断群组在各标签上是否有一些典型特征。
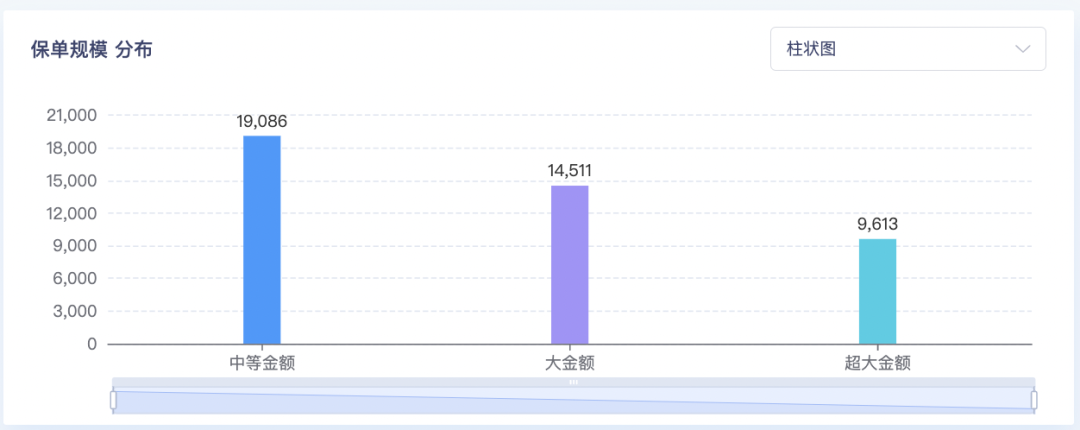
上图即为某一群组在“保单规模”这个标签上的结果分布情况,可以看出,这个群组中保单为中等金额的用户占大多数,保单规模为“中等金额”是这个群组的主要特点之一。
那么,是否根据这个标签的结果分布,我们就可以直接下结论这个群组有这个突出特点呢?答案是否定的。除了进行群组画像分析外,我们还需要用到显著性分析方法。
● 显著性分析
一个群组的构成需要配有相同的或相似的个体特征,这个特征可以是个体的基本属性、来源渠道、兴趣偏好,也可以是具有相似的行为特点,当将这个群体聚集起来时,这个群体的一些个体特征的占比通常比他在集体范围内的特征占比高很多,这就是显著性分析。
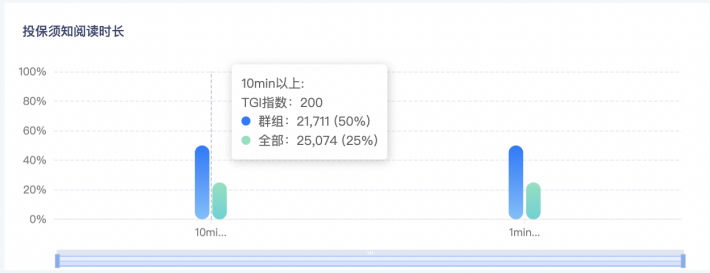
上图举了个分布的例子,总体中,阅读时长超过10分钟的人占比25%,把其中活跃度高的用户筛选出来构成一个群组,这个群组内阅读时长超过10分钟的人占比有50%,阅读时长则是这一群体的显著特征之一。
能够反映这一特征的指数即为TGI指数,其计算公式为:

对应上述例子,TGI = 50% / 20% * 100 = 250。
如何通过TGI来判断显著性?TGI结果以100为基准:当TGI>100时表示目标人群更显著,TGI < 100时表示大盘人群更显著。
除了在当前群体内部做特征分析,也可以和其他群体做比较分析,来确定当前群组有何突出特点。这时,可以进行对比分析或是群组交并差。
● 对比分析
想要将一个高潜用户转化为目标用户,首先需要知道目标用户有什么特点,以及和高潜用户之间的差异是什么?
这时可以通过对比分析来实现。通过下图可以看出,成熟期用户的APP浏览次数明显高于高潜用户数据,进一步分析原因后,就可以制定相应策略将高潜用户转化为成熟用户。

● 群组交并差
针对创建的标签,设置了很多群组,但这其中,有些群组因为时间的变化或是圈群条件的差异性过小,导致圈群结果的相似性过高。这时,如果继续保持这些群组的计算,将会造成大量的资源浪费,同时,运营每天的盯盘效率也会降低。
此时,就需要去比较群组间的差异性,更多的保留差异性大的群组,根据实际需要,对差异性小的群组进行适当取舍。
利用群组交集分析功能,可以查看群组间的交集量级及交集的数据详情。群组并集分析功能则更适用于查看并集组合结果和全部数据之间的量级差异性,以此来查看待分析用户群的覆盖量级情况。如统计所有已创建群组的并集结果,发现有10%的数据没有覆盖,此时可以去分析剩下的10%是因为数据异常,还是标签体系有疏漏导致的用户未覆盖到。群组差集分析功能则更加聚焦于群组的独特性。
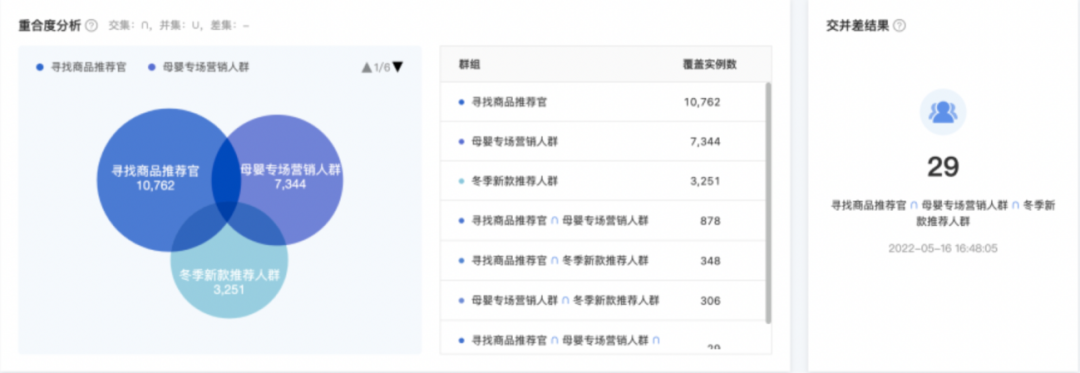
值得注意的是,群组的优劣不能以覆盖实例量级作为衡量标准。高ARPU值用户量级占比很低,但却是企业的主要收入来源,不可小觑。
那么什么样的群组可以被评价为优质群组呢?可以从以下几点考虑:
· 基于你的运营目标,群体可以有典型的特征出现;
· 圈选群组的特征变化将对运营目标的实现起到举足轻重的作用;
· 根据群组特点,用户的稳定性相对较高,这种稳定性体现在用户量级、新增用户占比数据上。
根据群体特点制定运营或营销策略,并落地执行,是实现用户精细化运营和精准营销的重要基石。
群组的一大构成要素就是运营,通常来说,群组构建的越精准,运营策略也就越好构建,运营效果就越好,同时,好的运营策略和运营效果也可以反向让群组更加稳固。
综上所述,标签工作至关重要,它是量化定性因素,提供价值判断的重要工具。基于标签圈群,可以进行用户的深度细分,并挖掘群组的画像特征、显著性特征、对比性特征,掌握群组特点,灵活迭代营销策略,进行精细化运营。
袋鼠云客户数据洞察平台还在持续迭代,精益求精中,未来将围绕用户洞察、标签应用方向、标签实现的方式方法等进行更多的深度场景价值挖掘。
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/