当我们访问购物网站的时候,我们能随意输入关键字就能查询出相关的内容,然是这些随意的数据不可能是根据数据库的字段查询的,他们都是通过es来实现的,es是全文检索服务,它是一个基于Lucene的全文检索服务器,例如北京天安门-----Lucene切分词:北京 天安门 等等词元,当我们检索到这些词元的时候都可以检索到北京天安门。
es是基于lucene的全文检测服务器,对外提供restful接口
 如上图为ES的逻辑结构
如上图为ES的逻辑结构
1.将搜索的文档最终以document方式存储起来
2.将要搜锁的文档的内容分词,所有不重复的词组成分词列表(1,不重复2,的,地,得,a,an,the,语气词不参与分词3,不搜索的字段不参与分词,eg:图片地址)
3.每个分词和document都有关联
如何使用es,es提供restfulapi接口进行索引,搜索,并且支持多种客户端
1)环境要求
1、jdk必须是jdk1.8.0_131以上版本。
2、ElasticSearch 需要至少4096 的线程池、65536个文件创建权限和 262144字节以上空间的虚拟内存才能正常启动,所以需要为虚拟机分配至少1.5G以上的内存
3、从5.0开始,ElasticSearch 安全级别提高了,不允许采用root帐号启动
4、Elasticsearch的插件要求至少centos的内核要3.5以上版本
2)创建用户
因为不能采用root账号启动,所以我们要添加一个用户
1,创建elk用户组
groupadd elk
2,创建用户admin
useradd admin
passwd admin
3.将admin用户添加到elk组
usermod -G elk admin
4.为用户分配权限
#chown将指定文件的拥有者改为指定的用户或组 -R处理指定目录以及其子目录下的所有文件
chown -R admin:elk /usr/upload
chown -R admin:elk /usr/local
3)安装解压
tar -zxvf elasticsearch-6.2.3.tar.gz -C /usr/local
启动
./elasticsearch
#或
./elasticsearch -d
关闭
ps-ef|grep elasticsearch
kill -9 pid
修改文件创建权限
su root
vim /etc/security/limits.conf:
* soft nofile 65536
* hard nofile 65536
修改线程开启限制
su root
vim /etc/security/limits.conf:
* soft nproc 4096
* hard nproc 4096
修改虚拟内存
su root
vim /etc/sysctl.conf:
vm.max_map_count=655360
sysctl -p
启动验证
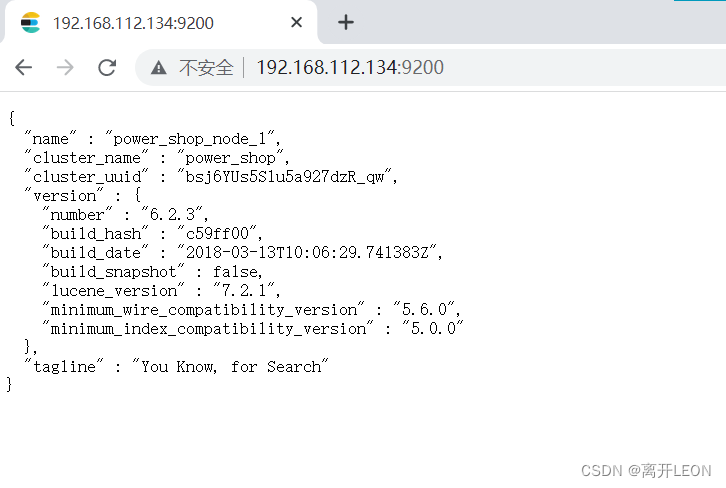
1,index管理
创建index
索引库。包含若干相似结构的 Document 数据,相当于数据库的database。
number_of_shards - 表示一个索引库将拆分成多片分别存储不同的结点,提高了ES的处理能力
number_of_replicas - 是为每个 primary shard分配的replica shard数,提高了ES的可用性,如果只有一台机器,设置为0
PUT /java2202
{
"settings":{
"number_of_shards":2,
"number_of_replicas":1
}
}
注意:一台服务器时,备份分片的数量必须设置为0,因为主备在同一台上没有意义
效果如下图
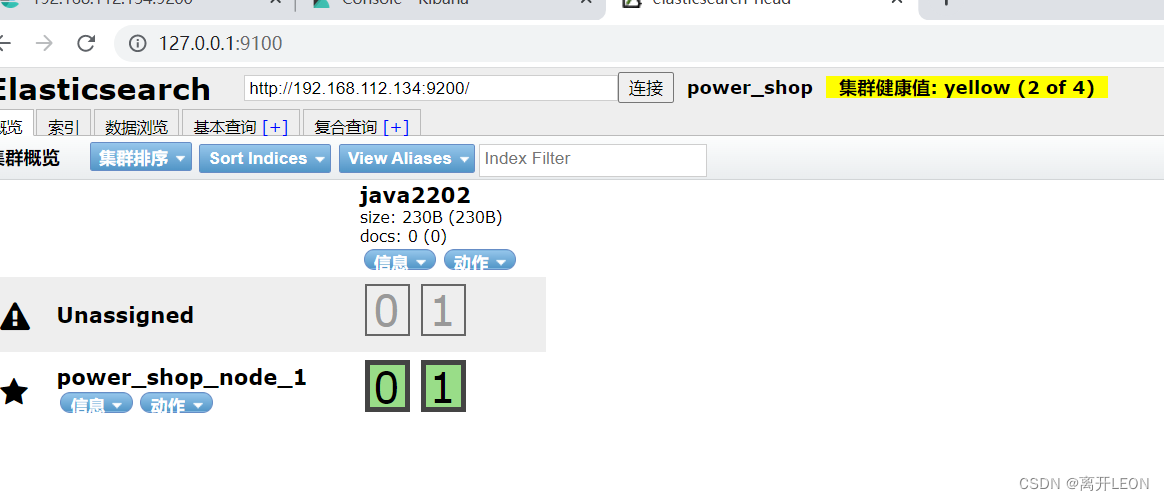 修改index
修改index
index创建后shard数量不能变化,但可以改变replicas的数量
index一旦创建,主分片数量不可修改,因为:Get时—>hash(id)%number_of_shards
PUT /java2202/_settings
{
"number_of_replicas" : 0
}
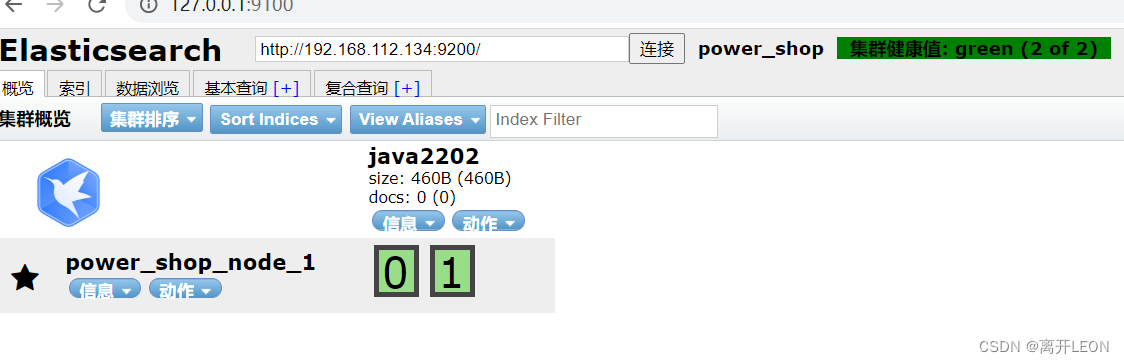 删除index
删除index
DELETE /Java2202
映射,创建映射就是向索引库中创建field(类型、是否索引、是否存储等特性)的过程,相当于建表
 新增mapping
新增mapping
POST /java2202/course/_mapping
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text"
},
"studymodel": {
"type": "keyword"
}
}
}
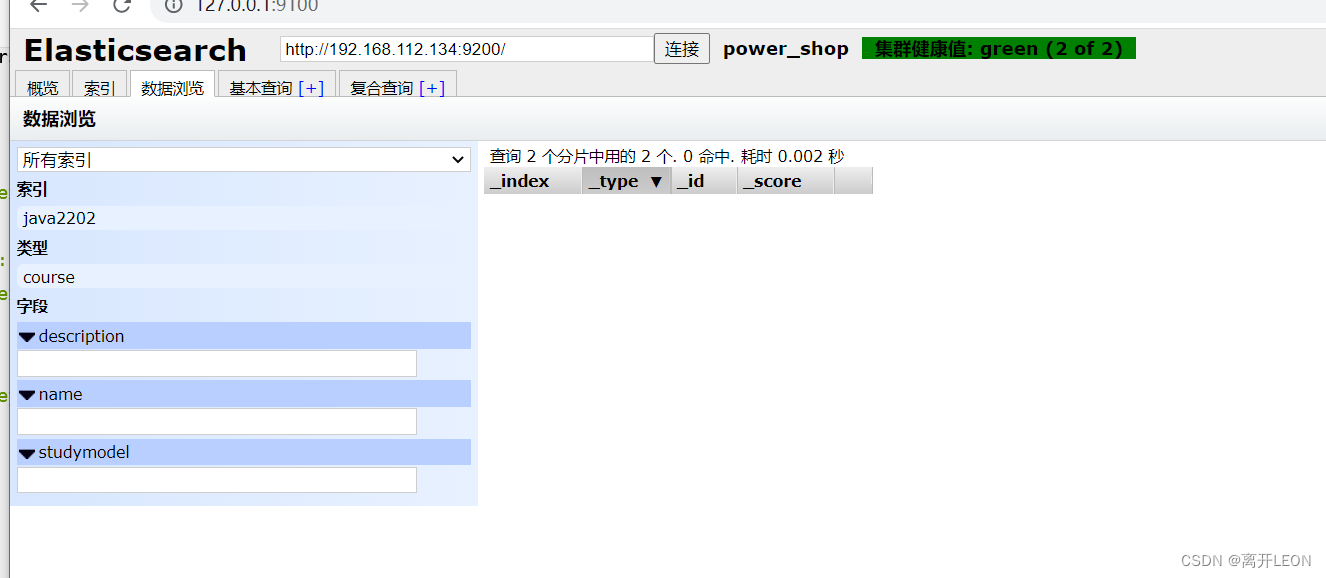 查询mapping
查询mapping
GET /java06/course/_mapping
 更新mapping
更新mapping
映射创建成功可以添加新字段,已有字段不允许更新。
删除mapping
通过删除索引index来删除映射。
document相当于mysql的表中的数据
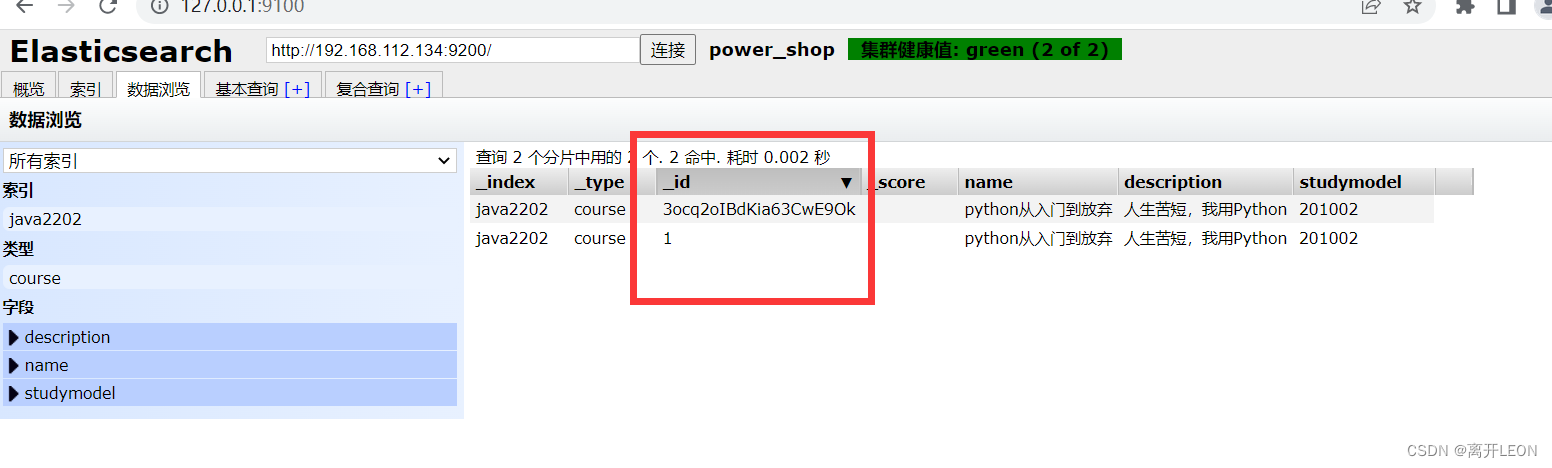
新增
此操作为 ES 自动生成 id 的新增 Document 方式
POST /java06/course/1
{
"name":"python从入门到放弃",
"description":"人生苦短,我用Python",
"studymodel":"201002"
}
POST /java06/course
{
"name":"python从入门到放弃",
"description":"人生苦短,我用Python",
"studymodel":"201002"
}
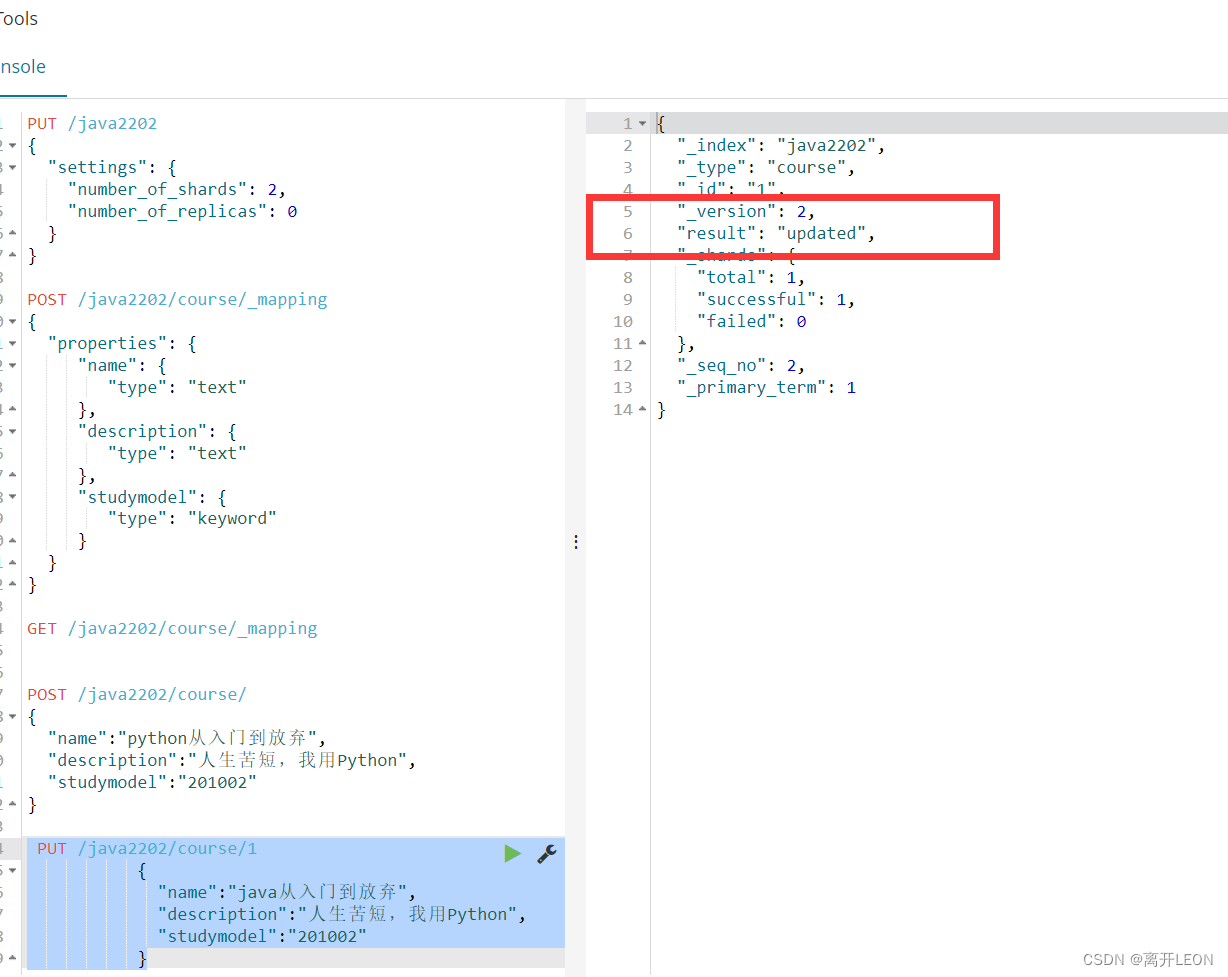
修改
PUT /java2202/course/1
{
"name":"java从入门到放弃",
"description":"人生苦短,我用Python",
"studymodel":"201002"
}
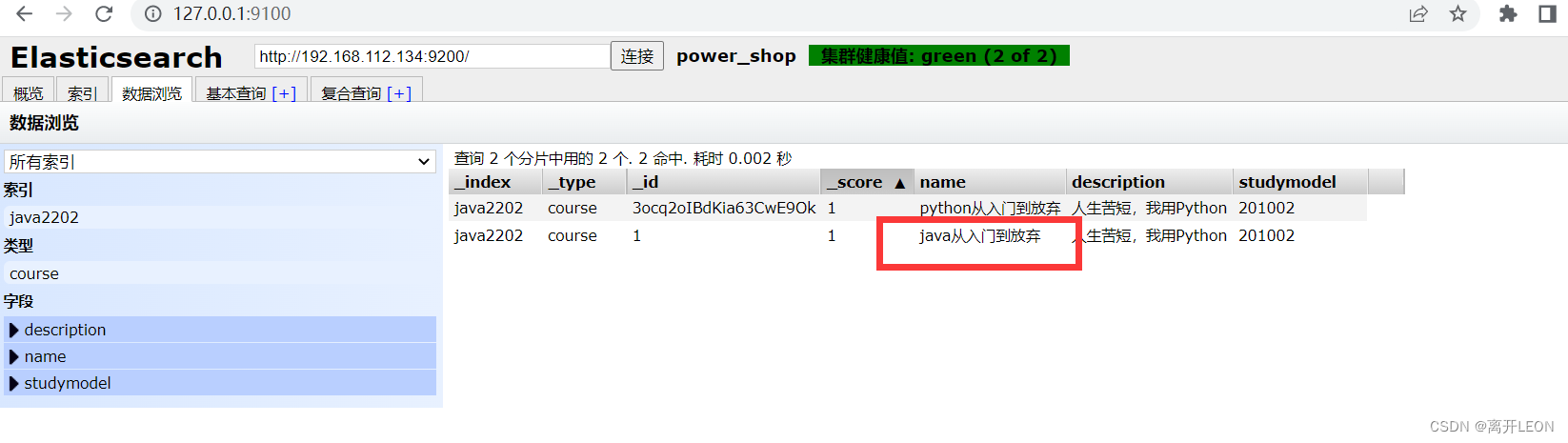 查询document
查询document
GET /Java2202/course/1
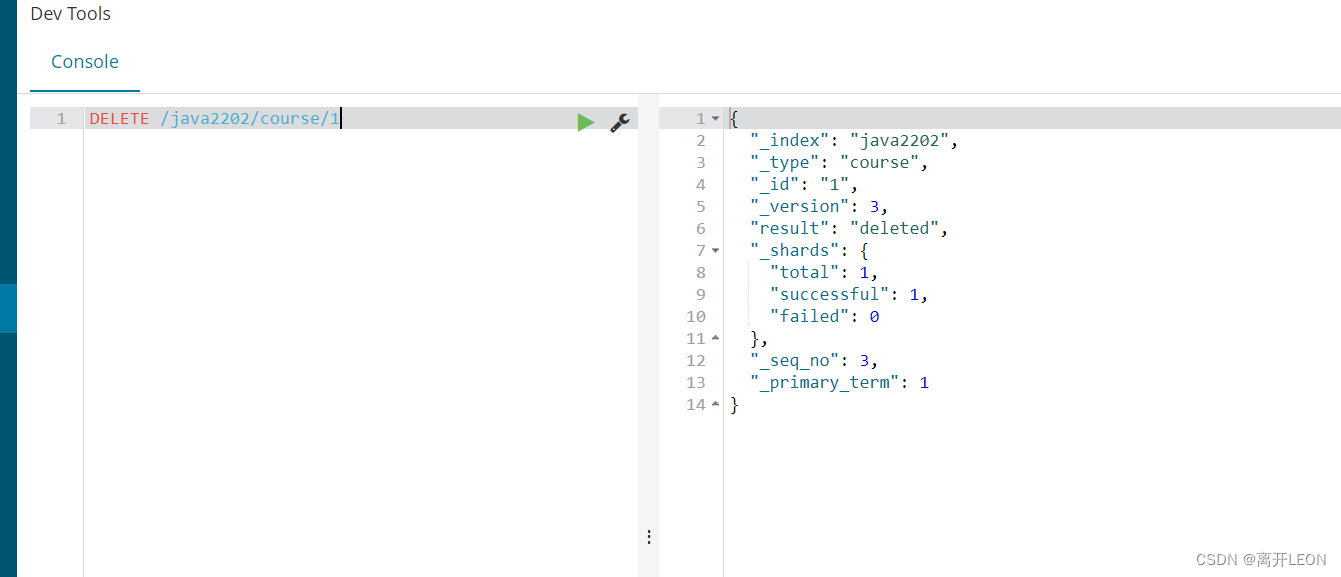
 删除document
删除document
DELETE /java2202/course/1
document routing
当客户端创建document文档数据时,es需要确定这文档数据放在index的哪个shard(分片)上,这个过程就是documentrouting
路由过程:
shard(分片)=hash(id)%number_of_primary_shards
id 为document的_id,可能是自己指定的也可能是自动生成的,
number_of_primary_shards:主分片的数量
为什么primary shard数量不可变?
原因:假如我们的集群在初始化的时候有5个primary shard,我们往里边加入一个document id=5,假如hash(5)=23,这时该document 将被加入 (shard=23%5=3)P3这个分片上。如果随后我们给es集群添加一个primary shard ,此时就有6个primary shard,当我们GET id=5 ,这条数据的时候,es会计算该请求的路由信息找到存储他的 primary shard(shard=23%6=5) ,根据计算结果定位到P5分片上。而我们的数据在P3上。所以es集群无法添加primary shard,但是可以扩展replicas shard。
总结就是:数据id不变,但是分片的数量变化导致新增分片数量后最终的分片位置与原先的位置不一样
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us
美团外卖搜索工程团队在Elasticsearch的优化实践中,基于Location-BasedService(LBS)业务场景对Elasticsearch的查询性能进行优化。该优化基于Run-LengthEncoding(RLE)设计了一款高效的倒排索引结构,使检索耗时(TP99)降低了84%。本文从问题分析、技术选型、优化方案等方面进行阐述,并给出最终灰度验证的结论。1.前言最近十年,Elasticsearch已经成为了最受欢迎的开源检索引擎,其作为离线数仓、近线检索、B端检索的经典基建,已沉淀了大量的实践案例及优化总结。然而在高并发、高可用、大数据量的C端场景,目前可参考的资料并不多。因此
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
我有一个关于配置elasticsearch以连接AWSelasticsearch服务以在生产环境中运行项目的问题。我的gem文件:gem'searchkick'gem'faraday_middleware-aws-signers-v4'gem'aws-sdk','~>2'gem"elasticsearch",">=1.0.15"引用:https://github.com/ankane/searchkick我的config/initializers/elasticsearch.rb文件:require"faraday_middleware/aws_signers_v4"ENV["ELAS
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
我在查询中使用geo_distancefilter和tire,它工作正常:search.filter:geo_distance,:distance=>"#{request.distance}km",:location=>"#{request.lat},#{request.lng}"我预计结果会以某种方式包括到我用于过滤器的地理位置的计算距离。有没有办法告诉elasticsearch在响应中包含它,这样我就不必在ruby中为每个结果计算它?==更新==我在谷歌群组中的foundtheanswer:search.sortdoby"_geo_distance","location"=>"
如果不必像这样进行搜索就可以对元素进行计数,那就太好了Obj.search("id:*").count这可能吗? 最佳答案 在ElasticSearch中,您可以使用计数API对所有元素进行计数curl-XGEThttp://localhost:9200/index/_count参见CountAPI他们网站上的文档。 关于ruby-有没有办法计算ElasticSearch或Tire中索引的所有元素?,我们在StackOverflow上找到一个类似的问题: ht