简介
容器服务 Kubernetes 版(简称 ACK)提供高性能可伸缩的容器应用管理能力,支持企业级容器化应用的全生命周期管理。2021 年成为国内唯一连续三年入选 Gartner 公共云容器报告的产品,2022 年国内唯一进入 Forrester 领导者象限。其整合了阿里云虚拟化、存储、网络和安全能力,助力企业高效运行云端 Kubernetes 容器化应用。
观测云支持 ACK 集群的接入,下面是入门接入的具体步骤。
前置条件
安装 ACK,本次使用版本 1.24.6-aliyun.1 。
注册「观测云账号」。
操作步骤
1 配置 yaml 文件
1.1 下载 datakit.yaml
登录「观测云」,点击「集成」模块,再点击左上角「DataKit」,选择「Kubernetes」,下载 datakit.yaml。本次部署的是 datakit 1.4.19 。
1.2 替换 Token
登录「观测云」,进入「管理」模块,在「基本设置」里面复制 token,替换 datakit.yaml 文件中的 ENV_DATAWAY 环境变量的 value 值中的 。
1.3 增加全局 Tag
针对一个工作空间接入多个 Kubernetes 集群指标,观测云提供了使用全局 Tag 的方式来进行区分。
当集群中只有一个采集对象,比如采集kubernetes API Server指标,集群中 DataKit 的数量会大于一个。为了避免指标采集重复,DataKit 开启了选举功能,这个时候区分集群的方式是增加
ENV_GLOBAL_ELECTION_TAGS;而针对非选举类的指标采集,比如为 Pod 增加 annotations 的方式进行指标采集,观测云提供了在 ENV_GLOBAL_HOST_TAGS环境变量中增加全局 Tag 的方式。(注意:旧版本这个环境变量名称是 ENV_GLOBAL_TAGS。)
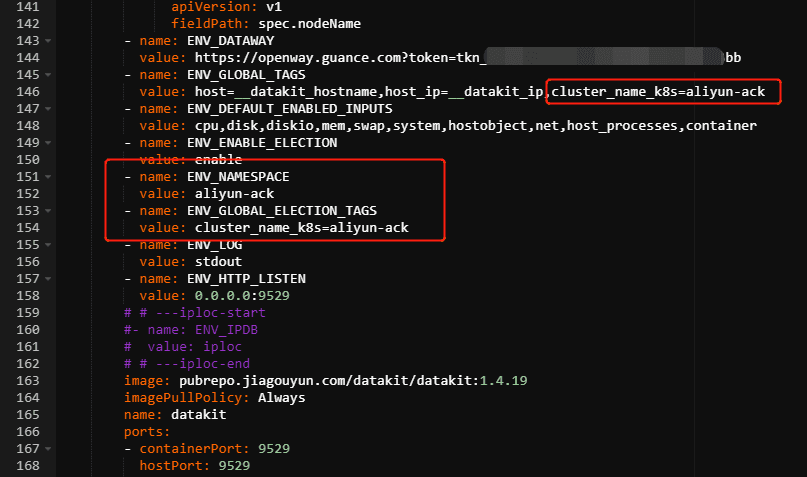
-name:ENV_GLOBAL_HOST_TAGS value:host=__datakit_hostname,host_ip=__datakit_ip,cluster_name_k8s=aliyun-ack
根据上面的说明,下面修改 yaml 文件。
在 datakit.yaml 文件中的 ENV_GLOBAL_TAGS 环境变量值最后增加 cluster_name_k8s=aliyun-ack;
再增加环境变量 ENV_GLOBAL_ELECTION_TAGS,这样测试环境的集群就是 aliyun-ack;
增加环境变量 ENV_NAMESPACE 值是 aliyun-ack。
2 部署 DataKit
修改完成 yaml 文件后,下面开始部署 DataKit。
(1)登录阿里云容器服务管理控制台。
(2)在控制台左侧导航栏中,单击「集群」。
(3)在「集群列表」页面中,单击目标集群名称或者目标集群右侧「操作」列下的「详情」。
(4)在集群管理页左侧导航栏单击「工作负载」 - 「自定义资源」,然后在右侧页面单击「使用 YAML 创建」。
选择相应的命名空间。选择所有名称空间。
在示例模板中,选择自定义。把 yaml 的内容贴入模板中, 点击「创建」。
在守护进程集下面可以查看到 DataKit 运行情况。
3 卸载 DataKit
DataKit 部署默认使用了 datakit 命名空间,卸载只需要删除守护进程集中的 datakit、datakit 命名空间下的资源及名为 datakit 的 ClusterRoleBinding。卸载的方式比较多,这里提供一种通过阿里云容器服务管理控制台卸载的方式。
3.1 删除 DaemonSet
在阿里云的容器管理控制台进入「工作负载」 - 「守护进程集」,找到 datakit,点击右边的「删除」。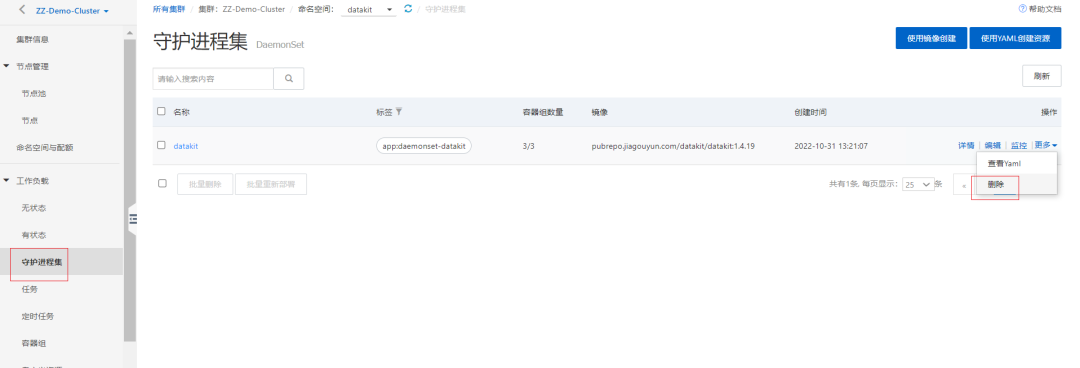
3.2 删除命名空间
进入「节点管理」- 「命名空间与配额」,找到 datakit,点击右边的「删除」。
3.3 删除 Cluster Role
进入 「安全管理」 - 「角色」,在 Cluster Role 下面找到 datakit,点击右边的「删除」。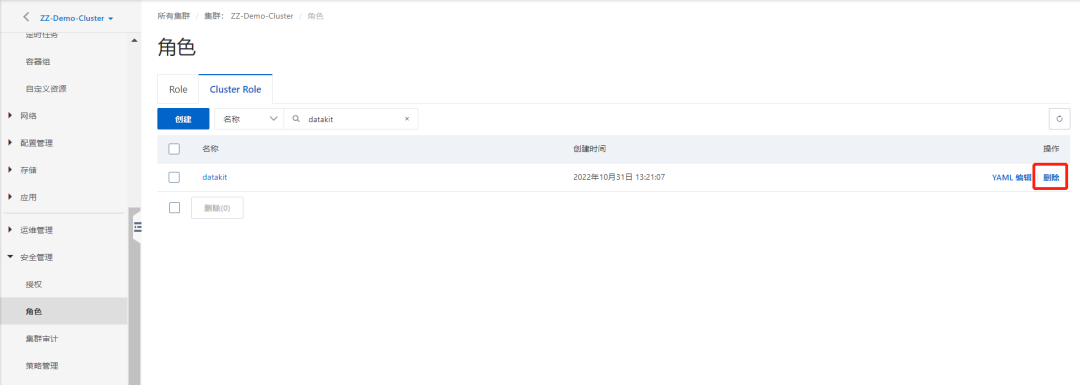
3.4 异常处理
如果在下次部署的时候提示如下错误,是因为阿里云控制台显示删除了,实际资源还存在的情况。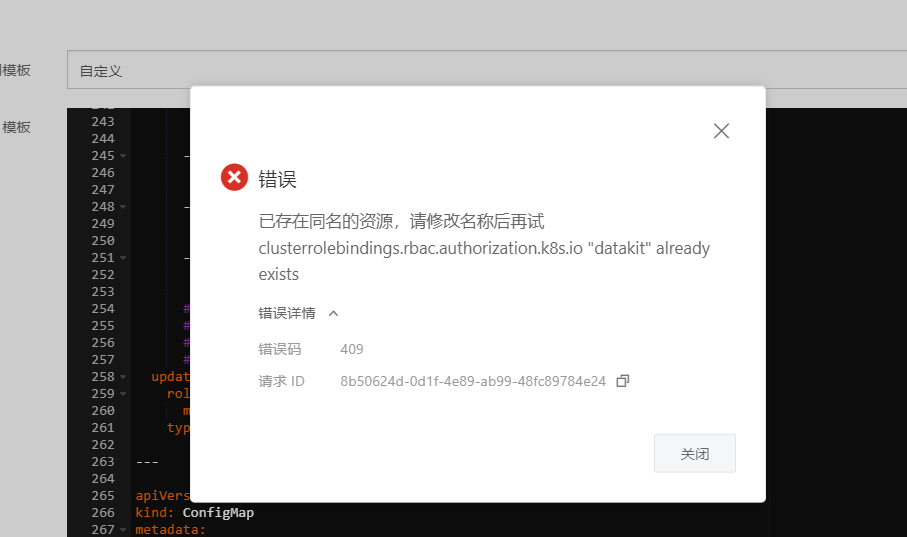
这时只需要把 datakit.yaml 文件中的如下部分删除即可重新部署。
1 apiVersion:rbac.authorization.k8s.io/v1
3 kind:ClusterRoleBinding
5 metadata:
7 name:datakit
9 roleRef:
11 apiGroup:rbac.authorization.k8s.io
13 kind:ClusterRole
15 name:datakit
17 subjects:
19 -kind: ServiceAccount
21 name:datakit
23 namespace: datakit
或者使用命令把 ClusterRoleBinding 删除,再部署 DataKit。
kubectldeleteclusterrolebindings datakit
目录1.AdmobSDK下载地址2.将下载好的unityPackagesdk导入到unity里编辑 3.解析依赖到项目中
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
三大公有云厂商,香港地区主机测评一、ping时延比对(厦门电信本地测试):Ping时延测试腾讯云阿里云华为云延迟率最低时延44ms,最高72ms,平均46ms47.242段:最低时延59ms,最高204ms,平均107ms最低时延45ms,最高93ms,平均47ms丢包率丢包率小有的ip段丢包率较大每个段都会有概率丢包阿里云:47.242段:最低时延59ms,最高204ms,平均107ms,有的ip段丢包率较大8.210段:最低时延64ms,最高232ms,平均119ms,丢包率较好腾讯云:最低时延44ms,最高72ms,平均46ms,丢包率小华为云:最低时延45ms,最高93ms,平均47m
WAF可以对网站进行扫描,识别API漏洞。API安全如何设置API安全_Web应用防火墙-阿里云帮助中心API安全如何划分API业务用途?登录认证手机验证码认证数据保存数据查询数据导出数据分享数据更新数据删除数据增加下线注销信息发送信息认证邮件信息发送邮箱验证码认证账号密码认证账号注册API安全支持检测哪些敏感数据?敏感数据级别敏感数据类型非敏感数据(N)不涉及。特级敏感数据(L0)与一级敏感数据(L1)或二级敏感数据(L2)相同。单次响应中一级敏感数据(L1)较多时,升级为特级敏感数据(L0)。单次响应中二级敏感数据(L2)较多时,升级为一级敏感数据(L1)或特级敏感数据(L0)。一级敏感数
提起阿里巴巴,大部分人想到的是他的电商业务,其实在文娱产业,阿里巴巴的布局很早,阿里大文娱是阿里双H战略的一环,从2014年开始,通过重金收购,阿里巴巴在文学音乐游戏,影院视频体育等板块开始了布局,阿里大文娱初具规模,当时阿里巴巴的高层认为,如果不做娱乐,只能是一家电子商务公司,有了娱乐和电子商务平台,相辅相成,在扩大版图的同时,同时能增强阿里巴巴的影响力。众所周知,电子商务领域,阿里巴巴在初创期也曾遭遇挫折,但整体来说发展势头很猛,始终处于领头羊的地位,阿里大文娱的发展,虽然经历了起伏和波折,发展势头一直看好。对于企业怎样发展,一直存在着两个观点,是做大面面俱到做综合业务,还是专而精呢?阿里
解析数据 进入阿里云的IOTStdio,点击新建项目。 新建项目后点击新建Web应用。名称 应用名称随便填写 创建完成后我们进入应用。 在左侧组件处拖入一个指示灯和一个开关。 点击指示灯组件,点击配置数据源 选择我们的产品、数据、和属性。 我们还可以配置开和关的显示颜色。 点击按钮,配置交互动作。 选择设备和属性,设置值位置点击数据来源,选择组件值 配置完成后进入预览,点击按钮,在esp8266就会收到来自平台的json格式的数据,MCU端需要做的就是解析来自平台的数据,进而达到控制下
BigData/CloudComputing:基于阿里云技术产品的人工智能与大数据/云计算/分布式引擎的综合应用案例目录来理解技术交互流程目录一、云计算网站建设:部署与发布网站建设:简单动态网站搭建云服务器管理维护云数据库管理与数据迁移云存储:对象存储管理与安全超大流量网站的负载均衡二、大数据MOOC网站日志分析搭建企业级数据分析平台基于LBS的热点店铺搜索基于机器学习PAI实现精细化营销基于机器学习的客户流失预警分析使用DataV制作实时销售数据可视化大屏使用MaxCompute进行数据质量核查使用Quick BI制作图形化报表使用时间序列分解模型预测商品销量三、云安全云平台使用安全云上服务
homeassistant久仰大名,据说可以一统各大物联网平台的设备,家里各平台的设备都有一点,控制起来很不方便,于是乎我也来尝尝~homeassistant官网https://www.home-assistant.io/HACShttps://github.com/hacs/integration准备1.Linux系统(Window)其实也类似2.安装好dockerdocker安装homeassistant官方有几个版本可供选择,安装方式可以:直接刷HA的系统,也可以用Docker安装,还可以直接安装在物理机上,具体区别如下:我采用的是Docker进行安装,也就是Container,从上图也
下载宝塔XShell连接上阿里云后,下载宝塔面板yuminstall-ywget&&wget-Oinstall.shhttp://download.bt.cn/install/install_6.0.sh&&shinstall.sh下载结束登录宝塔,一键下载服务下载phpadmin,nginx,mysql等服务器(图略了,我直接点击了,忘了截图了,反正登录后宝塔会自动弹出提示下载)安装jdkjdk网盘(linux)链接:https://pan.baidu.com/s/1VVrC6CYaJTBSucXz4sewHw提取码:frlo把jdk复制到目录中:我复制到了/home/jdk访问jdk目录: