Elasticsearch 作为一个搜索引擎,其可以提供高效的搜索匹配数据的能力,对于这类工具了解其运行原理其实是有一套功法的。
先解释一些概念性名词便于后续的快速理解
index 索引
index 相当于 ES 的数据表,我们主要建立的就是 index 索引文件,搜索也是基于索引来进行,建立的索引文件会存于磁盘
倒排索引
为什么叫 “倒排” 是因为一般的索引是通过下标找数据,而 ES 为了做分词搜索匹配是通过词来匹配找对应数据的下标,其实我觉得不如叫他 “分词索引” 更容易理解。
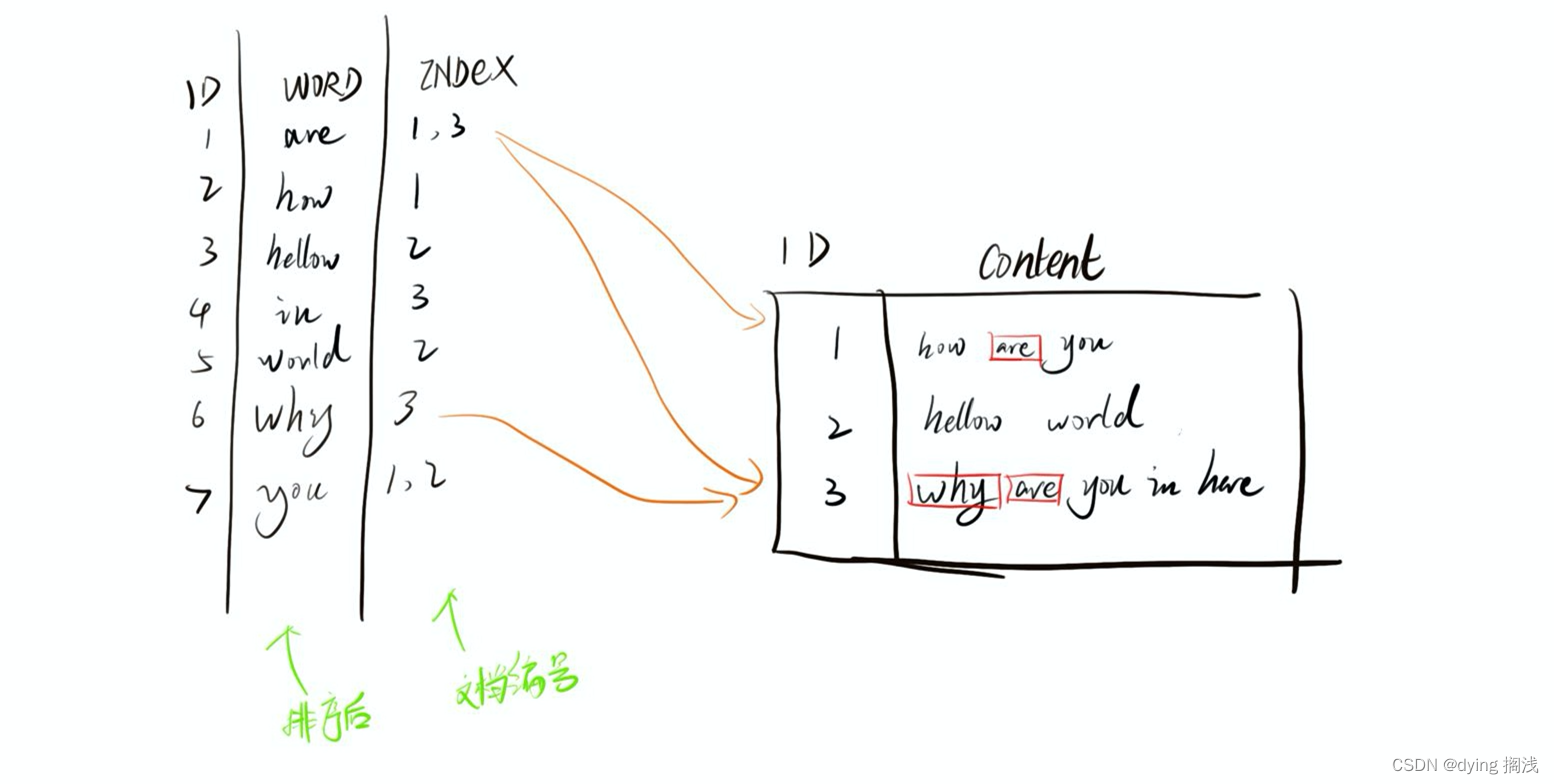
mapping 映射
定义你的 index 索引的数据结构映射,对应概念可以参考 Mysql 的表结构,这个是索引结构,定义了 index 存在那些字段,以及字段类型等相关配置参数。
field 字段
索引的数据字段,同比表字段
document 文档
是可以被索引的基元,人话就是:一条数据,一条记录。在 ES 中记录的格式是 JSON 格式。
cluster 集群
集群由多个节点组成,即多个 ES 服务,他们共同持有索引数据,并对外提供查询写入搜索服务
node 节点
每个 ES 服务称为一个节点,多个节点组成集群,对每个节点可以通过配置集群名称的方式来加入对应的集群。
shards 分片
为了平衡索引存储的大小问题,ES 提供对索引进行了分片的能力,简单理解就是将一个大容量的索引分为多份存储,有几个分片就有几份,而分片可以分布在不同的节点上。默认的确定一个 document 要存储在那个索引分片上是通过 id % 分片数 来确定的,类似 HashMap 的底层逻辑。分片的分布以及如何聚合搜索由 ES 负责管理。分片在 index 创建时指定,后续不可动态更改
replicas 副本
副本是分片的副本,设定几个副本 index 的分片就有几个副本分片,副本可以提供查询服务可以提高查询的并发能力,写入是在主分片然后同步到副本。副本可以在主分片节点宕机时重新选举成为主分片,从而实现高可用。
ES 作为搜索引擎,其索引数据最终是会落到磁盘的,这样的数据是较为持久的。同时在落盘的过程中也使用了内存缓存进行优化。
其实很多的存储工具都在这么玩,持久话是一定要落盘的,但可以使用内存来优化落盘的时间,而内存不可靠可以通过顺序写磁盘记录日志来进行恢复。
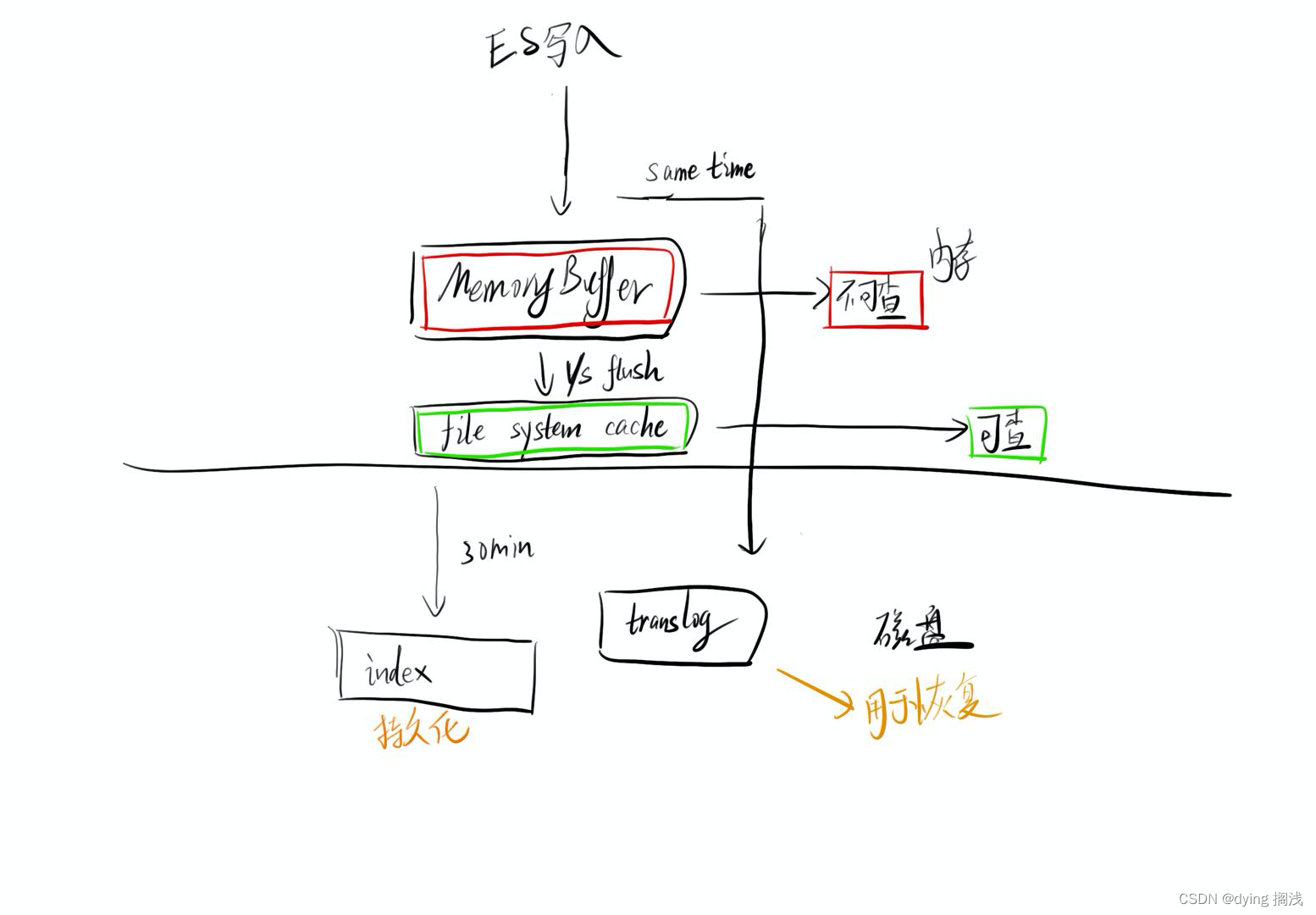
ES 在写入一条数据时首先会写入 memory buffer ,这部分是系统内存,同时会记录 translog 操作记录日志到磁盘(顺序读写命中系统 pageCache 性能较快),ES 每秒会将 memory buffer 数据刷新至 file system cache (或者 memory buffer 满时同步,ES 是基于 Luence 即 Java 实现,适用 JVM 垃圾收集,这里应该是进入了 JVM 内存中),读取到 JVM 内存后可搜索,即进入 file system cache 时可搜索。这个过程通常称之为 refresh 刷新 即 refresh 后数据可搜索
最终将 file system cache 写入 disk 的操作称为 flush 刷盘 flush 后数据持久化 这个过程有同样有两个触发点,一个是 translog 满时会进行 flush 如默认的 512M ,或者到达周期默认 30 min 进行 flush。flush 后会清空 translog
更详细的解释可以参考我之前的一篇博文 ES 的近实时搜索 filesystem cache 与 事务日志 Translog 数据恢复
通常来说企业级的 ES 一定是要组件集群的否则无法达到高可用,对于 ES 服务节点查询请求会发送到某一个 DataNode 数据节点上,此时这个节点会成为协调节点,该节点会广播这个查询请求到其他节点,其他节点在对应分片上进行数据查询最后将数据信息返回给协调节点,协调节点汇总数据进行返回。
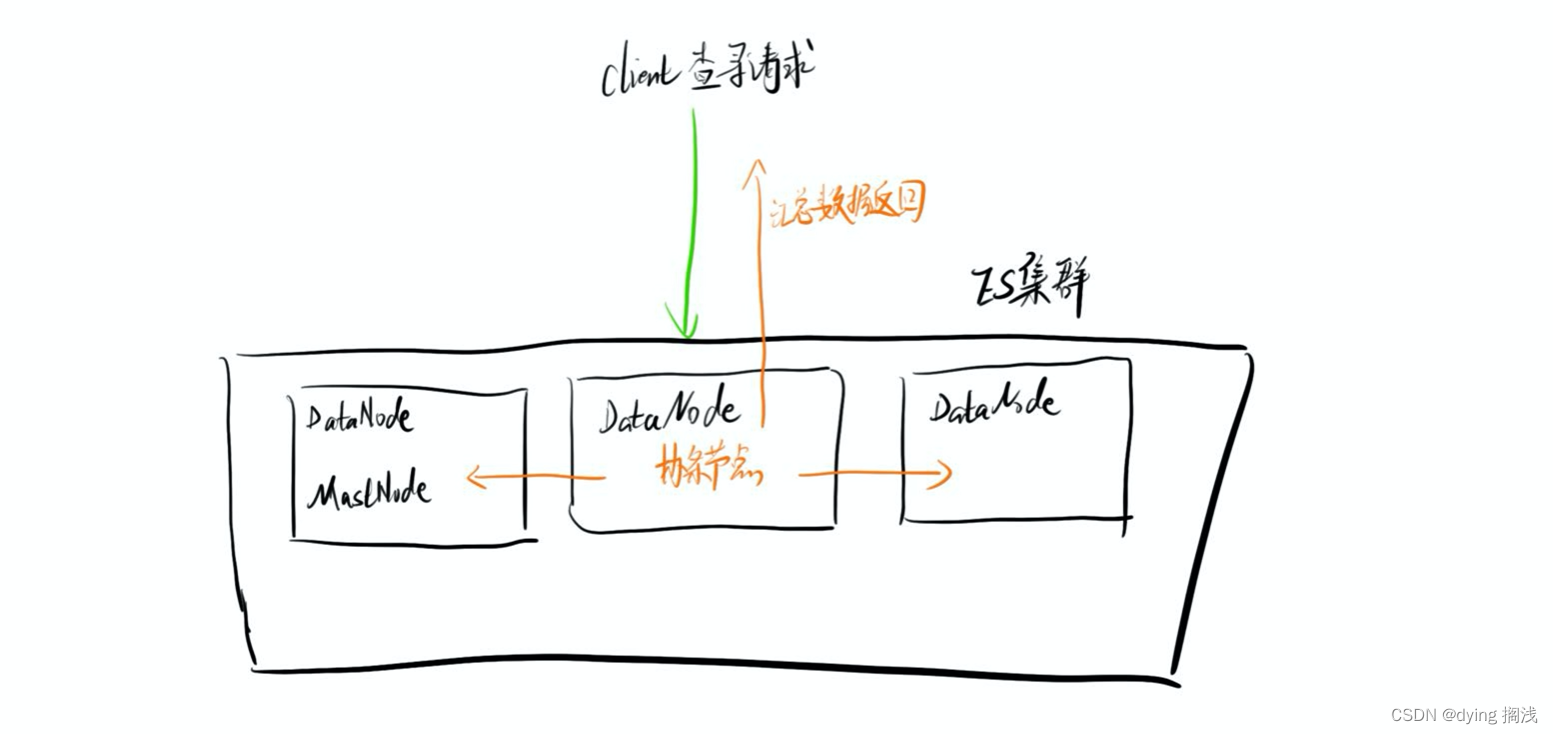
在企业应用中集群部署几乎是必不可少的,我们需要保证服务的高可用,ES 同样如此。一般的 ES 集群要保证至少 3 台或以上,用于保证某台服务宕机后的 Master 节点的选举。
比较常用的 ES 节点可以配置为 DataNode 数据节点,或者 MasterNode 主节点。
主节点负责管理索引(创建删除)以及维护元数据 mapping 以及节点状态,不负责查询和写入。
数据节点则会负责数据的查询写入等功能,估配置了数据节点的服务的内存需求更大。
这个配置可以同时配置,即一个节点即可以为 DataNode 也可以是 MasterNode ,但 MasterNode 在一个集群中只存在一个,配置了可以成为主节点的服务在选举过程中有机会成为主节点
官方提供了 Java High Level REST Client
一般来说在项目中引入 ES 是为了搜索服务即分词文本匹配等检索场景
抛一个 Kibana( ES 可视化管理界面) 设置样例,对应 Java 代码转换可以参考官方案例
PUT /esIndex
{
"mappings": {
"properties": {
"name": {
"type": "keyword",
"index": true,
"store": true
},
"sex": {
"type": "integer",
"index": true,
"store": true
},
"age": {
"type": "integer",
"index": true,
"store": true
}
}
}
}
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',